
It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.
- Developers & Startups: Build low-cost, high-performance AI apps that scale.
- Voice Interface Designers: Create real-time, voice-driven assistants without lag.
- AI Tool Builders: Add smart replies, image understanding, or voice output in light apps.
- IoT & Edge Device Engineers: Deploy compact multimodal models in constrained environments.
- Customer Support Teams: Deliver snappy, voice-enabled AI support with minimal infrastructure.
- EdTech & Accessibility Creators: Enable multimodal, real-time experiences on mobile and web.
🛠️ How to Use GPT-4o Mini Realtime Preview?
- Step 1: Choose gpt-4o-mini in API Settings: From the OpenAI platform, select gpt-4o-mini for realtime preview access.
- Step 2: Select Your Input Type: Supports text, audio, and image input—ideal for dynamic interaction design.
- Step 3: Stream Responses in Real Time: Use streaming endpoints for immediate, low-latency interaction and audio responses.
- Step 4: Integrate with Lightweight Apps: Perfect for mobile, embedded, and browser-based apps where performance matters.
- Step 5: Test, Fine-Tune, and Iterate: Monitor latency, tune prompts, and balance performance with cost.
- Compact Yet Multimodal: Combines text, vision, and voice processing in a smaller, faster model.
- Low Latency Voice Output: Voice responses arrive in milliseconds—great for real-time apps.
- Efficient Compute Usage: Smaller footprint means better cost-efficiency and faster scaling.
- Fast, Expressive Speech Synthesis: Outputs natural, emotive speech in real time.
- Ideal for Prototyping: Rapid iteration for real-world applications without GPT-4-sized costs.
- Seamless API Access: Works within the same API framework as other OpenAI models.
- Super Low Latency: Practically instant responses make for a human-like experience.
- Cost-Efficient: Lighter model means reduced costs for developers and businesses.
- Multimodal in a Mini Package: All the magic—text, vision, and voice—in a smaller, nimbler form.
- Great for Mobile & Edge: Perfect for apps where every millisecond and megabyte counts.
- Streaming Capabilities: Real-time conversation, audio replies, and more with smooth streaming.
- Still in Preview: Expect possible changes, limitations, or access restrictions.
- Reduced Context Window: May not handle long conversations or documents as well as full GPT-4o.
- Fewer Features Than Full Model: Lacks the advanced tool integrations of GPT-4 Turbo.
- Requires Prompt Discipline: You’ll need to carefully optimize prompts for best performance.
- Early-Stage API Behavior: Some quirks may arise as the preview evolves.
Text Tokens
$0.60/$2.40 for 1M tokens
Input: $0.60
Cached Input: $0.30
Output: $2.40
Audio Tokens
$10/$20 for 1M tokens
Input: $10.00
Cached Input: $0.30
Output: $20.00
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI o1
o1 is a fast, highly capable language model developed by OpenAI, optimized for performance, cost-efficiency, and general-purpose use. It represents the entry point into OpenAI’s GPT-4 class of models, delivering high-quality natural language generation, comprehension, and interaction at lower latency and cost than GPT-4 Turbo. Despite being a newer and smaller variant, o1 is robust enough for most AI applications—from content generation to customer support—making it a reliable choice for developers looking to build intelligent and responsive systems.
OpenAI o1
o1 is a fast, highly capable language model developed by OpenAI, optimized for performance, cost-efficiency, and general-purpose use. It represents the entry point into OpenAI’s GPT-4 class of models, delivering high-quality natural language generation, comprehension, and interaction at lower latency and cost than GPT-4 Turbo. Despite being a newer and smaller variant, o1 is robust enough for most AI applications—from content generation to customer support—making it a reliable choice for developers looking to build intelligent and responsive systems.
OpenAI o1
o1 is a fast, highly capable language model developed by OpenAI, optimized for performance, cost-efficiency, and general-purpose use. It represents the entry point into OpenAI’s GPT-4 class of models, delivering high-quality natural language generation, comprehension, and interaction at lower latency and cost than GPT-4 Turbo. Despite being a newer and smaller variant, o1 is robust enough for most AI applications—from content generation to customer support—making it a reliable choice for developers looking to build intelligent and responsive systems.

OpenAI GPT Image 1
GPT-Image-1 is OpenAI's state-of-the-art vision model designed to understand and interpret images with human-like perception. It enables developers and businesses to analyze, summarize, and extract detailed insights from images using natural language. Whether you're building AI agents, accessibility tools, or image-driven workflows, GPT-Image-1 brings powerful multimodal capabilities into your applications with impressive accuracy. Optimized for use via API, it can handle diverse image types—charts, screenshots, photographs, documents, and more—making it one of the most versatile models in OpenAI’s portfolio.
OpenAI GPT Image 1
GPT-Image-1 is OpenAI's state-of-the-art vision model designed to understand and interpret images with human-like perception. It enables developers and businesses to analyze, summarize, and extract detailed insights from images using natural language. Whether you're building AI agents, accessibility tools, or image-driven workflows, GPT-Image-1 brings powerful multimodal capabilities into your applications with impressive accuracy. Optimized for use via API, it can handle diverse image types—charts, screenshots, photographs, documents, and more—making it one of the most versatile models in OpenAI’s portfolio.
OpenAI GPT Image 1
GPT-Image-1 is OpenAI's state-of-the-art vision model designed to understand and interpret images with human-like perception. It enables developers and businesses to analyze, summarize, and extract detailed insights from images using natural language. Whether you're building AI agents, accessibility tools, or image-driven workflows, GPT-Image-1 brings powerful multimodal capabilities into your applications with impressive accuracy. Optimized for use via API, it can handle diverse image types—charts, screenshots, photographs, documents, and more—making it one of the most versatile models in OpenAI’s portfolio.

grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.
grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.
grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.

grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.

Grok 3 Mini
Grok 3 Mini is xAI’s compact, cost-efficient reasoning variant of the flagship Grok 3 model. Released alongside Grok 3 in February 2025, it offers many of the same advanced reasoning capabilities—like chain-of-thought “Think” mode and multimodal support—with lower compute and faster responses. It's ideal for logic-heavy tasks that don't require the depth of the full version.
Grok 3 Mini
Grok 3 Mini is xAI’s compact, cost-efficient reasoning variant of the flagship Grok 3 model. Released alongside Grok 3 in February 2025, it offers many of the same advanced reasoning capabilities—like chain-of-thought “Think” mode and multimodal support—with lower compute and faster responses. It's ideal for logic-heavy tasks that don't require the depth of the full version.
Grok 3 Mini
Grok 3 Mini is xAI’s compact, cost-efficient reasoning variant of the flagship Grok 3 model. Released alongside Grok 3 in February 2025, it offers many of the same advanced reasoning capabilities—like chain-of-thought “Think” mode and multimodal support—with lower compute and faster responses. It's ideal for logic-heavy tasks that don't require the depth of the full version.

grok-3-mini-latest
Grok 3 Mini is xAI’s compact, reasoning-focused variant of the Grok 3 series. Released in February 2025 alongside the flagship model, it's optimized for cost-effective, transparent chain-of-thought reasoning via "Think" mode, with full multimodal input and access to xAI’s Colossus-trained capabilities. The latest version supports live preview on Azure AI Foundry and GitHub Models—combining speed, affordability, and logic traversal in real-time workflows.
grok-3-mini-latest
Grok 3 Mini is xAI’s compact, reasoning-focused variant of the Grok 3 series. Released in February 2025 alongside the flagship model, it's optimized for cost-effective, transparent chain-of-thought reasoning via "Think" mode, with full multimodal input and access to xAI’s Colossus-trained capabilities. The latest version supports live preview on Azure AI Foundry and GitHub Models—combining speed, affordability, and logic traversal in real-time workflows.
grok-3-mini-latest
Grok 3 Mini is xAI’s compact, reasoning-focused variant of the Grok 3 series. Released in February 2025 alongside the flagship model, it's optimized for cost-effective, transparent chain-of-thought reasoning via "Think" mode, with full multimodal input and access to xAI’s Colossus-trained capabilities. The latest version supports live preview on Azure AI Foundry and GitHub Models—combining speed, affordability, and logic traversal in real-time workflows.

grok-3-mini-fast
Grok 3 Mini Fast is the low-latency, high-performance version of xAI’s Grok 3 Mini model. Released in beta around May 2025, it offers the same visible chain-of-thought reasoning as Grok 3 Mini but delivers responses significantly faster, powered by optimized infrastructure. It supports up to 131,072 tokens of context.
grok-3-mini-fast
Grok 3 Mini Fast is the low-latency, high-performance version of xAI’s Grok 3 Mini model. Released in beta around May 2025, it offers the same visible chain-of-thought reasoning as Grok 3 Mini but delivers responses significantly faster, powered by optimized infrastructure. It supports up to 131,072 tokens of context.
grok-3-mini-fast
Grok 3 Mini Fast is the low-latency, high-performance version of xAI’s Grok 3 Mini model. Released in beta around May 2025, it offers the same visible chain-of-thought reasoning as Grok 3 Mini but delivers responses significantly faster, powered by optimized infrastructure. It supports up to 131,072 tokens of context.
Grok 3 Mini Fast is xAI’s most recent, low-latency variant of the compact Grok 3 Mini model. It maintains full chain-of-thought “Think” reasoning and multimodal support while delivering faster response times. The model handles up to 131,072 tokens of context and is now widely accessible in beta via xAI API and select cloud platforms.
Grok 3 Mini Fast is xAI’s most recent, low-latency variant of the compact Grok 3 Mini model. It maintains full chain-of-thought “Think” reasoning and multimodal support while delivering faster response times. The model handles up to 131,072 tokens of context and is now widely accessible in beta via xAI API and select cloud platforms.
Grok 3 Mini Fast is xAI’s most recent, low-latency variant of the compact Grok 3 Mini model. It maintains full chain-of-thought “Think” reasoning and multimodal support while delivering faster response times. The model handles up to 131,072 tokens of context and is now widely accessible in beta via xAI API and select cloud platforms.

Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.

Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.

Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
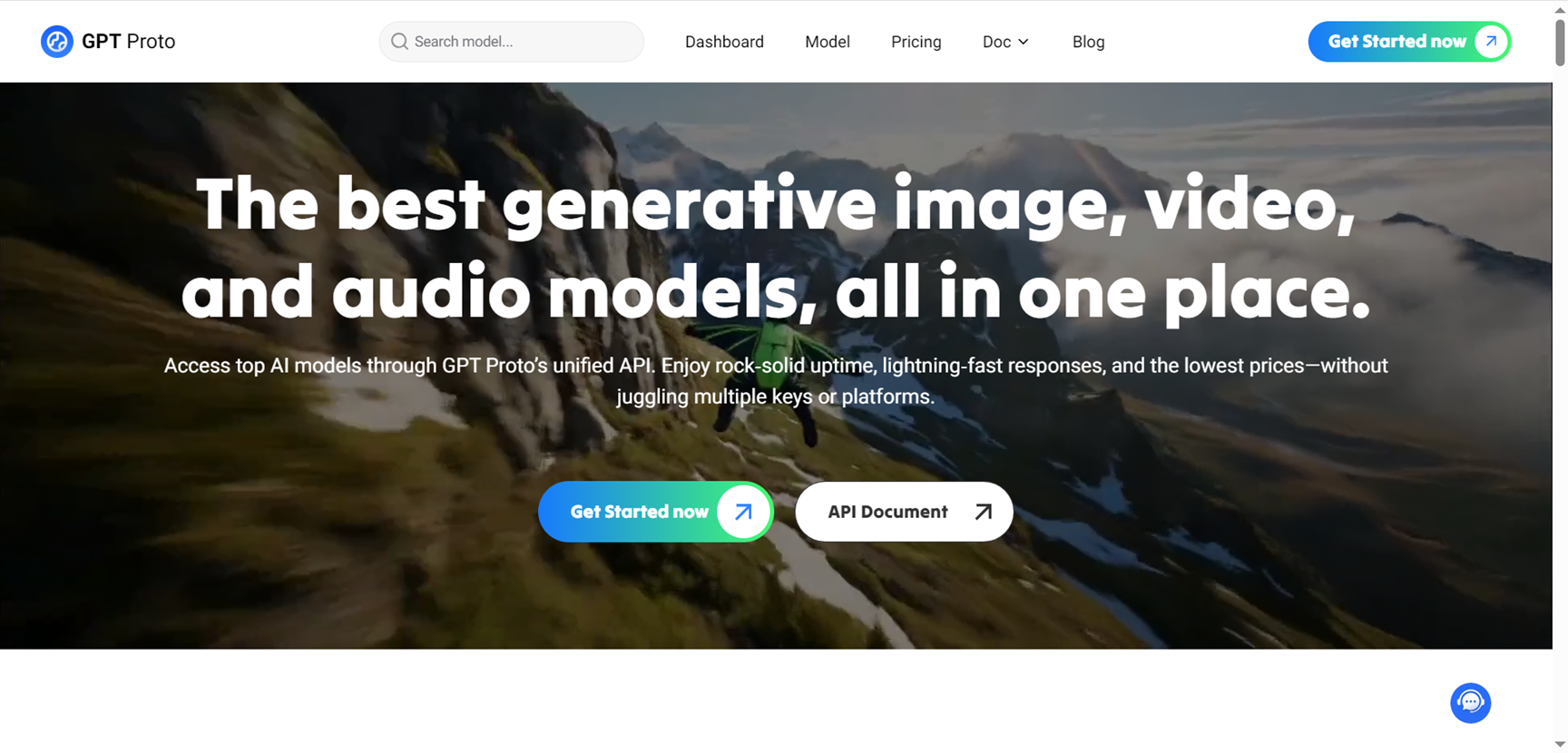

GPT Proto
GPT Proto provides developers with a unified API to access top AI models for text, image, video, and audio generation, offering rock-solid uptime, lightning-fast responses, and the lowest prices without managing multiple keys or platforms. It aggregates leading models like GPT-5 series, Claude Opus/Sonnet/Haiku, Gemini variants, Grok, and specialized tools for creators, with significant discounts such as 40% off market rates on many. From solo projects to enterprise scale, it ensures 95% of requests respond within 20 seconds, half in just 6 seconds, via robust infrastructure and failover. Quick setup lets you sign up, add credits, generate one API key, and integrate seamlessly into apps, agents, or workflows for prototyping or production.
GPT Proto
GPT Proto provides developers with a unified API to access top AI models for text, image, video, and audio generation, offering rock-solid uptime, lightning-fast responses, and the lowest prices without managing multiple keys or platforms. It aggregates leading models like GPT-5 series, Claude Opus/Sonnet/Haiku, Gemini variants, Grok, and specialized tools for creators, with significant discounts such as 40% off market rates on many. From solo projects to enterprise scale, it ensures 95% of requests respond within 20 seconds, half in just 6 seconds, via robust infrastructure and failover. Quick setup lets you sign up, add credits, generate one API key, and integrate seamlessly into apps, agents, or workflows for prototyping or production.
GPT Proto
GPT Proto provides developers with a unified API to access top AI models for text, image, video, and audio generation, offering rock-solid uptime, lightning-fast responses, and the lowest prices without managing multiple keys or platforms. It aggregates leading models like GPT-5 series, Claude Opus/Sonnet/Haiku, Gemini variants, Grok, and specialized tools for creators, with significant discounts such as 40% off market rates on many. From solo projects to enterprise scale, it ensures 95% of requests respond within 20 seconds, half in just 6 seconds, via robust infrastructure and failover. Quick setup lets you sign up, add credits, generate one API key, and integrate seamlessly into apps, agents, or workflows for prototyping or production.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai