- Developers & Engineers: Integrate advanced AI capabilities into applications, chatbots, and tools.
- Content Creators & Marketers: Generate high-quality, long-form content efficiently.
- Educators & Researchers: Summarize extensive documents, analyze data, and assist in academic writing.
- Businesses & Enterprises: Enhance customer support, automate tasks, and develop intelligent assistants.
- Data Analysts: Interpret complex datasets and generate insightful reports.
🛠️ How to Use GPT-4 Turbo?
- Access the OpenAI API: Ensure you have API access through OpenAI's platform.
- Specify the Model: Use "gpt-4-turbo" as the model name in your API requests.
- Prepare Your Input: Craft prompts or inputs, including text or images, depending on your use case.
- Send Requests: Utilize the API to send your inputs and receive generated outputs.
- Implement Outputs: Incorporate the AI-generated content into your applications, workflows, or analyses.
Note: Detailed API documentation and examples are available on the OpenAI platform.
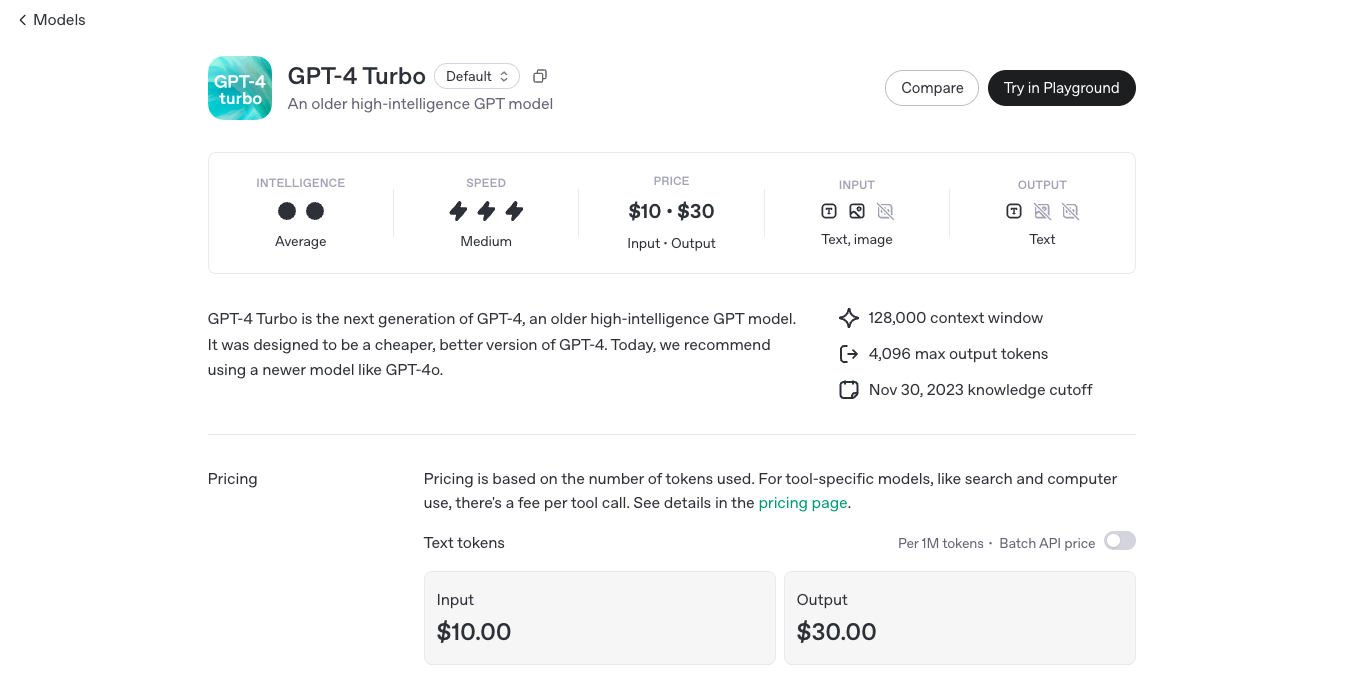
- Extended Context Window: Handles up to 128,000 tokens, enabling processing of extensive documents and conversations.
- Multimodal Capabilities: Accepts both text and image inputs, enhancing versatility.
- Cost-Effective: Offers lower pricing compared to its predecessor, making it accessible for a broader range of users.
- Improved Performance: Delivers faster response times and better adherence to instructions.
- Updated Knowledge Base: Includes information up to April 2023, providing more current responses.
- Long-Form Content Handling: Efficiently processes and generates lengthy documents.
- Image Input Support: Enhances applications requiring visual data interpretation.
- Affordable Pricing: Reduces costs for developers and businesses.
- Fast Processing: Improves user experience with quicker responses.
- Enhanced Instruction Following: Better understands and executes complex prompts
- Preview Status: As a preview model, it may have limitations and is not recommended for production use without thorough testing.
- Limited Transparency: Detailed information on model architecture and training data is not publicly available.
- Potential for Hallucinations: May generate inaccurate information, necessitating human oversight.
- Knowledge Cutoff: Information is current only up to April 2023.
- Complex Integration: Implementing multimodal inputs may require additional development effort.
API Only
$10/$30 for 1M tokens
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI o3
o3 is OpenAI's next-generation language model, representing a significant leap in performance, reasoning ability, and efficiency. Positioned between GPT-4 and GPT-4o in terms of evolution, o3 is engineered for advanced language understanding, content generation, multilingual communication, and code-related tasks—while maintaining faster speeds and lower latency than earlier models. As part of OpenAI’s GPT-4 Turbo family, o3 delivers high-quality outputs at scale, supporting both chat and completion endpoints. It’s currently used in various commercial and developer-facing tools for streamlined and intelligent interactions.
OpenAI o3
o3 is OpenAI's next-generation language model, representing a significant leap in performance, reasoning ability, and efficiency. Positioned between GPT-4 and GPT-4o in terms of evolution, o3 is engineered for advanced language understanding, content generation, multilingual communication, and code-related tasks—while maintaining faster speeds and lower latency than earlier models. As part of OpenAI’s GPT-4 Turbo family, o3 delivers high-quality outputs at scale, supporting both chat and completion endpoints. It’s currently used in various commercial and developer-facing tools for streamlined and intelligent interactions.
OpenAI o3
o3 is OpenAI's next-generation language model, representing a significant leap in performance, reasoning ability, and efficiency. Positioned between GPT-4 and GPT-4o in terms of evolution, o3 is engineered for advanced language understanding, content generation, multilingual communication, and code-related tasks—while maintaining faster speeds and lower latency than earlier models. As part of OpenAI’s GPT-4 Turbo family, o3 delivers high-quality outputs at scale, supporting both chat and completion endpoints. It’s currently used in various commercial and developer-facing tools for streamlined and intelligent interactions.

OpenAI o1-pro
o1-pro is a highly capable AI model developed by OpenAI, designed to deliver efficient, high-quality text generation across a wide range of use cases. As part of OpenAI’s GPT-4 architecture family, o1-pro is optimized for low-latency performance and high accuracy—making it suitable for both everyday tasks and enterprise-scale applications. It powers natural language interactions, content creation, summarization, and more, offering developers a solid balance between performance, cost, and output quality.
OpenAI o1-pro
o1-pro is a highly capable AI model developed by OpenAI, designed to deliver efficient, high-quality text generation across a wide range of use cases. As part of OpenAI’s GPT-4 architecture family, o1-pro is optimized for low-latency performance and high accuracy—making it suitable for both everyday tasks and enterprise-scale applications. It powers natural language interactions, content creation, summarization, and more, offering developers a solid balance between performance, cost, and output quality.
OpenAI o1-pro
o1-pro is a highly capable AI model developed by OpenAI, designed to deliver efficient, high-quality text generation across a wide range of use cases. As part of OpenAI’s GPT-4 architecture family, o1-pro is optimized for low-latency performance and high accuracy—making it suitable for both everyday tasks and enterprise-scale applications. It powers natural language interactions, content creation, summarization, and more, offering developers a solid balance between performance, cost, and output quality.

GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.

GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.

GPT-4o Mini Realtime Preview is a lightweight, high-speed variant of OpenAI’s flagship multimodal model, GPT-4o. Built for blazing-fast, cost-efficient inference across text, vision, and voice inputs, this preview version is optimized for real-time responsiveness—without compromising on core intelligence. Whether you’re building chatbots, interactive voice tools, or lightweight apps, GPT-4o Mini delivers smart performance with minimal latency and compute load. It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.
GPT-4o Mini Realtime Preview is a lightweight, high-speed variant of OpenAI’s flagship multimodal model, GPT-4o. Built for blazing-fast, cost-efficient inference across text, vision, and voice inputs, this preview version is optimized for real-time responsiveness—without compromising on core intelligence. Whether you’re building chatbots, interactive voice tools, or lightweight apps, GPT-4o Mini delivers smart performance with minimal latency and compute load. It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.
GPT-4o Mini Realtime Preview is a lightweight, high-speed variant of OpenAI’s flagship multimodal model, GPT-4o. Built for blazing-fast, cost-efficient inference across text, vision, and voice inputs, this preview version is optimized for real-time responsiveness—without compromising on core intelligence. Whether you’re building chatbots, interactive voice tools, or lightweight apps, GPT-4o Mini delivers smart performance with minimal latency and compute load. It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.

GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.

codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.
codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.
codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.

Aider
Aider.ai is an open-source AI-powered coding assistant that allows developers to collaborate with large language models like GPT-4 directly from the command line. It integrates seamlessly with Git, enabling conversational programming, code editing, and refactoring within your existing development workflow. With Aider, you can modify multiple files at once, get code explanations, and maintain clean version history—all from your terminal.
Aider
Aider.ai is an open-source AI-powered coding assistant that allows developers to collaborate with large language models like GPT-4 directly from the command line. It integrates seamlessly with Git, enabling conversational programming, code editing, and refactoring within your existing development workflow. With Aider, you can modify multiple files at once, get code explanations, and maintain clean version history—all from your terminal.
Aider
Aider.ai is an open-source AI-powered coding assistant that allows developers to collaborate with large language models like GPT-4 directly from the command line. It integrates seamlessly with Git, enabling conversational programming, code editing, and refactoring within your existing development workflow. With Aider, you can modify multiple files at once, get code explanations, and maintain clean version history—all from your terminal.
DeepSeek-Coder-V2
DeepSeek‑Coder V2 is an open-source, Mixture‑of‑Experts (MoE) code-focused variant of DeepSeek‑V2, purpose-built for code generation, completion, debugging, and mathematical reasoning. Trained with an additional 6 trillion tokens of code and text, it supports up to 338 programming languages and a massive 128K‑token context window, rivaling or exceeding commercial code models in performance.
DeepSeek-Coder-V2
DeepSeek‑Coder V2 is an open-source, Mixture‑of‑Experts (MoE) code-focused variant of DeepSeek‑V2, purpose-built for code generation, completion, debugging, and mathematical reasoning. Trained with an additional 6 trillion tokens of code and text, it supports up to 338 programming languages and a massive 128K‑token context window, rivaling or exceeding commercial code models in performance.
DeepSeek-Coder-V2
DeepSeek‑Coder V2 is an open-source, Mixture‑of‑Experts (MoE) code-focused variant of DeepSeek‑V2, purpose-built for code generation, completion, debugging, and mathematical reasoning. Trained with an additional 6 trillion tokens of code and text, it supports up to 338 programming languages and a massive 128K‑token context window, rivaling or exceeding commercial code models in performance.

Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.

DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.

DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai