
- Enterprise & Research Teams: For deep document analysis, R&D workflows, and high-context reasoning.
- Developers & Engineers: Generate, debug, and optimize extensive codebases or system designs.
- Data Analysts & Scientists: Analyze large datasets, financial reports, charts, using multimodal inputs.
- Legal & Finance Professionals: Summarize and interpret contracts or complex filings with high accuracy.
- Educators & Advanced Learners: Perform graduate-level problem solving in math, logic, and technical domains.
How to Use Claude 3 Opus?
- Access via API & Cloud: Available through Anthropic API, AWS Bedrock, and Google Vertex AI under model IDs like `claude-3-opus-20240229`.
- Submit Text & Images: Send prompts including text, charts, or documents—up to 200K tokens.
- Configure for Depth: Use chain-of-thought prompts to unlock deep reasoning.
- Process Vision Inputs: Include charts, graphs, or screenshots for integrated analysis.
- Manage Cost: Priced at $15 per million input tokens and $75 per million output tokens.
- Benchmark-Leading Reasoning: Scores
86–88% on MMLU,84.9% on HumanEval, 95.4% on HellaSwag—beating GPT-4 and Gemini. - Huge Context + Enterprise Scalability: 200K-token window (scalable to 1M) supports massive documents.
- Multimodal Comprehension: Expert at analyzing images, graphics, and charts alongside text.
- Flagship Cognitive Power: Excels at deep math, coding, logic, and creative reasoning tasks.
- Cloud-Ready Integration: Deployable via major cloud platforms with enterprise support.
- Top-tier reasoning, math, coding, and benchmarks
- Massive 200K-token window with image support
- Deep analysis suited to enterprise and research
- Available across major cloud platforms
- Outperforms other LLMs on nuanced tasks
- Slowest and most expensive option in Claude 3 lineup
- High input/output token cost may limit frequent usage
- Lacks transparent visual chain-of-thought (“Think” mode) found in later hybrid Claude 4 models
- Requires large context awareness—may be overkill for simple tasks
Pro Plan
$20/month
Connect Google Workspace: email, calendar, and docs
Connect any context or tool through Integrations with remote MCP
Extended thinking for complex work
Ability to use more Claude models
Max
$100/month
- Choose 5x or 20x more usage than Pro
- Higher output limits for all tasks
- Early access to advanced Claude features
- Priority access at high traffic times
API Usage
$15/$75 per 1M tokens
- $15 input & $75 output per 1M tokens
- Prompt caching write - $18.75 / MTok
- Prompt caching read- $1.50 / MTok
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
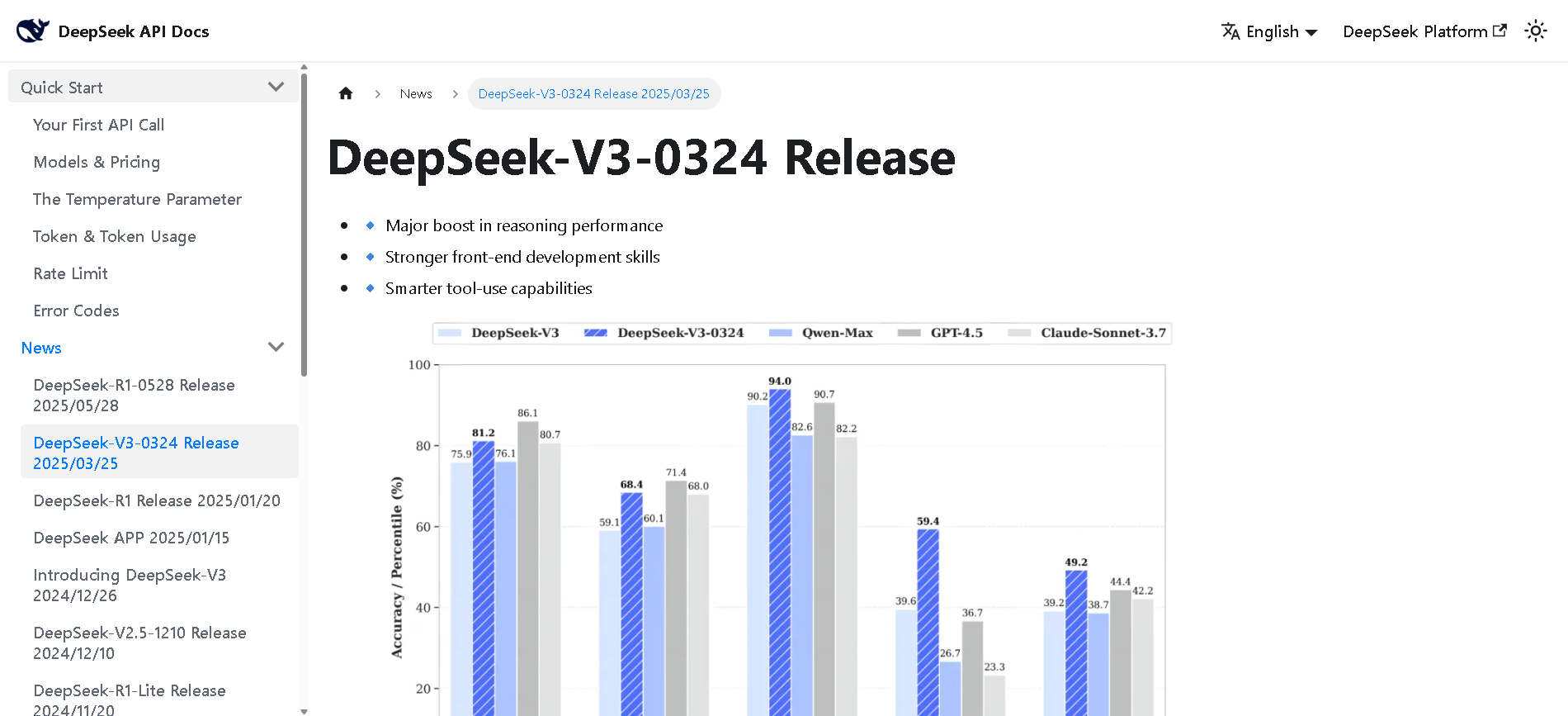
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.

DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.

grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.
grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.
grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.

grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.

grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.

Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.

Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.

ChatHub
ChatHub is a platform that allows users to simultaneously interact with multiple AI chatbots, providing diverse AI-generated responses for enhanced insights and confidence. It supports top AI models like GPT-5, Claude 4, Gemini 2.5, Llama 3.3, and over 20 others, all accessible under one subscription. Users can input one question and receive multiple perspectives from these models, helping to cross-verify information and minimize hallucinations. ChatHub also includes AI-powered image generation using models such as DALL-E 3 and Stable Diffusion, file upload and analysis for documents and images, and features like AI-powered web search, code preview, prompt libraries, and productivity tools.
ChatHub
ChatHub is a platform that allows users to simultaneously interact with multiple AI chatbots, providing diverse AI-generated responses for enhanced insights and confidence. It supports top AI models like GPT-5, Claude 4, Gemini 2.5, Llama 3.3, and over 20 others, all accessible under one subscription. Users can input one question and receive multiple perspectives from these models, helping to cross-verify information and minimize hallucinations. ChatHub also includes AI-powered image generation using models such as DALL-E 3 and Stable Diffusion, file upload and analysis for documents and images, and features like AI-powered web search, code preview, prompt libraries, and productivity tools.
ChatHub
ChatHub is a platform that allows users to simultaneously interact with multiple AI chatbots, providing diverse AI-generated responses for enhanced insights and confidence. It supports top AI models like GPT-5, Claude 4, Gemini 2.5, Llama 3.3, and over 20 others, all accessible under one subscription. Users can input one question and receive multiple perspectives from these models, helping to cross-verify information and minimize hallucinations. ChatHub also includes AI-powered image generation using models such as DALL-E 3 and Stable Diffusion, file upload and analysis for documents and images, and features like AI-powered web search, code preview, prompt libraries, and productivity tools.


GlobalGPT
GlobalGPT is an all-in-one AI platform that unifies leading models for writing, coding, research, image generation, and video creation—accessible through a single account and subscription. It brings together top models like GPT-5, GPT-4.1, GPT-4o, GPT-o3, Claude Opus 4.1, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek V3, Unikorn (MJ-like) V7, Flux, Ideogram, and Google Veo 3 so you can chat, draft content, analyze documents, generate images, and produce cinematic videos without switching tools. Designed for over 2 million users worldwide, GlobalGPT also includes advanced research agents powered by GPT-4o and perplexity for deep web analysis, PDF summarization, and market insights, all wrapped in a clean interface with flexible credit-based plans.
GlobalGPT
GlobalGPT is an all-in-one AI platform that unifies leading models for writing, coding, research, image generation, and video creation—accessible through a single account and subscription. It brings together top models like GPT-5, GPT-4.1, GPT-4o, GPT-o3, Claude Opus 4.1, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek V3, Unikorn (MJ-like) V7, Flux, Ideogram, and Google Veo 3 so you can chat, draft content, analyze documents, generate images, and produce cinematic videos without switching tools. Designed for over 2 million users worldwide, GlobalGPT also includes advanced research agents powered by GPT-4o and perplexity for deep web analysis, PDF summarization, and market insights, all wrapped in a clean interface with flexible credit-based plans.
GlobalGPT
GlobalGPT is an all-in-one AI platform that unifies leading models for writing, coding, research, image generation, and video creation—accessible through a single account and subscription. It brings together top models like GPT-5, GPT-4.1, GPT-4o, GPT-o3, Claude Opus 4.1, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek V3, Unikorn (MJ-like) V7, Flux, Ideogram, and Google Veo 3 so you can chat, draft content, analyze documents, generate images, and produce cinematic videos without switching tools. Designed for over 2 million users worldwide, GlobalGPT also includes advanced research agents powered by GPT-4o and perplexity for deep web analysis, PDF summarization, and market insights, all wrapped in a clean interface with flexible credit-based plans.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai