- Data Scientists & ML Engineers: Fine-tune models for custom enterprise SQL and code needs.
- Developers & DevOps: Deploy via vLLM or TRT-LLM for scalable inference setups.
- Enterprise IT Teams: Leverage open-source LLMs for internal analytics and automation.
- AI Researchers: Access full weights, data recipes, and hybrid architecture insights.
- Business Analysts: Apply top-performing models to instruction-heavy workflows.
How to Use Snowflake's Arctic?
- Download Weights & Code: Access Apache 2.0 licensed models directly from Snowflake.
- Follow Cookbooks: Use training guides for LoRA fine-tuning or inference setups.
- Select Frameworks: Deploy with TRT-LLM, vLLM for optimal MoE performance.
- Integrate Enterprise: Apply to SQL, coding, and instruction tasks in your stack.
- Dense-MoE Hybrid: Balances expert efficiency with dense model strengths cost-effectively.
- Apache 2.0 Ungated: Full open access to weights, code, and training recipes.
- Enterprise Benchmarks: Tops SQL, code generation, and instruction following scores.
- Low Development Cost: Achieves top results without massive proprietary training expenses.
- Framework Cookbooks: Detailed guides for LoRA, TRT-LLM, vLLM deployment.
- Open-source with no access restrictions or licensing hurdles.
- Excels specifically in high-value enterprise coding and SQL tasks.
- Hybrid architecture optimizes inference speed and cost.
- Comprehensive cookbooks simplify fine-tuning and deployment.
- MoE complexity may need specialized inference hardware.
- Requires framework knowledge for optimal vLLM or TRT-LLM use.
- Enterprise focus might underperform niche general chat scenarios.
- Ongoing maintenance needed for latest benchmark competition.

Standard
$ 2.00
All core platform functionality with fully managed elastic compute
Security with automatic encryption of all data
Snowpark
Data sharing
Optimized storage with compression and Time Travel
+ more
Enterprise
$ 3.00
ALL STANDARD EDITION FEATURES +
Ability to use multi-cluster compute
Granular governance and privacy controls
Extended Time Travel windows
+ more
Business Critical
$ 4.00
ALL ENTERPRISE EDITION FEATURES +
Tri-Secret Secure
Access to private connectivity
Failover and failback for backup and disaster recovery
+ more
Virtual Private Snowflake
Contact Sales
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.
codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.
codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.

DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.

Kilo Code
Kilo Code is an AI-powered coding assistant designed to enhance software development within IDEs like Visual Studio Code and JetBrains. It integrates features from existing AI coding tools while providing unique functionalities such as the Model Context Protocol (MCP) Server Marketplace and intelligent system notifications. Kilo Code streamlines development by automating repetitive tasks, generating code from natural language prompts, and providing intelligent suggestions to developers.
Kilo Code
Kilo Code is an AI-powered coding assistant designed to enhance software development within IDEs like Visual Studio Code and JetBrains. It integrates features from existing AI coding tools while providing unique functionalities such as the Model Context Protocol (MCP) Server Marketplace and intelligent system notifications. Kilo Code streamlines development by automating repetitive tasks, generating code from natural language prompts, and providing intelligent suggestions to developers.
Kilo Code
Kilo Code is an AI-powered coding assistant designed to enhance software development within IDEs like Visual Studio Code and JetBrains. It integrates features from existing AI coding tools while providing unique functionalities such as the Model Context Protocol (MCP) Server Marketplace and intelligent system notifications. Kilo Code streamlines development by automating repetitive tasks, generating code from natural language prompts, and providing intelligent suggestions to developers.

Unsloth AI
Unsloth.AI is an open-source platform designed to accelerate and simplify the fine-tuning of large language models (LLMs). By leveraging manual mathematical derivations, custom GPU kernels, and efficient optimization techniques, Unsloth achieves up to 30x faster training speeds compared to traditional methods, without compromising model accuracy. It supports a wide range of popular models, including Llama, Mistral, Gemma, and BERT, and works seamlessly on various GPUs, from consumer-grade Tesla T4 to high-end H100, as well as AMD and Intel GPUs. Unsloth empowers developers, researchers, and AI enthusiasts to fine-tune models efficiently, even with limited computational resources, democratizing access to advanced AI model customization. With a focus on performance, scalability, and flexibility, Unsloth.AI is suitable for both academic research and commercial applications, helping users deploy specialized AI solutions faster and more effectively.
Unsloth AI
Unsloth.AI is an open-source platform designed to accelerate and simplify the fine-tuning of large language models (LLMs). By leveraging manual mathematical derivations, custom GPU kernels, and efficient optimization techniques, Unsloth achieves up to 30x faster training speeds compared to traditional methods, without compromising model accuracy. It supports a wide range of popular models, including Llama, Mistral, Gemma, and BERT, and works seamlessly on various GPUs, from consumer-grade Tesla T4 to high-end H100, as well as AMD and Intel GPUs. Unsloth empowers developers, researchers, and AI enthusiasts to fine-tune models efficiently, even with limited computational resources, democratizing access to advanced AI model customization. With a focus on performance, scalability, and flexibility, Unsloth.AI is suitable for both academic research and commercial applications, helping users deploy specialized AI solutions faster and more effectively.
Unsloth AI
Unsloth.AI is an open-source platform designed to accelerate and simplify the fine-tuning of large language models (LLMs). By leveraging manual mathematical derivations, custom GPU kernels, and efficient optimization techniques, Unsloth achieves up to 30x faster training speeds compared to traditional methods, without compromising model accuracy. It supports a wide range of popular models, including Llama, Mistral, Gemma, and BERT, and works seamlessly on various GPUs, from consumer-grade Tesla T4 to high-end H100, as well as AMD and Intel GPUs. Unsloth empowers developers, researchers, and AI enthusiasts to fine-tune models efficiently, even with limited computational resources, democratizing access to advanced AI model customization. With a focus on performance, scalability, and flexibility, Unsloth.AI is suitable for both academic research and commercial applications, helping users deploy specialized AI solutions faster and more effectively.

inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
Genloop AI
Genloop is a platform that empowers enterprises to build, deploy, and manage custom, private large language models (LLMs) tailored to their business data and requirements — all with minimal development effort. It turns enterprise data into intelligent, conversational insights, allowing users to ask business questions in natural language and receive actionable analysis instantly. The platform enables organizations to confidently manage their data-driven decision-making by offering advanced fine-tuning, automation, and deployment tools. Businesses can transform their existing datasets into private AI assistants that deliver accurate insights, while maintaining complete security and compliance. Genloop’s focus is on bridging the gap between AI and enterprise data operations, providing a scalable, trustworthy, and adaptive solution for teams that want to leverage AI without extensive coding or infrastructure complexity.
Genloop AI
Genloop is a platform that empowers enterprises to build, deploy, and manage custom, private large language models (LLMs) tailored to their business data and requirements — all with minimal development effort. It turns enterprise data into intelligent, conversational insights, allowing users to ask business questions in natural language and receive actionable analysis instantly. The platform enables organizations to confidently manage their data-driven decision-making by offering advanced fine-tuning, automation, and deployment tools. Businesses can transform their existing datasets into private AI assistants that deliver accurate insights, while maintaining complete security and compliance. Genloop’s focus is on bridging the gap between AI and enterprise data operations, providing a scalable, trustworthy, and adaptive solution for teams that want to leverage AI without extensive coding or infrastructure complexity.
Genloop AI
Genloop is a platform that empowers enterprises to build, deploy, and manage custom, private large language models (LLMs) tailored to their business data and requirements — all with minimal development effort. It turns enterprise data into intelligent, conversational insights, allowing users to ask business questions in natural language and receive actionable analysis instantly. The platform enables organizations to confidently manage their data-driven decision-making by offering advanced fine-tuning, automation, and deployment tools. Businesses can transform their existing datasets into private AI assistants that deliver accurate insights, while maintaining complete security and compliance. Genloop’s focus is on bridging the gap between AI and enterprise data operations, providing a scalable, trustworthy, and adaptive solution for teams that want to leverage AI without extensive coding or infrastructure complexity.
Soket AI
Soket AI is an Indian deep-tech startup building sovereign, multilingual foundational AI models and real-time voice/speech APIs designed for Indic languages and global scale. By focusing on language diversity, cultural context and ethical AI, Soket AI aims to develop models that recognise and respond across many languages, while delivering enterprise-grade capabilities for sectors such as defence, healthcare, education and governance.
Soket AI
Soket AI is an Indian deep-tech startup building sovereign, multilingual foundational AI models and real-time voice/speech APIs designed for Indic languages and global scale. By focusing on language diversity, cultural context and ethical AI, Soket AI aims to develop models that recognise and respond across many languages, while delivering enterprise-grade capabilities for sectors such as defence, healthcare, education and governance.
Soket AI
Soket AI is an Indian deep-tech startup building sovereign, multilingual foundational AI models and real-time voice/speech APIs designed for Indic languages and global scale. By focusing on language diversity, cultural context and ethical AI, Soket AI aims to develop models that recognise and respond across many languages, while delivering enterprise-grade capabilities for sectors such as defence, healthcare, education and governance.

Pruna AI
Pruna.ai is an AI optimization engine designed to make machine learning models faster, smaller, cheaper, and greener with minimal overhead. It leverages advanced compression algorithms like pruning, quantization, distillation, caching, and compilation to reduce model size and accelerate inference times. The platform supports various AI models including large language models, vision transformers, and speech recognition models, making it ideal for real-time applications such as autonomous systems and recommendation engines. Pruna.ai aims to lower computational costs, decrease energy consumption, and improve deployment scalability across cloud and on-premise environments while ensuring minimal loss of model quality.
Pruna AI
Pruna.ai is an AI optimization engine designed to make machine learning models faster, smaller, cheaper, and greener with minimal overhead. It leverages advanced compression algorithms like pruning, quantization, distillation, caching, and compilation to reduce model size and accelerate inference times. The platform supports various AI models including large language models, vision transformers, and speech recognition models, making it ideal for real-time applications such as autonomous systems and recommendation engines. Pruna.ai aims to lower computational costs, decrease energy consumption, and improve deployment scalability across cloud and on-premise environments while ensuring minimal loss of model quality.
Pruna AI
Pruna.ai is an AI optimization engine designed to make machine learning models faster, smaller, cheaper, and greener with minimal overhead. It leverages advanced compression algorithms like pruning, quantization, distillation, caching, and compilation to reduce model size and accelerate inference times. The platform supports various AI models including large language models, vision transformers, and speech recognition models, making it ideal for real-time applications such as autonomous systems and recommendation engines. Pruna.ai aims to lower computational costs, decrease energy consumption, and improve deployment scalability across cloud and on-premise environments while ensuring minimal loss of model quality.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
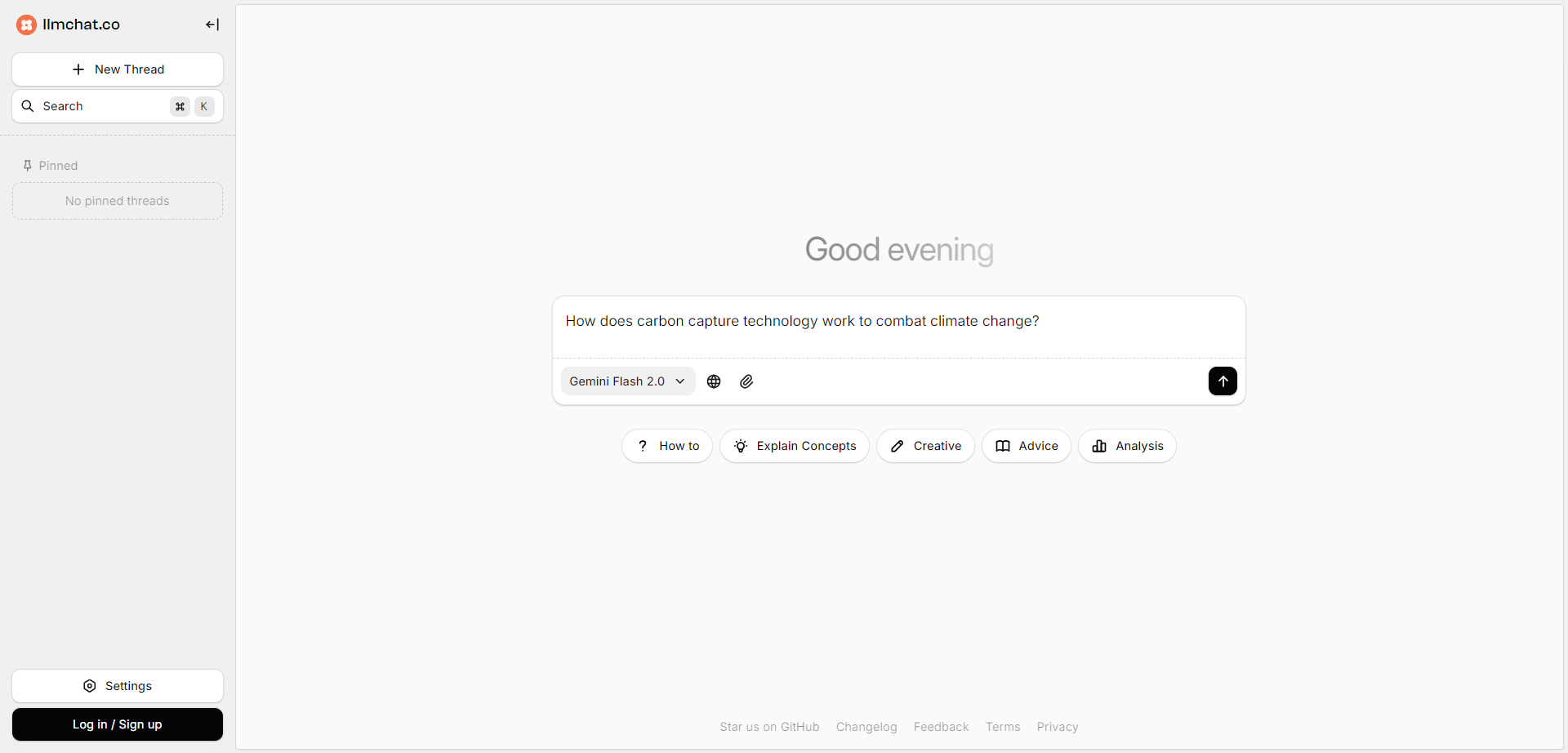

LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.

Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai