
- Developers & Engineers: Ideal for multi-document summarization, long-form code reasoning, and large-scale logic on modest hardware.
- Researchers & Analysts: Process extensive datasets, logs, or transcripts in a single pass.
- Educators & Students: Work through long documents, codebases, or multi-modal tasks with ease.
- Enterprises & SMEs: Deploy reasoning systems that can handle massive context affordably.
- Startups & Speed-Focused Teams: Get flagship-class performance on a single GPU, ideal for rapid prototyping.
How to Use Llama 4 Scout?
- Deploy on Single H100 GPU: Officially supported with int4 or 8-bit quantization.
- Access via API or Cloud: Available through Hugging Face, AWS Bedrock, SageMaker, IBM Watsonx, or Groq Cloud.
- Send Long Prompts: Submit text, code, or images in a context window that spans up to 10 million tokens.
- Use Mix of Inputs: Handles multimodal early-fusion—process images, video, and text natively.
- Optimize with Quantized Weights: Take advantage of efficient mixed-precision formats to save resources.
- Unmatched Context Capacity: 10 million tokens far exceed any other model's capability.
- MoE Efficiency: 16 experts activate per token, balancing scalability and compute from MoE design.
- Flagship-Level Performance: Outperforms top open models in reasoning, coding, document QA, image analysis, and multimodal benchmarks.
- Runs on a Single H100: Accessible to many developers and businesses without clustered infrastructure.
- Open-Weight and Multi-Platform Reach: Weights available via Hugging Face, Bedrock, SageMaker, IBM, and Groq.
- Unprecedented 10M-token context—ideal for ultra-long tasks
- Strong benchmark performance across domains
- Efficient performance on a single GPU with quantization
- Truly multimodal abilities—early fusion across text, image, video
- Widely deployable with open-weight license and cloud integration
- Model’s openness restricted: commercial entities over 700 M users require permission
- Expert-mixing complexity adds deployment hurdles
- Very large context may be overkill or hard to manage effectively
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.

GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
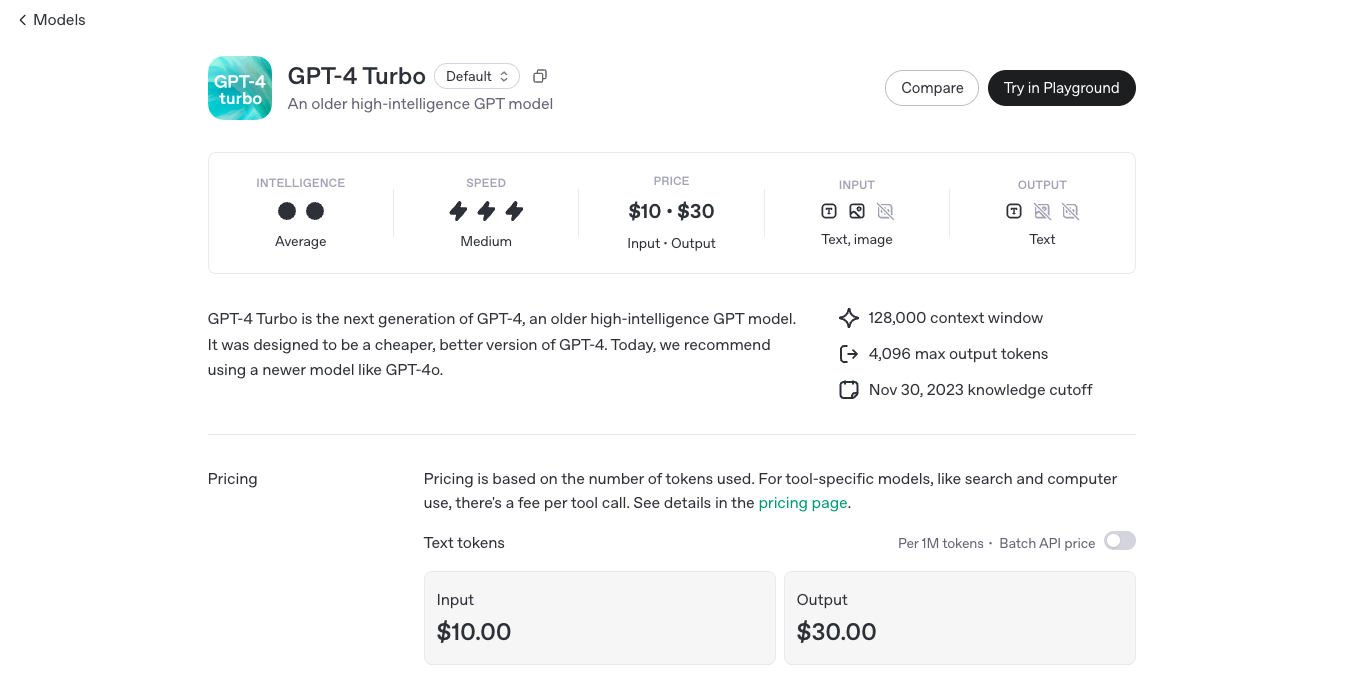
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.

Claude Sonnet 4
Claude Sonnet 4 is Anthropic’s hybrid‑reasoning AI model that combines fast, near-instant responses with visible, step‑by‑step thinking in a single model. It delivers frontier-level performance in coding, reasoning, vision, and tool usage—while offering a massive 200K token context window and cost-effective pricing
Claude Sonnet 4
Claude Sonnet 4 is Anthropic’s hybrid‑reasoning AI model that combines fast, near-instant responses with visible, step‑by‑step thinking in a single model. It delivers frontier-level performance in coding, reasoning, vision, and tool usage—while offering a massive 200K token context window and cost-effective pricing
Claude Sonnet 4
Claude Sonnet 4 is Anthropic’s hybrid‑reasoning AI model that combines fast, near-instant responses with visible, step‑by‑step thinking in a single model. It delivers frontier-level performance in coding, reasoning, vision, and tool usage—while offering a massive 200K token context window and cost-effective pricing

Claude Opus 4
Claude Opus 4 is Anthropic’s most powerful, frontier-capability AI model optimized for deep reasoning and advanced software engineering. It sets industry-leading scores in coding (SWE-bench: 72.5 %; Terminal-bench: 43.2 %) and can sustain autonomous workflows—like an open-source refactor—for up to seven hours straight
Claude Opus 4
Claude Opus 4 is Anthropic’s most powerful, frontier-capability AI model optimized for deep reasoning and advanced software engineering. It sets industry-leading scores in coding (SWE-bench: 72.5 %; Terminal-bench: 43.2 %) and can sustain autonomous workflows—like an open-source refactor—for up to seven hours straight
Claude Opus 4
Claude Opus 4 is Anthropic’s most powerful, frontier-capability AI model optimized for deep reasoning and advanced software engineering. It sets industry-leading scores in coding (SWE-bench: 72.5 %; Terminal-bench: 43.2 %) and can sustain autonomous workflows—like an open-source refactor—for up to seven hours straight

DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.

DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.

DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.

Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.

polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai