
- Developers & Engineers: Build chat assistants, document readers, or multimodal agents with vision and long-context capabilities.
- Researchers & Data Scientists: Analyze long documents, codebases, or images—leveraging chain-of-thought and multimodal reasoning.
- Enterprises & Startups: Deploy a powerful multimodal LLM on-premises or in cloud environments under Apache 2.0 license.
- Educators & Content Creators: Generate, edit, and understand multimodal content across languages and formats.
- Hobbyists & Open-Source Advocates: Run the model locally or in browsers with accessible hardware requirements.
How to Use Mistral Small 3.1?
- Choose Version: Download base or instruct checkpoints for `mistral-small-2503`.
- Deploy Locally or via API: Use Ollama, vLLM, or Hugging Face tools; also available on Google Cloud Vertex AI.
- Send Text or Vision Prompts: Input text, images, or combined media within a massive 128K-token window.
- Use for Tasks: Handle instruction-following, visual Q&A (e.g., ChartQA, DocVQA), long-document understanding, multilingual tasks.
- Optimize Performance: Fine-tune, quantize, or function-call within low-latency workflows.
- Multimodal Power: Integrates strong image understanding into a small, open-source model.
- 128K Context: Processes very long conversations, documents, or codebases seamlessly.
- High Benchmarks: Outperforms Gemma 3 and GPT-4o Mini in MMLU, Math, vision, and multilingual tests.
- Fast, Lightweight Deployment: Ideal for consumer-grade GPUs and MacBooks; 150 tokens/sec makes it responsive.
- Open, Commercial Use: Apache 2.0 license encourages wide adoption and modification for RAG, agents, and custom workflows.
- Full multimodal capabilities in a 24B model
- Huge 128K context window for long-form tasks
- Excellent benchmarks vs closed models
- Runs on accessible hardware with low latency
- Permissive Apache 2.0 license for commercial use
- Vision support is capped at inference-level image understanding
- Model size may still be heavy for mobile deployment
- May consume substantial memory when handling 128K contexts
API only
$0.5/$1.5 per 1M tokens
$1.5 per 1M output tokens
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
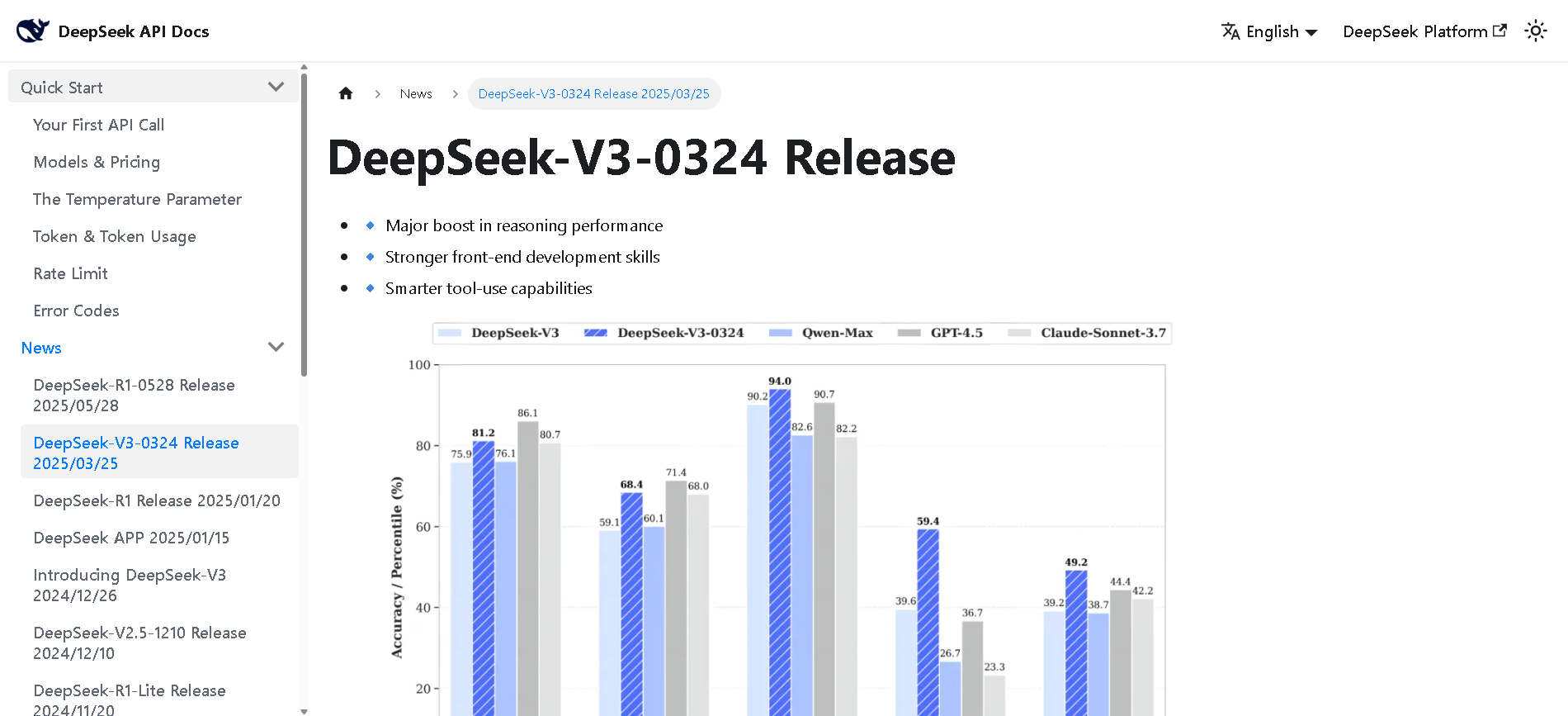
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.

DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.

DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Codestral 25.01 is Mistral AI’s upgraded code-generation model, released January 13, 2025. Featuring a more efficient architecture and improved tokenizer, it delivers code completion and intelligence about 2× faster than its predecessor, with support for fill-in-the-middle (FIM), code correction, test generation, and proficiency in over 80 programming languages, all within a 256K-token context window.
Codestral 25.01 is Mistral AI’s upgraded code-generation model, released January 13, 2025. Featuring a more efficient architecture and improved tokenizer, it delivers code completion and intelligence about 2× faster than its predecessor, with support for fill-in-the-middle (FIM), code correction, test generation, and proficiency in over 80 programming languages, all within a 256K-token context window.
Codestral 25.01 is Mistral AI’s upgraded code-generation model, released January 13, 2025. Featuring a more efficient architecture and improved tokenizer, it delivers code completion and intelligence about 2× faster than its predecessor, with support for fill-in-the-middle (FIM), code correction, test generation, and proficiency in over 80 programming languages, all within a 256K-token context window.
Mistral Document AI is Mistral AI’s enterprise-grade document processing platform, launched May 2025. It combines state-of-the-art OCR model mistral-ocr-latest with structured data extraction, document Q&A, and natural language understanding—delivering 99%+ OCR accuracy, support for over 40 languages and complex layouts (tables, forms, handwriting), and blazing-fast processing at up to 2,000 pages/min per GPU.
Mistral Document AI is Mistral AI’s enterprise-grade document processing platform, launched May 2025. It combines state-of-the-art OCR model mistral-ocr-latest with structured data extraction, document Q&A, and natural language understanding—delivering 99%+ OCR accuracy, support for over 40 languages and complex layouts (tables, forms, handwriting), and blazing-fast processing at up to 2,000 pages/min per GPU.
Mistral Document AI is Mistral AI’s enterprise-grade document processing platform, launched May 2025. It combines state-of-the-art OCR model mistral-ocr-latest with structured data extraction, document Q&A, and natural language understanding—delivering 99%+ OCR accuracy, support for over 40 languages and complex layouts (tables, forms, handwriting), and blazing-fast processing at up to 2,000 pages/min per GPU.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.

Pixtral Large is Mistral AI’s latest multimodal powerhouse, launched November 18, 2024. Built atop the 123B‑parameter Mistral Large 2, it features a 124B‑parameter multimodal decoder paired with a 1B‑parameter vision encoder, and supports a massive 128K‑token context window—enabling it to process up to 30 high-resolution images or ~300-page documents.
Pixtral Large is Mistral AI’s latest multimodal powerhouse, launched November 18, 2024. Built atop the 123B‑parameter Mistral Large 2, it features a 124B‑parameter multimodal decoder paired with a 1B‑parameter vision encoder, and supports a massive 128K‑token context window—enabling it to process up to 30 high-resolution images or ~300-page documents.
Pixtral Large is Mistral AI’s latest multimodal powerhouse, launched November 18, 2024. Built atop the 123B‑parameter Mistral Large 2, it features a 124B‑parameter multimodal decoder paired with a 1B‑parameter vision encoder, and supports a massive 128K‑token context window—enabling it to process up to 30 high-resolution images or ~300-page documents.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Solar Mini is Upstage’s compact, high-performance large language model (LLM) with under 30 billion parameters, engineered for exceptional speed and efficiency without sacrificing quality. It outperforms comparable models like Llama2, Mistral 7B, and Ko-Alpaca on major benchmarks, delivering responses similar to GPT-3.5 but 2.5 times faster. Thanks to its innovative Depth Up-scaling (DUS) and continued pre-training, Solar Mini is easily customized for domain-specific tasks, supports on-device deployment, and is especially suited for decentralized, responsive AI applications.
Solar Mini is Upstage’s compact, high-performance large language model (LLM) with under 30 billion parameters, engineered for exceptional speed and efficiency without sacrificing quality. It outperforms comparable models like Llama2, Mistral 7B, and Ko-Alpaca on major benchmarks, delivering responses similar to GPT-3.5 but 2.5 times faster. Thanks to its innovative Depth Up-scaling (DUS) and continued pre-training, Solar Mini is easily customized for domain-specific tasks, supports on-device deployment, and is especially suited for decentralized, responsive AI applications.
Solar Mini is Upstage’s compact, high-performance large language model (LLM) with under 30 billion parameters, engineered for exceptional speed and efficiency without sacrificing quality. It outperforms comparable models like Llama2, Mistral 7B, and Ko-Alpaca on major benchmarks, delivering responses similar to GPT-3.5 but 2.5 times faster. Thanks to its innovative Depth Up-scaling (DUS) and continued pre-training, Solar Mini is easily customized for domain-specific tasks, supports on-device deployment, and is especially suited for decentralized, responsive AI applications.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai