- Developers & Engineers: Build advanced reasoning assistants, code generators, and tool-enabled pipelines.
- Data Scientists & Analysts: Use it for structured problem-solving, data QA, and interactive tool workflows.
- Multilingual Teams: Produce high-quality content in Chinese with improved writing quality.
- Full-Stack Engineers: Generate and refine front-end code with better executability and aesthetics.
- Open-Source Community: Self-host, customize, or perform inference locally using Hugging Face or OpenRouter.
How to Use DeepSeek V3 (0324)?
- Get the Model: Access via Hugging Face under `deepseek-ai/DeepSeek-V3-0324`, licensed MIT.
- Deploy Locally or via API: Use the same architecture as V3; supports function calling, JSON output, and FIM completion.
- Configure Prompts: Include system prefixes or temperature tuning; V3-0324 excels at multi-step reasoning.
- Use in Front-End & Chinese Workflows: Enhanced capabilities in web code generation, Chinese writing, translation, and search.
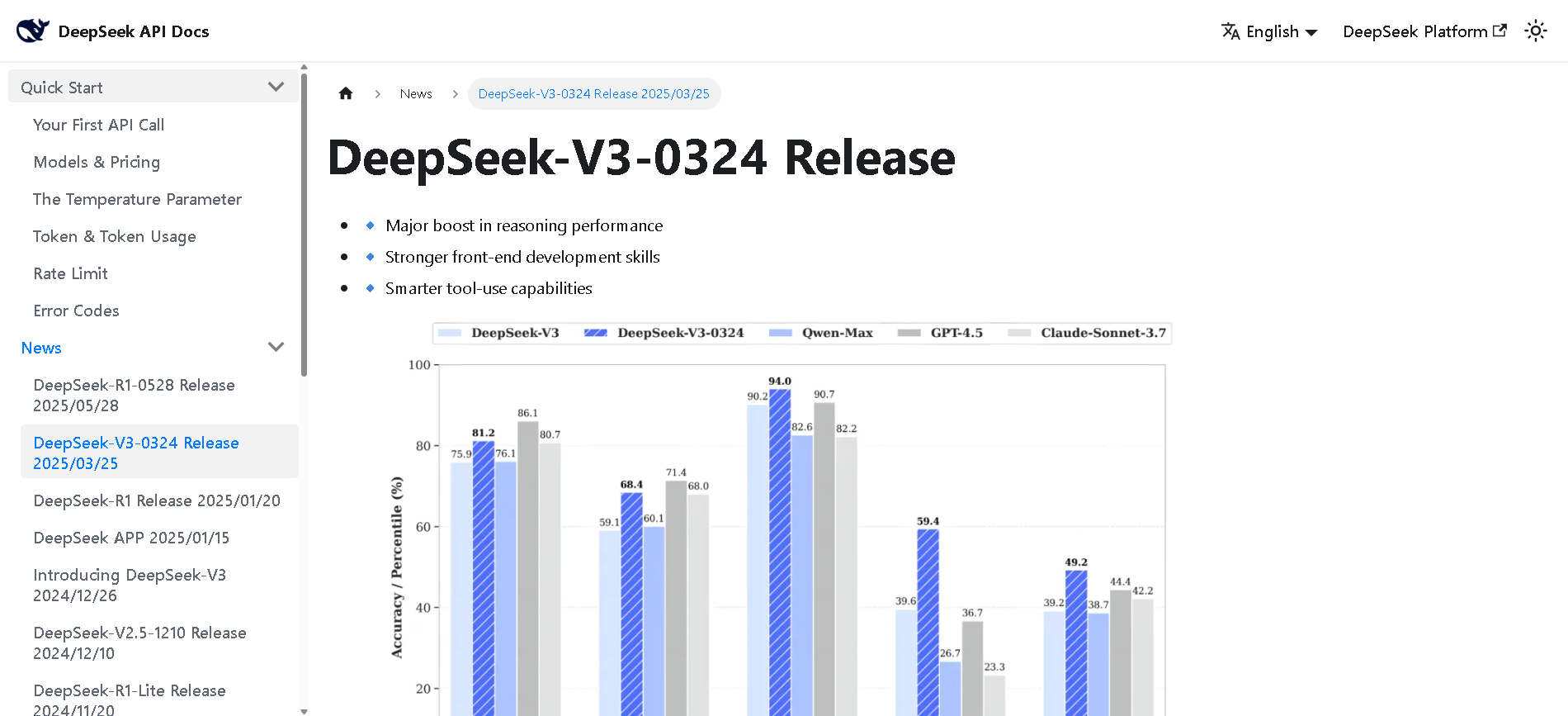
- Improved Reasoning & Benchmarks: MMLU-Pro jumped from 75.9 → 81.2, GPQA 59.1 → 68.4, AIME 39.6 → 59.4—major gains in logical and coding tasks.
- Front-End Code Quality: Generates more functional and aesthetically improved HTML/CSS/JS components.
- Stronger Chinese Performance: Writes longer-form Chinese text with better style and clarity.
- Smart Function Calling: Enhanced function-calling accuracy and API integration compared to earlier versions.
- Open-Source & Free: Fully MIT-licensed, available on Hugging Face, OpenRouter, and GitHub Models.
- Strong gains in reasoning and code benchmarks
- Better Chinese writing and search capabilities
- Improved front-end code generation quality
- Open-source MIT license with broad accessibility
- Works with function calls and JSON output formats
- ~32% more verbose—could increase token costs
- Heavier inference—higher latency and cost for deeper reasoning
- Imminent deprecation of original V3—may require migration to 0324
API
$0.14/$0.28 per 1M tokens
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
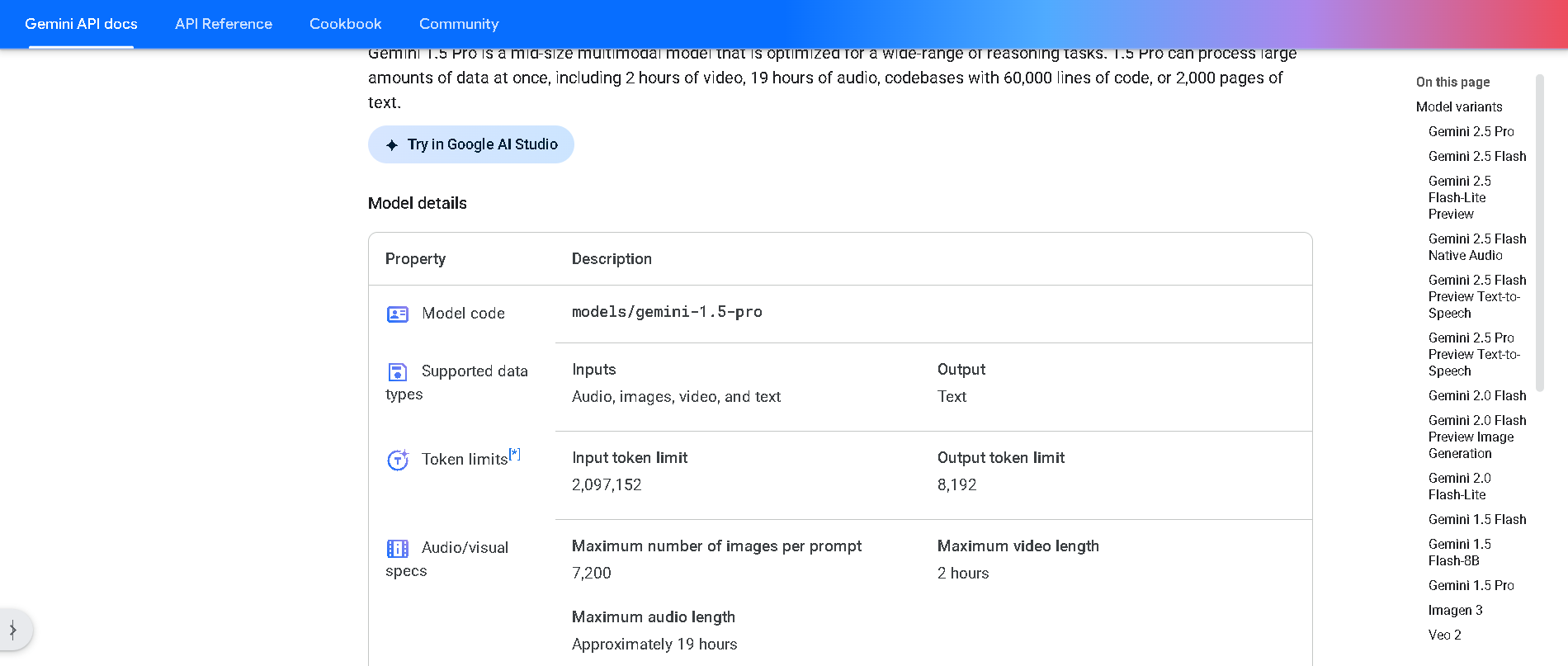

Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.

Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.

Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.

Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.
Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.
Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.
grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.
grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.

grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.

grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.
grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.
grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.

DeepSeek-R1-Zero
DeepSeek R1 Zero is an open-source large language model introduced in January 2025 by DeepSeek AI. It is a reinforcement learning–only version of DeepSeek R1, trained without supervised fine-tuning. With 671B total parameters (37B active) and a 128K-token context window, it demonstrates strong chain-of-thought reasoning, self-verification, and reflection.
DeepSeek-R1-Zero
DeepSeek R1 Zero is an open-source large language model introduced in January 2025 by DeepSeek AI. It is a reinforcement learning–only version of DeepSeek R1, trained without supervised fine-tuning. With 671B total parameters (37B active) and a 128K-token context window, it demonstrates strong chain-of-thought reasoning, self-verification, and reflection.
DeepSeek-R1-Zero
DeepSeek R1 Zero is an open-source large language model introduced in January 2025 by DeepSeek AI. It is a reinforcement learning–only version of DeepSeek R1, trained without supervised fine-tuning. With 671B total parameters (37B active) and a 128K-token context window, it demonstrates strong chain-of-thought reasoning, self-verification, and reflection.

DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
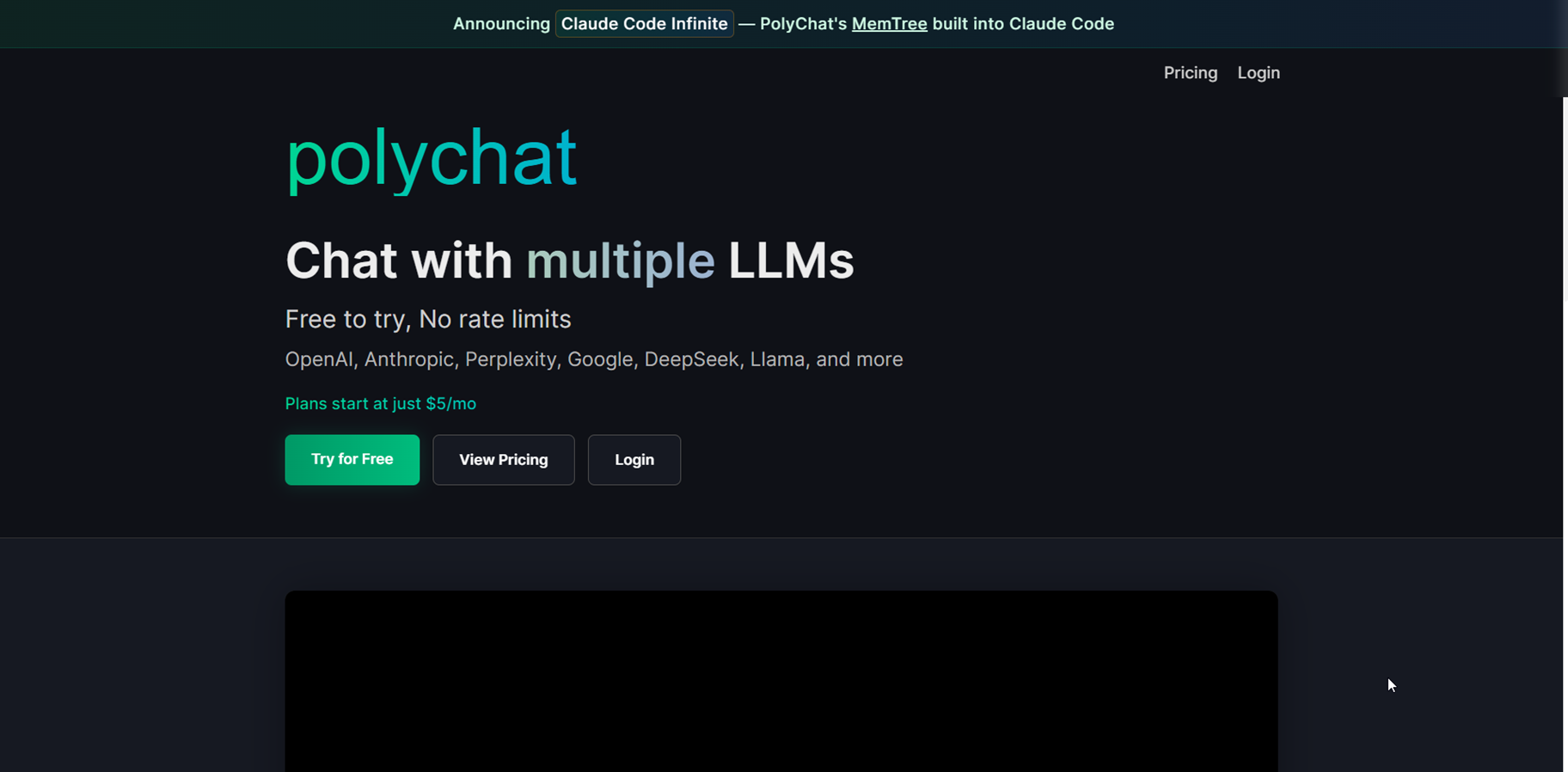

polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai