
- Developers & Engineers: Build chatbots, code tools, analytics apps, and RAG systems with function-calling.
- Data Scientists & Analysts: Process long documents, codebases, and multilingual data within a single context window.
- Educators & Students: Solve advanced math tasks (GSM8K, Math benchmarks) and generate code.
- Enterprises & API Users: Deploy via Mistral’s La Plateforme, Azure, AWS Bedrock, IBM Watsonx, or self-host using open weights.
- Open-Source Advocates: Use free weights for research/non-commercial; commercial use via license.
How to Use Mistral Large 2?
- Model Access: Call `mistral-large-2407` via La Plateforme API, or through cloud endpoints (Azure, AWS Bedrock, IBM Watsonx).
- Deploy Locally: Download weights and run with Mistral Inference or Hugging Face Transformers.
- Send Large Context Prompts: Support up to 128K tokens for text, code, or documents.
- Invoke Function Calling & JSON Mode: Native structured outputs and tool integration.
- Integrate in Apps: Use for coding, QA, math, and multilingual use cases with high accuracy and efficiency.
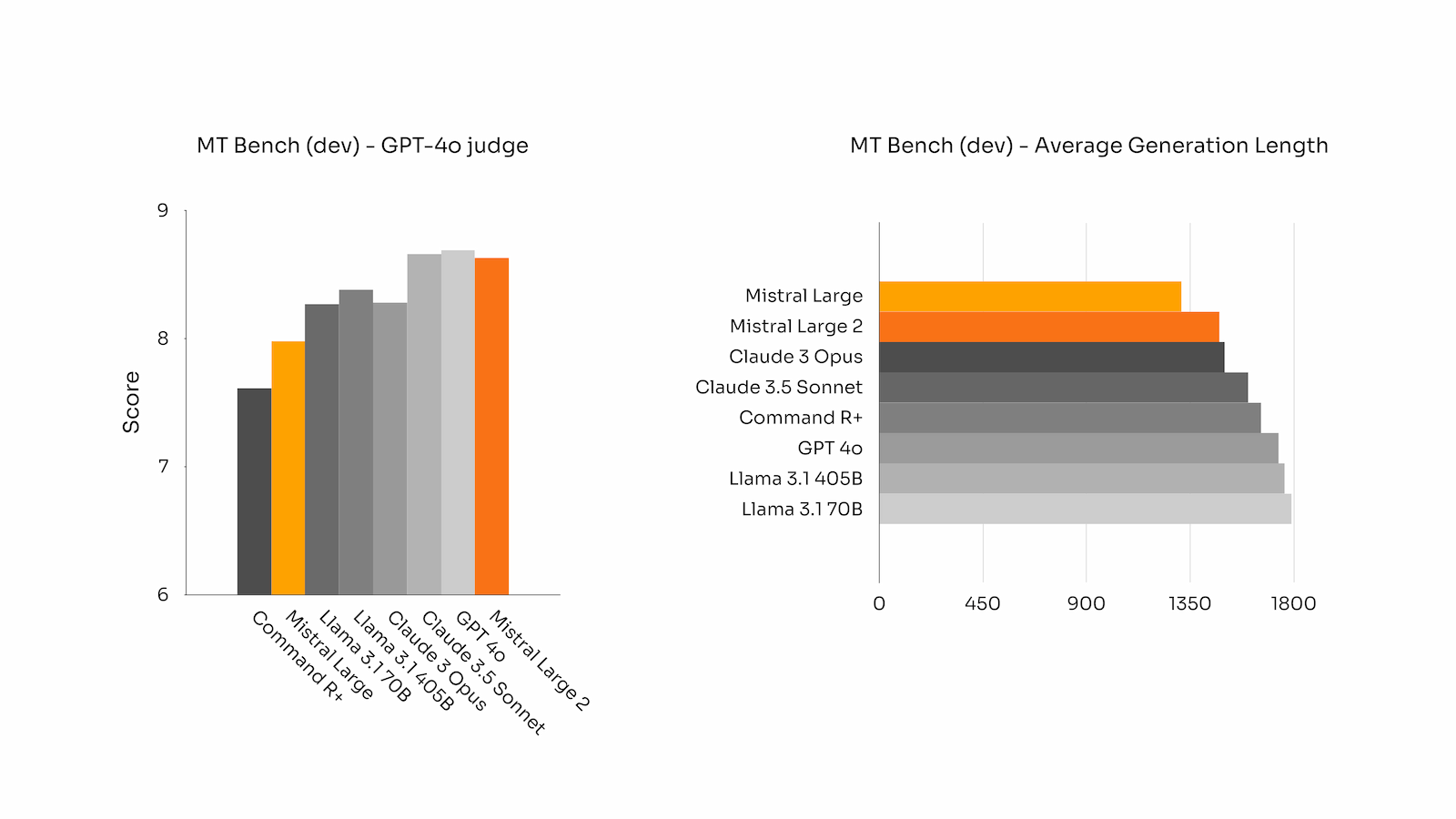
- High Parameter Efficiency: With 123B dense parameters, Mistral Large 2 achieves GPT-4o and Claude 3-level performance with fewer resources.
- 128K Context Window: Handles massive documents, codebases, or multimodal inputs in a single pass.
- Powerhouse Code & Reasoning: Exceptional in OpenAI-grade code tasks, math benchmarks, and reasoning, rivaling closed models.
- Multilingual & Function Calling: Fluent across many languages and supports advanced agentic capabilities.
- High performance with fewer parameters
- Extremely long context supports complex workflows
- Excellent code/math/reasoning benchmarks
- Native support for function calling and structured output
- Deployable across major cloud platforms & open weights
- Deprecated as of May 2025 in GitHub Models – users should switch to version 24.11
- Dense architecture uses more compute than Mixture-of-Experts alternatives
- Commercial usage requires licensing (research use is free)

Chat
0/$14.99/$24.99 per month
Free - $0
Pro - $14.99 per month
Enterprise - $24.99 per month
API
$2/$6 per 1M tokens
Stirage Cost - $4 per month per model
Input - $2 per 1M tokens
Output - $6 per 1M tokens
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.
Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.
Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.

Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.

Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.

grok-2-vision-1212
Grok 2 Vision – 1212 is a December 2024 release of xAI’s multimodal large language model, fine-tuned specifically for image understanding and generation. It supports combined text and image inputs (up to 32,768 tokens) and excels in document question answering, visual math reasoning, object recognition, and photorealistic image generation powered by FLUX.1. It also supports API deployment for developers and enterprises.
grok-2-vision-1212
Grok 2 Vision – 1212 is a December 2024 release of xAI’s multimodal large language model, fine-tuned specifically for image understanding and generation. It supports combined text and image inputs (up to 32,768 tokens) and excels in document question answering, visual math reasoning, object recognition, and photorealistic image generation powered by FLUX.1. It also supports API deployment for developers and enterprises.
grok-2-vision-1212
Grok 2 Vision – 1212 is a December 2024 release of xAI’s multimodal large language model, fine-tuned specifically for image understanding and generation. It supports combined text and image inputs (up to 32,768 tokens) and excels in document question answering, visual math reasoning, object recognition, and photorealistic image generation powered by FLUX.1. It also supports API deployment for developers and enterprises.

Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.

Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.

DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.

DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai