
- Mobile & Edge Developers: 1B and 3B variants run locally on smartphones or IoT devices—even ARM-based chips.
- AI Developers & Enterprises: 11B/90B Vision models support image tasks like charts, OCR, and document analysis.
- Researchers & Tool Builders: Use text-only or vision models with long-context input for summarization, retrieval, or reasoning.
- Educators & Multilingual Applications: Multilingual text and vision assist in education, translation, and interactive learning.
- Open-Source Advocates: All sizes available under the Llama 3.2 community license, ensuring open deployment and fine-tuning opportunities.
How to Use Llama 3.2?
- Select Model: Choose 1B/3B for text-only tasks on-device; 11B/90B Vision via API/cloud.
- Deploy on Edge or Cloud: Use Hugging Face, AWS Bedrock, IBM watsonx.ai, or mobile runtimes.
- Send Prompts: Provide up to 128K tokens per prompt—texts or mixed media for Vision models.
- Perform Tasks: Summarization, visual Q&A, chart interpretation, code generation, multilingual chat, etc.
- Optimize for Efficiency: Edge variants designed for privacy and speed, while Vision models use GQA and efficient GPU inference.
- Edge-Ready Text Models: 1B/3B run locally with low latency and minimal resource use.
- First Open Multimodal: 11B/90B Vision models rival closed-source systems in chart and diagram understanding.
- Huge Context Window: 128K-token support enables long document and code workflows.
- Efficient Inference: GQA boosts speed, making even Vision models practical at scale.
- Open-Source & Commercial Flexibility: Community license supports widespread adoption and customization.
- Open-source 70B model matching much larger LLMs
- Massive 128K context for long documents and codebases
- Strong multilingual and instruction-following capabilities
- Available on major platforms including Oracle OCI
- Efficient inference via GQA and transformer optimizations
- Vision and multimodal features are not supported—text-only model
- Larger hardware requirements than smaller open models
- Context window still falls short of million-token ultra-long needs
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools


Claude 3.5 Sonnet
Claude 3.5 Sonnet is Anthropic’s mid-tier model in the Claude 3.5 lineup. Launched June 21, 2024, it delivers state-of-the-art reasoning, coding, and visual comprehension at twice the speed of its predecessor, while remaining cost-effective. It introduces the Artifacts feature—structured outputs like code, charts, or documents embedded alongside your chat.
Claude 3.5 Sonnet
Claude 3.5 Sonnet is Anthropic’s mid-tier model in the Claude 3.5 lineup. Launched June 21, 2024, it delivers state-of-the-art reasoning, coding, and visual comprehension at twice the speed of its predecessor, while remaining cost-effective. It introduces the Artifacts feature—structured outputs like code, charts, or documents embedded alongside your chat.
Claude 3.5 Sonnet
Claude 3.5 Sonnet is Anthropic’s mid-tier model in the Claude 3.5 lineup. Launched June 21, 2024, it delivers state-of-the-art reasoning, coding, and visual comprehension at twice the speed of its predecessor, while remaining cost-effective. It introduces the Artifacts feature—structured outputs like code, charts, or documents embedded alongside your chat.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
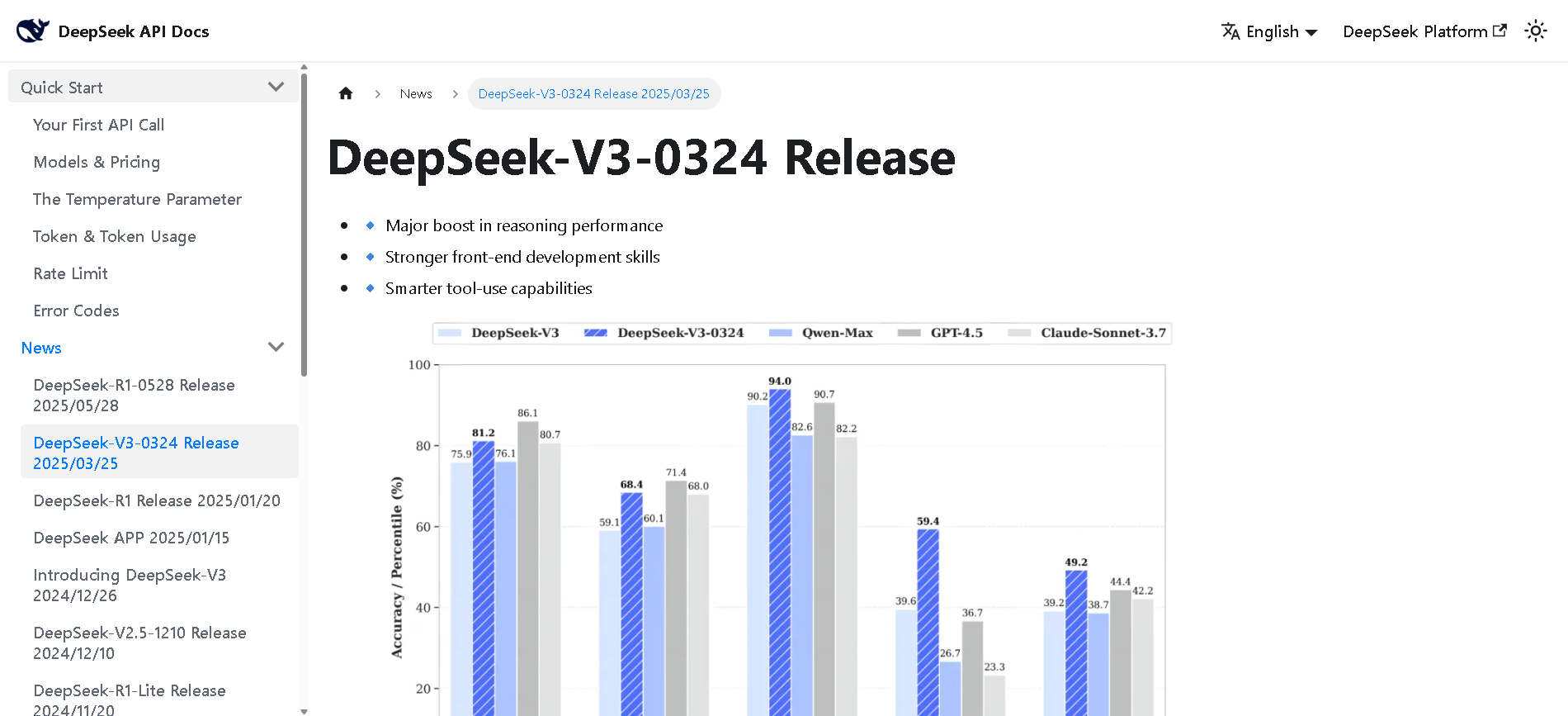
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.

DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.

grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.

Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
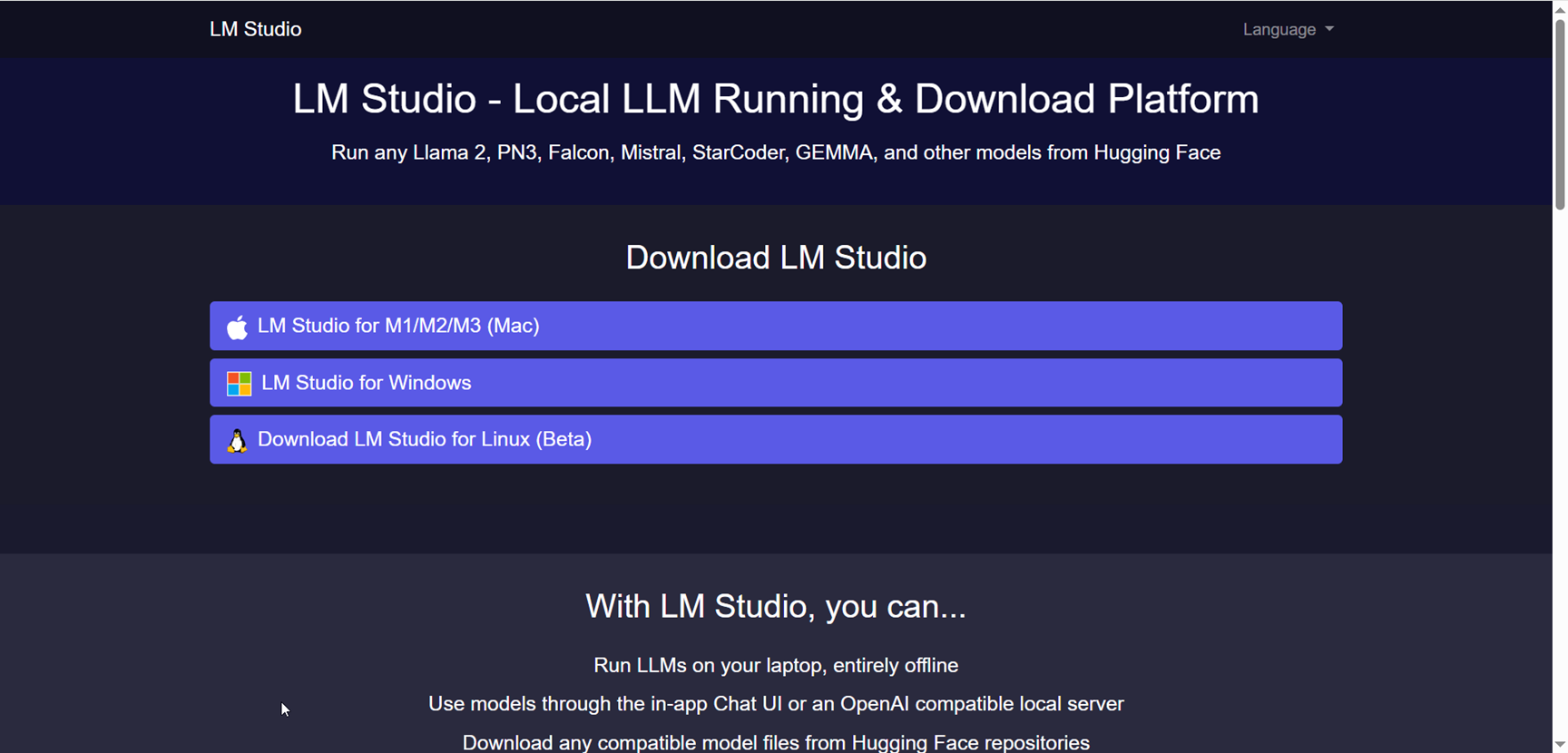
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
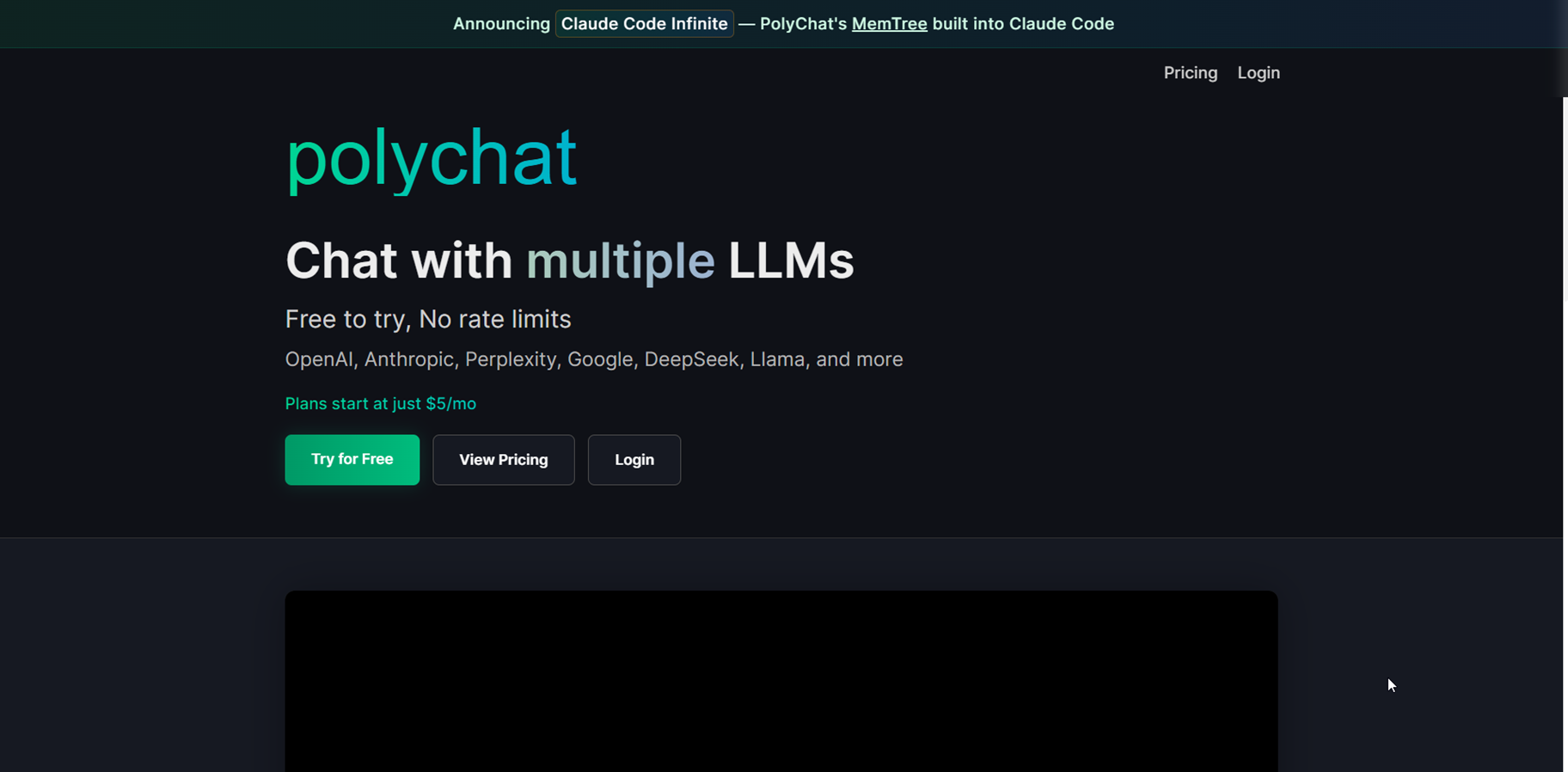

polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai