- Customer Support & Live Chat: Power responsive chatbots and FAQ systems with minimal delay.
- Data & Document Teams: Analyze contracts, filings, and reports quickly with extracted insights.
- Content Moderation: Detect policy violations instantly across text and images.
- Localization & Translation: Provide real-time translations with fast, low-cost performance.
- Enterprise Developers: Build high-throughput, AI-powered applications with vision and language support.
How to Use Claude 3 Haiku?
- Get Access: Available through Anthropic API, Claude.ai Pro plan, Amazon Bedrock, and coming soon to Google Vertex AI.
- Send Inputs: Submit text, PDFs, or images; Haiku processes them with near-instant response time.
- Run High-Speed Workloads: Use for chat support, compliance scans, RAG pipelines, or summarization tasks.
- Scale Efficiently: Benefit from its fast token throughput and cost-effective pricing structure.
- Deploy Securely: Integrate with enterprise-grade monitoring, authentication, and encryption.
- Blazing-Fast Throughput: Processes around 21,000 tokens per second for short prompts—ideal for real-time workflows.
- Enterprise-Ready Vision Capabilities: Understands and processes images, PDFs, and documents alongside text.
- Cost-Optimized: Offers a 1:5 input-to-output token pricing ratio, making it highly economical for large workloads.
- Supports Large Context: Can handle up to 200K tokens in a single session.
- Secure by Design: Built with enterprise-grade security, monitoring, and compliance standards.
- Unmatched speed for live chat, document analysis, and scaling
- Vision-to-text capabilities within the same fast model
- Cost-effective with Haiku’s unique pricing model
- Secure, robust, enterprise-ready architecture
- Broad platform availability for easy integration
- Lower reasoning depth compared to Sonnet or Opus
- Not designed for complex coding or logic tasks
- Best suited for short tasks; may underperform on deep workflows
Pro Mode
$20/month
Connect Google Workspace: email, calendar, and docs
Connect any context or tool through Integrations with remote MCP
Extended thinking for complex work
Ability to use more Claude models
Max
$100/month
- Choose 5x or 20x more usage than Pro
- Higher output limits for all tasks
- Early access to advanced Claude features
- Priority access at high traffic times
API Usage
$0.25/$1.25 per 1M tokens
- $0.25 input & $1.25 output per 1M tokens
- Prompt caching write- $0.30 / MTok
- Prompt caching read- $0.03 / MTok
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.
grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.
grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.

Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.

Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Claude Opus 4.1
Claude Opus 4.1 is the latest upgrade of Anthropic’s AI model Claude Opus 4, enhancing agentic tasks, coding, and reasoning capabilities. This version improves state-of-the-art coding performance, achieving 74.5% on SWE-bench Verified and excels in detailed research, data analysis, and multi-file code refactoring. It is optimized for precise bug fixes without unnecessary changes and is designed to boost productivity for developers and researchers. Claude Opus 4.1 is available via API and integrated into platforms like Amazon Bedrock and Google Cloud’s Vertex AI, offering advanced AI solutions with consistent pricing from the previous model.
Claude Opus 4.1
Claude Opus 4.1 is the latest upgrade of Anthropic’s AI model Claude Opus 4, enhancing agentic tasks, coding, and reasoning capabilities. This version improves state-of-the-art coding performance, achieving 74.5% on SWE-bench Verified and excels in detailed research, data analysis, and multi-file code refactoring. It is optimized for precise bug fixes without unnecessary changes and is designed to boost productivity for developers and researchers. Claude Opus 4.1 is available via API and integrated into platforms like Amazon Bedrock and Google Cloud’s Vertex AI, offering advanced AI solutions with consistent pricing from the previous model.
Claude Opus 4.1
Claude Opus 4.1 is the latest upgrade of Anthropic’s AI model Claude Opus 4, enhancing agentic tasks, coding, and reasoning capabilities. This version improves state-of-the-art coding performance, achieving 74.5% on SWE-bench Verified and excels in detailed research, data analysis, and multi-file code refactoring. It is optimized for precise bug fixes without unnecessary changes and is designed to boost productivity for developers and researchers. Claude Opus 4.1 is available via API and integrated into platforms like Amazon Bedrock and Google Cloud’s Vertex AI, offering advanced AI solutions with consistent pricing from the previous model.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
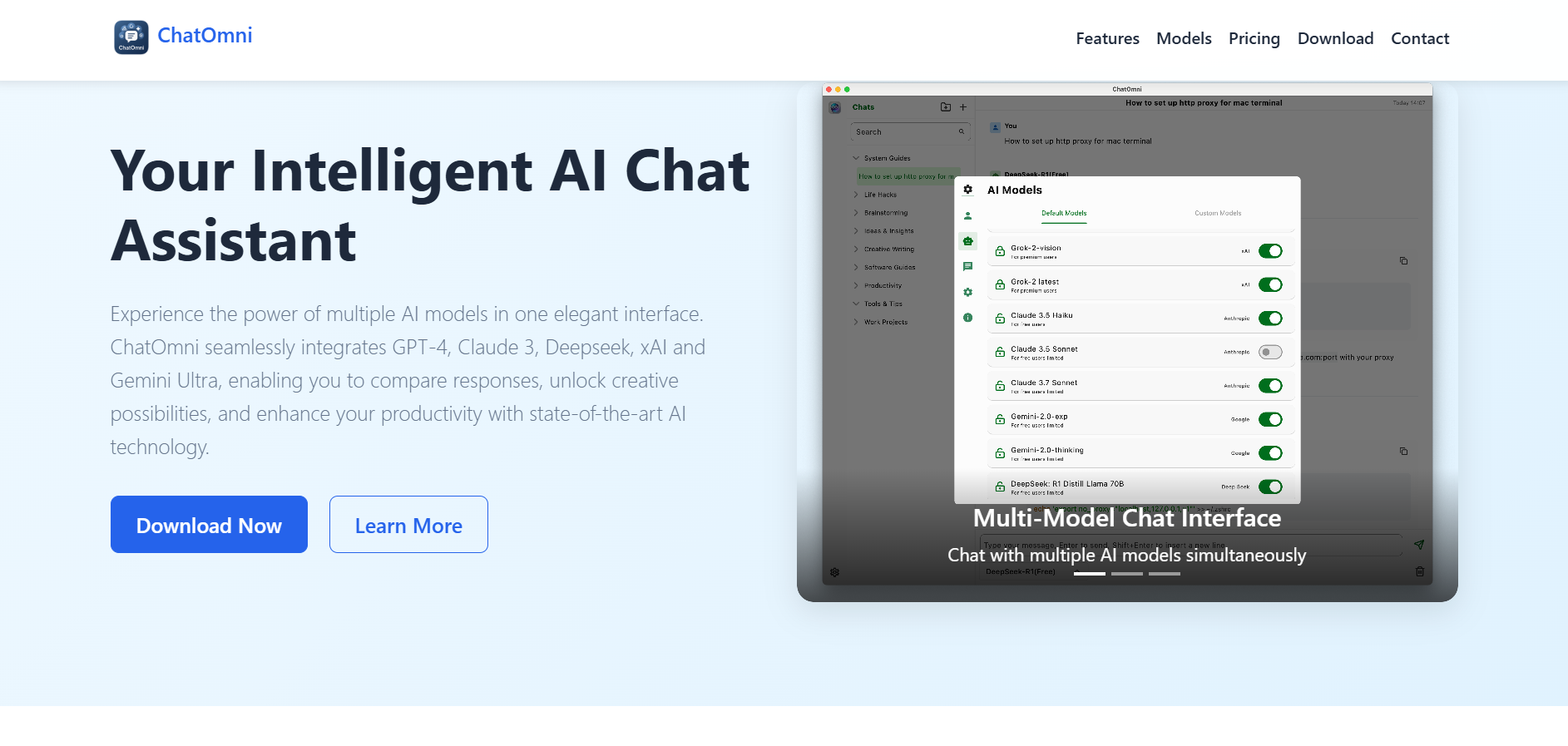
ChatOmni
ChatOmni is a multi-model AI chat platform that brings together multiple leading AI models into a single, unified conversational interface designed to enhance user productivity, creativity, and information depth. The platform supports top-tier large language models such as GPT-4, Claude 3, xAI Grok, Gemini Ultra, and Deepseek, allowing users to chat, compare responses side by side, and tailor outputs to their needs without switching between tools. ChatOmni provides advanced chat management features, including unlimited history, folders, advanced search, and export options, enabling users to organize interactions efficiently. With custom API key support and automatic updates to the latest available models, the platform is positioned as a flexible, evolving AI assistant for research, writing, design, brainstorming, and multi-model comparison workflows across professional and personal contexts.
ChatOmni
ChatOmni is a multi-model AI chat platform that brings together multiple leading AI models into a single, unified conversational interface designed to enhance user productivity, creativity, and information depth. The platform supports top-tier large language models such as GPT-4, Claude 3, xAI Grok, Gemini Ultra, and Deepseek, allowing users to chat, compare responses side by side, and tailor outputs to their needs without switching between tools. ChatOmni provides advanced chat management features, including unlimited history, folders, advanced search, and export options, enabling users to organize interactions efficiently. With custom API key support and automatic updates to the latest available models, the platform is positioned as a flexible, evolving AI assistant for research, writing, design, brainstorming, and multi-model comparison workflows across professional and personal contexts.
ChatOmni
ChatOmni is a multi-model AI chat platform that brings together multiple leading AI models into a single, unified conversational interface designed to enhance user productivity, creativity, and information depth. The platform supports top-tier large language models such as GPT-4, Claude 3, xAI Grok, Gemini Ultra, and Deepseek, allowing users to chat, compare responses side by side, and tailor outputs to their needs without switching between tools. ChatOmni provides advanced chat management features, including unlimited history, folders, advanced search, and export options, enabling users to organize interactions efficiently. With custom API key support and automatic updates to the latest available models, the platform is positioned as a flexible, evolving AI assistant for research, writing, design, brainstorming, and multi-model comparison workflows across professional and personal contexts.
Yes Chat
YesChat AI is an all-in-one AI platform powered by advanced models such as DeepSeek-R1, GPT-o1, GPT-4o, Claude 3.5 Sonnet, and Claude 3 Opus. It offers AI chat, music generation, video creation, and image generation within one environment. The platform gives users ultra-fast, intelligent responses while enabling creative and multimedia capabilities through multiple high-performance models. By combining several leading AI engines, YesChat AI provides flexibility for writing, research, creativity, and content generation without requiring different subscriptions or tools.
Yes Chat
YesChat AI is an all-in-one AI platform powered by advanced models such as DeepSeek-R1, GPT-o1, GPT-4o, Claude 3.5 Sonnet, and Claude 3 Opus. It offers AI chat, music generation, video creation, and image generation within one environment. The platform gives users ultra-fast, intelligent responses while enabling creative and multimedia capabilities through multiple high-performance models. By combining several leading AI engines, YesChat AI provides flexibility for writing, research, creativity, and content generation without requiring different subscriptions or tools.
Yes Chat
YesChat AI is an all-in-one AI platform powered by advanced models such as DeepSeek-R1, GPT-o1, GPT-4o, Claude 3.5 Sonnet, and Claude 3 Opus. It offers AI chat, music generation, video creation, and image generation within one environment. The platform gives users ultra-fast, intelligent responses while enabling creative and multimedia capabilities through multiple high-performance models. By combining several leading AI engines, YesChat AI provides flexibility for writing, research, creativity, and content generation without requiring different subscriptions or tools.

polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.

Gemini 3
Gemini 3 is Google's most advanced AI model family, including Gemini 3 Pro and Gemini 3 Flash, excelling in state-of-the-art reasoning, multimodal understanding across text, images, video, audio, and code, with exceptional agentic capabilities for handling complex, multi-step tasks autonomously. Accessible directly in Google AI Studio for developers to experiment, tune prompts, and build apps, it shines in vibe coding, generating interactive experiences from ideas, superior tool use like Google Search integration, and conversational editing for images. With a massive 1M token context window, Deep Think mode for ultra-complex problem-solving, and features like structured outputs and function calling, it powers everything from personal assistants to sophisticated workflows, outperforming predecessors on benchmarks like GPQA and ARC-AGI.
Gemini 3
Gemini 3 is Google's most advanced AI model family, including Gemini 3 Pro and Gemini 3 Flash, excelling in state-of-the-art reasoning, multimodal understanding across text, images, video, audio, and code, with exceptional agentic capabilities for handling complex, multi-step tasks autonomously. Accessible directly in Google AI Studio for developers to experiment, tune prompts, and build apps, it shines in vibe coding, generating interactive experiences from ideas, superior tool use like Google Search integration, and conversational editing for images. With a massive 1M token context window, Deep Think mode for ultra-complex problem-solving, and features like structured outputs and function calling, it powers everything from personal assistants to sophisticated workflows, outperforming predecessors on benchmarks like GPQA and ARC-AGI.
Gemini 3
Gemini 3 is Google's most advanced AI model family, including Gemini 3 Pro and Gemini 3 Flash, excelling in state-of-the-art reasoning, multimodal understanding across text, images, video, audio, and code, with exceptional agentic capabilities for handling complex, multi-step tasks autonomously. Accessible directly in Google AI Studio for developers to experiment, tune prompts, and build apps, it shines in vibe coding, generating interactive experiences from ideas, superior tool use like Google Search integration, and conversational editing for images. With a massive 1M token context window, Deep Think mode for ultra-complex problem-solving, and features like structured outputs and function calling, it powers everything from personal assistants to sophisticated workflows, outperforming predecessors on benchmarks like GPQA and ARC-AGI.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai