
- Developers & Engineers: Integrate powerful reasoning and coding LLM into production without heavy MoE complexity.
- Researchers & Students: Study high-quality chain-of-thought reasoning in a compact, transparent model.
- Startups & Enterprises: Deploy reasoning-first LLM on consumer-grade hardware with quantization.
- Open-Source Enthusiasts: Modify and tinker freely; MIT license supports innovation and redistribution.
- Benchmarkers: Compare small-but-mighty performance against dense and MoE peers in math and code.
How to Use DeepSeek R1 0528 – Qwen3-8B?
- Load the Model: Access via Hugging Face (`deepseek-ai/DeepSeek-R1-0528-Qwen3-8B`) or inference frameworks like Ollama/vLLM.
- Use Chain-of-Thought Prompts: Provide reasoning prompts at temperature
0.6, top_p0.95 for best clarity. - Support up to 32K Tokens: Handles long math problems, code debugging, logic chains.
- Quantize for Efficiency: Use GGUF / Q4_K formats to run on setups with ~20–40GB RAM or H100-class GPUs.
- Call via API: Also available through DeepSeek API with DeepThink mode enabled.
- 10% Over Qwen3 8B: Surpasses base Qwen3-8B by +10% on AIME 2024 and matches Qwen3-235B for chain-of-thought.
- Efficient Yet Deep: Brings flagship-level reasoning into an 8B model—ideal for limited hardware.
- Easy to Deploy & Customize: MIT license, HuggingFace access, supported by Ollama and LM Studio.
- Exceptional reasoning and coding benchmark scores in a compact model
- Outperforms Qwen3 8B by +10% while rivaling much larger open-source models
- Efficient deployment on modest GPUs with quantization support
- Open-source and permissively licensed—ideal for fine-tuning and extension
- Rich ecosystem support (Hugging Face, Ollama, vLLM, LM Studio)
- No multimodal or MoE capabilities—text-only and limited context window
- May not match full R1‑0528 model on absolute reasoning depth
- Some users report occasional quirks in code generation vs specialized coders
Custom
Custom
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
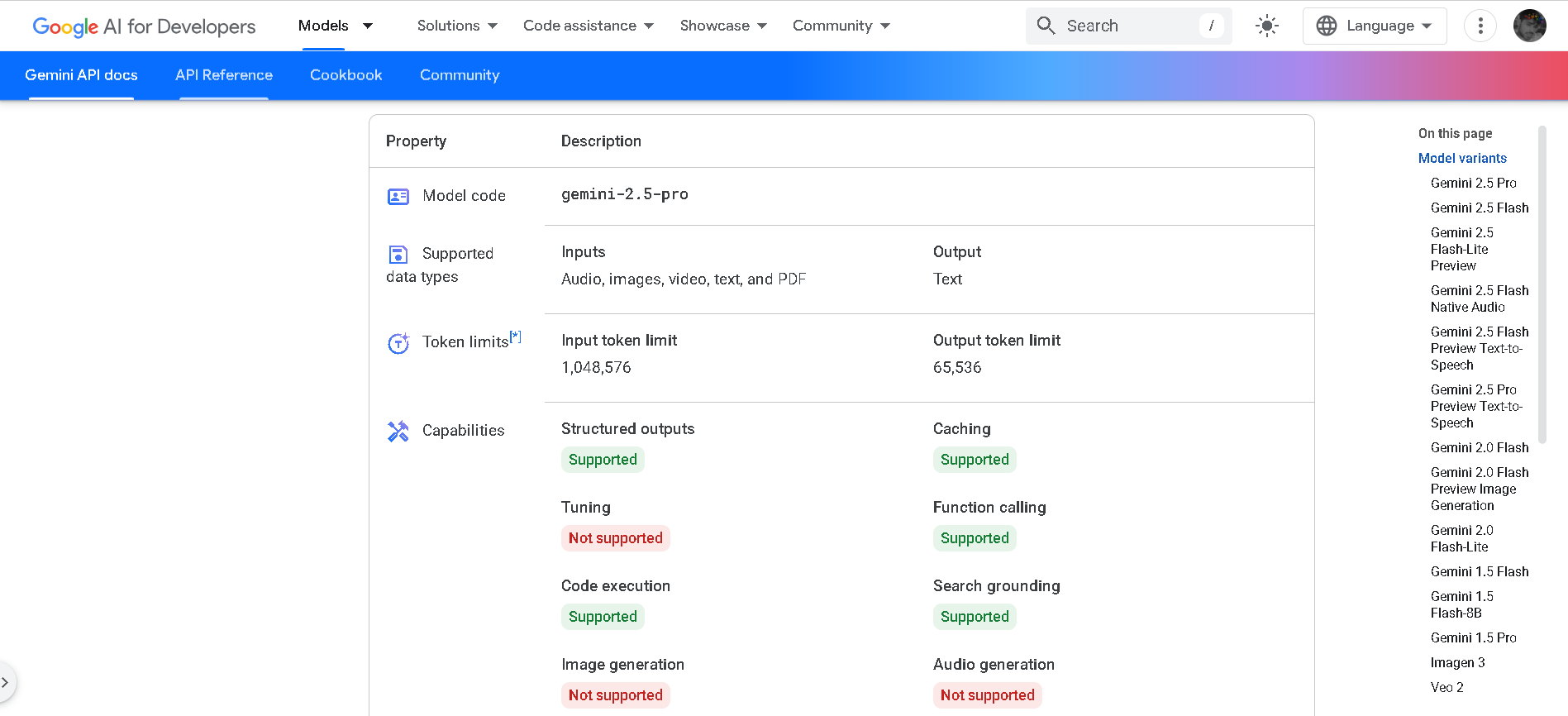

Gemini 2.5 Pro
Gemini 2.5 Pro is Google DeepMind’s advanced hybrid-reasoning AI model, designed to think deeply before responding. With support for multimodal inputs—text, images, audio, video, and code—it offers lightning-fast inference performance, up to 2 million tokens of context, and top-tier results in math, science, and coding benchmarks.
Gemini 2.5 Pro
Gemini 2.5 Pro is Google DeepMind’s advanced hybrid-reasoning AI model, designed to think deeply before responding. With support for multimodal inputs—text, images, audio, video, and code—it offers lightning-fast inference performance, up to 2 million tokens of context, and top-tier results in math, science, and coding benchmarks.
Gemini 2.5 Pro
Gemini 2.5 Pro is Google DeepMind’s advanced hybrid-reasoning AI model, designed to think deeply before responding. With support for multimodal inputs—text, images, audio, video, and code—it offers lightning-fast inference performance, up to 2 million tokens of context, and top-tier results in math, science, and coding benchmarks.
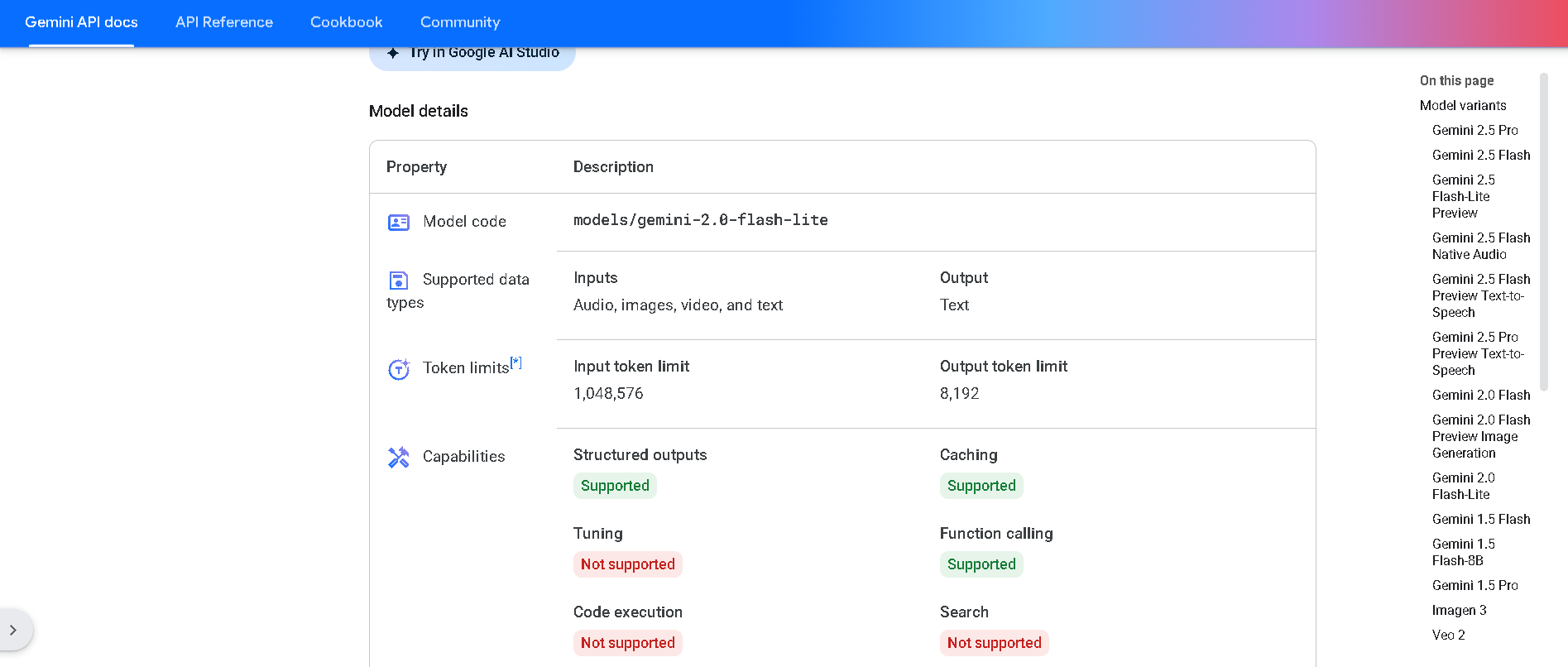
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
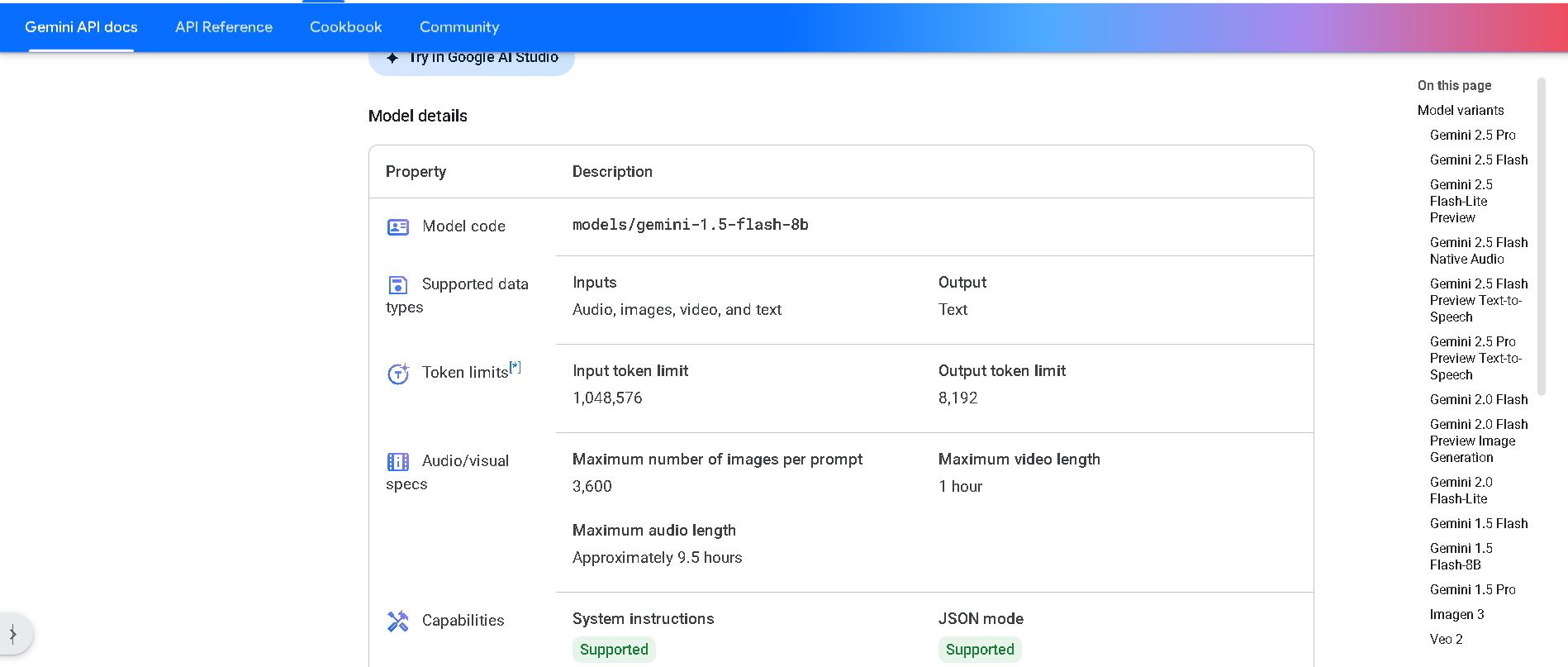
Gemini 1.5 Flash‑8B is Google DeepMind’s lightweight, high-volume variant of the 1.5 Flash model, optimized for efficiency and scale. It maintains multimodal abilities (text, image, audio, video) and a massive 1 million token context window—while offering 50 % lower pricing, 2× higher rate limits, and lower latency on small prompts compared to standard Flash.
Gemini 1.5 Flash‑8B is Google DeepMind’s lightweight, high-volume variant of the 1.5 Flash model, optimized for efficiency and scale. It maintains multimodal abilities (text, image, audio, video) and a massive 1 million token context window—while offering 50 % lower pricing, 2× higher rate limits, and lower latency on small prompts compared to standard Flash.
Gemini 1.5 Flash‑8B is Google DeepMind’s lightweight, high-volume variant of the 1.5 Flash model, optimized for efficiency and scale. It maintains multimodal abilities (text, image, audio, video) and a massive 1 million token context window—while offering 50 % lower pricing, 2× higher rate limits, and lower latency on small prompts compared to standard Flash.
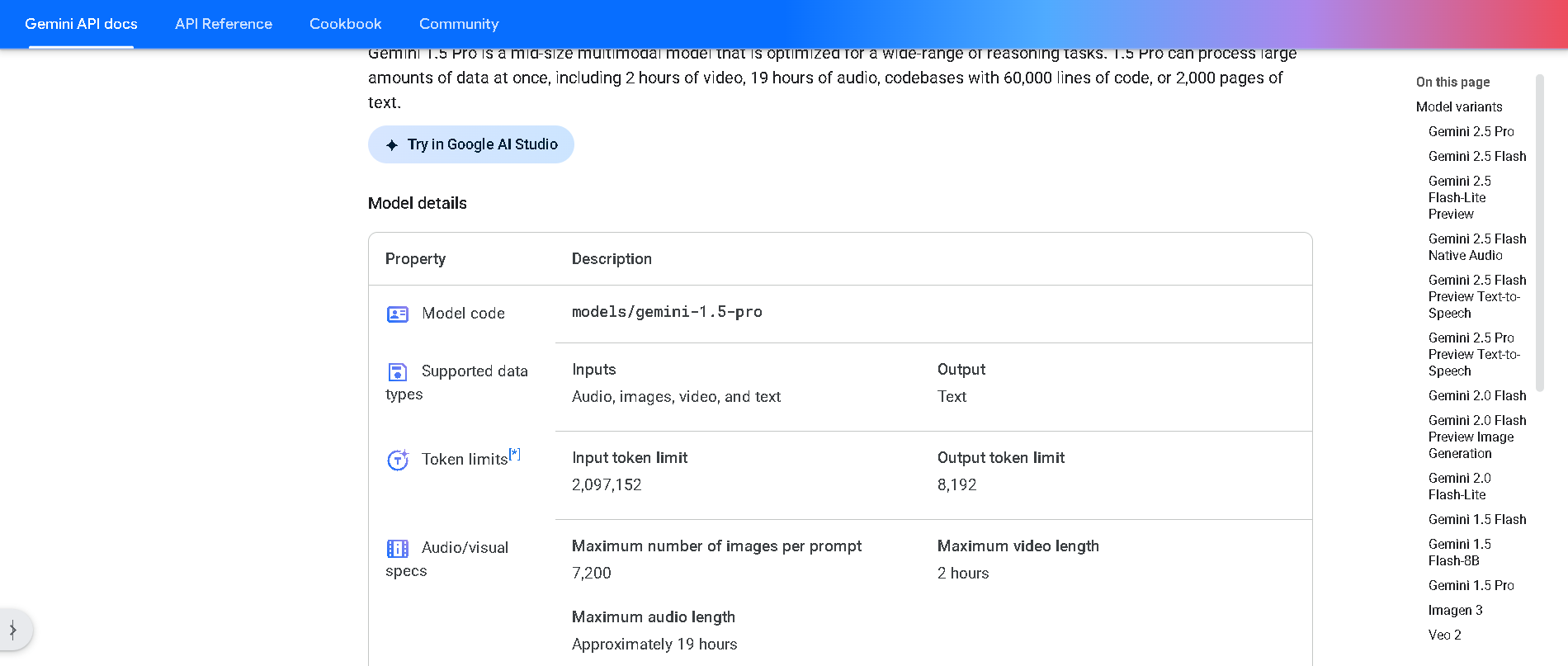

Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.

Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.

Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.
Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.
Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.

DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Ministral 8B (Ministral‑8B‑Instruct‑2410) is a state-of-the-art, 8‑billion-parameter dense transformer from Mistral AI’s “Ministraux” line, launched October 2024. With a 128 K-token context window (currently 32 K supported in vLLM), interleaved sliding-window attention, and function-calling support, it excels in reasoning, multilingual performance, code, and math tasks—outpacing many models in its size class.
Ministral 8B (Ministral‑8B‑Instruct‑2410) is a state-of-the-art, 8‑billion-parameter dense transformer from Mistral AI’s “Ministraux” line, launched October 2024. With a 128 K-token context window (currently 32 K supported in vLLM), interleaved sliding-window attention, and function-calling support, it excels in reasoning, multilingual performance, code, and math tasks—outpacing many models in its size class.
Ministral 8B (Ministral‑8B‑Instruct‑2410) is a state-of-the-art, 8‑billion-parameter dense transformer from Mistral AI’s “Ministraux” line, launched October 2024. With a 128 K-token context window (currently 32 K supported in vLLM), interleaved sliding-window attention, and function-calling support, it excels in reasoning, multilingual performance, code, and math tasks—outpacing many models in its size class.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai