
It powers natural language interactions, content creation, summarization, and more, offering developers a solid balance between performance, cost, and output quality.
- Product Developers: Integrate o1-pro into tools and platforms for fast, context-aware AI capabilities.
- Customer Support Teams: Build bots and virtual agents that understand and resolve customer queries effectively.
- Content Creators: Generate ideas, blog posts, social media content, and long-form articles with ease.
- App Builders: Use o1-pro in mobile or SaaS apps to add dynamic responses and interactive user experiences.
- Students & Educators: Summarize research, explain concepts, or create study material efficiently.
- Marketing Teams: Craft product descriptions, landing page content, and email sequences at scale.
🛠️ How to Use o1-pro?
- Step 1: Sign in to the OpenAI Platform: Access o1-pro through the OpenAI API, using chat or completion endpoints.
- Step 2: Select the o1-pro Model: Choose gpt-4-o1 as your target model from the list of available deployments.
- Step 3: Input a Prompt: Provide the model with a detailed prompt, instruction, or question in natural language.
- Step 4: Configure Output Settings: Adjust parameters like temperature, topp, and maxtokens to control creativity and length.
- Step 5: Receive & Use Output: Use the AI’s generated response in your app, website, or process pipeline.
- Step 6: Scale Up as Needed: With reliable performance and manageable cost, o1-pro is ideal for production workloads.
- High-Speed Generation: Optimized for fast inference times—ideal for real-time applications.
- Reliable Accuracy: Offers coherent, relevant responses across a wide array of domains.
- Production-Ready: Robust enough for live user-facing tools and business workflows.
- Lower Latency: Outperforms older GPT models in speed without sacrificing quality.
- Cost-Effective: Priced more affordably than GPT-4 while offering comparable output in many cases.
- Flexible Integration: Works with OpenAI's Assistants API, JSON mode, and function calling.
- Fast Response Time: Suitable for responsive user experiences and chat-based tools.
- Strong General Knowledge: Performs well across diverse topics and writing styles.
- Better Price-to-Performance Ratio: A great middle-ground between GPT-3.5 and full GPT-4 models.
- Supports JSON & Function Calling: Simplifies data handling and structured integrations.
- Easy to Deploy in Existing Workflows: Fits well in both lightweight and complex applications.
- Limited Transparency: OpenAI has not revealed detailed architecture or training data specifics.
- Not as Capable as GPT-4 Turbo: May struggle with complex reasoning tasks or domain-specific outputs.
- Occasional Repetition or Over-summarization: Especially in longer content.
- No Fine-Tuning (Yet): Developers must rely on prompt engineering instead of model customization.
- Slightly Less Multilingual Versatility: Performs best in English and major global languages.
1M tokens
$150/$600
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI’s Real-Time API is a game-changing advancement in AI interaction, enabling developers to build apps that respond instantly—literally in milliseconds—to user inputs. It drastically reduces the response latency of OpenAI’s GPT-4o model to as low as 100 milliseconds, unlocking a whole new world of AI-powered experiences that feel more human, responsive, and conversational in real time. Whether you're building a live voice assistant, a responsive chatbot, or interactive multiplayer tools powered by AI, this API puts real in real-time AI.
OpenAI’s Real-Time API is a game-changing advancement in AI interaction, enabling developers to build apps that respond instantly—literally in milliseconds—to user inputs. It drastically reduces the response latency of OpenAI’s GPT-4o model to as low as 100 milliseconds, unlocking a whole new world of AI-powered experiences that feel more human, responsive, and conversational in real time. Whether you're building a live voice assistant, a responsive chatbot, or interactive multiplayer tools powered by AI, this API puts real in real-time AI.
OpenAI’s Real-Time API is a game-changing advancement in AI interaction, enabling developers to build apps that respond instantly—literally in milliseconds—to user inputs. It drastically reduces the response latency of OpenAI’s GPT-4o model to as low as 100 milliseconds, unlocking a whole new world of AI-powered experiences that feel more human, responsive, and conversational in real time. Whether you're building a live voice assistant, a responsive chatbot, or interactive multiplayer tools powered by AI, this API puts real in real-time AI.

OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.

GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.

GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.

codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.
codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.
codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.
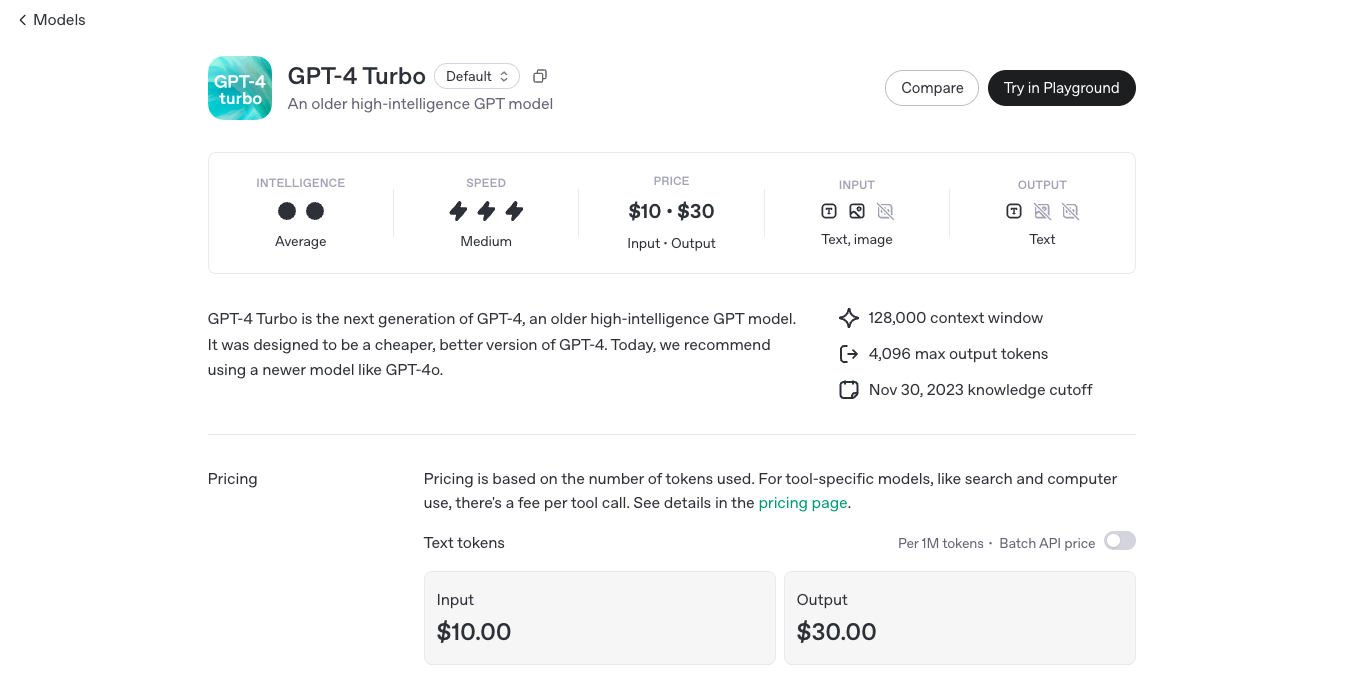
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
Boundary AI
BoundaryML.com introduces BAML, an expressive language specifically designed for structured text generation with Large Language Models (LLMs). Its primary purpose is to simplify and enhance the process of obtaining structured data (like JSON) from LLMs, moving beyond the challenges of traditional methods by providing robust parsing, error correction, and reliable function-calling capabilities.
Boundary AI
BoundaryML.com introduces BAML, an expressive language specifically designed for structured text generation with Large Language Models (LLMs). Its primary purpose is to simplify and enhance the process of obtaining structured data (like JSON) from LLMs, moving beyond the challenges of traditional methods by providing robust parsing, error correction, and reliable function-calling capabilities.
Boundary AI
BoundaryML.com introduces BAML, an expressive language specifically designed for structured text generation with Large Language Models (LLMs). Its primary purpose is to simplify and enhance the process of obtaining structured data (like JSON) from LLMs, moving beyond the challenges of traditional methods by providing robust parsing, error correction, and reliable function-calling capabilities.

inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.

Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
Snowflake - Arctic
Snowflake's Arctic is a family of open-source large language models optimized for enterprise workloads, featuring a unique dense-MoE hybrid architecture that delivers top-tier performance in SQL generation, code tasks, and instruction following at a fraction of comparable model development costs. Released under Apache 2.0 license with fully ungated access to weights, code, open data recipes, and research insights, it excels in complex business scenarios while remaining capable across general tasks. Enterprises can fine-tune or deploy using popular frameworks like LoRA, TRT-LLM, and vLLM, with detailed training and inference cookbooks available. The models lead benchmarks for enterprise intelligence, balancing expert efficiency for fast inference and broad applicability without restrictive gates or proprietary limits.
Snowflake - Arctic
Snowflake's Arctic is a family of open-source large language models optimized for enterprise workloads, featuring a unique dense-MoE hybrid architecture that delivers top-tier performance in SQL generation, code tasks, and instruction following at a fraction of comparable model development costs. Released under Apache 2.0 license with fully ungated access to weights, code, open data recipes, and research insights, it excels in complex business scenarios while remaining capable across general tasks. Enterprises can fine-tune or deploy using popular frameworks like LoRA, TRT-LLM, and vLLM, with detailed training and inference cookbooks available. The models lead benchmarks for enterprise intelligence, balancing expert efficiency for fast inference and broad applicability without restrictive gates or proprietary limits.
Snowflake - Arctic
Snowflake's Arctic is a family of open-source large language models optimized for enterprise workloads, featuring a unique dense-MoE hybrid architecture that delivers top-tier performance in SQL generation, code tasks, and instruction following at a fraction of comparable model development costs. Released under Apache 2.0 license with fully ungated access to weights, code, open data recipes, and research insights, it excels in complex business scenarios while remaining capable across general tasks. Enterprises can fine-tune or deploy using popular frameworks like LoRA, TRT-LLM, and vLLM, with detailed training and inference cookbooks available. The models lead benchmarks for enterprise intelligence, balancing expert efficiency for fast inference and broad applicability without restrictive gates or proprietary limits.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai