- AI Researchers & Scientists: Push boundaries in science and mathematics with graduate-level reasoning.
- Enterprise Developers: Build cost-efficient research/data assistants and coding copilots for real-world workflows.
- Software Engineers: Tackle debugging, multi-step planning, and robust code generation using advanced tool use.
- Startups & Labs: Fine-tune open datasets to accelerate the development of specialized agentic models.
- Technical Teams & Architects: Deploy scalable, low-latency AI microservices on-premises or in the cloud.
How to Use Llama Nemotron Ultra?
- Access Model & Datasets: Download from Hugging Face including weights, training, and post-training datasets.
- Deploy with NVIDIA NIM: Utilize as a high-throughput AI microservice for enterprise inferencing needs.
- Fine-tune for Tasks: Adapt open datasets for supervised and RL training to fit unique reasoning workflows.
- Activate Reasoning as Needed: Use reasoning mode for complex tasks and keep it off for routine operations.
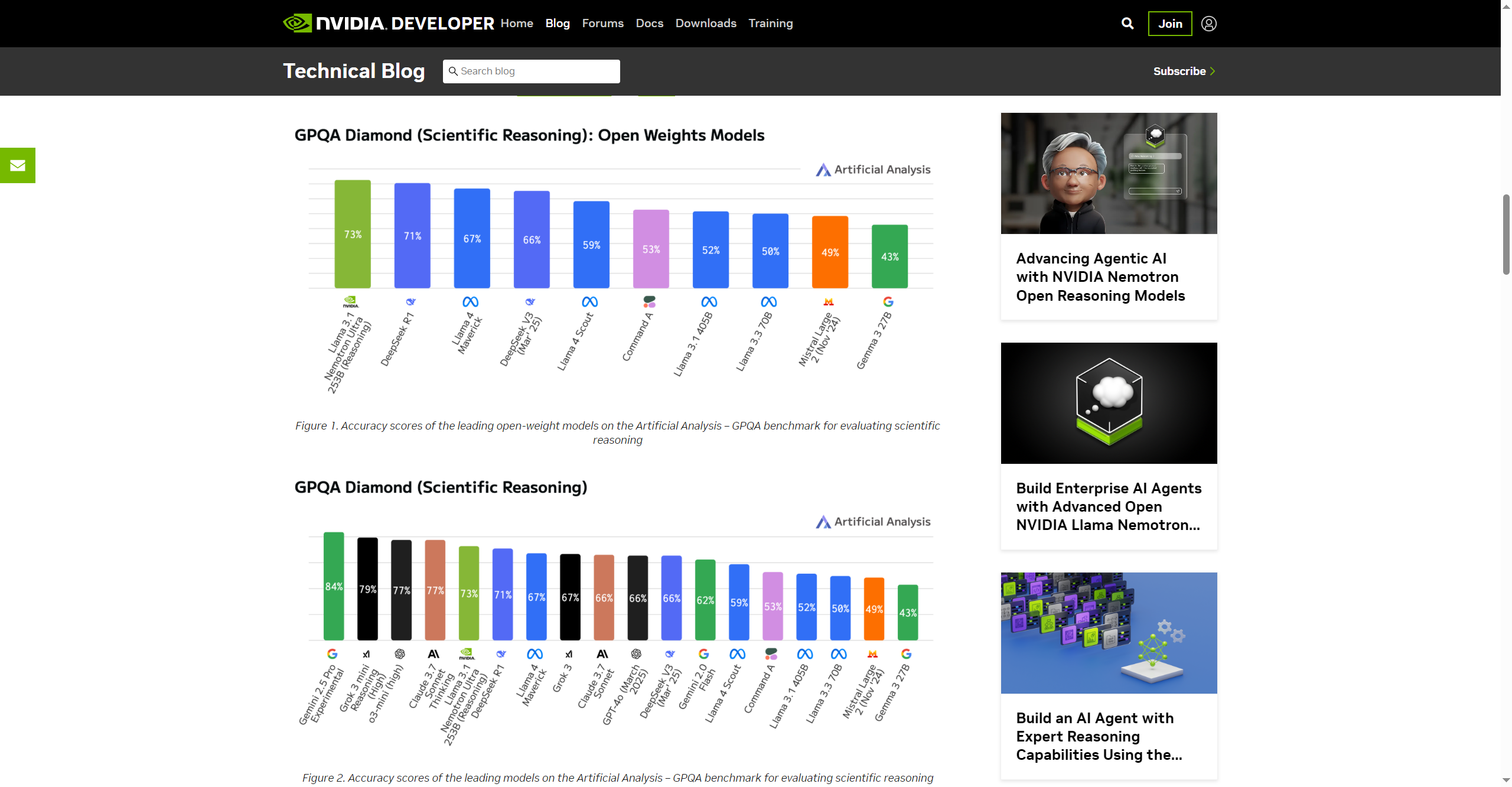
- Top Open-Source Reasoning Accuracy: Achieves 76% on GPQA Diamond, surpassing PhD-level scientific benchmarks.
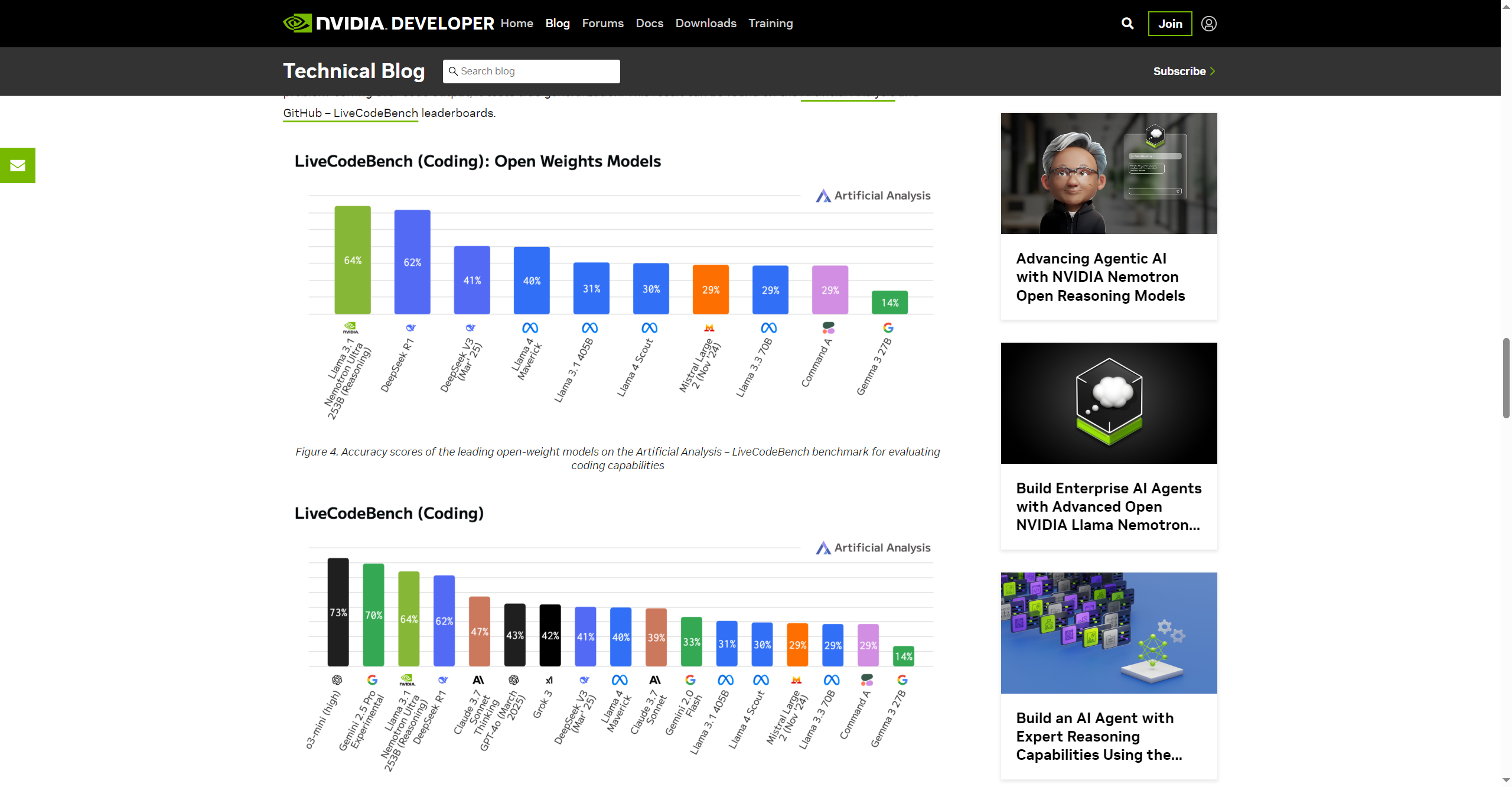
- LiveCodeBench Performance: Excels in coding generation, debugging, and self-repair with real-world code tasks.
- AIME Math Mastery: Outperforms open models on mathematical reasoning challenges.
- Open, Commercially-Viable Datasets: Provides full datasets for code and reasoning post-training.
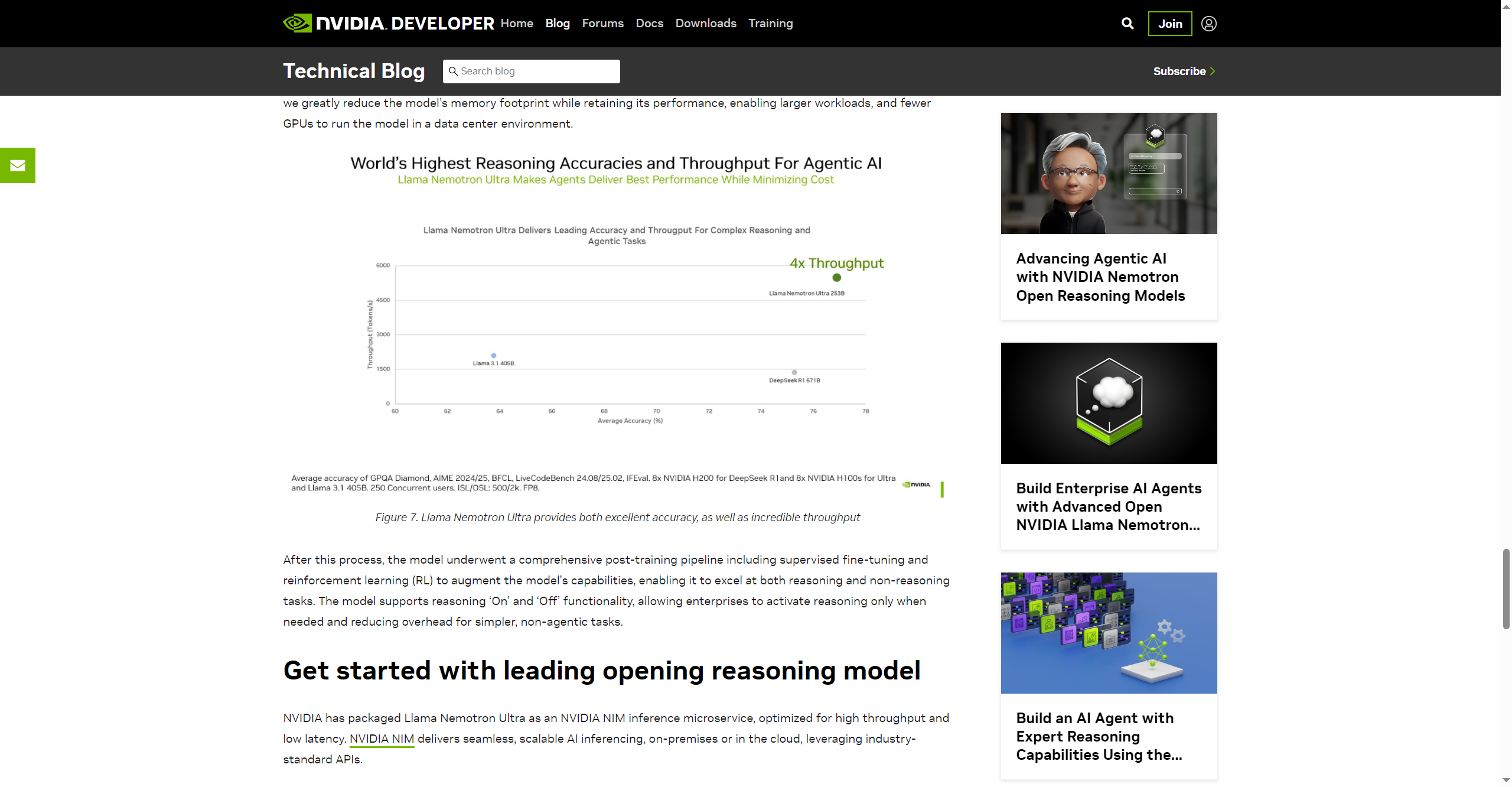
- Optimized Inference & Memory Efficiency: Neural Architecture Search reduces footprint for scalable deployment.
- Sets a new standard for open scientific and coding benchmarks.
- Full open access to weights and datasets for customization.
- Efficiency allows commercial-scale workloads with less hardware.
- Flexible design for agentic, reasoning-first and routine tasks.
- Complexity may challenge less-experienced developers.
- Full feature set requires NVIDIA NIM or similar infrastructure.
- Specialized reasoning may be overkill for basic generation tasks.
- Competing closed models may still have advantages for some use cases.
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.

DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.
DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.
DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.

Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.

Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.

DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.

DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Build by Nvidia
Build by NVIDIA is a developer-focused platform showcasing blueprints and microservices for building AI-powered applications using NVIDIA’s NIM (NeMo Inference Microservices) ecosystem. It offers plug-and-play workflows like enterprise research agents, RAG pipelines, video summarization assistants, and AI-powered virtual assistants—all optimized for scalability, latency, and multimodal capabilities.
Build by Nvidia
Build by NVIDIA is a developer-focused platform showcasing blueprints and microservices for building AI-powered applications using NVIDIA’s NIM (NeMo Inference Microservices) ecosystem. It offers plug-and-play workflows like enterprise research agents, RAG pipelines, video summarization assistants, and AI-powered virtual assistants—all optimized for scalability, latency, and multimodal capabilities.
Build by Nvidia
Build by NVIDIA is a developer-focused platform showcasing blueprints and microservices for building AI-powered applications using NVIDIA’s NIM (NeMo Inference Microservices) ecosystem. It offers plug-and-play workflows like enterprise research agents, RAG pipelines, video summarization assistants, and AI-powered virtual assistants—all optimized for scalability, latency, and multimodal capabilities.
Grok 4
Grok 4 is the latest and most intelligent AI model developed by xAI, designed for expert-level reasoning and real-time knowledge integration. It combines large-scale reinforcement learning with native tool use, including code interpretation, web browsing, and advanced search capabilities, to provide highly accurate and up-to-date responses. Grok 4 excels across diverse domains such as math, coding, science, and complex reasoning, supporting multimodal inputs like text and vision. With its massive 256,000-token context window and advanced toolset, Grok 4 is built to push the boundaries of AI intelligence and practical utility for both developers and enterprises.
Grok 4
Grok 4 is the latest and most intelligent AI model developed by xAI, designed for expert-level reasoning and real-time knowledge integration. It combines large-scale reinforcement learning with native tool use, including code interpretation, web browsing, and advanced search capabilities, to provide highly accurate and up-to-date responses. Grok 4 excels across diverse domains such as math, coding, science, and complex reasoning, supporting multimodal inputs like text and vision. With its massive 256,000-token context window and advanced toolset, Grok 4 is built to push the boundaries of AI intelligence and practical utility for both developers and enterprises.
Grok 4
Grok 4 is the latest and most intelligent AI model developed by xAI, designed for expert-level reasoning and real-time knowledge integration. It combines large-scale reinforcement learning with native tool use, including code interpretation, web browsing, and advanced search capabilities, to provide highly accurate and up-to-date responses. Grok 4 excels across diverse domains such as math, coding, science, and complex reasoning, supporting multimodal inputs like text and vision. With its massive 256,000-token context window and advanced toolset, Grok 4 is built to push the boundaries of AI intelligence and practical utility for both developers and enterprises.
Prompt Llama
Prompt Llama is a tool for creatives and AI enthusiasts that lets you gather high-quality text-to-image prompts and test how different generative AI models respond to the same prompts. It’s made for comparing model outputs side by side, so you can see strengths and weaknesses, styles, fidelity, and prompt adherence across models without doing the prompt-engineering yourself every time.
Prompt Llama
Prompt Llama is a tool for creatives and AI enthusiasts that lets you gather high-quality text-to-image prompts and test how different generative AI models respond to the same prompts. It’s made for comparing model outputs side by side, so you can see strengths and weaknesses, styles, fidelity, and prompt adherence across models without doing the prompt-engineering yourself every time.
Prompt Llama
Prompt Llama is a tool for creatives and AI enthusiasts that lets you gather high-quality text-to-image prompts and test how different generative AI models respond to the same prompts. It’s made for comparing model outputs side by side, so you can see strengths and weaknesses, styles, fidelity, and prompt adherence across models without doing the prompt-engineering yourself every time.
Chat01.ai
OpenAI01.net is a third-party, browser-based chat platform that lets you use OpenAI’s o1 family of advanced reasoning models for free, without needing your own API key or paid account. Branded as Chat01.ai in some places, it focuses on giving users generous access to o1-preview and o1-mini through a simple chat interface so they can tackle complex math, coding, science, and problem-solving tasks. The site often features public question-and-answer threads, allowing you to study other users’ prompts and responses to improve your own prompting skills. It acts as an accessible front-end to powerful OpenAI models, but is not officially operated by OpenAI.
Chat01.ai
OpenAI01.net is a third-party, browser-based chat platform that lets you use OpenAI’s o1 family of advanced reasoning models for free, without needing your own API key or paid account. Branded as Chat01.ai in some places, it focuses on giving users generous access to o1-preview and o1-mini through a simple chat interface so they can tackle complex math, coding, science, and problem-solving tasks. The site often features public question-and-answer threads, allowing you to study other users’ prompts and responses to improve your own prompting skills. It acts as an accessible front-end to powerful OpenAI models, but is not officially operated by OpenAI.
Chat01.ai
OpenAI01.net is a third-party, browser-based chat platform that lets you use OpenAI’s o1 family of advanced reasoning models for free, without needing your own API key or paid account. Branded as Chat01.ai in some places, it focuses on giving users generous access to o1-preview and o1-mini through a simple chat interface so they can tackle complex math, coding, science, and problem-solving tasks. The site often features public question-and-answer threads, allowing you to study other users’ prompts and responses to improve your own prompting skills. It acts as an accessible front-end to powerful OpenAI models, but is not officially operated by OpenAI.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai