
- Developers & AI Engineers: Integrate fast, efficient LLMs for customized applications and edge devices.
- Businesses & Startups: Deploy scalable, cost-effective AI solutions without high compute requirements.
- Korean Language Researchers: Benefit from fine-tuned instruction following and alignment for Korean.
- Teams Building RAG Systems: Use Solar Mini to enhance output accuracy and relevance in retrieval-augmented generation workflows.
- Researchers & Labs: Experiment with open, license-free models for layout analysis, document extraction, and instruction tuning.
How to Use Solar Mini?
- Deploy On Device or Edge: Leverage the compact size for mobile and decentralized AI.
- Integrate via Hugging Face/Poe: Run and customize with leading model frameworks or demo platforms.
- Utilize for RAG Tasks: Combine with retrieval algorithms for improved, context-aware results.
- Process Documents & Data: Extract tables, charts, and layouts using the built-in OCR and analysis modules.
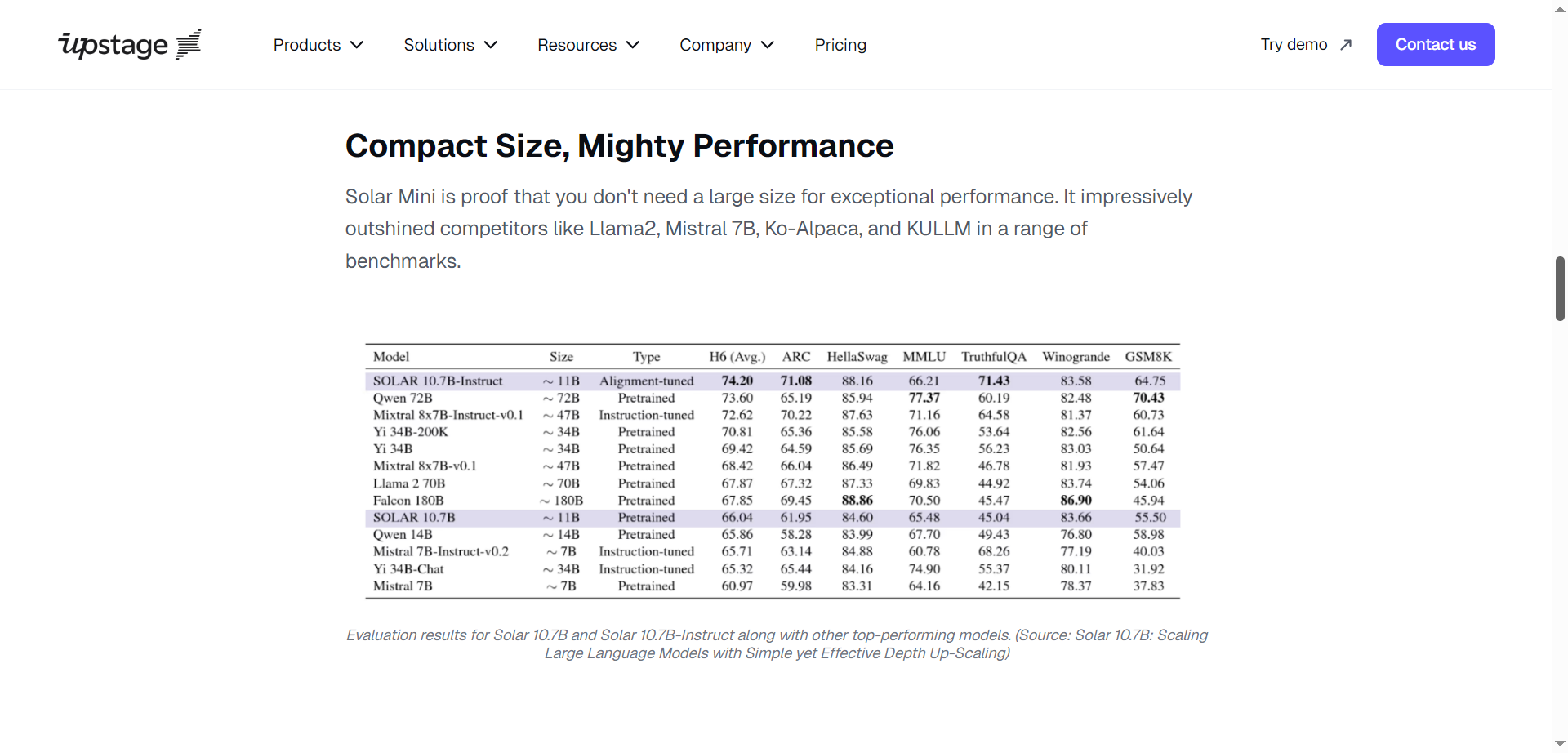
- Compact Yet Powerful Architecture: Delivers top-tier benchmarks with under 30B parameters.
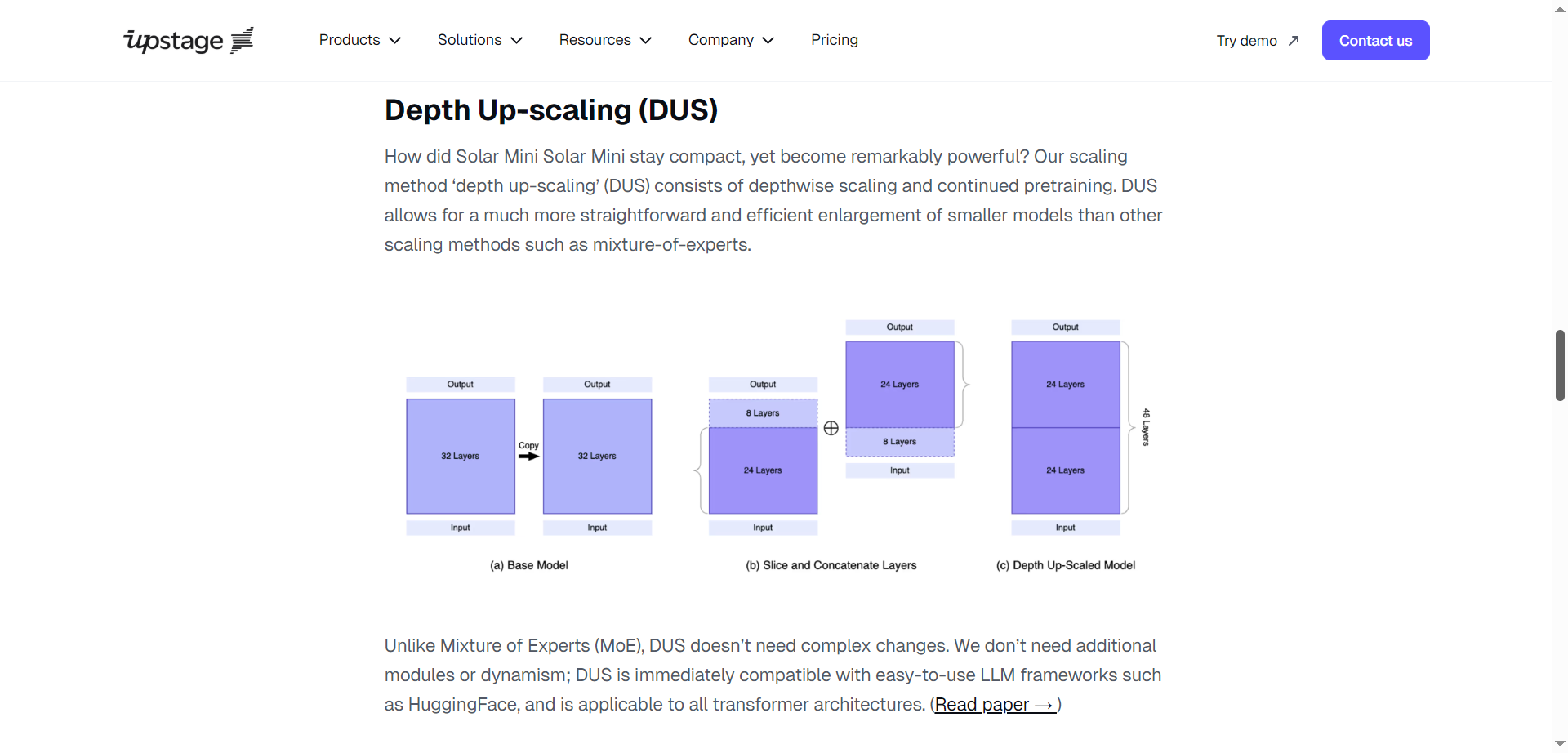
- Depth Up-scaling (DUS): Efficient scaling methodology compatible with most LLM frameworks.
- Fast Deployment and Customization: Reduced compute needs make on-device and edge AI practical.
- Strong Performance in Korean and Multilingual QA: Instruction and alignment tuning for real-world language use.
- Open Source License: Available under Apache 2.0 for broad experimentation and commercial use.
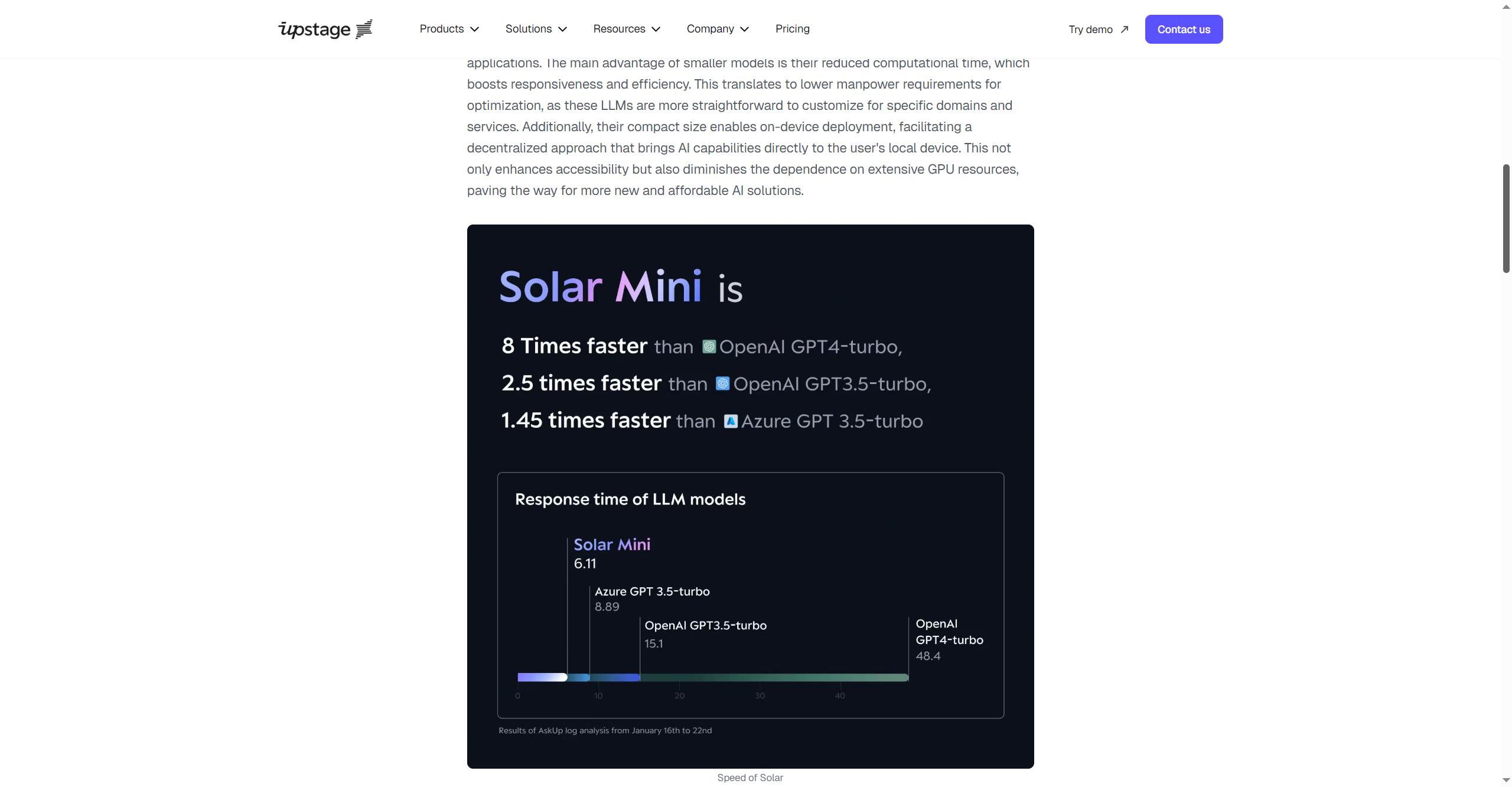
- Exceptional speed and efficiency for real-time and on-device AI.
- Benchmark performance rivals models nearly twice its size.
- Easy to customize and deploy for diverse domains and languages.
- Fully open source with a robust ecosystem for research and development.
- Smaller size may limit raw knowledge depth versus largest LLMs.
- Continued tuning and integration required for some domain tasks.
- Documentation and community support is newer than major closed models.
- Primarily optimized for Korean and RAG use cases—other languages may need extra adaptation.
Developers
Custom
Pay-as-you-go
Public models (See detailed pricing)
REST API
Public cloud
Help center
Enterprise
Custom
All public models
Custom LLM and RAG
Custom key information extraction
Custom document classification
REST API
Custom integrations
Serverless (API)
Private cloud
On-premises
Upstage Fine-tuning Studio
Upstage Labeling Studio
Personal information masking
Usage and resource monitoring
SSO
24/7 priority support
99% uptime SLA
Dedicated success manager
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
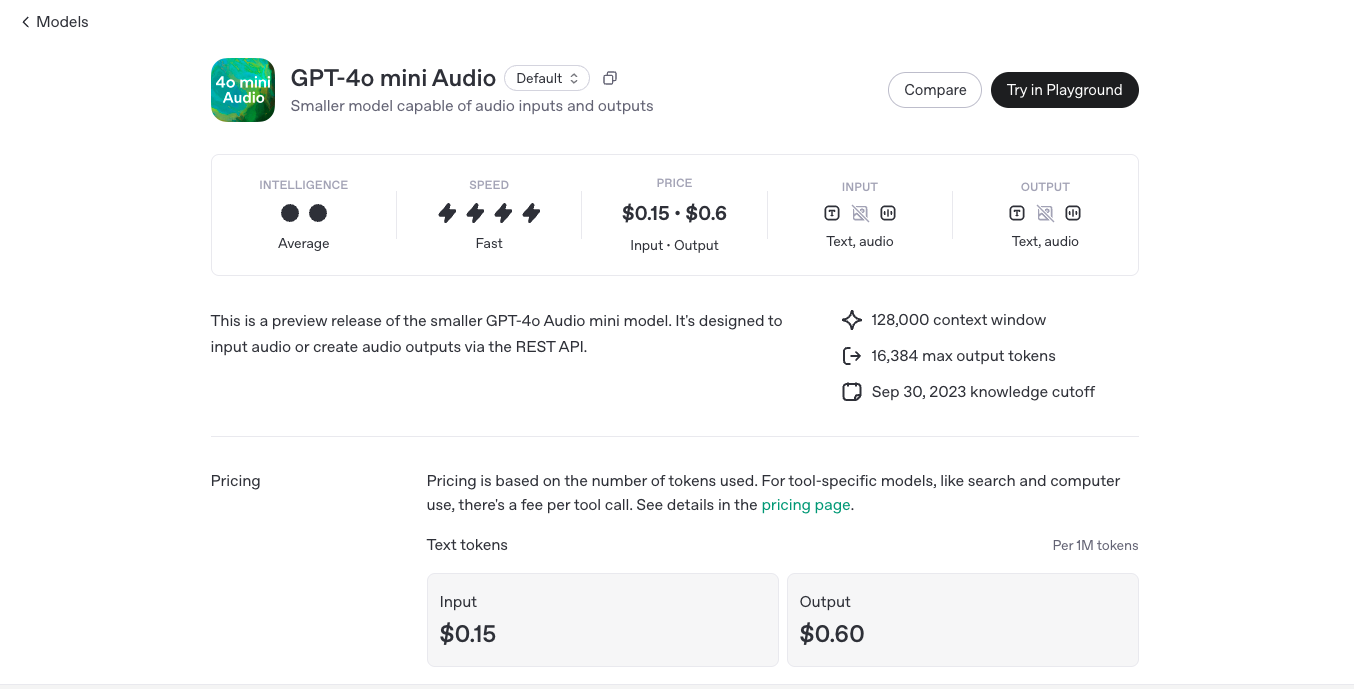
OpenAI GPT-4o Mini Audio is a lighter, faster, and cost-effective version of OpenAI's real-time voice AI, designed for natural and expressive AI conversations. It provides instant voice interactions with low latency, making it ideal for applications like AI assistants, customer service, and real-time translation without the high computational costs of full-scale GPT-4o Audio.
OpenAI GPT-4o Mini Audio is a lighter, faster, and cost-effective version of OpenAI's real-time voice AI, designed for natural and expressive AI conversations. It provides instant voice interactions with low latency, making it ideal for applications like AI assistants, customer service, and real-time translation without the high computational costs of full-scale GPT-4o Audio.
OpenAI GPT-4o Mini Audio is a lighter, faster, and cost-effective version of OpenAI's real-time voice AI, designed for natural and expressive AI conversations. It provides instant voice interactions with low latency, making it ideal for applications like AI assistants, customer service, and real-time translation without the high computational costs of full-scale GPT-4o Audio.

GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.

GPT-4o-mini-transcribe is a lightweight, high-speed speech-to-text model from OpenAI, built on the GPT-4o-mini architecture. It converts spoken language into text with exceptional speed and surprising accuracy for its size—making it ideal for real-time transcription in resource-constrained environments. Whether you're building voice-enabled apps, smart assistants, meeting transcription tools, or captioning systems, GPT-4o-mini-transcribe offers responsive, multilingual transcription that balances cost, performance, and ease of integration.
GPT-4o-mini-transcribe is a lightweight, high-speed speech-to-text model from OpenAI, built on the GPT-4o-mini architecture. It converts spoken language into text with exceptional speed and surprising accuracy for its size—making it ideal for real-time transcription in resource-constrained environments. Whether you're building voice-enabled apps, smart assistants, meeting transcription tools, or captioning systems, GPT-4o-mini-transcribe offers responsive, multilingual transcription that balances cost, performance, and ease of integration.
GPT-4o-mini-transcribe is a lightweight, high-speed speech-to-text model from OpenAI, built on the GPT-4o-mini architecture. It converts spoken language into text with exceptional speed and surprising accuracy for its size—making it ideal for real-time transcription in resource-constrained environments. Whether you're building voice-enabled apps, smart assistants, meeting transcription tools, or captioning systems, GPT-4o-mini-transcribe offers responsive, multilingual transcription that balances cost, performance, and ease of integration.

GPT-4o-mini Search Preview is OpenAI’s lightweight semantic search feature powered by the GPT-4o-mini model. Designed for real-time applications and low-latency environments, it brings retrieval-augmented intelligence to any product or tool that needs blazing-fast, accurate information lookup. While compact in size, it offers the power of contextual understanding, enabling smarter, more relevant search results with fewer resources. It’s ideal for startups, embedded systems, or anyone who needs search that just works—fast, efficient, and tuned for integration.
GPT-4o-mini Search Preview is OpenAI’s lightweight semantic search feature powered by the GPT-4o-mini model. Designed for real-time applications and low-latency environments, it brings retrieval-augmented intelligence to any product or tool that needs blazing-fast, accurate information lookup. While compact in size, it offers the power of contextual understanding, enabling smarter, more relevant search results with fewer resources. It’s ideal for startups, embedded systems, or anyone who needs search that just works—fast, efficient, and tuned for integration.
GPT-4o-mini Search Preview is OpenAI’s lightweight semantic search feature powered by the GPT-4o-mini model. Designed for real-time applications and low-latency environments, it brings retrieval-augmented intelligence to any product or tool that needs blazing-fast, accurate information lookup. While compact in size, it offers the power of contextual understanding, enabling smarter, more relevant search results with fewer resources. It’s ideal for startups, embedded systems, or anyone who needs search that just works—fast, efficient, and tuned for integration.

codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.
codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.
codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.

grok-3-mini-latest
Grok 3 Mini is xAI’s compact, reasoning-focused variant of the Grok 3 series. Released in February 2025 alongside the flagship model, it's optimized for cost-effective, transparent chain-of-thought reasoning via "Think" mode, with full multimodal input and access to xAI’s Colossus-trained capabilities. The latest version supports live preview on Azure AI Foundry and GitHub Models—combining speed, affordability, and logic traversal in real-time workflows.
grok-3-mini-latest
Grok 3 Mini is xAI’s compact, reasoning-focused variant of the Grok 3 series. Released in February 2025 alongside the flagship model, it's optimized for cost-effective, transparent chain-of-thought reasoning via "Think" mode, with full multimodal input and access to xAI’s Colossus-trained capabilities. The latest version supports live preview on Azure AI Foundry and GitHub Models—combining speed, affordability, and logic traversal in real-time workflows.
grok-3-mini-latest
Grok 3 Mini is xAI’s compact, reasoning-focused variant of the Grok 3 series. Released in February 2025 alongside the flagship model, it's optimized for cost-effective, transparent chain-of-thought reasoning via "Think" mode, with full multimodal input and access to xAI’s Colossus-trained capabilities. The latest version supports live preview on Azure AI Foundry and GitHub Models—combining speed, affordability, and logic traversal in real-time workflows.

grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.
grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.
grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.

Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
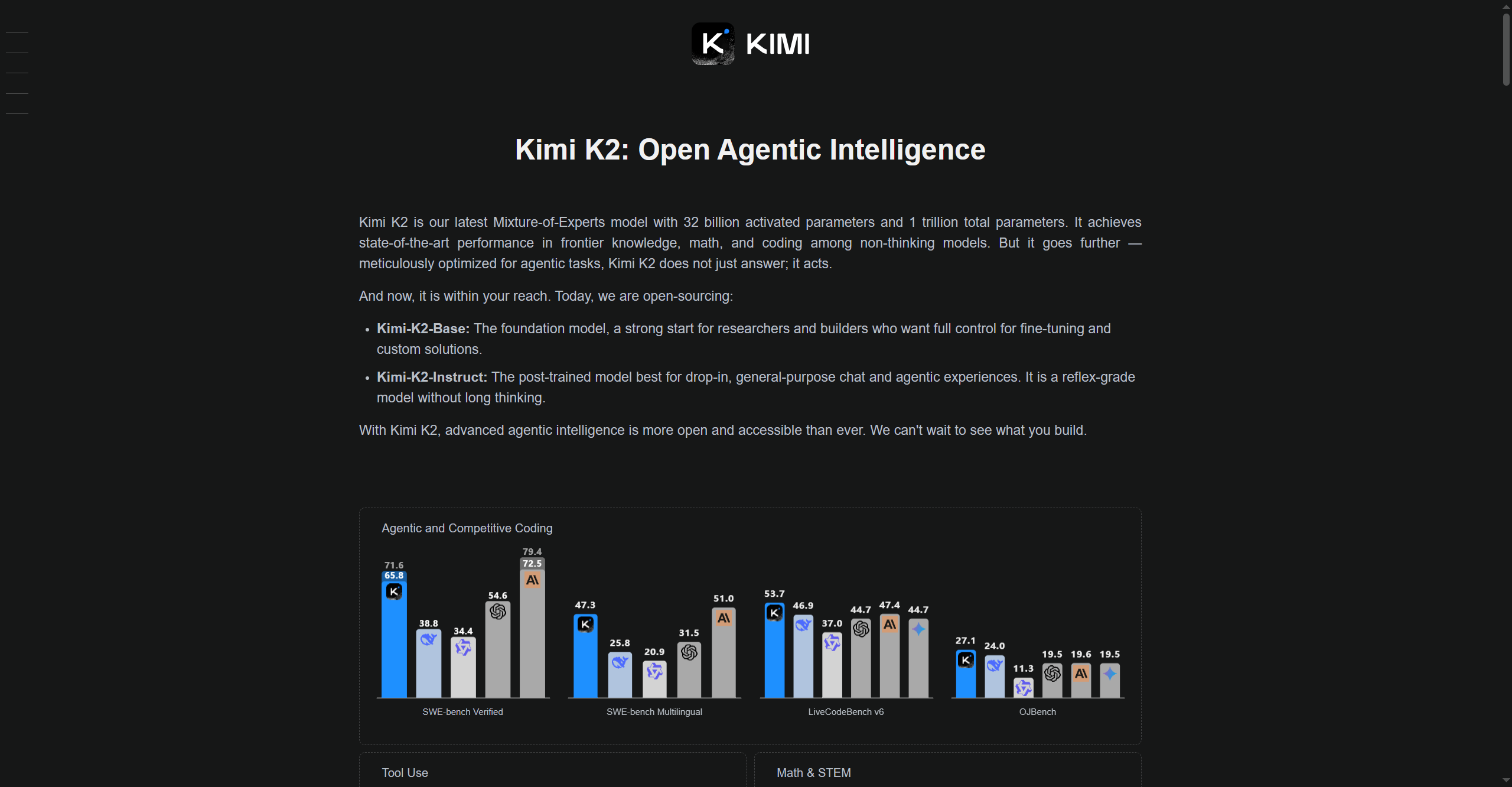

Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Upstage Information Extract is a powerful, schema-agnostic document data extraction solution that requires zero training or setup. It intelligently extracts structured insights from any document type—PDFs, scanned images, Office files, multi-page documents, and more—understanding both explicit content and implicit contextual meaning such as totals from line items. Designed for enterprise-scale workflows, it offers high accuracy, dynamic schema alignment, and seamless API-first integration with ERP, CRM, cloud storage, and automation platforms, enabling reliable and customizable data extraction without the complexity typical of traditional IDP or generic LLM approaches.
Upstage Information Extract is a powerful, schema-agnostic document data extraction solution that requires zero training or setup. It intelligently extracts structured insights from any document type—PDFs, scanned images, Office files, multi-page documents, and more—understanding both explicit content and implicit contextual meaning such as totals from line items. Designed for enterprise-scale workflows, it offers high accuracy, dynamic schema alignment, and seamless API-first integration with ERP, CRM, cloud storage, and automation platforms, enabling reliable and customizable data extraction without the complexity typical of traditional IDP or generic LLM approaches.
Upstage Information Extract is a powerful, schema-agnostic document data extraction solution that requires zero training or setup. It intelligently extracts structured insights from any document type—PDFs, scanned images, Office files, multi-page documents, and more—understanding both explicit content and implicit contextual meaning such as totals from line items. Designed for enterprise-scale workflows, it offers high accuracy, dynamic schema alignment, and seamless API-first integration with ERP, CRM, cloud storage, and automation platforms, enabling reliable and customizable data extraction without the complexity typical of traditional IDP or generic LLM approaches.

Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.

Typing Mind
TypingMind is a powerful frontend for large language models, giving users a clean, customizable interface to interact with AI more efficiently. It enhances the user experience by offering advanced features such as conversation organization, prompt management, model switching, and private local usage options. TypingMind provides a more flexible and user-friendly environment than standard AI chat interfaces, allowing users to optimize workflows, manage sessions, and personalize interactions. It is built for individuals and teams who want full control over how they use LLMs without relying on default chat UIs.
Typing Mind
TypingMind is a powerful frontend for large language models, giving users a clean, customizable interface to interact with AI more efficiently. It enhances the user experience by offering advanced features such as conversation organization, prompt management, model switching, and private local usage options. TypingMind provides a more flexible and user-friendly environment than standard AI chat interfaces, allowing users to optimize workflows, manage sessions, and personalize interactions. It is built for individuals and teams who want full control over how they use LLMs without relying on default chat UIs.
Typing Mind
TypingMind is a powerful frontend for large language models, giving users a clean, customizable interface to interact with AI more efficiently. It enhances the user experience by offering advanced features such as conversation organization, prompt management, model switching, and private local usage options. TypingMind provides a more flexible and user-friendly environment than standard AI chat interfaces, allowing users to optimize workflows, manage sessions, and personalize interactions. It is built for individuals and teams who want full control over how they use LLMs without relying on default chat UIs.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai