- Developers & Engineers: Deploy in agent-focused applications requiring long-context reasoning, tools, or code.
- Researchers & Data Scientists: Benchmark and explore model capabilities across extensive language, code, and reasoning tasks.
- Enterprises & Cloud Providers: Integrate into large-scale inference engines using NVIDIA hardware.
- Educators & Students: Utilize for advanced chain-of-thought, math problem solving, and programming support.
- Multilingual Application Builders: Fine-tune or use it in multiple languages at scale.
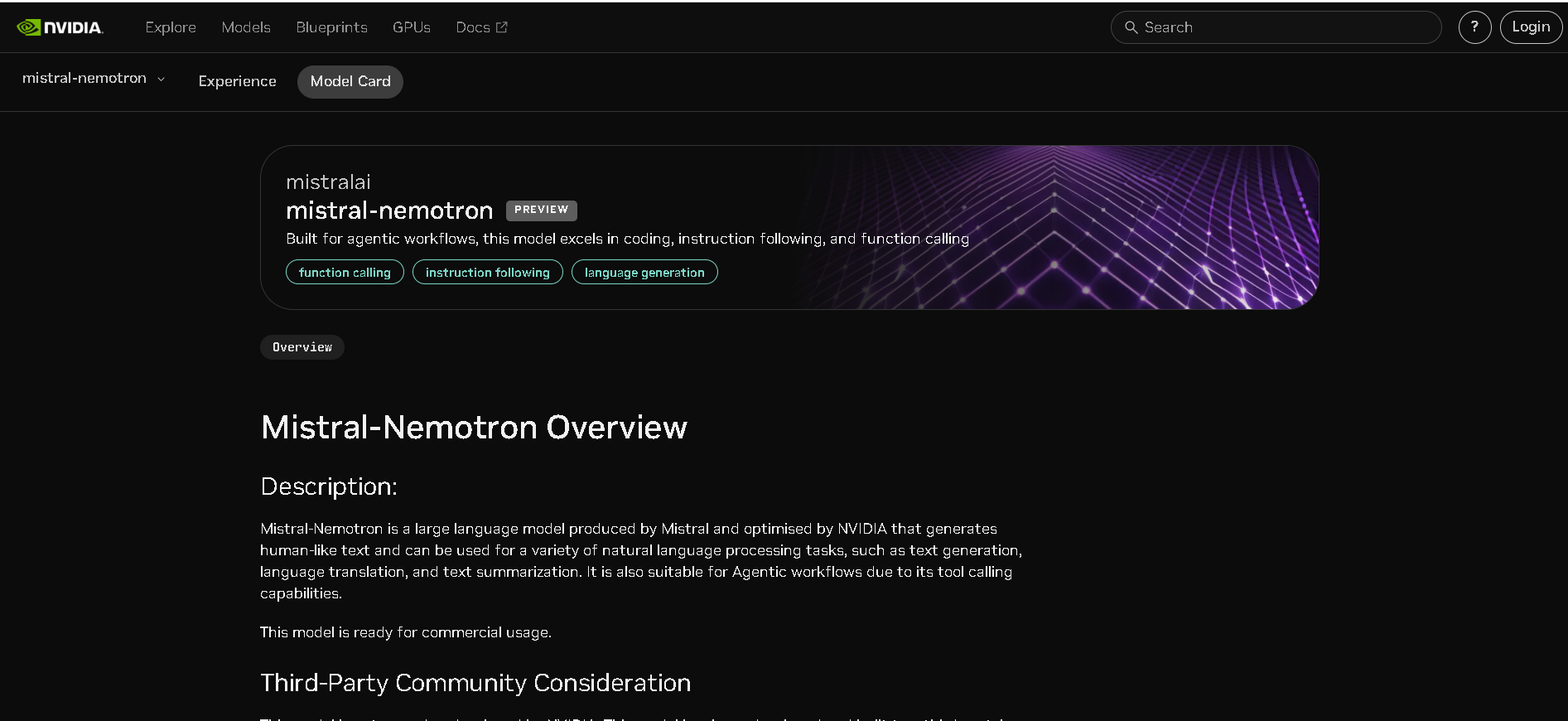
How to Use Mistral Nemotron?
- Access via NVIDIA NIM API: Available for inference on GPUs like Hopper with TensorRT-LLM or vLLM.
- Supply Long Prompts: Supports the full 128K-token context for rich reasoning and instruction chaining.
- Call Functions & Tools: Leverage built-in instruction-following capabilities for sophisticated agentic workflows.
- Perform in Inference-Optimized Environments: Use on H100/Hopper GPUs with NVIDIA’s optimized runtime.
- Monitor Benchmark Scores: Check benchmark metrics to ensure quality and accuracy for your use case.
- Ultra-Long Context: Handles up to 128K tokens—far beyond typical LLM limits.
- Inference-Optimized: Runs efficiently via TensorRT-LLM and vLLM on NVIDIA GPUs.
- Agent-Ready Design: Built for function calling and tool-based, multi-step operations.
- Commercially Ready: Licensed and deployable for enterprise use via NVIDIA API.
- Agent-Ready Design: Built for function calling and tool-based, multi-step operations.
- Commercially Ready: Licensed and deployable for enterprise use via NVIDIA API.
- Support for 128K‑token context suits long document and code workflows
- Optimized for high-throughput NVIDIA inference stacks
- Excellent coding, math, and reasoning performance
- Multilingual capabilities across Asian and European languages
- Function-calling and instruction-following tailored for agents
- Still in preview—access requires NVIDIA’s trial API terms
- Large memory requirements—Hopper/H100 GPUs needed
- Moderately lower code-score on LiveCodeBench compared to specialized models.
API only
$0.15/$0.15 per 1M tokens
$0.15 per 1M output token
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

GPT-4o Mini Realtime Preview is a lightweight, high-speed variant of OpenAI’s flagship multimodal model, GPT-4o. Built for blazing-fast, cost-efficient inference across text, vision, and voice inputs, this preview version is optimized for real-time responsiveness—without compromising on core intelligence. Whether you’re building chatbots, interactive voice tools, or lightweight apps, GPT-4o Mini delivers smart performance with minimal latency and compute load. It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.
GPT-4o Mini Realtime Preview is a lightweight, high-speed variant of OpenAI’s flagship multimodal model, GPT-4o. Built for blazing-fast, cost-efficient inference across text, vision, and voice inputs, this preview version is optimized for real-time responsiveness—without compromising on core intelligence. Whether you’re building chatbots, interactive voice tools, or lightweight apps, GPT-4o Mini delivers smart performance with minimal latency and compute load. It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.
GPT-4o Mini Realtime Preview is a lightweight, high-speed variant of OpenAI’s flagship multimodal model, GPT-4o. Built for blazing-fast, cost-efficient inference across text, vision, and voice inputs, this preview version is optimized for real-time responsiveness—without compromising on core intelligence. Whether you’re building chatbots, interactive voice tools, or lightweight apps, GPT-4o Mini delivers smart performance with minimal latency and compute load. It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.
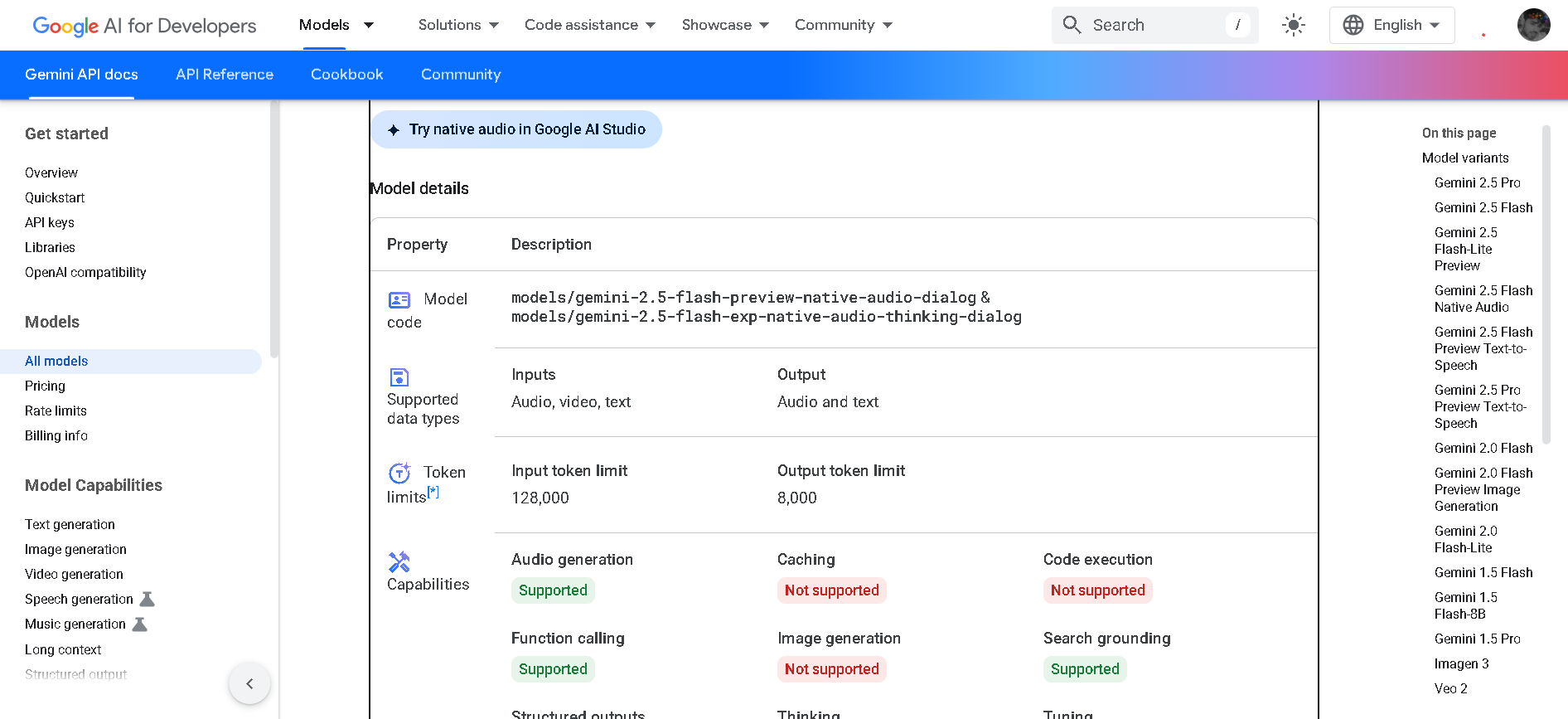
Gemini 2.5 Flash Native Audio is a preview variant of Google DeepMind’s fast, reasoning-enabled “Flash” model, enhanced to support natural, expressive audio dialogue. It allows real-time back-and-forth voice conversation—responding to tone, background noise, affect, and multilingual input—while maintaining its high-speed, multimodal, hybrid-reasoning capabilities.
Gemini 2.5 Flash Native Audio is a preview variant of Google DeepMind’s fast, reasoning-enabled “Flash” model, enhanced to support natural, expressive audio dialogue. It allows real-time back-and-forth voice conversation—responding to tone, background noise, affect, and multilingual input—while maintaining its high-speed, multimodal, hybrid-reasoning capabilities.
Gemini 2.5 Flash Native Audio is a preview variant of Google DeepMind’s fast, reasoning-enabled “Flash” model, enhanced to support natural, expressive audio dialogue. It allows real-time back-and-forth voice conversation—responding to tone, background noise, affect, and multilingual input—while maintaining its high-speed, multimodal, hybrid-reasoning capabilities.
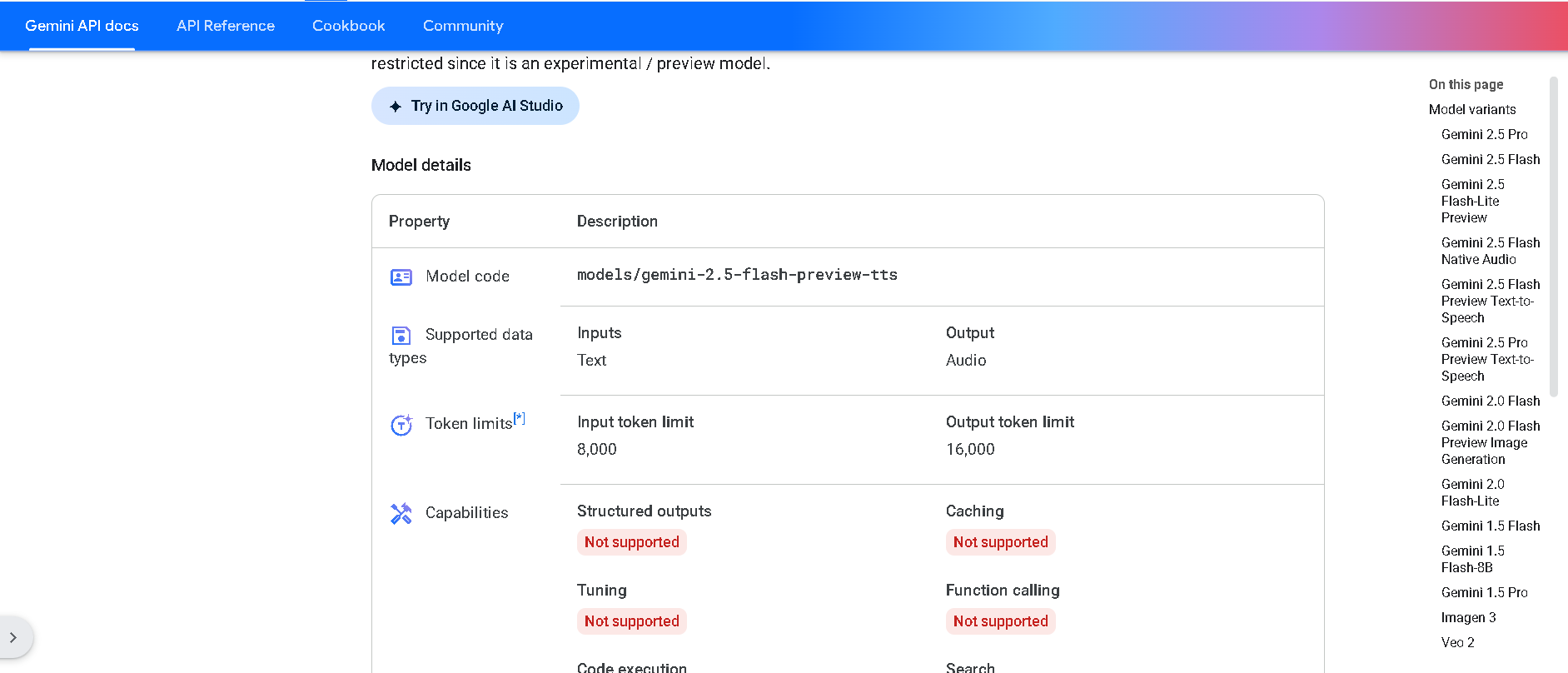
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
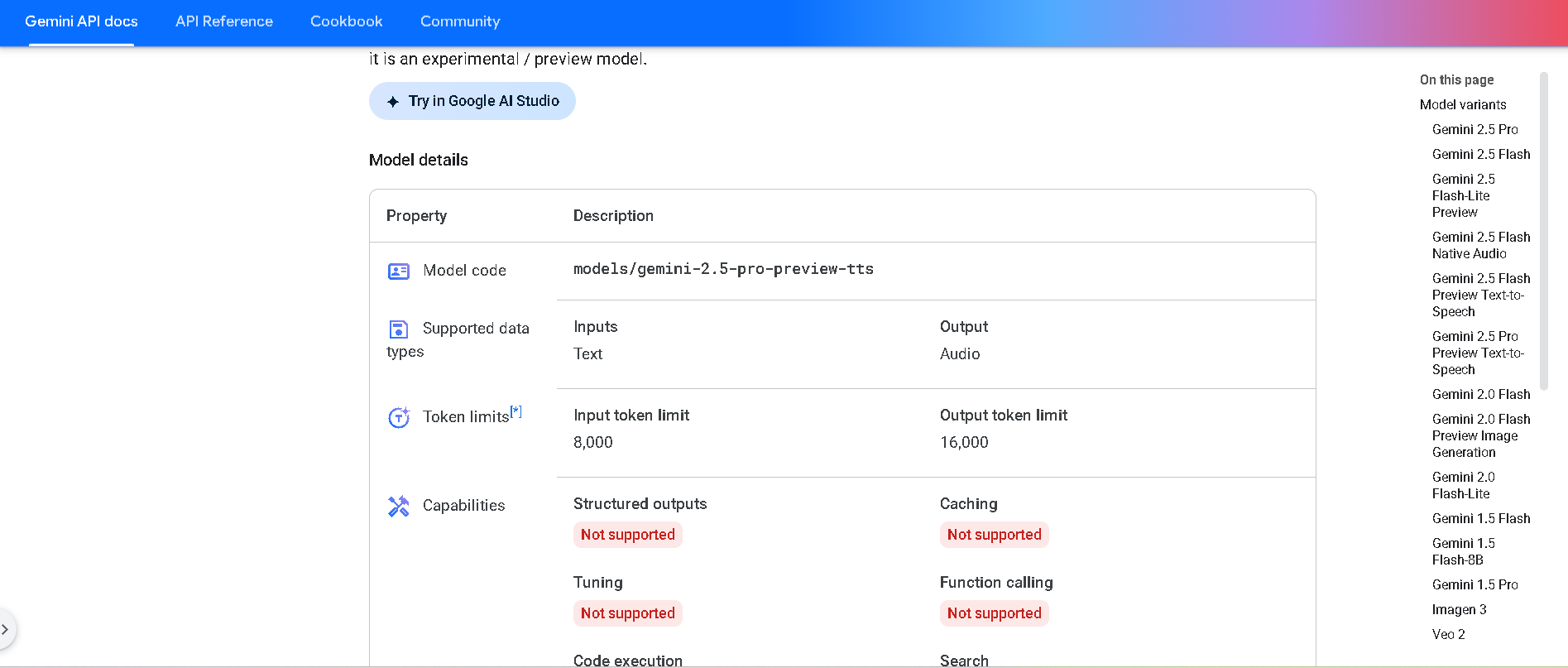
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.

DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
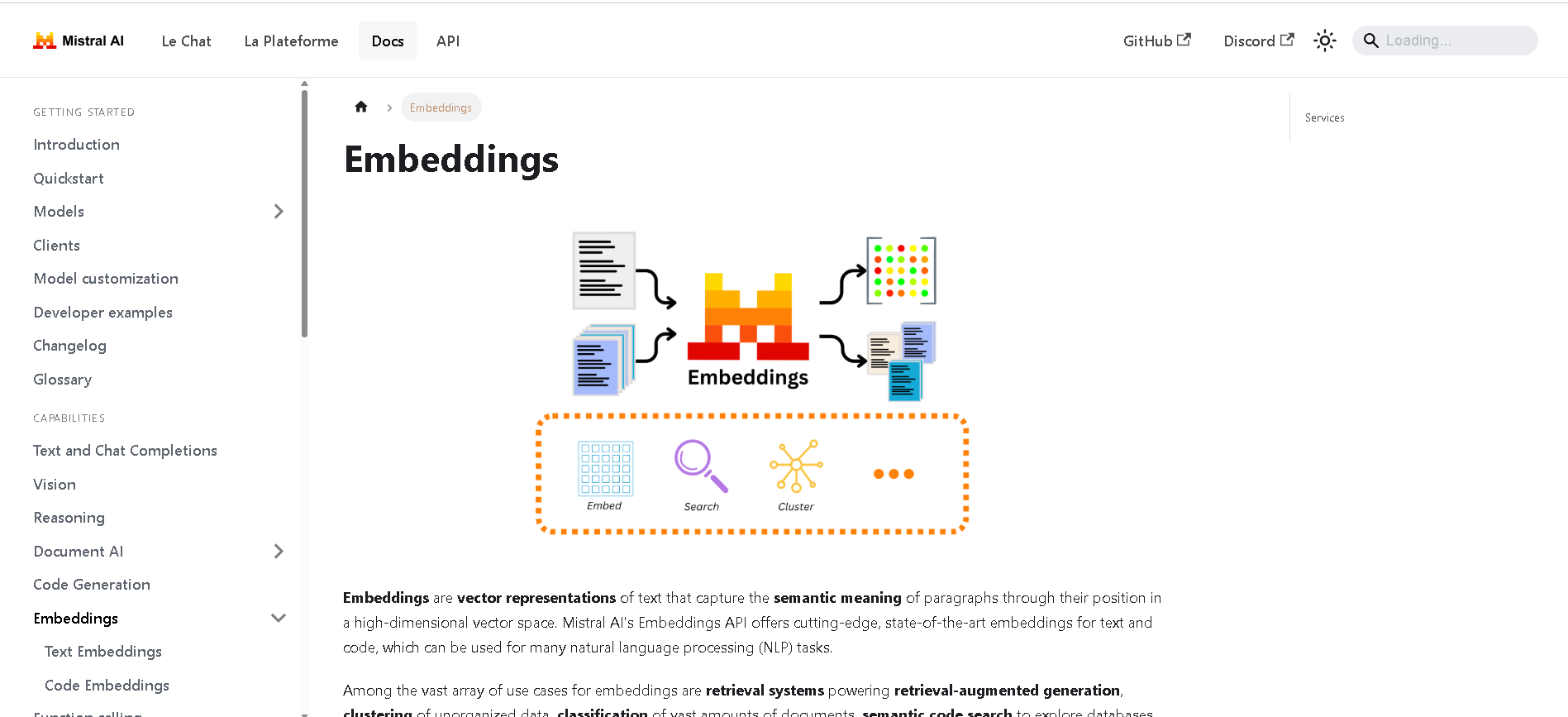
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai