
- Premium+ Subscribers: Users of X’s higher-tier plan gain priority access to Grok 3's features.
- SuperGrok Members: Standalone users with SuperGrok subscription unlock full capabilities including DeepSearch and unlimited image generation.
- Data Scientists & Developers: Ideal for complex logic, coding, and technical reasoning with Think and Big Brain modes.
- Researchers & Analysts: DeepSearch provides rapid, cited insight synthesis across internet and social channels.
- Creators & Chat Enthusiasts: Supports expressive, customizable tone—humorous, sarcastic, academic—for engaging chat.
How to Use Grok 3?
- Log In to Your Account: Access via X Premium+ or the Grok app/website with SuperGrok.
- Enter Prompts: Chat normally or request deeper thinking with Think/Big Brain; use DeepSearch for research summaries.
- Submit Mixed Inputs: Text or context prompts trigger fast, contextual responses.
- Scale Usage: Ideal for on-the-fly research, coding help, or conversational agents across platforms.
- Upgrade as Needed: SuperGrok unlocks advanced reasoning, image tools, and early feature access.
- 10× Computing Power: Built on a 200K-GPU cluster, offering significant speed and depth.
- Think & Big Brain Modes: Let the model spend more compute to solve difficult problems with visible reasoning.
- DeepSearch Agent: Pulls from internet and X to provide traceable summaries and data-driven reports.
- Lively & Honest Chat Style: More personality and less censorship compared to competitors.
- Multimodal & High Throughput: Handles text, coding, and summaries with speed and expressive output.
- Frontier-tier performance in reasoning, coding, and research
- Visible chain of thought for trust and transparency
- DeepSearch brings agentic web research into chat
- Distinctive chat personality with humor and tone control
- Works across chat, app, and subscription models
- Responses can be unpredictable or controversial
- May produce biases or inaccuracies in sensitive topics
- Requires multiple subscriptions (Premium+ and SuperGrok) for full features
Free Tier
$ 0.00
Aurora Image Model
Context Memory
Limited access to Thinking
Limited access to DeepSearch
Limited access to DeeperSearch
Super Grok
$30/month
More Aurora Images - 100 Images / 2h
Even Better Memory - 128K Context Window
Extended access to Thinking - 30 Queries / 2h
Extended access to DeepSearch - 30 Queries / 2h
Extended access to DeeperSearch - 10 Queries / 2h
API
$3/$15 per 1M tokens
Cached Input - $0.75/M
Output - $15.00/M
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
Claude 3 Haiku
Claude 3 Haiku is Anthropic’s fastest and most affordable model in its Claude 3 family. It processes up to 21K tokens per second under 32K token prompts, delivers enterprise-grade vision and text understanding, and can analyze large datasets or image-heavy content in near real-time—all while offering ultra‑low latency and cost.
Claude 3 Haiku
Claude 3 Haiku is Anthropic’s fastest and most affordable model in its Claude 3 family. It processes up to 21K tokens per second under 32K token prompts, delivers enterprise-grade vision and text understanding, and can analyze large datasets or image-heavy content in near real-time—all while offering ultra‑low latency and cost.
Claude 3 Haiku
Claude 3 Haiku is Anthropic’s fastest and most affordable model in its Claude 3 family. It processes up to 21K tokens per second under 32K token prompts, delivers enterprise-grade vision and text understanding, and can analyze large datasets or image-heavy content in near real-time—all while offering ultra‑low latency and cost.

Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.

Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
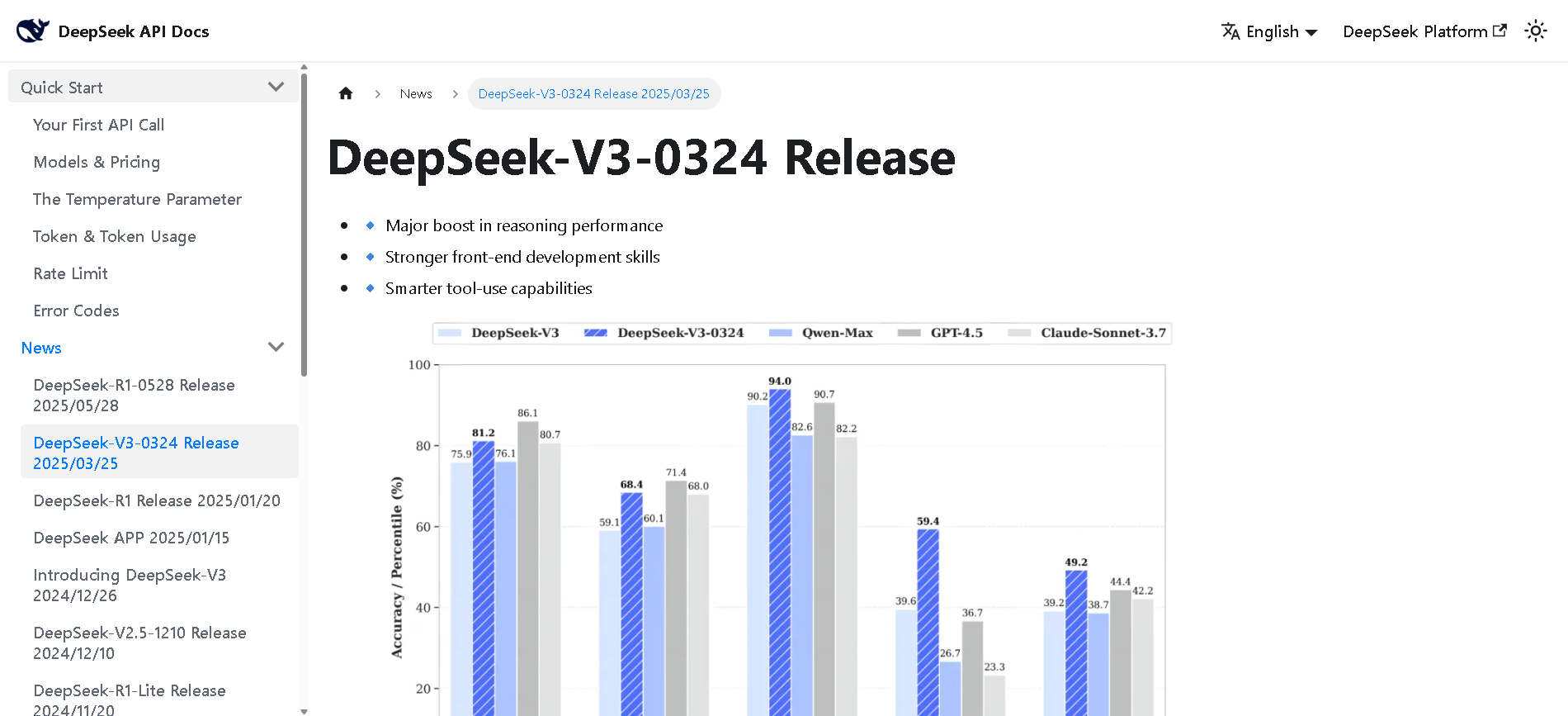
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.

grok-2-vision
Grok 2 Vision (also known as Grok‑2‑Vision‑1212 or grok‑2‑vision‑latest) is xAI’s multimodal variant of Grok 2, designed specifically for advanced image understanding and generation. Launched in December 2024, it supports joint text+image inputs up to 32,768 tokens, excelling in visual math reasoning (MathVista), document question answering (DocVQA), object recognition, and style analysis—while also offering photorealistic image creation via the FLUX.1 model.
grok-2-vision
Grok 2 Vision (also known as Grok‑2‑Vision‑1212 or grok‑2‑vision‑latest) is xAI’s multimodal variant of Grok 2, designed specifically for advanced image understanding and generation. Launched in December 2024, it supports joint text+image inputs up to 32,768 tokens, excelling in visual math reasoning (MathVista), document question answering (DocVQA), object recognition, and style analysis—while also offering photorealistic image creation via the FLUX.1 model.
grok-2-vision
Grok 2 Vision (also known as Grok‑2‑Vision‑1212 or grok‑2‑vision‑latest) is xAI’s multimodal variant of Grok 2, designed specifically for advanced image understanding and generation. Launched in December 2024, it supports joint text+image inputs up to 32,768 tokens, excelling in visual math reasoning (MathVista), document question answering (DocVQA), object recognition, and style analysis—while also offering photorealistic image creation via the FLUX.1 model.
Grok 2 Vision is xAI’s advanced vision-enabled variant of Grok 2, launched in December 2024. It supports joint text + image inputs with a 32K-token context window, combining image understanding, document QA, visual math reasoning (e.g., MathVista, DocVQA), and photorealistic image generation via FLUX.1 (later complemented by Aurora). It scores state-of-the-art on multimodal tasks.
Grok 2 Vision is xAI’s advanced vision-enabled variant of Grok 2, launched in December 2024. It supports joint text + image inputs with a 32K-token context window, combining image understanding, document QA, visual math reasoning (e.g., MathVista, DocVQA), and photorealistic image generation via FLUX.1 (later complemented by Aurora). It scores state-of-the-art on multimodal tasks.
Grok 2 Vision is xAI’s advanced vision-enabled variant of Grok 2, launched in December 2024. It supports joint text + image inputs with a 32K-token context window, combining image understanding, document QA, visual math reasoning (e.g., MathVista, DocVQA), and photorealistic image generation via FLUX.1 (later complemented by Aurora). It scores state-of-the-art on multimodal tasks.

grok-2-vision-1212
Grok 2 Vision – 1212 is a December 2024 release of xAI’s multimodal large language model, fine-tuned specifically for image understanding and generation. It supports combined text and image inputs (up to 32,768 tokens) and excels in document question answering, visual math reasoning, object recognition, and photorealistic image generation powered by FLUX.1. It also supports API deployment for developers and enterprises.
grok-2-vision-1212
Grok 2 Vision – 1212 is a December 2024 release of xAI’s multimodal large language model, fine-tuned specifically for image understanding and generation. It supports combined text and image inputs (up to 32,768 tokens) and excels in document question answering, visual math reasoning, object recognition, and photorealistic image generation powered by FLUX.1. It also supports API deployment for developers and enterprises.
grok-2-vision-1212
Grok 2 Vision – 1212 is a December 2024 release of xAI’s multimodal large language model, fine-tuned specifically for image understanding and generation. It supports combined text and image inputs (up to 32,768 tokens) and excels in document question answering, visual math reasoning, object recognition, and photorealistic image generation powered by FLUX.1. It also supports API deployment for developers and enterprises.

grok-2-image-1212
Grok 2 Image 1212 (also known as grok-2-image-1212) is xAI’s December 2024 release of their unified image generation and understanding model. Built on Grok 2, it combines Aurora-powered photorealistic image creation with strong multimodal comprehension—handling image editing, vision QA, chart interpretation, and document analysis—within a single API and 32,768-token context.
grok-2-image-1212
Grok 2 Image 1212 (also known as grok-2-image-1212) is xAI’s December 2024 release of their unified image generation and understanding model. Built on Grok 2, it combines Aurora-powered photorealistic image creation with strong multimodal comprehension—handling image editing, vision QA, chart interpretation, and document analysis—within a single API and 32,768-token context.
grok-2-image-1212
Grok 2 Image 1212 (also known as grok-2-image-1212) is xAI’s December 2024 release of their unified image generation and understanding model. Built on Grok 2, it combines Aurora-powered photorealistic image creation with strong multimodal comprehension—handling image editing, vision QA, chart interpretation, and document analysis—within a single API and 32,768-token context.

Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.

DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai