
- Enthusiasts & Experimenters: Use the free web preview (“Deep Think” mode) to explore reasoning chains step by step.
- Math & Logic Users: Tackle difficult high-school to competition-level problems with visible, multi-step solutions.
- Coding Enthusiasts: Generate and debug code with full reasoning paths shown.
- Researchers: Study RL-induced reasoning behaviors in open-source models before the full R1 release.
- Benchmarkers: Compare reasoning performance transparently against o1-preview and other top LLMs.
How to Use DeepSeek R1 Lite Preview?
- Enable Deep Think: Use the “Deep Think” mode on the web interface to access extended reasoning emissions.
- Submit Complex Prompts: Focus on math, code, or logic problems to leverage transparent chain-of-thought capabilities.
- Multiple Iterations: The model refines outputs through iterative self-verification, boosting accuracy with longer reasoning.
- Web-Only Preview Mode: Currently limited to web use; API access to full models planned for later.
- Transparent Reasoning: Displays full internal chain-of-thought during inference—unlike hidden reasoning in o1-preview.
- Test-Time Compute Scaling: Longer thought chains directly improve performance on math benchmarks.
- High Benchmark Scores: Exceeds o1-preview on AIME, MATH, and Codeforces tasks.
- Prelude to R1 Family: A stepping-stone before full DeepSeek-R1 and API support; open-sourced under MIT.
- Visible step-by-step reasoning enhances transparency
- Strong performance on complex math and coding
- Open-source mindset with MIT licensing
- Multi-turn evaluation boosts answer confidence
- Represents breakthrough in RL-only reasoning models
- Web-only preview with no API or heavy usage access
- Built on smaller base model—limits reasoning depth compared to full R1
- Output can be verbose or include redundant self-checking steps
Custom
Custom
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.

GPT-4o Mini Realtime Preview is a lightweight, high-speed variant of OpenAI’s flagship multimodal model, GPT-4o. Built for blazing-fast, cost-efficient inference across text, vision, and voice inputs, this preview version is optimized for real-time responsiveness—without compromising on core intelligence. Whether you’re building chatbots, interactive voice tools, or lightweight apps, GPT-4o Mini delivers smart performance with minimal latency and compute load. It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.
GPT-4o Mini Realtime Preview is a lightweight, high-speed variant of OpenAI’s flagship multimodal model, GPT-4o. Built for blazing-fast, cost-efficient inference across text, vision, and voice inputs, this preview version is optimized for real-time responsiveness—without compromising on core intelligence. Whether you’re building chatbots, interactive voice tools, or lightweight apps, GPT-4o Mini delivers smart performance with minimal latency and compute load. It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.
GPT-4o Mini Realtime Preview is a lightweight, high-speed variant of OpenAI’s flagship multimodal model, GPT-4o. Built for blazing-fast, cost-efficient inference across text, vision, and voice inputs, this preview version is optimized for real-time responsiveness—without compromising on core intelligence. Whether you’re building chatbots, interactive voice tools, or lightweight apps, GPT-4o Mini delivers smart performance with minimal latency and compute load. It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.
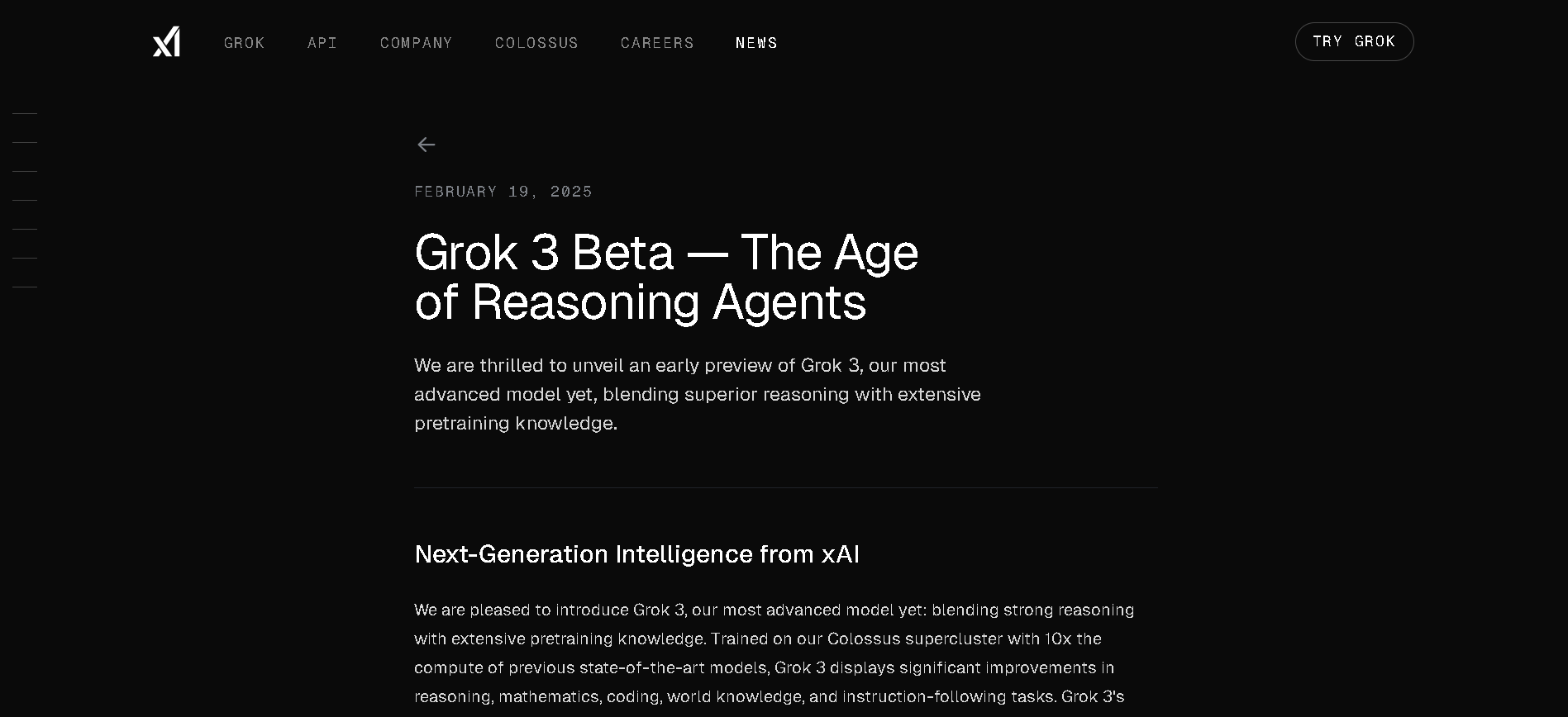

Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
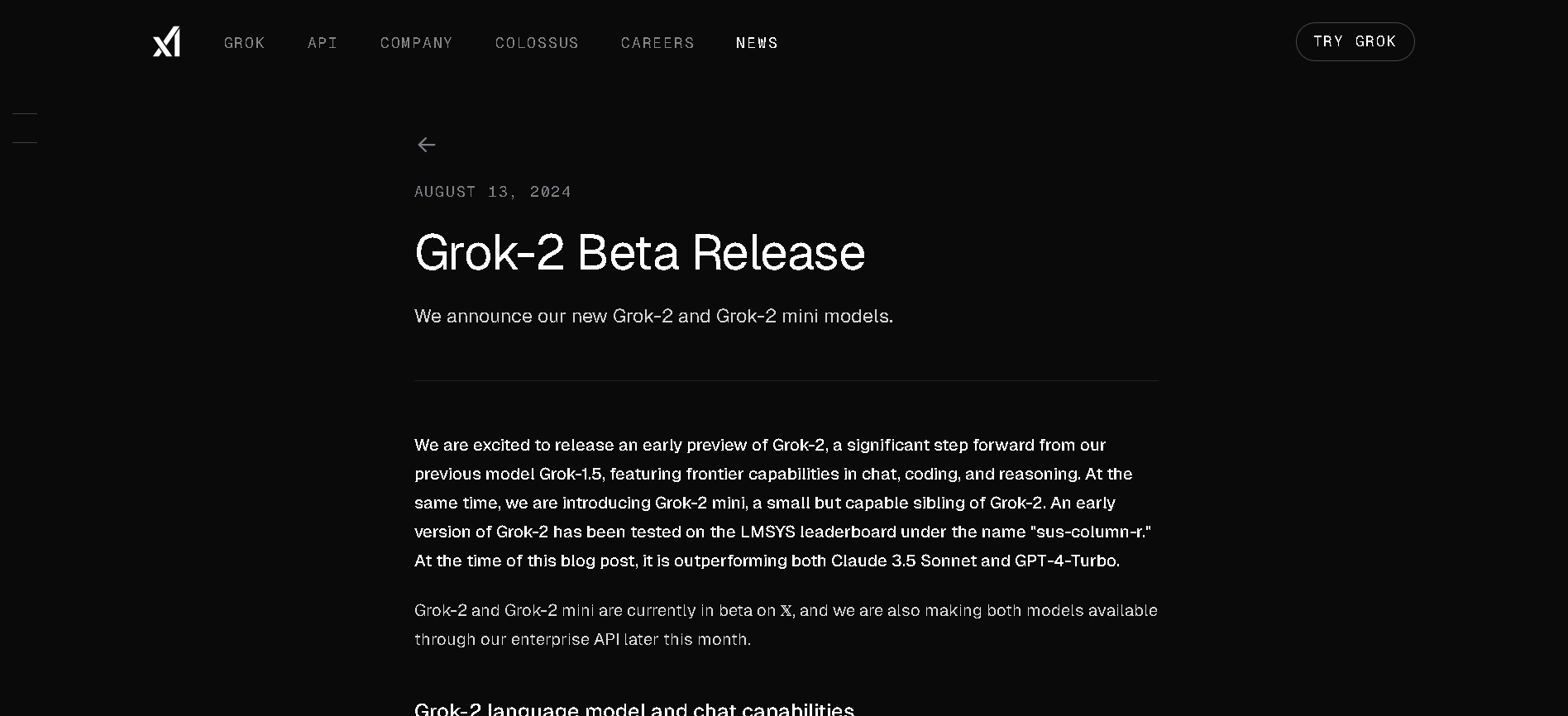

Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.
Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.
Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.
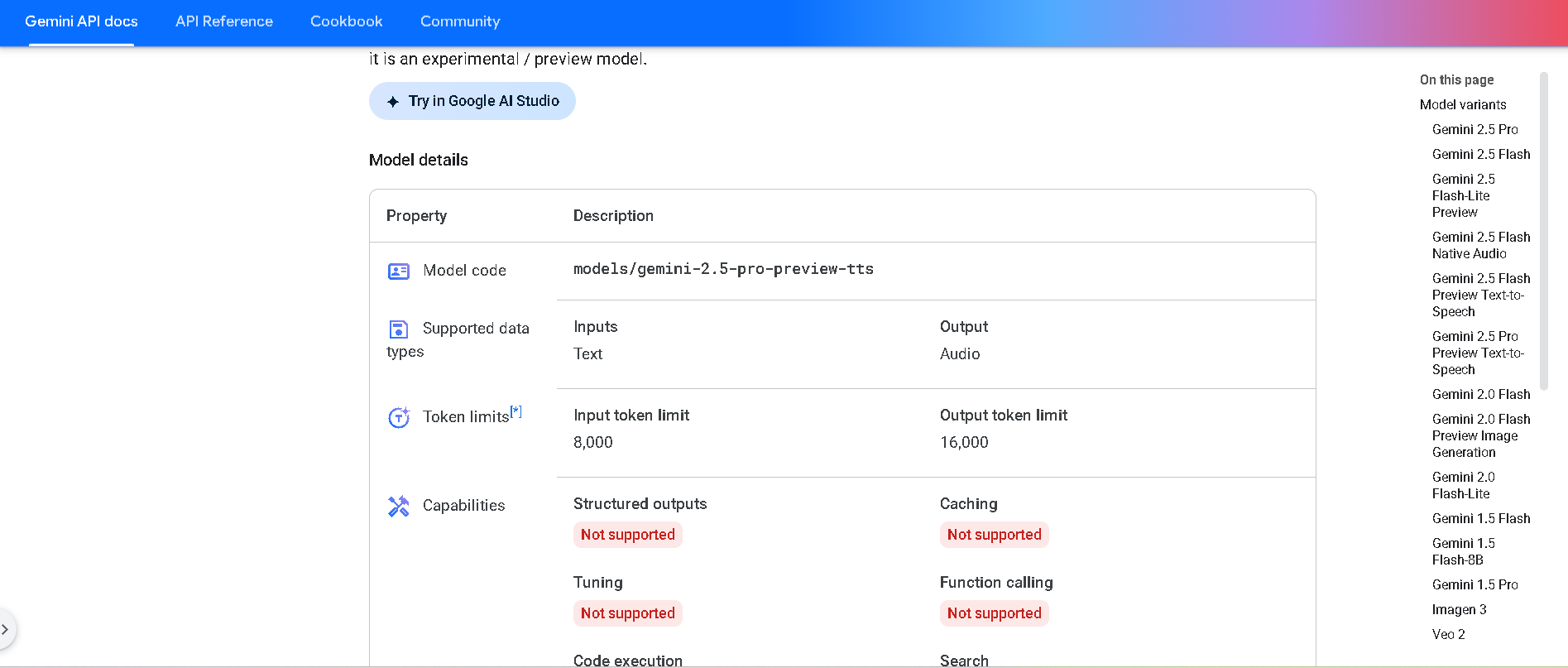
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
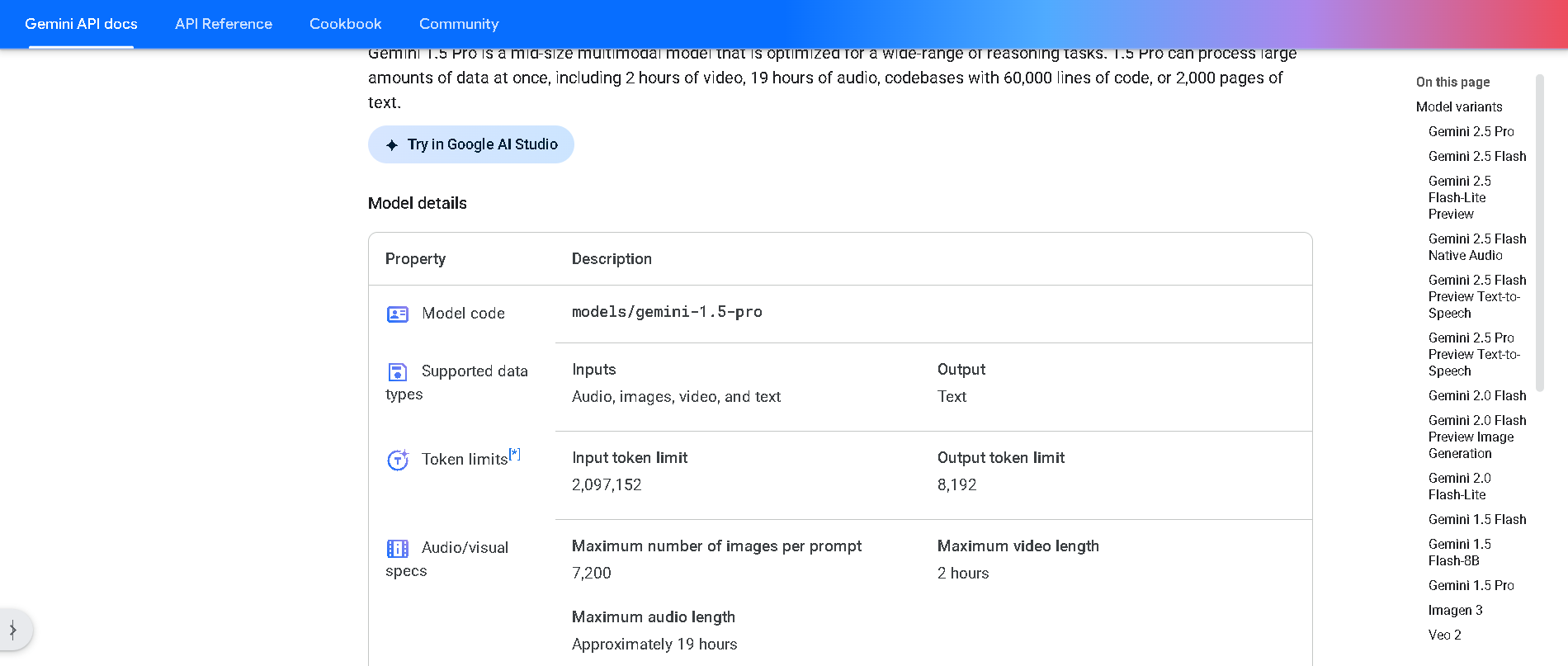

Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.

Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.
Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.
Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
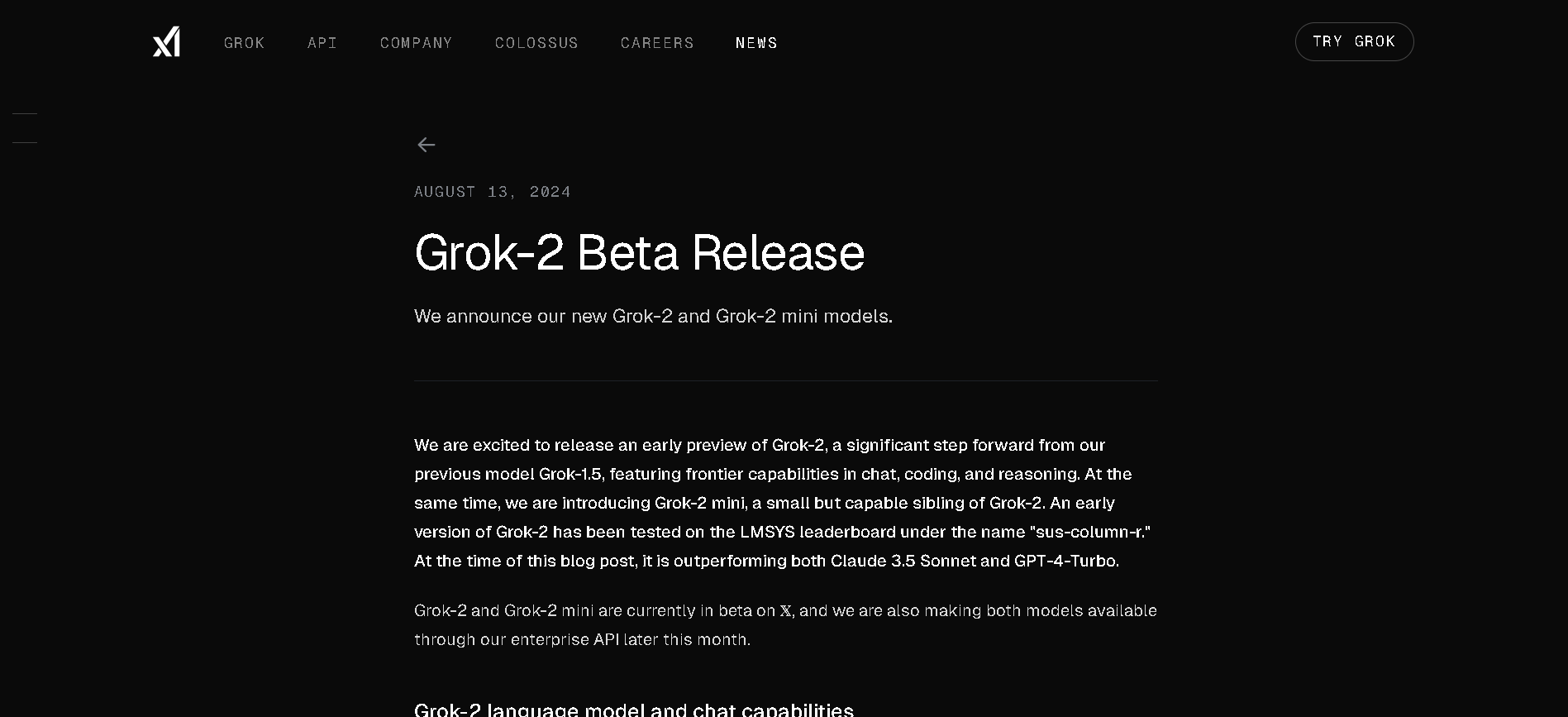

grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
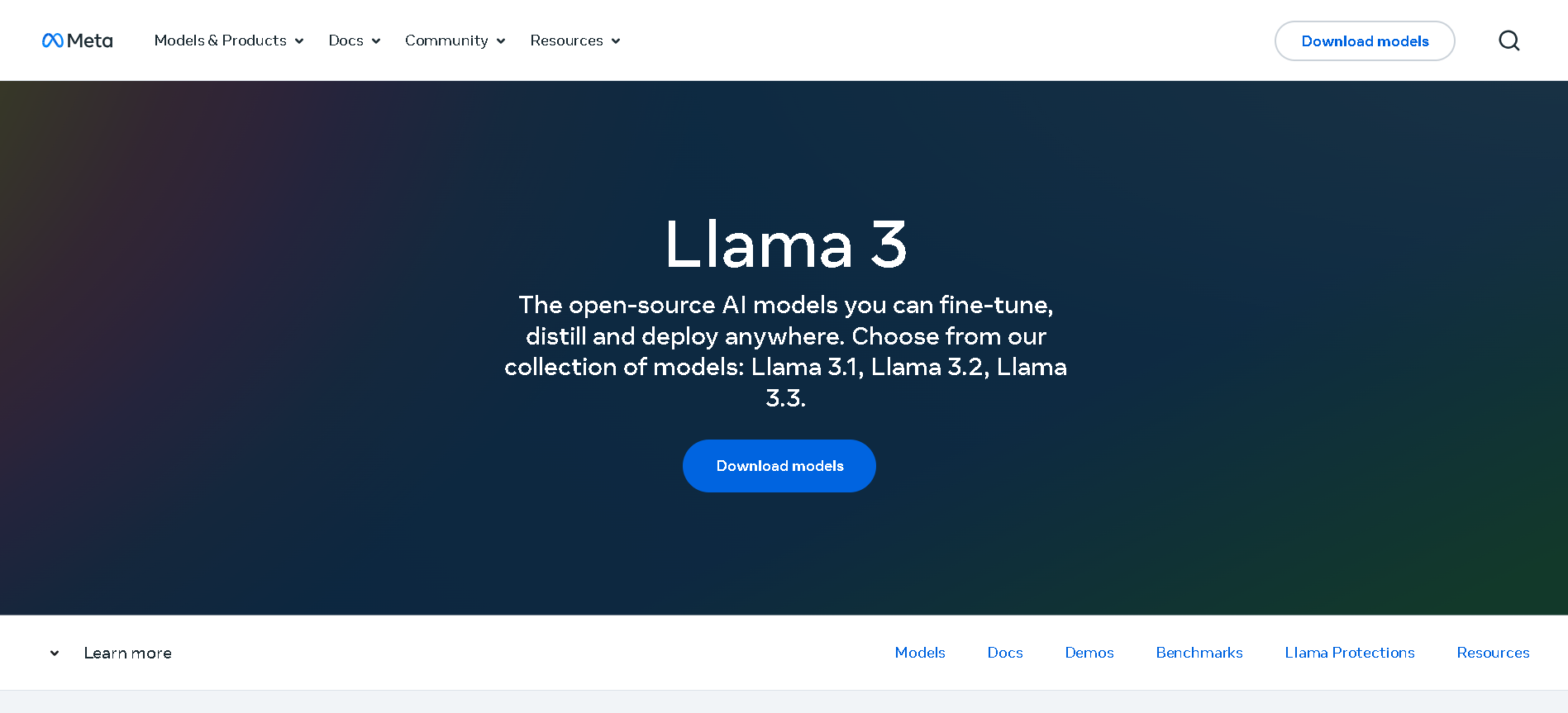

Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
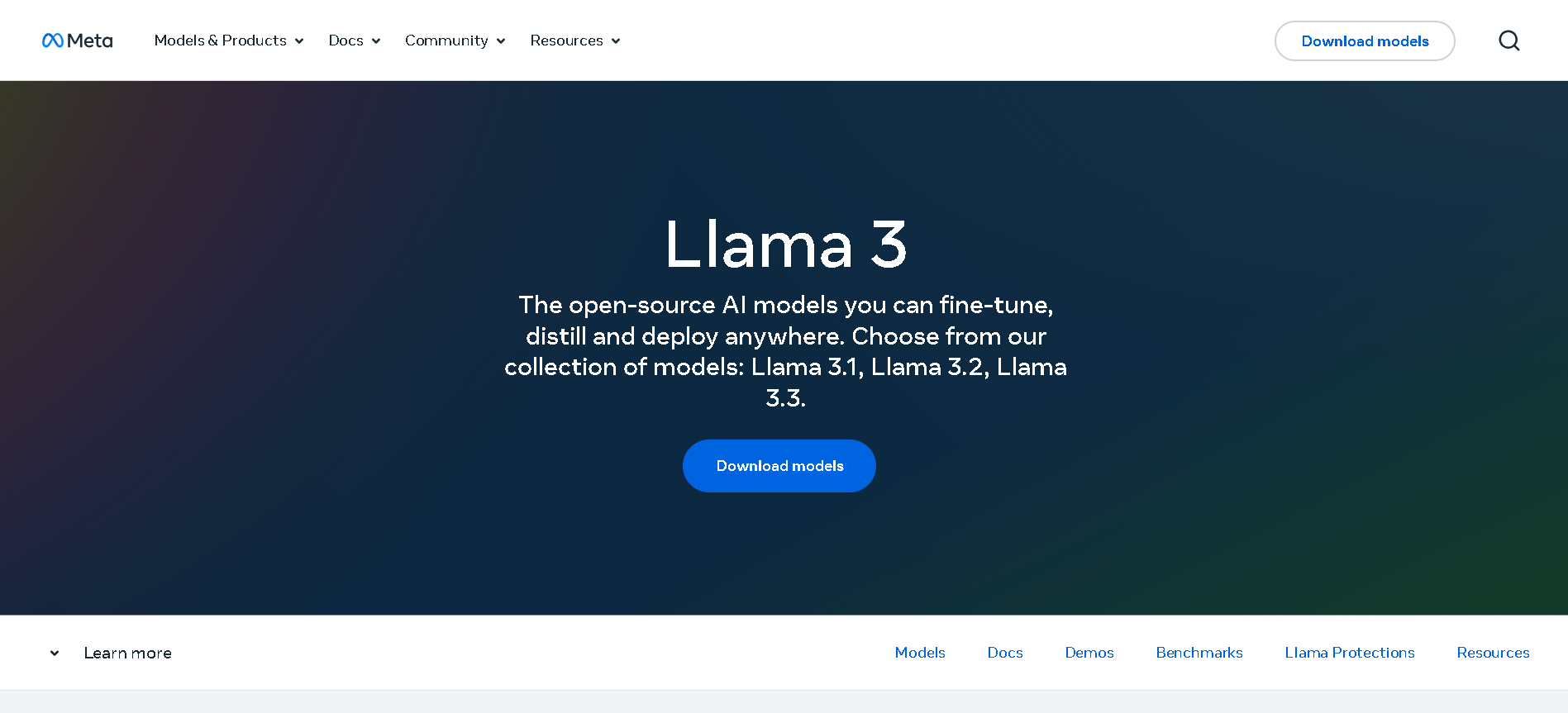

Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.

Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai