- AI Developers & Engineers: Build multimodal agents—text, image, video, audio—using tested workflows.
- Enterprise Architects: Integrate scalable retrieval-augmented generation (RAG) systems and research assistants.
- Data Teams & Researchers: Ingest and query large multimodal datasets like PDFs or video archives.
- Solution Providers: Assemble customer-service chatbots, security screening pipelines, or voice assistants.
- Startups & Scale-Ups: Launch AI applications faster with enterprise-grade blueprints.
How to Use Build by NVIDIA?
- Browse Blueprints: Choose from options like “Enterprise Research Agent,” “Video Search & Summarization,” or “RAG Pipeline.”
- Install Microservices: Deploy NeMo microservices via NIM—including retrievers, generators, summarizers, audio processors.
- Connect Data Sources: Ingest PDFs, video, audio, or enterprise documents using GPU-accelerated extractors.
- Configure Agent Flow: Use reference code and Helm charts to customize workflows with RAG, chat, audio/video pipelines.
- Deploy & Scale: Launch on any infrastructure—Kubernetes, cloud providers, or on-prem—with GPU acceleration and monitoring tools.
- Enterprise-Ready Blueprints: Pre-built, scalable pipelines for real-world AI use cases.
- Microservices Architecture: Modular NeMo services allow composable, GPU-accelerated AI components.
- Multimodal Support: Handles text, images, audio, and video in unified flows (e.g., PDF-to-podcast, video summarization).
- Cloud-Agnostic & Scalable: Easily deployable across Kubernetes and major clouds with performance tuning.
- Open-Weight Friendly: Works with open models like Llama and Mistral, giving flexibility and data control.
- Turnkey enterprise workflows for rapid prototyping
- GPU-accelerated microservices for fast inference
- Strong multimodal capabilities out of the box
- Modular and easily customizable pipelines
- Open-model compatibility avoids vendor lock-in
- Requires GPU infrastructure and Kubernetes expertise
- May involve non-trivial integration overhead for custom use cases
- Largely enterprise-oriented—individual developers may find it heavyweight
Paid
custom
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
Ministral refers to Mistral AI’s new “Les Ministraux” series—comprising Ministral 3B and Ministral 8B—launched in October 2024. These are ultra-efficient, open-weight LLMs optimized for on-device and edge computing, with a massive 128 K‑token context window. They offer strong reasoning, knowledge, multilingual support, and function-calling capabilities, outperforming previous models in the sub‑10B parameter class
Ministral refers to Mistral AI’s new “Les Ministraux” series—comprising Ministral 3B and Ministral 8B—launched in October 2024. These are ultra-efficient, open-weight LLMs optimized for on-device and edge computing, with a massive 128 K‑token context window. They offer strong reasoning, knowledge, multilingual support, and function-calling capabilities, outperforming previous models in the sub‑10B parameter class
Ministral refers to Mistral AI’s new “Les Ministraux” series—comprising Ministral 3B and Ministral 8B—launched in October 2024. These are ultra-efficient, open-weight LLMs optimized for on-device and edge computing, with a massive 128 K‑token context window. They offer strong reasoning, knowledge, multilingual support, and function-calling capabilities, outperforming previous models in the sub‑10B parameter class
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Batteries Included
Batteries Included is a self-hosted AI platform designed to provide the necessary infrastructure for building and deploying AI applications. Its primary purpose is to simplify the deployment of large language models (LLMs), vector databases, and Jupyter notebooks, offering enterprise-grade tools similar to those used by hyperscalers, but within a user's self-hosted environment.
Batteries Included
Batteries Included is a self-hosted AI platform designed to provide the necessary infrastructure for building and deploying AI applications. Its primary purpose is to simplify the deployment of large language models (LLMs), vector databases, and Jupyter notebooks, offering enterprise-grade tools similar to those used by hyperscalers, but within a user's self-hosted environment.
Batteries Included
Batteries Included is a self-hosted AI platform designed to provide the necessary infrastructure for building and deploying AI applications. Its primary purpose is to simplify the deployment of large language models (LLMs), vector databases, and Jupyter notebooks, offering enterprise-grade tools similar to those used by hyperscalers, but within a user's self-hosted environment.
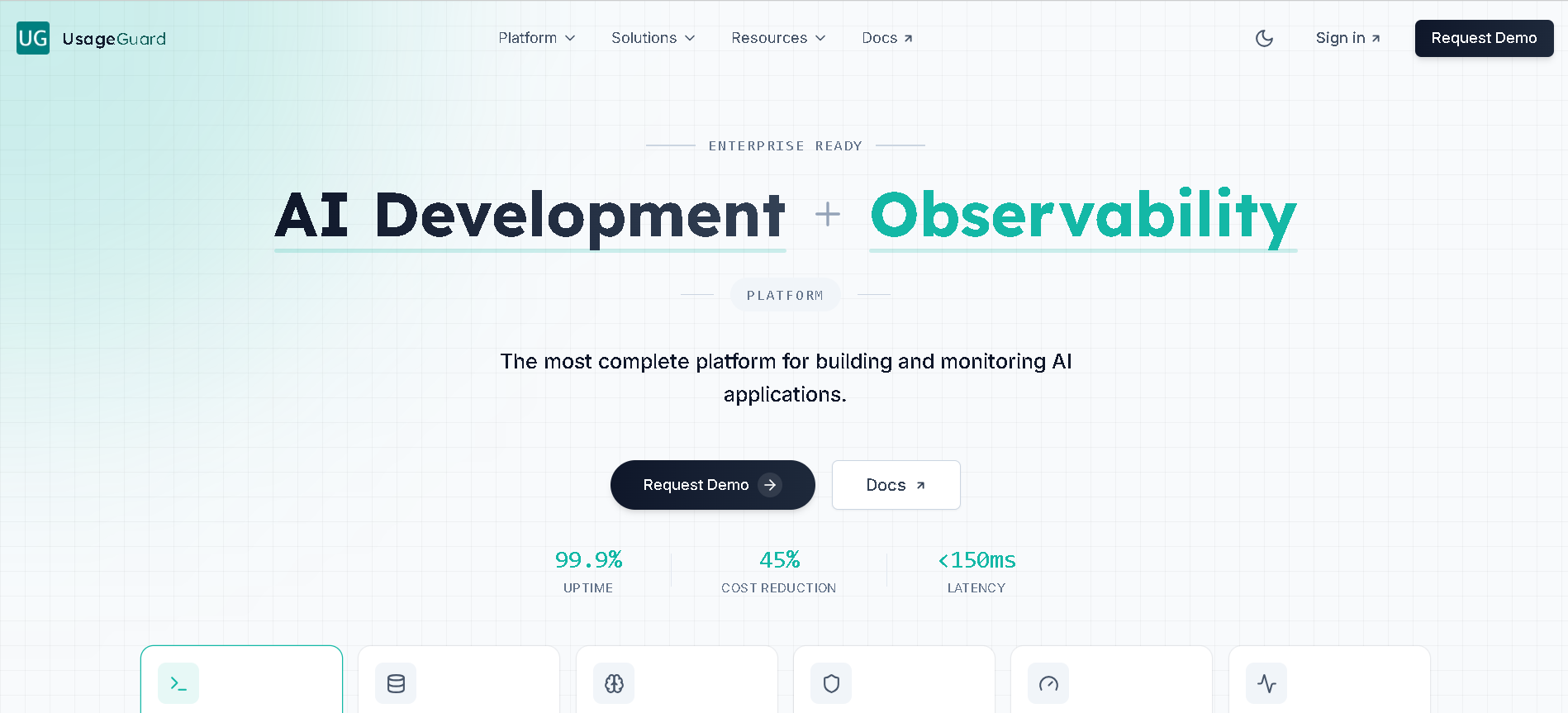
UsageGuard
UsageGuard is an AI infrastructure platform designed to help businesses build, deploy, and monitor AI applications with confidence. It acts as a proxy service for Large Language Model (LLM) API calls, providing a unified endpoint that offers a suite of enterprise-grade features. Its core mission is to empower developers and enterprises with robust solutions for AI security, cost control, usage tracking, and comprehensive observability.
UsageGuard
UsageGuard is an AI infrastructure platform designed to help businesses build, deploy, and monitor AI applications with confidence. It acts as a proxy service for Large Language Model (LLM) API calls, providing a unified endpoint that offers a suite of enterprise-grade features. Its core mission is to empower developers and enterprises with robust solutions for AI security, cost control, usage tracking, and comprehensive observability.
UsageGuard
UsageGuard is an AI infrastructure platform designed to help businesses build, deploy, and monitor AI applications with confidence. It acts as a proxy service for Large Language Model (LLM) API calls, providing a unified endpoint that offers a suite of enterprise-grade features. Its core mission is to empower developers and enterprises with robust solutions for AI security, cost control, usage tracking, and comprehensive observability.

Finetunefast
FinetuneFast.com is a platform designed to drastically reduce the time and complexity of launching AI models, enabling users to fine-tune and deploy machine learning models from weeks to just days. It provides a comprehensive ML boilerplate and a suite of tools for various AI applications, including text-to-image and Large Language Models (LLMs). The platform aims to accelerate the development, production, and monetization of AI applications by offering pre-configured training scripts, efficient data loading, optimized infrastructure, and one-click deployment solutions.
Finetunefast
FinetuneFast.com is a platform designed to drastically reduce the time and complexity of launching AI models, enabling users to fine-tune and deploy machine learning models from weeks to just days. It provides a comprehensive ML boilerplate and a suite of tools for various AI applications, including text-to-image and Large Language Models (LLMs). The platform aims to accelerate the development, production, and monetization of AI applications by offering pre-configured training scripts, efficient data loading, optimized infrastructure, and one-click deployment solutions.
Finetunefast
FinetuneFast.com is a platform designed to drastically reduce the time and complexity of launching AI models, enabling users to fine-tune and deploy machine learning models from weeks to just days. It provides a comprehensive ML boilerplate and a suite of tools for various AI applications, including text-to-image and Large Language Models (LLMs). The platform aims to accelerate the development, production, and monetization of AI applications by offering pre-configured training scripts, efficient data loading, optimized infrastructure, and one-click deployment solutions.
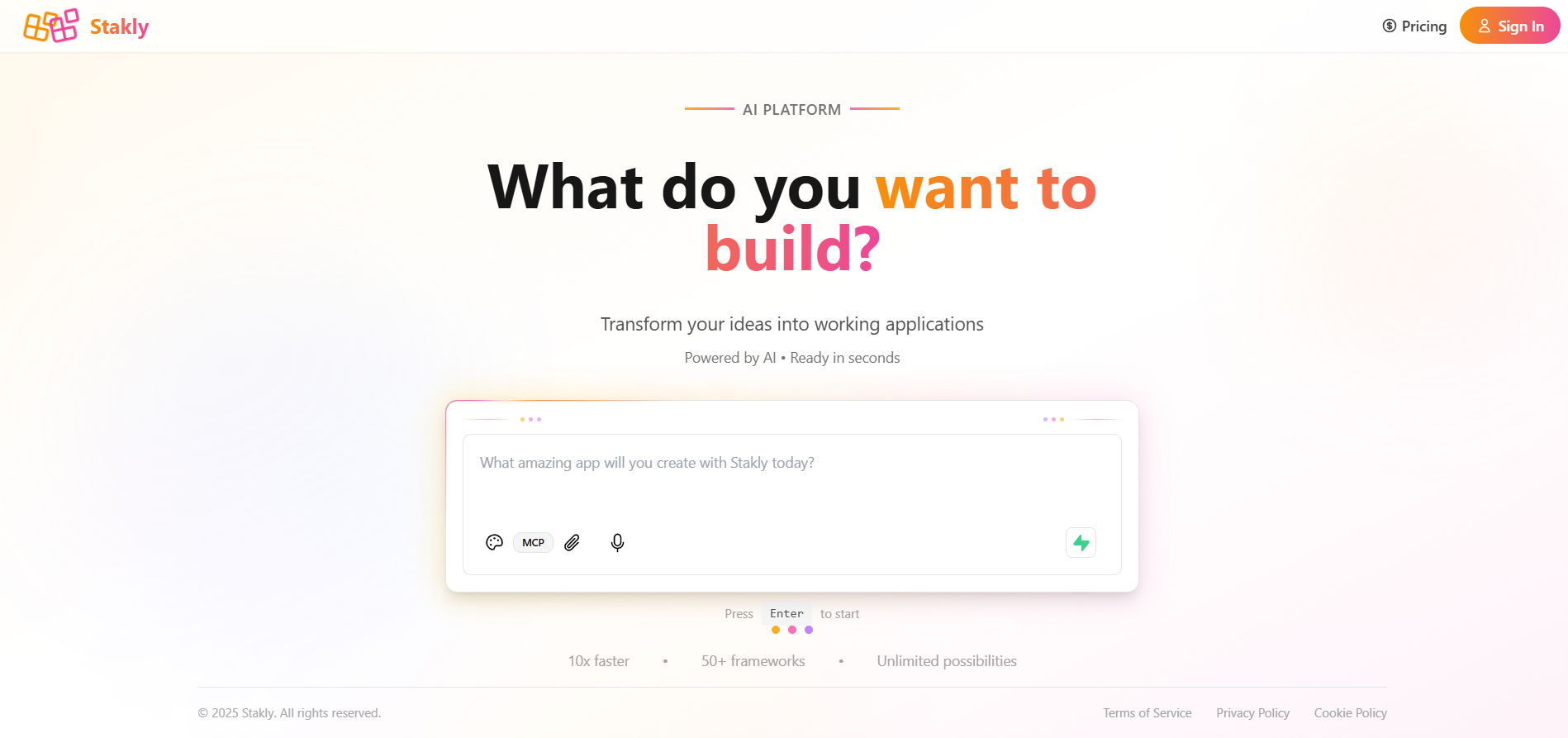
Stakly
Stakly.dev is an AI-powered full-stack app builder that lets users design, code, and deploy web applications without writing manual boilerplate. You describe the app idea in plain language, set up data models, pages, and UI components through an intuitive interface, and Stakly generates production-ready code (including React front-end, Supabase or equivalent backend) and handles deployment to platforms like Vercel or Netlify. It offers a monthly free token allotment so you can experiment, supports live previews so you can see your app as you build, integrates with GitHub for code versioning, and is functional enough to build dashboards, SaaS tools, admin panels, and e-commerce sites. While not replacing full engineering teams for deeply custom or extremely large scale systems, Stakly lowers the technical barrier significantly: non-technical founders, product managers, solo makers, or small agencies can use Stakly to create usable, polished apps in minutes instead of weeks.
Stakly
Stakly.dev is an AI-powered full-stack app builder that lets users design, code, and deploy web applications without writing manual boilerplate. You describe the app idea in plain language, set up data models, pages, and UI components through an intuitive interface, and Stakly generates production-ready code (including React front-end, Supabase or equivalent backend) and handles deployment to platforms like Vercel or Netlify. It offers a monthly free token allotment so you can experiment, supports live previews so you can see your app as you build, integrates with GitHub for code versioning, and is functional enough to build dashboards, SaaS tools, admin panels, and e-commerce sites. While not replacing full engineering teams for deeply custom or extremely large scale systems, Stakly lowers the technical barrier significantly: non-technical founders, product managers, solo makers, or small agencies can use Stakly to create usable, polished apps in minutes instead of weeks.
Stakly
Stakly.dev is an AI-powered full-stack app builder that lets users design, code, and deploy web applications without writing manual boilerplate. You describe the app idea in plain language, set up data models, pages, and UI components through an intuitive interface, and Stakly generates production-ready code (including React front-end, Supabase or equivalent backend) and handles deployment to platforms like Vercel or Netlify. It offers a monthly free token allotment so you can experiment, supports live previews so you can see your app as you build, integrates with GitHub for code versioning, and is functional enough to build dashboards, SaaS tools, admin panels, and e-commerce sites. While not replacing full engineering teams for deeply custom or extremely large scale systems, Stakly lowers the technical barrier significantly: non-technical founders, product managers, solo makers, or small agencies can use Stakly to create usable, polished apps in minutes instead of weeks.
WebDev Arena
LMArena is an open, crowdsourced platform for evaluating large language models (LLMs) based on human preferences. Rather than relying purely on automated benchmarks, it presents paired responses from different models to users, who vote for which is better. These votes build live leaderboards, revealing which models perform best in real-use scenarios. Key features include prompt-to-leaderboard comparison, transparent evaluation methods, style control for how responses are formatted, and auditability of feedback data. The platform is particularly valuable for researchers, developers, and AI labs that want to understand how their models compare when judged by real people, not just metrics.
WebDev Arena
LMArena is an open, crowdsourced platform for evaluating large language models (LLMs) based on human preferences. Rather than relying purely on automated benchmarks, it presents paired responses from different models to users, who vote for which is better. These votes build live leaderboards, revealing which models perform best in real-use scenarios. Key features include prompt-to-leaderboard comparison, transparent evaluation methods, style control for how responses are formatted, and auditability of feedback data. The platform is particularly valuable for researchers, developers, and AI labs that want to understand how their models compare when judged by real people, not just metrics.
WebDev Arena
LMArena is an open, crowdsourced platform for evaluating large language models (LLMs) based on human preferences. Rather than relying purely on automated benchmarks, it presents paired responses from different models to users, who vote for which is better. These votes build live leaderboards, revealing which models perform best in real-use scenarios. Key features include prompt-to-leaderboard comparison, transparent evaluation methods, style control for how responses are formatted, and auditability of feedback data. The platform is particularly valuable for researchers, developers, and AI labs that want to understand how their models compare when judged by real people, not just metrics.
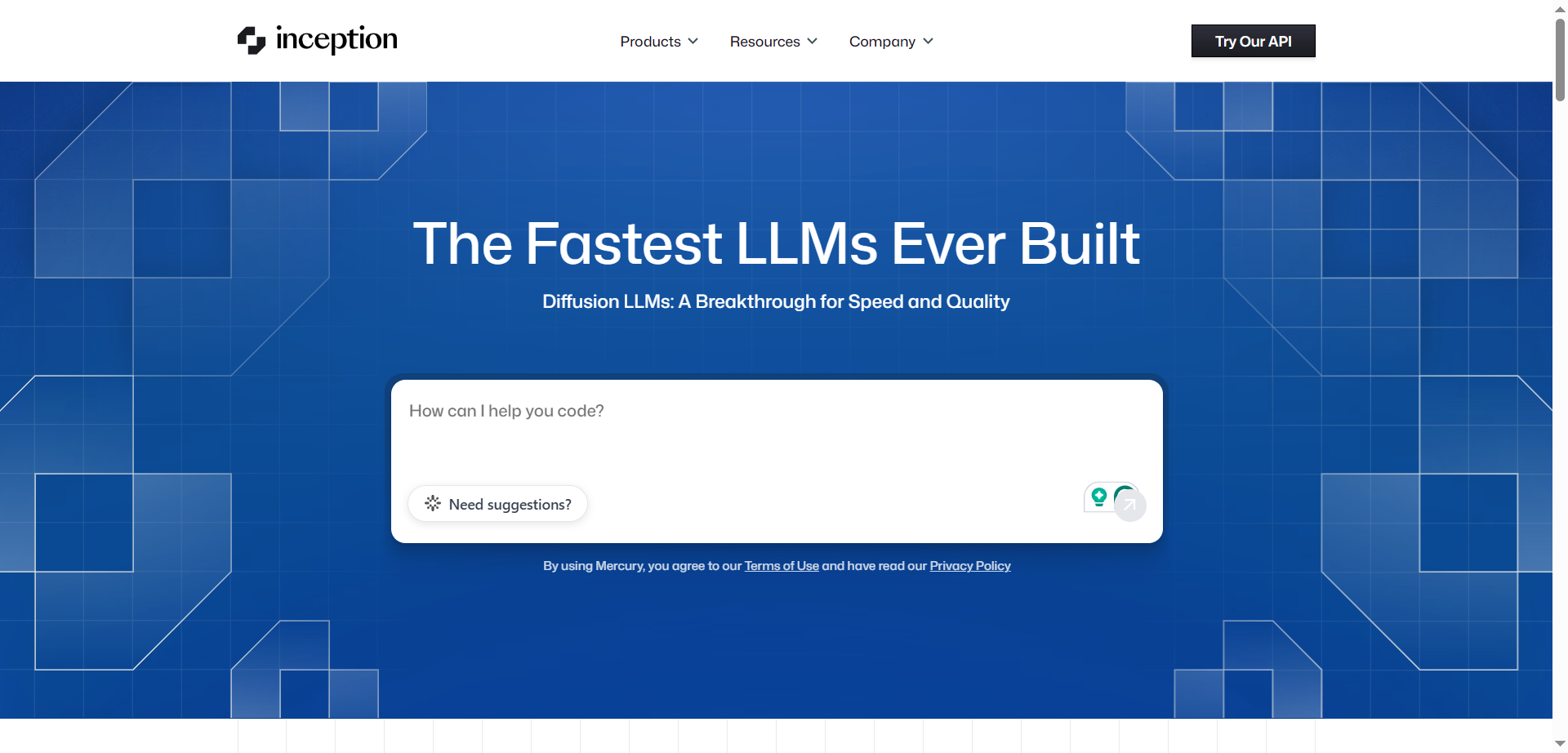

inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
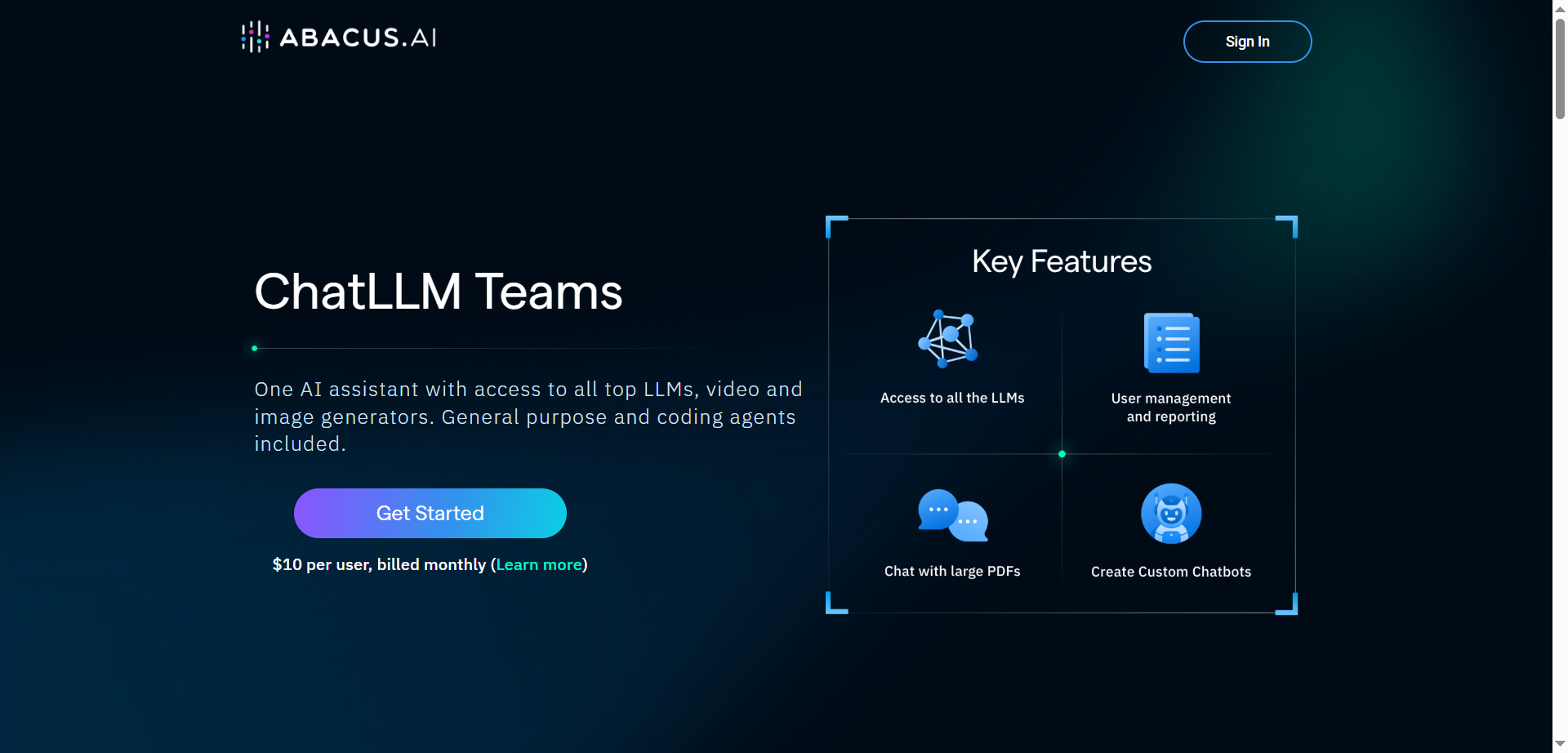

Abacus.AI
ChatLLM Teams by Abacus.AI is an all‑in‑one AI assistant that unifies access to top LLMs, image and video generators, and powerful agentic tools in a single workspace. It includes DeepAgent for complex, multi‑step tasks, code execution with an editor, document/chat with files, web search, TTS, and slide/doc generation. Users can build custom chatbots, set up AI workflows, generate images and videos from multiple models, and organize work with projects across desktop and mobile apps. The platform is OpenAI‑style in usability but adds operator features for running tasks on a computer, plus DeepAgent Desktop and AppLLM for building and hosting small apps.
Abacus.AI
ChatLLM Teams by Abacus.AI is an all‑in‑one AI assistant that unifies access to top LLMs, image and video generators, and powerful agentic tools in a single workspace. It includes DeepAgent for complex, multi‑step tasks, code execution with an editor, document/chat with files, web search, TTS, and slide/doc generation. Users can build custom chatbots, set up AI workflows, generate images and videos from multiple models, and organize work with projects across desktop and mobile apps. The platform is OpenAI‑style in usability but adds operator features for running tasks on a computer, plus DeepAgent Desktop and AppLLM for building and hosting small apps.
Abacus.AI
ChatLLM Teams by Abacus.AI is an all‑in‑one AI assistant that unifies access to top LLMs, image and video generators, and powerful agentic tools in a single workspace. It includes DeepAgent for complex, multi‑step tasks, code execution with an editor, document/chat with files, web search, TTS, and slide/doc generation. Users can build custom chatbots, set up AI workflows, generate images and videos from multiple models, and organize work with projects across desktop and mobile apps. The platform is OpenAI‑style in usability but adds operator features for running tasks on a computer, plus DeepAgent Desktop and AppLLM for building and hosting small apps.
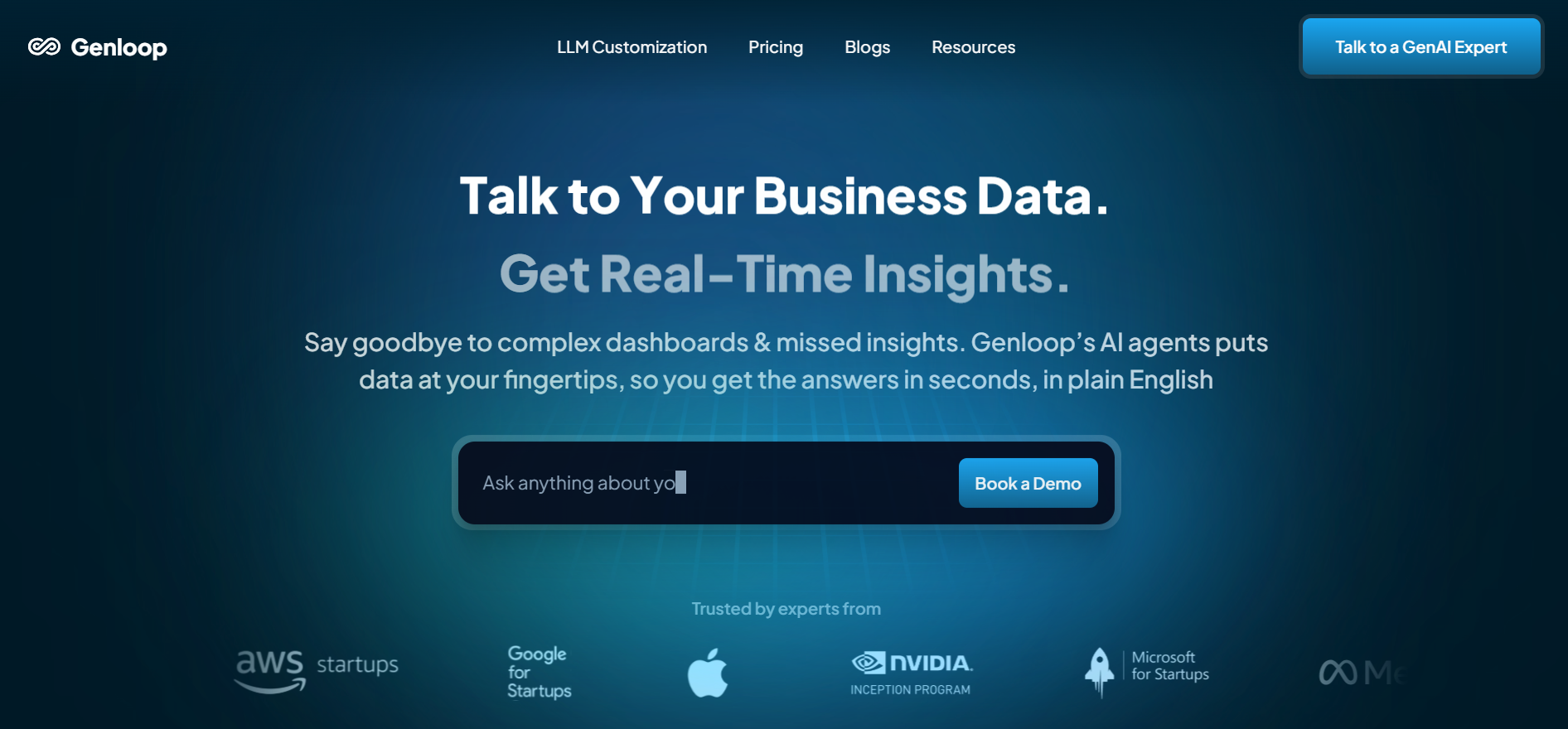
Genloop AI
Genloop is a platform that empowers enterprises to build, deploy, and manage custom, private large language models (LLMs) tailored to their business data and requirements — all with minimal development effort. It turns enterprise data into intelligent, conversational insights, allowing users to ask business questions in natural language and receive actionable analysis instantly. The platform enables organizations to confidently manage their data-driven decision-making by offering advanced fine-tuning, automation, and deployment tools. Businesses can transform their existing datasets into private AI assistants that deliver accurate insights, while maintaining complete security and compliance. Genloop’s focus is on bridging the gap between AI and enterprise data operations, providing a scalable, trustworthy, and adaptive solution for teams that want to leverage AI without extensive coding or infrastructure complexity.
Genloop AI
Genloop is a platform that empowers enterprises to build, deploy, and manage custom, private large language models (LLMs) tailored to their business data and requirements — all with minimal development effort. It turns enterprise data into intelligent, conversational insights, allowing users to ask business questions in natural language and receive actionable analysis instantly. The platform enables organizations to confidently manage their data-driven decision-making by offering advanced fine-tuning, automation, and deployment tools. Businesses can transform their existing datasets into private AI assistants that deliver accurate insights, while maintaining complete security and compliance. Genloop’s focus is on bridging the gap between AI and enterprise data operations, providing a scalable, trustworthy, and adaptive solution for teams that want to leverage AI without extensive coding or infrastructure complexity.
Genloop AI
Genloop is a platform that empowers enterprises to build, deploy, and manage custom, private large language models (LLMs) tailored to their business data and requirements — all with minimal development effort. It turns enterprise data into intelligent, conversational insights, allowing users to ask business questions in natural language and receive actionable analysis instantly. The platform enables organizations to confidently manage their data-driven decision-making by offering advanced fine-tuning, automation, and deployment tools. Businesses can transform their existing datasets into private AI assistants that deliver accurate insights, while maintaining complete security and compliance. Genloop’s focus is on bridging the gap between AI and enterprise data operations, providing a scalable, trustworthy, and adaptive solution for teams that want to leverage AI without extensive coding or infrastructure complexity.
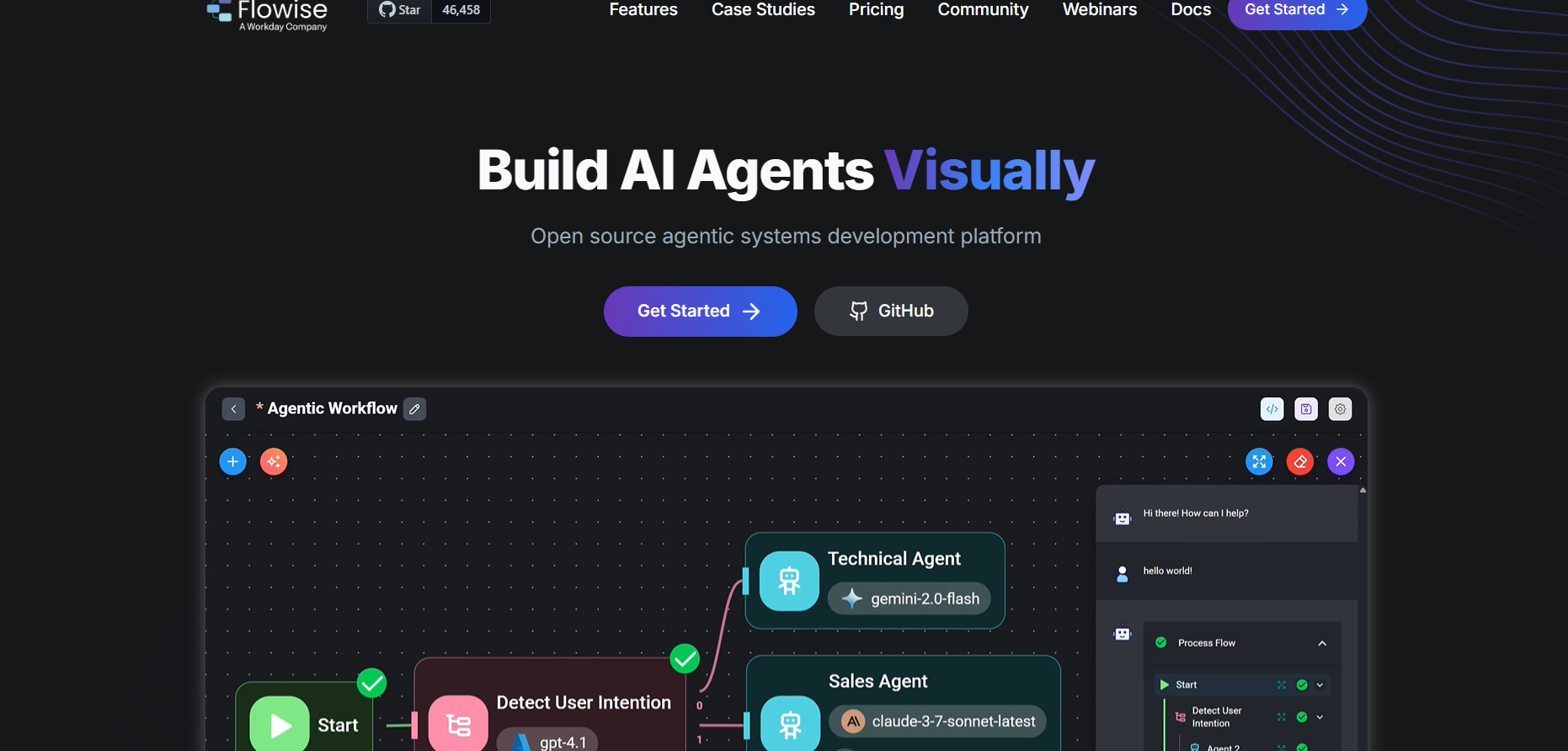
Flowise AI
Flowise AI is an open-source, visual tool that allows users to build, deploy, and manage AI workflows and chatbots powered by large language models without needing to code. It provides a drag-and-drop interface where users can visually connect LangChain components, APIs, data sources, and models to create complex AI systems easily. With Flowise AI, developers, analysts, and businesses can build chatbots, RAG pipelines, or automation systems through an intuitive UI rather than scripting everything manually. Its no-code design accelerates prototyping and deployment, enabling faster experimentation with LLM-powered workflows.
Flowise AI
Flowise AI is an open-source, visual tool that allows users to build, deploy, and manage AI workflows and chatbots powered by large language models without needing to code. It provides a drag-and-drop interface where users can visually connect LangChain components, APIs, data sources, and models to create complex AI systems easily. With Flowise AI, developers, analysts, and businesses can build chatbots, RAG pipelines, or automation systems through an intuitive UI rather than scripting everything manually. Its no-code design accelerates prototyping and deployment, enabling faster experimentation with LLM-powered workflows.
Flowise AI
Flowise AI is an open-source, visual tool that allows users to build, deploy, and manage AI workflows and chatbots powered by large language models without needing to code. It provides a drag-and-drop interface where users can visually connect LangChain components, APIs, data sources, and models to create complex AI systems easily. With Flowise AI, developers, analysts, and businesses can build chatbots, RAG pipelines, or automation systems through an intuitive UI rather than scripting everything manually. Its no-code design accelerates prototyping and deployment, enabling faster experimentation with LLM-powered workflows.
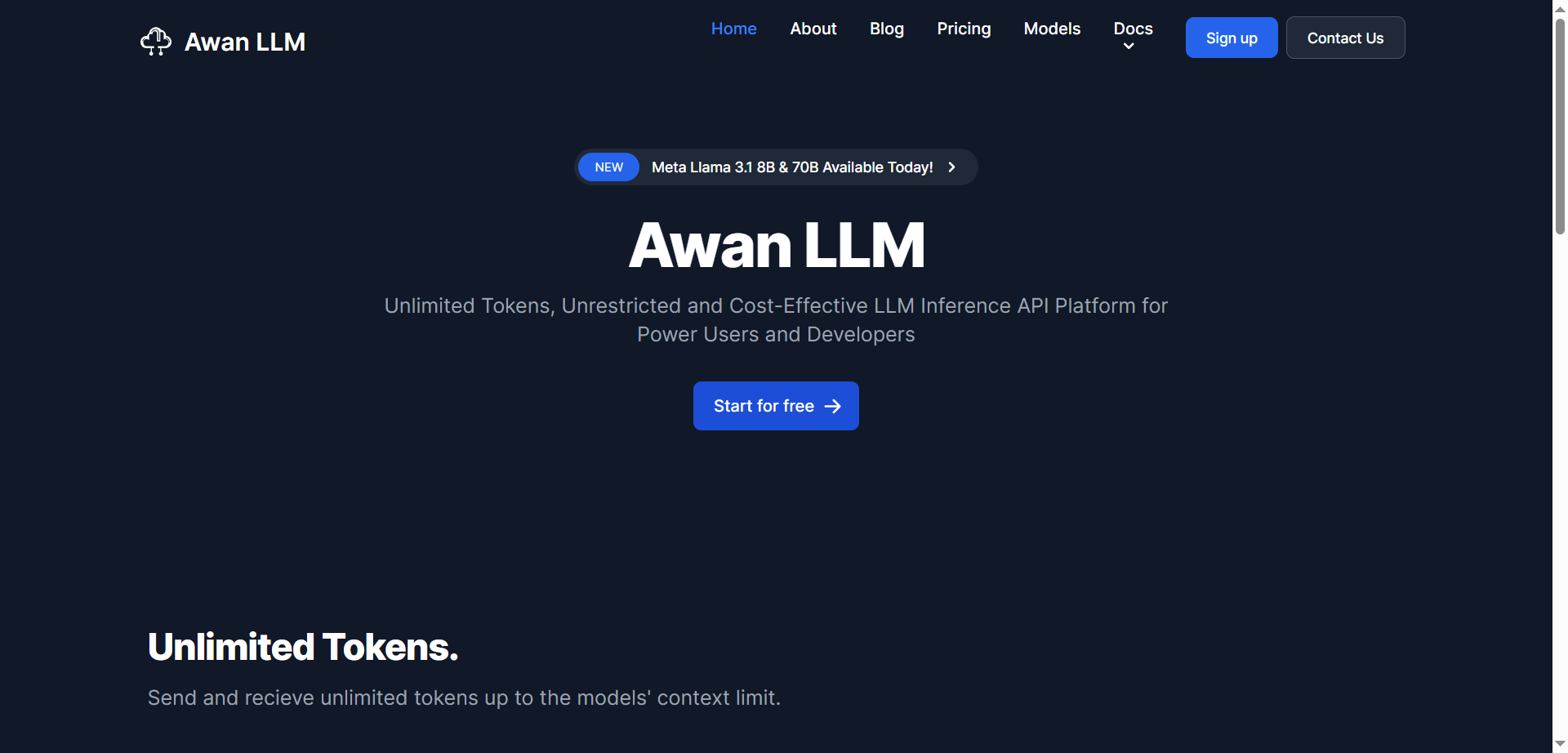

Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai