
- Developers & Engineers: Handle massive text/code/video datasets, build advanced assistants, perform multimodal reasoning.
- Researchers & Analysts: Summarize entire books, analyze multimedia documents, and run code-heavy tasks within one prompt.
- Enterprise & API Users: Integrate through Meta AI, Vertex AI, AWS SageMaker, Databricks, or Hugging Face.
- Content & Language Teams: Process multilingual content, image-based QA, and translation across 12+ languages.
- Open-Source Community: Download Scout and Maverick to experiment and build applications (with certain usage restrictions).
How to Use Meta Llama 4?
- Access the Models: Scout and Maverick are available via Meta’s platforms and Hugging Face; Behemoth will be released from LlamaCon.
- Choose a Variant: Use Scout for extreme long-context tasks, Maverick for balanced reasoning & multimodal use, or await Behemoth for peak performance.
- Input Text or Images: Models accept mixed modalities with context windows up to 10M tokens (Scout) or 1M tokens (Maverick).
- Run Tasks: Perform summarization, coding, document analysis, image question answering, or complex reasoning.
- Deploy Safely: Use Llama Guard, Prompt Guard, and watermarked outputs as available; comply with license for larger platforms.
- Mixture-of-Experts Efficiency: Only relevant expert subnetworks are activated, enabling high performance with fewer resources.
- Record Context Windows: Scout supports up to 10 million tokens; no other open model approaches this scale.
- Native Multimodality: Joint training on text, images, and video enables coherent understanding across media types.
- Benchmark-Topping: Maverick rivals GPT-4o, Gemini 2.0 Flash, and DeepSeek-V3 on reasoning, code, and image tasks. Scout outperforms peers in efficiency benchmarks.
- Open-Weight with Guardrails: Scout and Maverick weights are publicly available (with usage limits); safety features include content filters and watermarking.
- Long-context support up to 10 million tokens
- Superior multimodal performance with joint text-image/video
- Efficient architecture yields strong performance per compute
- Open-source access fosters innovation
- Strong safety tooling with Llama Guard and watermarking
- Behemoth is still in development—limited for now
- License restricts commercial use for very large platforms
- Early releases may exhibit inconsistencies or minor artifacts
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.

Poe AI
Poe.com is a comprehensive AI chatbot aggregation platform developed by Quora, providing users with unified access to a wide range of conversational AI models from various leading providers, including OpenAI, Anthropic, Google, and Meta. It simplifies the process of discovering and interacting with different AI chatbots and also empowers users to create and monetize their own custom AI bots.
Poe AI
Poe.com is a comprehensive AI chatbot aggregation platform developed by Quora, providing users with unified access to a wide range of conversational AI models from various leading providers, including OpenAI, Anthropic, Google, and Meta. It simplifies the process of discovering and interacting with different AI chatbots and also empowers users to create and monetize their own custom AI bots.
Poe AI
Poe.com is a comprehensive AI chatbot aggregation platform developed by Quora, providing users with unified access to a wide range of conversational AI models from various leading providers, including OpenAI, Anthropic, Google, and Meta. It simplifies the process of discovering and interacting with different AI chatbots and also empowers users to create and monetize their own custom AI bots.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.

DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.

Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.

Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.

ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
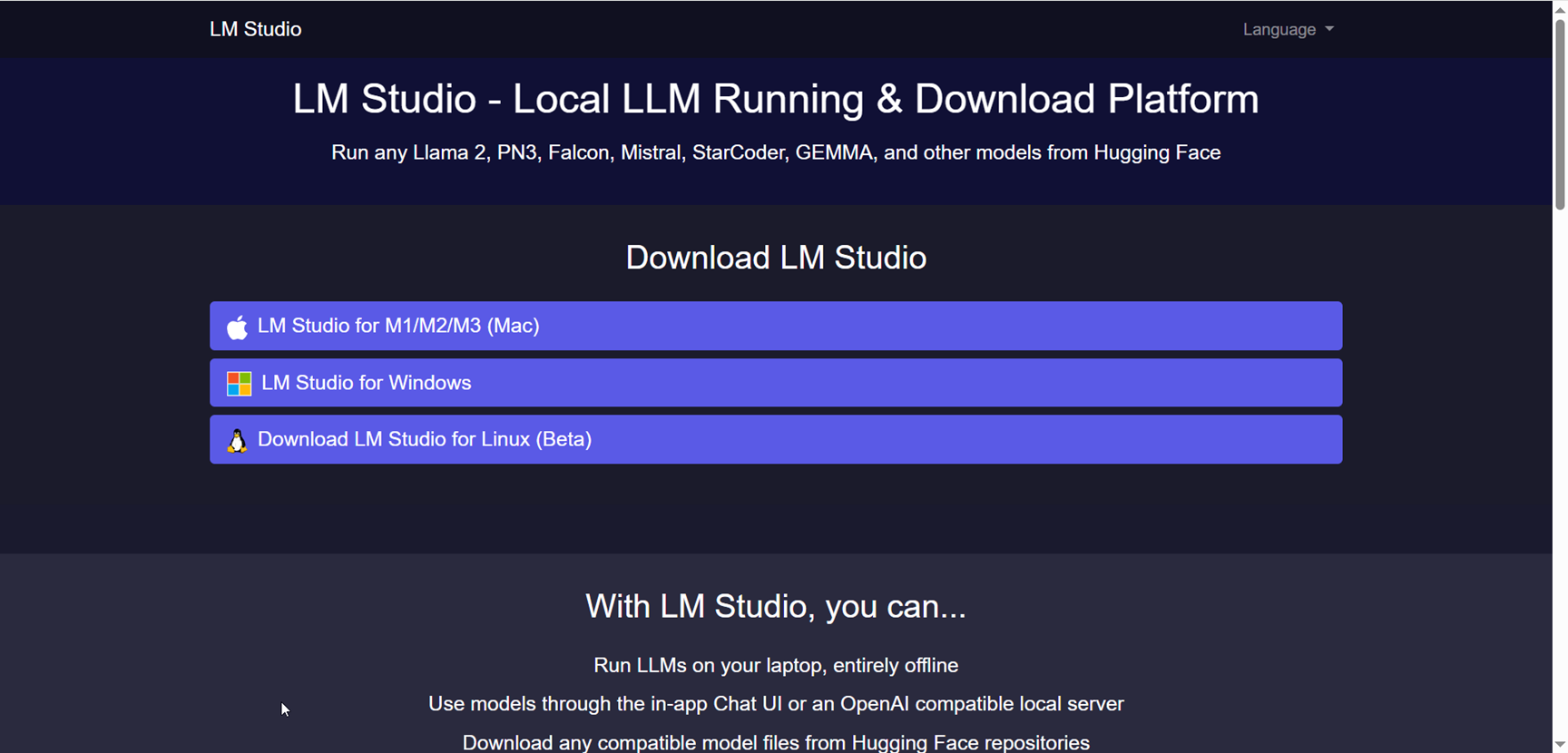
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
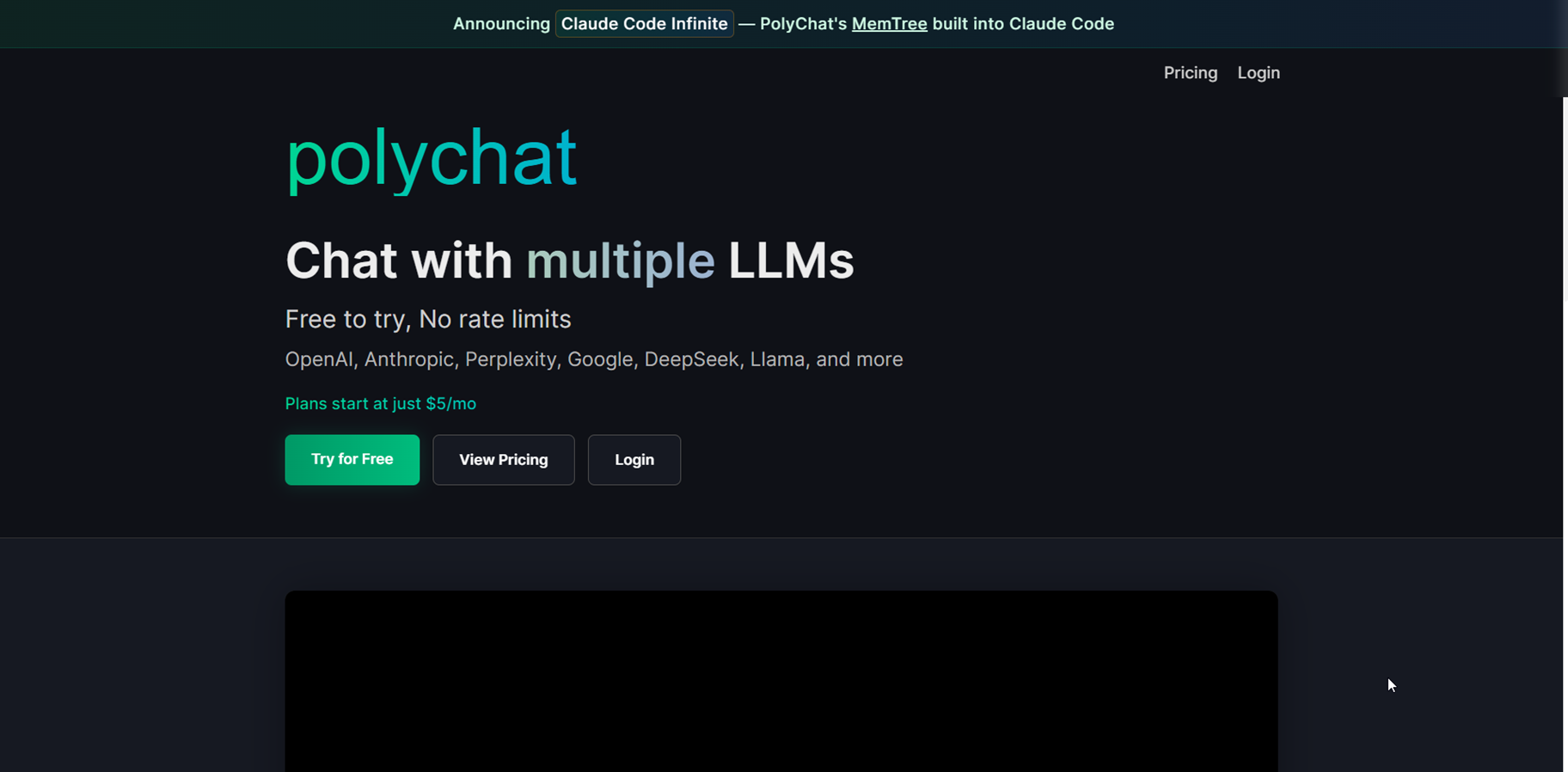

polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai