
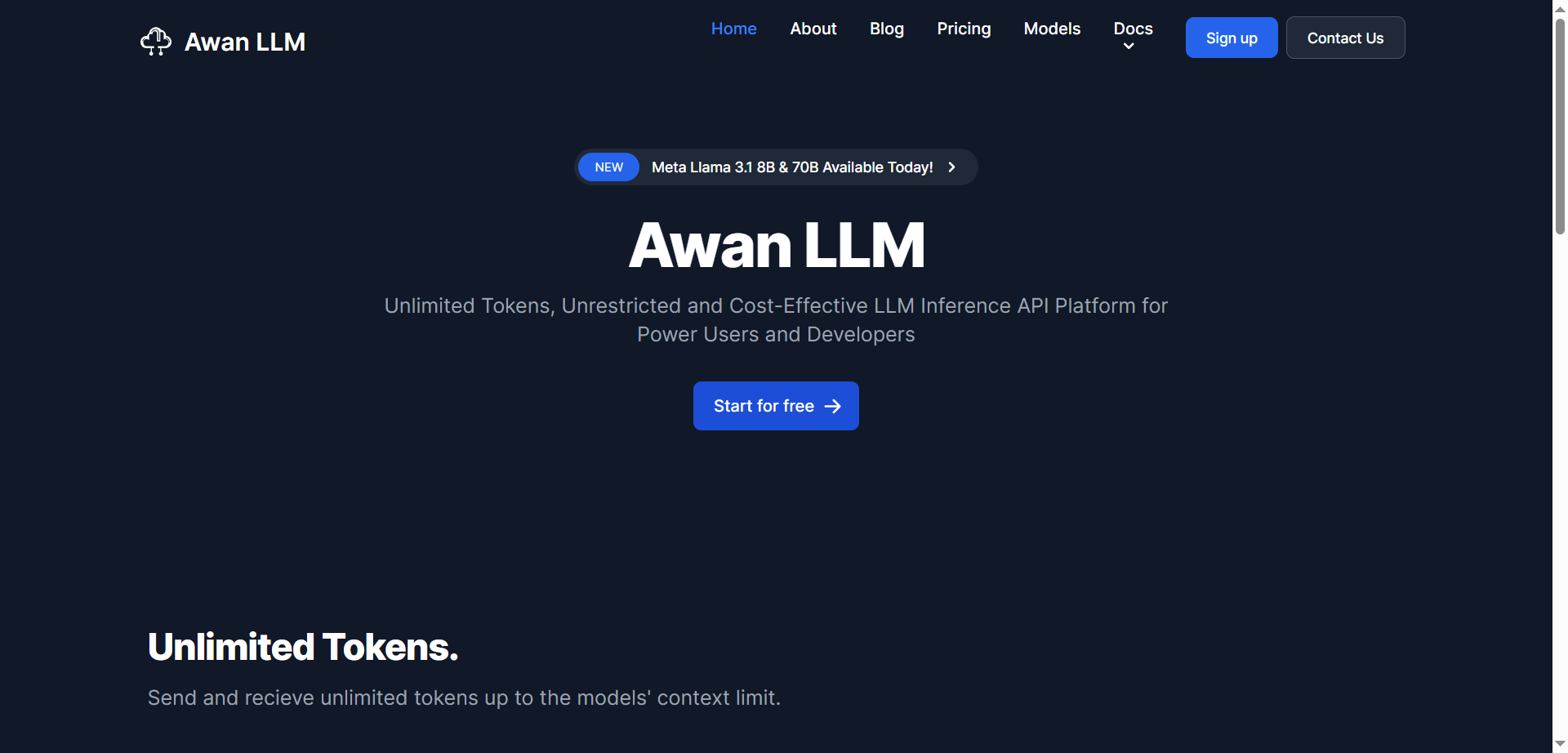
- Developers & Power Users: Access unrestricted LLM models for building advanced AI applications and services.
- Companies & Startups: Integrate cost-effective AI inference APIs without token-based pricing concerns.
- Data Scientists: Process large datasets quickly using unlimited token generation.
- Coders & Programmers: Get limitless code completion and debugging support for faster development.
- AI Enthusiasts & Creators: Explore roleplaying and interactive AI experiences without restrictions or censorship.
How to Use Awan LLM?
- Sign Up for an Account: Register on the platform to access unlimited token usage.
- Explore Quick-Start Guides: Follow documentation to easily integrate API endpoints into your projects.
- Use Assistant or AI Agents: Leverage ready-to-use AI functionalities for various tasks.
- Scale with Unlimited Tokens: Run heavy workloads and large applications without worrying about token limits.
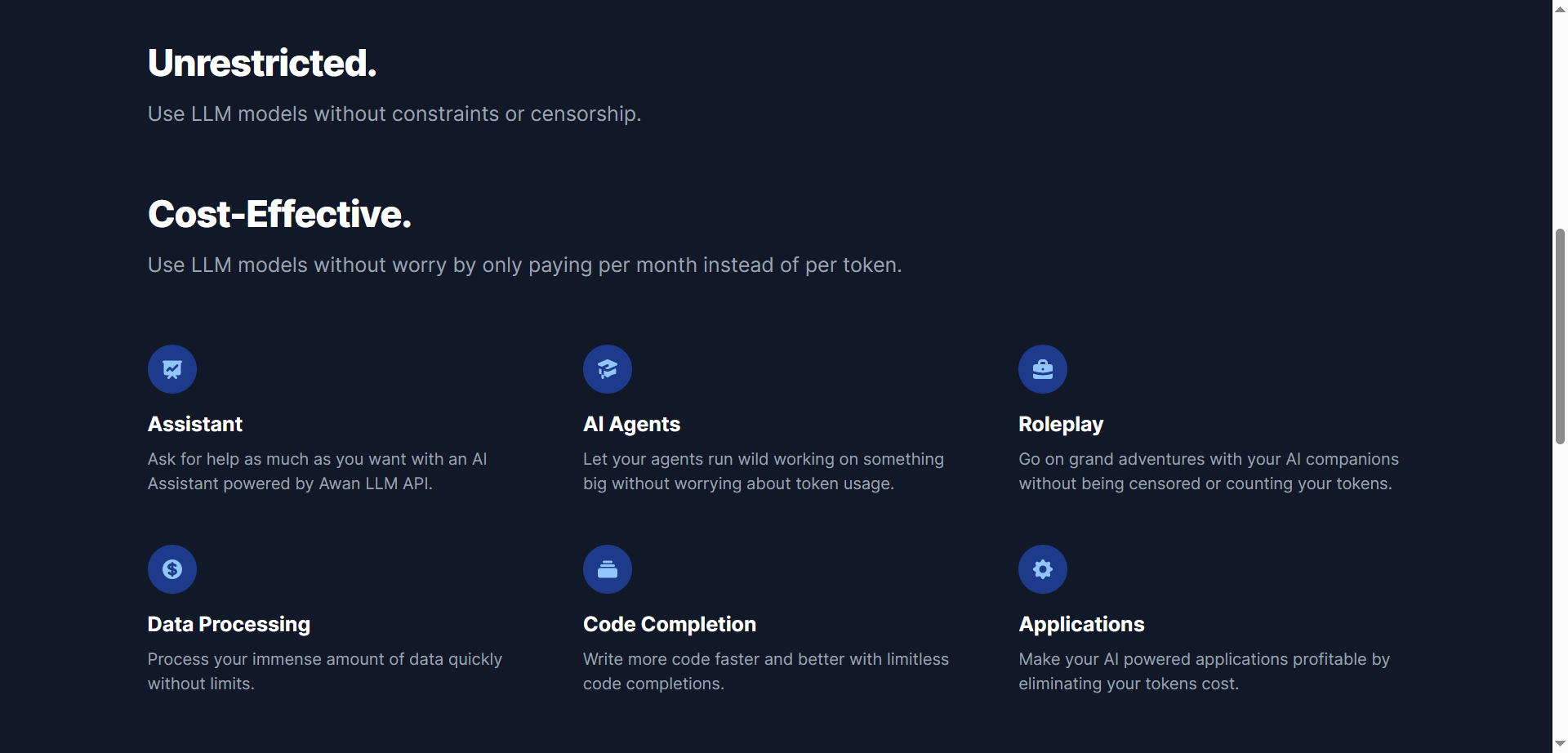
- Unlimited Token Generation: Offers infinite tokens for cost-effective, large-scale AI usage.
- No Censorship or Constraints: Supports unrestricted access to LLMs for diverse applications.
- Private Data Centers & GPUs: Owns infrastructure for scalability and cost efficiency.
- Monthly Subscription Pricing: Fixed monthly costs without per-token billing surprises.
- Wide Use Case Support: From assistants to code completion and interactive roleplay experiences.
- True unlimited token model ideal for heavy users.
- No logging of prompts or generated content for privacy.
- Cost-efficiency compared to cloud GPU rentals or self-hosting.
- Flexible API supporting various AI-powered applications.
- Request rate limits are enforced, which may impact very high volume use.
- Platform may require some technical knowledge to integrate effectively.
- Limited model choices unless new ones are requested.
- Monthly fee model might be less attractive for very low usage users.
Lite
$ 0.00
20 req/minute
Small Models
200 req/day
Medium Models
10 req/day
Large Models
10 req/day
Core
$ 5.00
20 req/minute
Small Models
5,000 req/day
Medium Models
3,000 req/day
Large Models
10 req/day
Plus
$ 10.00
50 req/minute
Small Models
10,000 req/day
Medium Models
6,000 req/day
Large Models
2,000 req/day
Pro
$ 20.00
Parallel requests!
100 req/minute
Small Models
80,000 req/day
Medium Models
40,000 req/day
Large Models
30,000 req/day
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
Inweave
Inweave is an AI tool designed to help startups and scaleups automate their workflows. It allows users to create, deploy, and manage tailored AI assistants for a variety of tasks and business processes. By offering flexible model selection and robust API support, Inweave enables businesses to seamlessly integrate AI into their existing applications, boosting productivity and efficiency.
Inweave
Inweave is an AI tool designed to help startups and scaleups automate their workflows. It allows users to create, deploy, and manage tailored AI assistants for a variety of tasks and business processes. By offering flexible model selection and robust API support, Inweave enables businesses to seamlessly integrate AI into their existing applications, boosting productivity and efficiency.
Inweave
Inweave is an AI tool designed to help startups and scaleups automate their workflows. It allows users to create, deploy, and manage tailored AI assistants for a variety of tasks and business processes. By offering flexible model selection and robust API support, Inweave enables businesses to seamlessly integrate AI into their existing applications, boosting productivity and efficiency.
LLM Gateway
LLM Gateway is a unified API gateway designed to simplify working with large language models (LLMs) from multiple providers by offering a single, OpenAI-compatible endpoint. Whether using OpenAI, Anthropic, Google Vertex AI, or others, developers can route, monitor, and manage requests—all without altering existing code. Available as an open-source self-hosted option (MIT-licensed) or hosted service, it combines powerful features for analytics, cost optimization, and performance management—all under one roof.
LLM Gateway
LLM Gateway is a unified API gateway designed to simplify working with large language models (LLMs) from multiple providers by offering a single, OpenAI-compatible endpoint. Whether using OpenAI, Anthropic, Google Vertex AI, or others, developers can route, monitor, and manage requests—all without altering existing code. Available as an open-source self-hosted option (MIT-licensed) or hosted service, it combines powerful features for analytics, cost optimization, and performance management—all under one roof.
LLM Gateway
LLM Gateway is a unified API gateway designed to simplify working with large language models (LLMs) from multiple providers by offering a single, OpenAI-compatible endpoint. Whether using OpenAI, Anthropic, Google Vertex AI, or others, developers can route, monitor, and manage requests—all without altering existing code. Available as an open-source self-hosted option (MIT-licensed) or hosted service, it combines powerful features for analytics, cost optimization, and performance management—all under one roof.

Radal AI
Radal AI is a no-code platform designed to simplify the training and deployment of small language models (SLMs) without requiring engineering or MLOps expertise. With an intuitive visual interface, you can drag your data, interact with an AI copilot, and train models with a single click. Trained models can be exported in quantized form for edge or local deployment, and seamlessly pushed to Hugging Face for easy sharing and versioning. Radal enables rapid iteration on custom models—making AI accessible to startups, researchers, and teams building domain-specific intelligence.
Radal AI
Radal AI is a no-code platform designed to simplify the training and deployment of small language models (SLMs) without requiring engineering or MLOps expertise. With an intuitive visual interface, you can drag your data, interact with an AI copilot, and train models with a single click. Trained models can be exported in quantized form for edge or local deployment, and seamlessly pushed to Hugging Face for easy sharing and versioning. Radal enables rapid iteration on custom models—making AI accessible to startups, researchers, and teams building domain-specific intelligence.
Radal AI
Radal AI is a no-code platform designed to simplify the training and deployment of small language models (SLMs) without requiring engineering or MLOps expertise. With an intuitive visual interface, you can drag your data, interact with an AI copilot, and train models with a single click. Trained models can be exported in quantized form for edge or local deployment, and seamlessly pushed to Hugging Face for easy sharing and versioning. Radal enables rapid iteration on custom models—making AI accessible to startups, researchers, and teams building domain-specific intelligence.
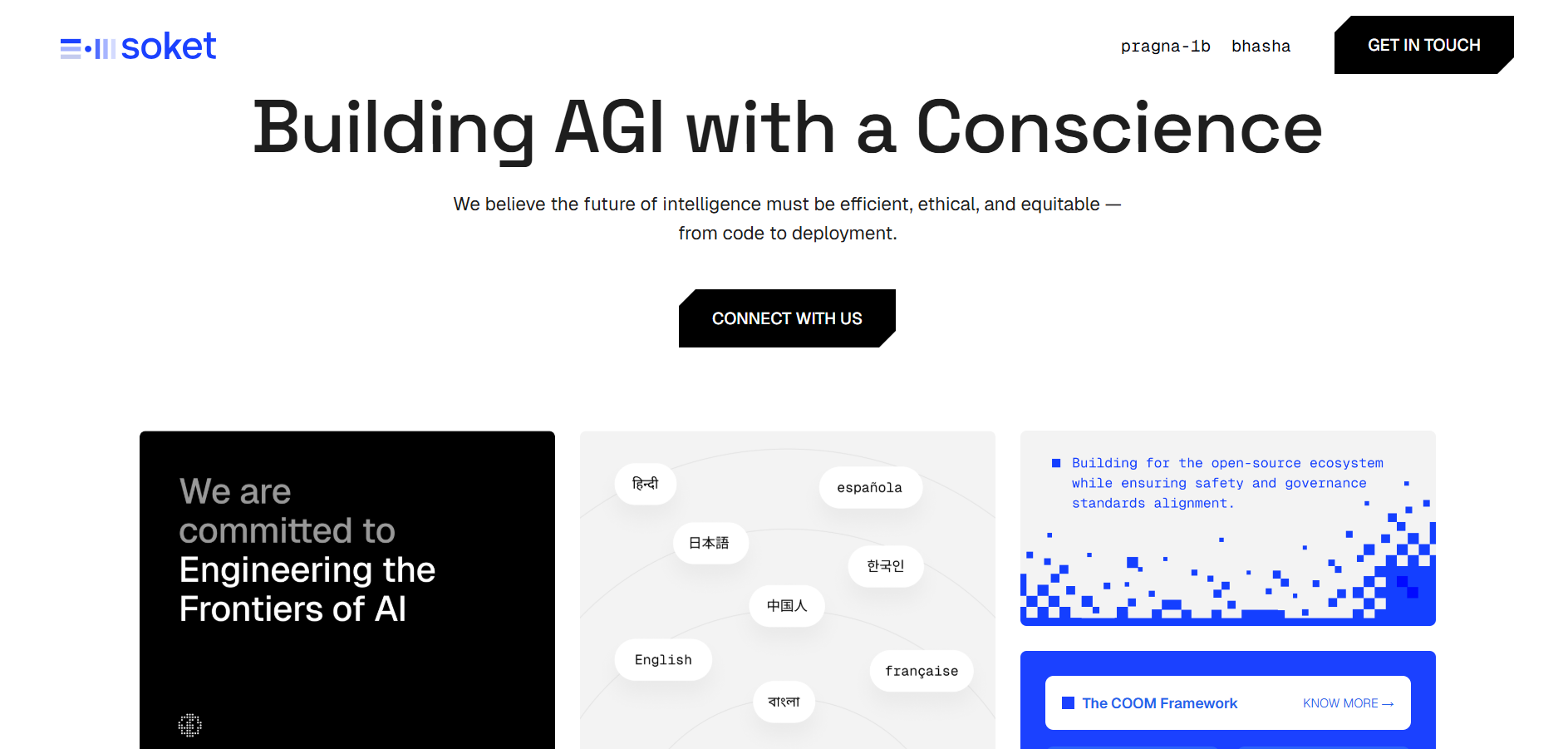
Soket AI
Soket AI is an Indian deep-tech startup building sovereign, multilingual foundational AI models and real-time voice/speech APIs designed for Indic languages and global scale. By focusing on language diversity, cultural context and ethical AI, Soket AI aims to develop models that recognise and respond across many languages, while delivering enterprise-grade capabilities for sectors such as defence, healthcare, education and governance.
Soket AI
Soket AI is an Indian deep-tech startup building sovereign, multilingual foundational AI models and real-time voice/speech APIs designed for Indic languages and global scale. By focusing on language diversity, cultural context and ethical AI, Soket AI aims to develop models that recognise and respond across many languages, while delivering enterprise-grade capabilities for sectors such as defence, healthcare, education and governance.
Soket AI
Soket AI is an Indian deep-tech startup building sovereign, multilingual foundational AI models and real-time voice/speech APIs designed for Indic languages and global scale. By focusing on language diversity, cultural context and ethical AI, Soket AI aims to develop models that recognise and respond across many languages, while delivering enterprise-grade capabilities for sectors such as defence, healthcare, education and governance.
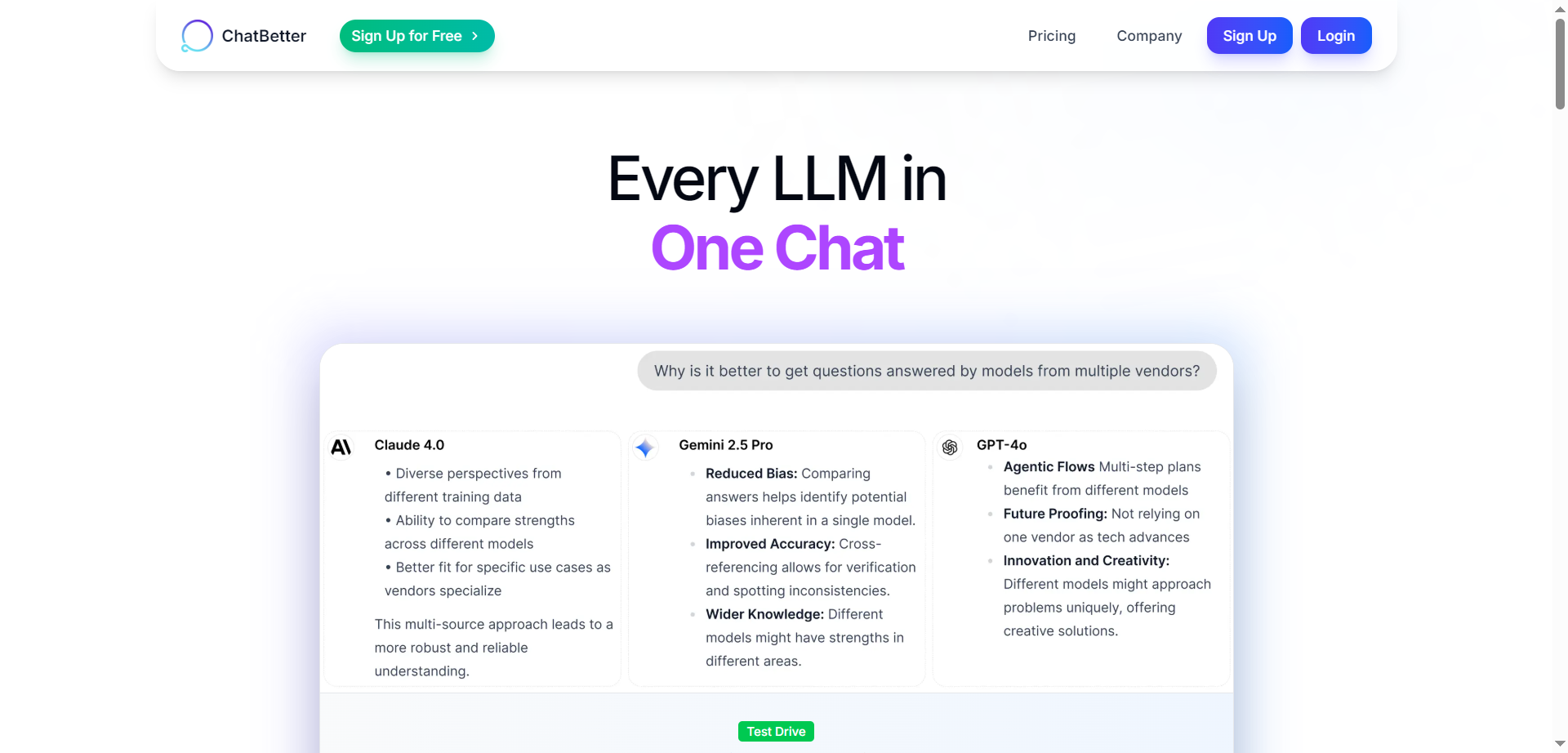

ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
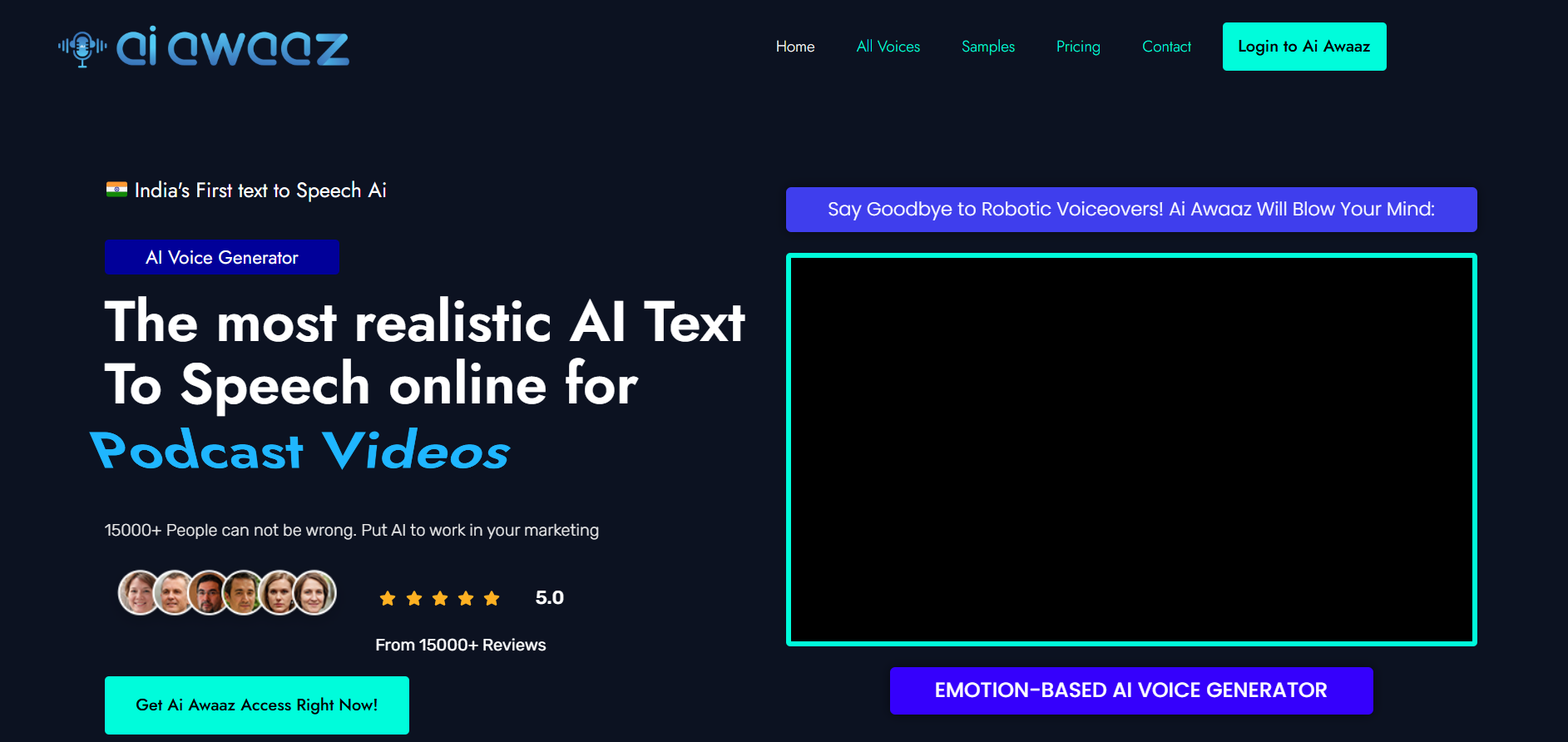
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.


Supernovas AI LLM
Supernovas AI is an all-in-one AI chat workspace designed to empower teams with seamless access to the best AI models and data integration. It supports all major AI providers including OpenAI, Anthropic, Google Gemini, Azure OpenAI, and more, allowing users to prompt any AI model through a single subscription and platform. Supernovas AI enables building intelligent AI assistants that can access private data, databases, and APIs via Model Context Protocol (MCP). It offers advanced prompting tools, custom prompt templates, and integrated AI image generation and editing. The platform supports analyzing a wide range of document types such as PDFs, spreadsheets, legal documents, and images to generate rich responses including text and visuals, boosting productivity across teams worldwide.
Supernovas AI LLM
Supernovas AI is an all-in-one AI chat workspace designed to empower teams with seamless access to the best AI models and data integration. It supports all major AI providers including OpenAI, Anthropic, Google Gemini, Azure OpenAI, and more, allowing users to prompt any AI model through a single subscription and platform. Supernovas AI enables building intelligent AI assistants that can access private data, databases, and APIs via Model Context Protocol (MCP). It offers advanced prompting tools, custom prompt templates, and integrated AI image generation and editing. The platform supports analyzing a wide range of document types such as PDFs, spreadsheets, legal documents, and images to generate rich responses including text and visuals, boosting productivity across teams worldwide.
Supernovas AI LLM
Supernovas AI is an all-in-one AI chat workspace designed to empower teams with seamless access to the best AI models and data integration. It supports all major AI providers including OpenAI, Anthropic, Google Gemini, Azure OpenAI, and more, allowing users to prompt any AI model through a single subscription and platform. Supernovas AI enables building intelligent AI assistants that can access private data, databases, and APIs via Model Context Protocol (MCP). It offers advanced prompting tools, custom prompt templates, and integrated AI image generation and editing. The platform supports analyzing a wide range of document types such as PDFs, spreadsheets, legal documents, and images to generate rich responses including text and visuals, boosting productivity across teams worldwide.
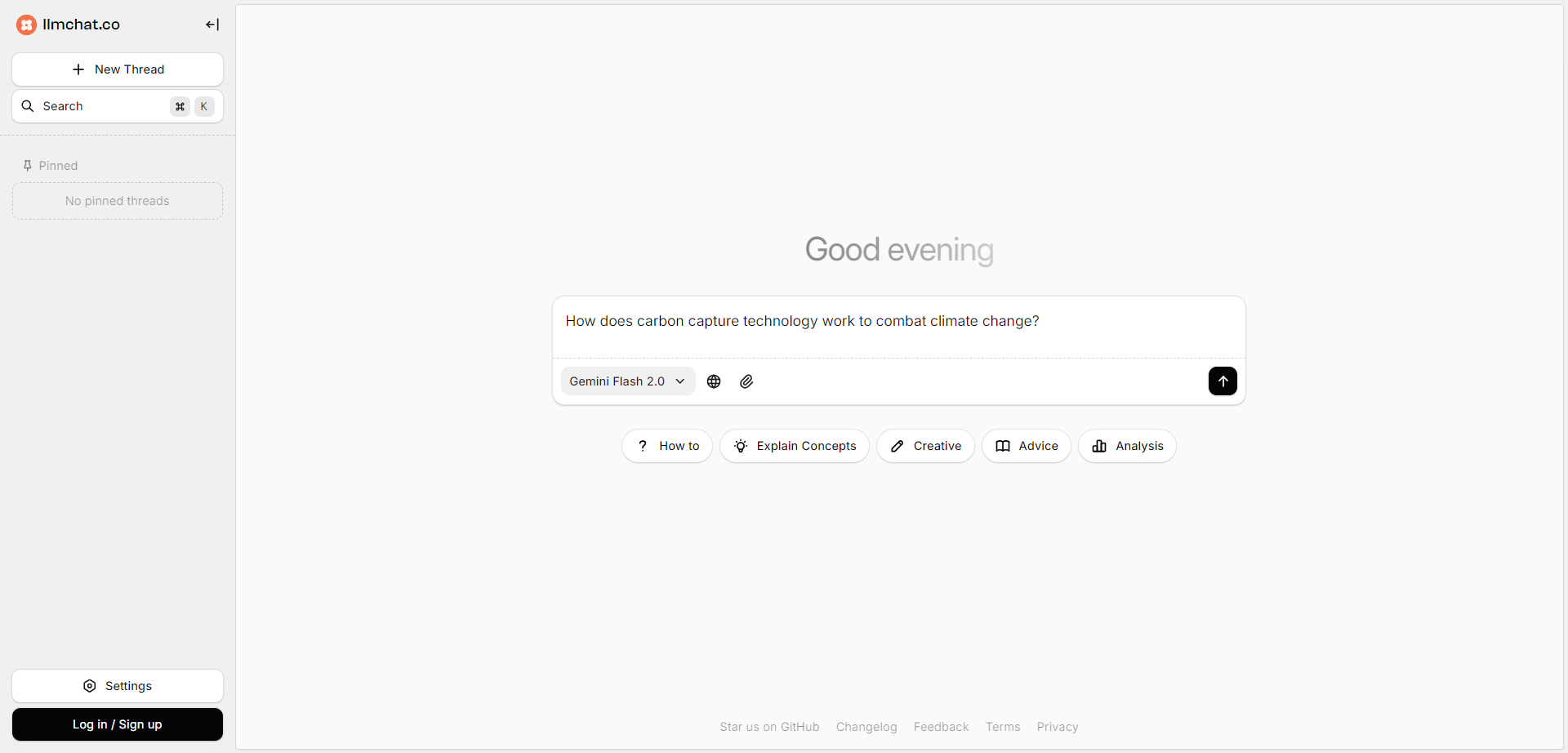

LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.

LLM as-a-service
LLM.co LLM-as-a-Service (LLMaaS) is a secure, enterprise-grade AI platform that provides private and fully managed large language model deployments tailored to an organization’s specific industry, workflows, and data. Unlike public LLM APIs, each client receives a dedicated, single-tenant model hosted in private clouds or virtual private clouds (VPCs), ensuring complete data privacy and compliance. The platform offers model fine-tuning on proprietary internal documents, semantic search, multi-document Q&A, custom AI agents, contract review, and offline AI capabilities for regulated industries. It removes infrastructure burdens by handling deployment, scaling, and monitoring, while enabling businesses to customize models for domain-specific language, regulatory compliance, and unique operational needs.
LLM as-a-service
LLM.co LLM-as-a-Service (LLMaaS) is a secure, enterprise-grade AI platform that provides private and fully managed large language model deployments tailored to an organization’s specific industry, workflows, and data. Unlike public LLM APIs, each client receives a dedicated, single-tenant model hosted in private clouds or virtual private clouds (VPCs), ensuring complete data privacy and compliance. The platform offers model fine-tuning on proprietary internal documents, semantic search, multi-document Q&A, custom AI agents, contract review, and offline AI capabilities for regulated industries. It removes infrastructure burdens by handling deployment, scaling, and monitoring, while enabling businesses to customize models for domain-specific language, regulatory compliance, and unique operational needs.
LLM as-a-service
LLM.co LLM-as-a-Service (LLMaaS) is a secure, enterprise-grade AI platform that provides private and fully managed large language model deployments tailored to an organization’s specific industry, workflows, and data. Unlike public LLM APIs, each client receives a dedicated, single-tenant model hosted in private clouds or virtual private clouds (VPCs), ensuring complete data privacy and compliance. The platform offers model fine-tuning on proprietary internal documents, semantic search, multi-document Q&A, custom AI agents, contract review, and offline AI capabilities for regulated industries. It removes infrastructure burdens by handling deployment, scaling, and monitoring, while enabling businesses to customize models for domain-specific language, regulatory compliance, and unique operational needs.
Emby AI
Emby.ai is a secure EU-hosted AI platform and API service that lets developers and businesses access powerful open-source large language models (LLMs) like Llama, DeepSeek, and others with predictable pricing, transparent billing, and strong privacy protections in compliance with GDPR. It provides a way to build AI-powered applications by offering an OpenAI-compatible API and scalable token plans, all hosted in Amsterdam.
Emby AI
Emby.ai is a secure EU-hosted AI platform and API service that lets developers and businesses access powerful open-source large language models (LLMs) like Llama, DeepSeek, and others with predictable pricing, transparent billing, and strong privacy protections in compliance with GDPR. It provides a way to build AI-powered applications by offering an OpenAI-compatible API and scalable token plans, all hosted in Amsterdam.
Emby AI
Emby.ai is a secure EU-hosted AI platform and API service that lets developers and businesses access powerful open-source large language models (LLMs) like Llama, DeepSeek, and others with predictable pricing, transparent billing, and strong privacy protections in compliance with GDPR. It provides a way to build AI-powered applications by offering an OpenAI-compatible API and scalable token plans, all hosted in Amsterdam.
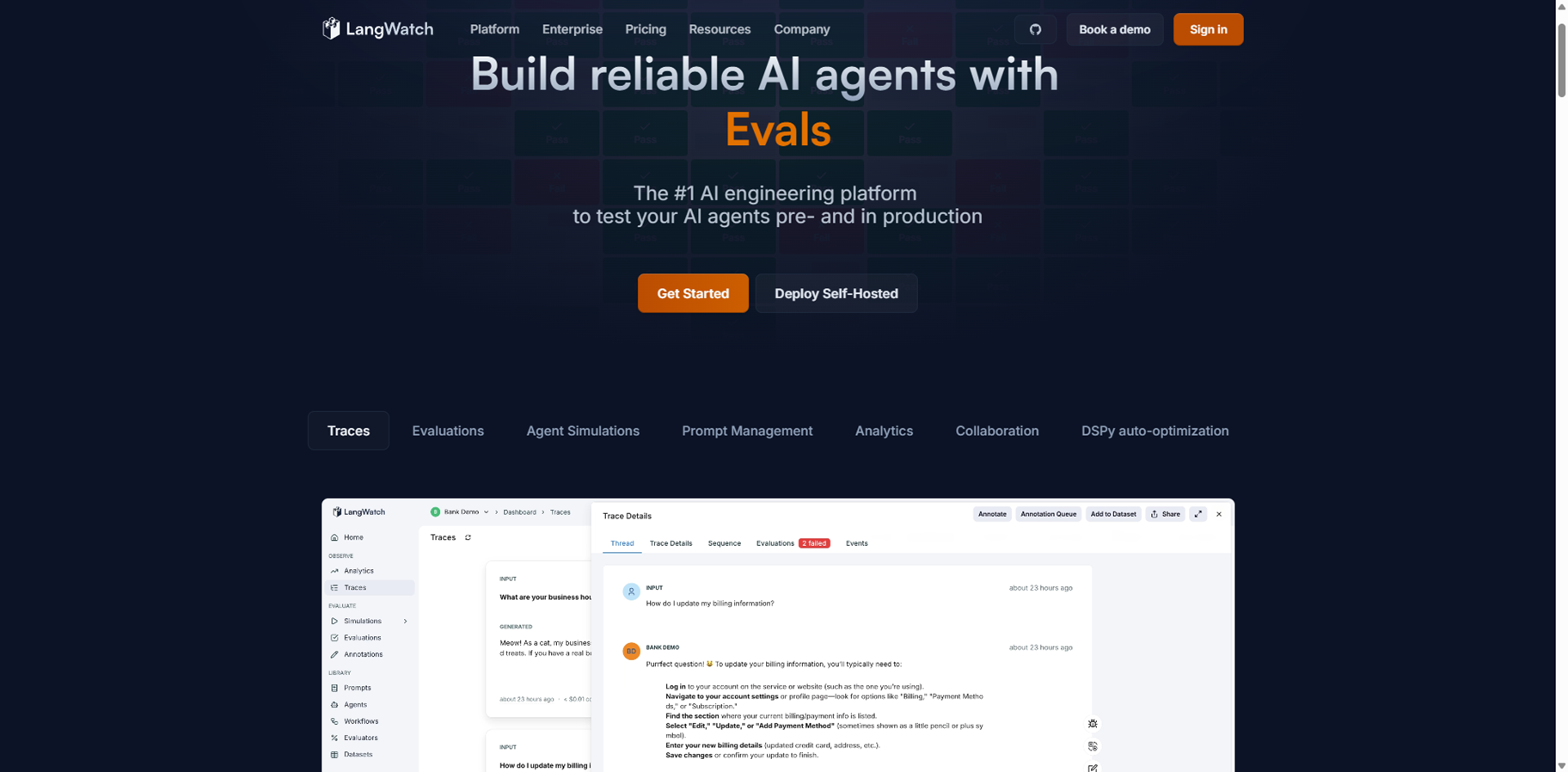

LangWatch
LangWatch.ai is the leading AI engineering platform built specifically to test, evaluate, and monitor AI agents from prototype through production, helping thousands of developers ship reliable complex AI without guesswork. It creates a continuous quality loop with tools like traces, custom evaluations, agent simulations, prompt management, analytics, collaboration features, and DSPy auto-optimization, boasting 400k monthly installs, 500k daily evaluations to curb hallucinations, and 5k GitHub stars. Teams use it to build prompts and models with version control and safe rollouts, run batch tests and synthetic conversations across scenarios, and track every change's impact programmatically or via UI. Fully open-source with OpenTelemetry integration, it works with any LLM, agent framework, or model via simple Python/TypeScript installs, offering self-hosting, enterprise security like ISO27001/SOC2, and no data lock-in for seamless tech stack fit.
LangWatch
LangWatch.ai is the leading AI engineering platform built specifically to test, evaluate, and monitor AI agents from prototype through production, helping thousands of developers ship reliable complex AI without guesswork. It creates a continuous quality loop with tools like traces, custom evaluations, agent simulations, prompt management, analytics, collaboration features, and DSPy auto-optimization, boasting 400k monthly installs, 500k daily evaluations to curb hallucinations, and 5k GitHub stars. Teams use it to build prompts and models with version control and safe rollouts, run batch tests and synthetic conversations across scenarios, and track every change's impact programmatically or via UI. Fully open-source with OpenTelemetry integration, it works with any LLM, agent framework, or model via simple Python/TypeScript installs, offering self-hosting, enterprise security like ISO27001/SOC2, and no data lock-in for seamless tech stack fit.
LangWatch
LangWatch.ai is the leading AI engineering platform built specifically to test, evaluate, and monitor AI agents from prototype through production, helping thousands of developers ship reliable complex AI without guesswork. It creates a continuous quality loop with tools like traces, custom evaluations, agent simulations, prompt management, analytics, collaboration features, and DSPy auto-optimization, boasting 400k monthly installs, 500k daily evaluations to curb hallucinations, and 5k GitHub stars. Teams use it to build prompts and models with version control and safe rollouts, run batch tests and synthetic conversations across scenarios, and track every change's impact programmatically or via UI. Fully open-source with OpenTelemetry integration, it works with any LLM, agent framework, or model via simple Python/TypeScript installs, offering self-hosting, enterprise security like ISO27001/SOC2, and no data lock-in for seamless tech stack fit.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai