- Enterprise & Cloud Teams: Deploy hybrid, in-VPC, or on-premises setups using just four GPUs.
- Developers & Engineers: Build coding assistants, document parsers, or multimodal agents with function calling and long-text support.
- Data Scientists & Analysts: Analyze technical documents, codebases, images, and business data with a single model.
- Researchers & Evaluators: Benchmark on coding, STEM, multimodal tasks thanks to high accuracy at low cost.
- Early Adopters in Regulated Fields: Finance, healthcare, energy sectors using secure, customizable AI pipelines.
How to Use Mistral Medium 3?
- Access the Model: Available via Mistral’s API (`mistral-medium-2505`), Amazon SageMaker, IBM watsonx, NVIDIA NIM, Azure Foundry, and Google Vertex.
- Send Prompts: Input text and images, context up to 128K tokens for extensive pipelines.
- Use in Enterprise: Self-host on four GPUs or customize with post-training to embed internal knowledge.
- Monitor Costs: Approx. $0.40 per million input tokens, $2 per million output tokens—8× cheaper than rivals.
- Deploy Agents & Function Calls: Integrates seamlessly with tool-calling APIs and structured outputs.
- Cost-Efficient Frontier Performance: Matches ~90% of Claude Sonnet 3.7 and outpaces Llama 4 Maverick—while being 8× cheaper and faster.
- Frontline Coding & STEM: Outstanding 0-shot results—HumanEval (92.1%), Math500 (91%), ArenaHard (97.1%).
- Vision + Text + Long Context: Supports multimodal tasks like DocVQA (95.3%) and long-form understanding to 128K tokens.
- Enterprise Deployability: Easily self-hostable on four GPUs; supports post-training and in-VPC deployment.
- Wide Platform Reach: Available across major cloud providers and enterprise AI stacks.
- High performance in coding, STEM, and multimodal tasks
- Cost-efficient token pricing ideal for scale
- Supports long-context pipelines and function calls
- Flexible deployment options including self-hosted & customizable
- Broad enterprise and cloud integration
- Not open-source; proprietary weights
- Four‑GPU requirement may limit smaller teams
- Enterprise pricing and support needed for customization
Chat
0/$14.99/$24.99 per month
Free - $0
Pro - $14.99 per month
Enterprise - $24.99 per month
API
$0.40/$2 per 1M tokens
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
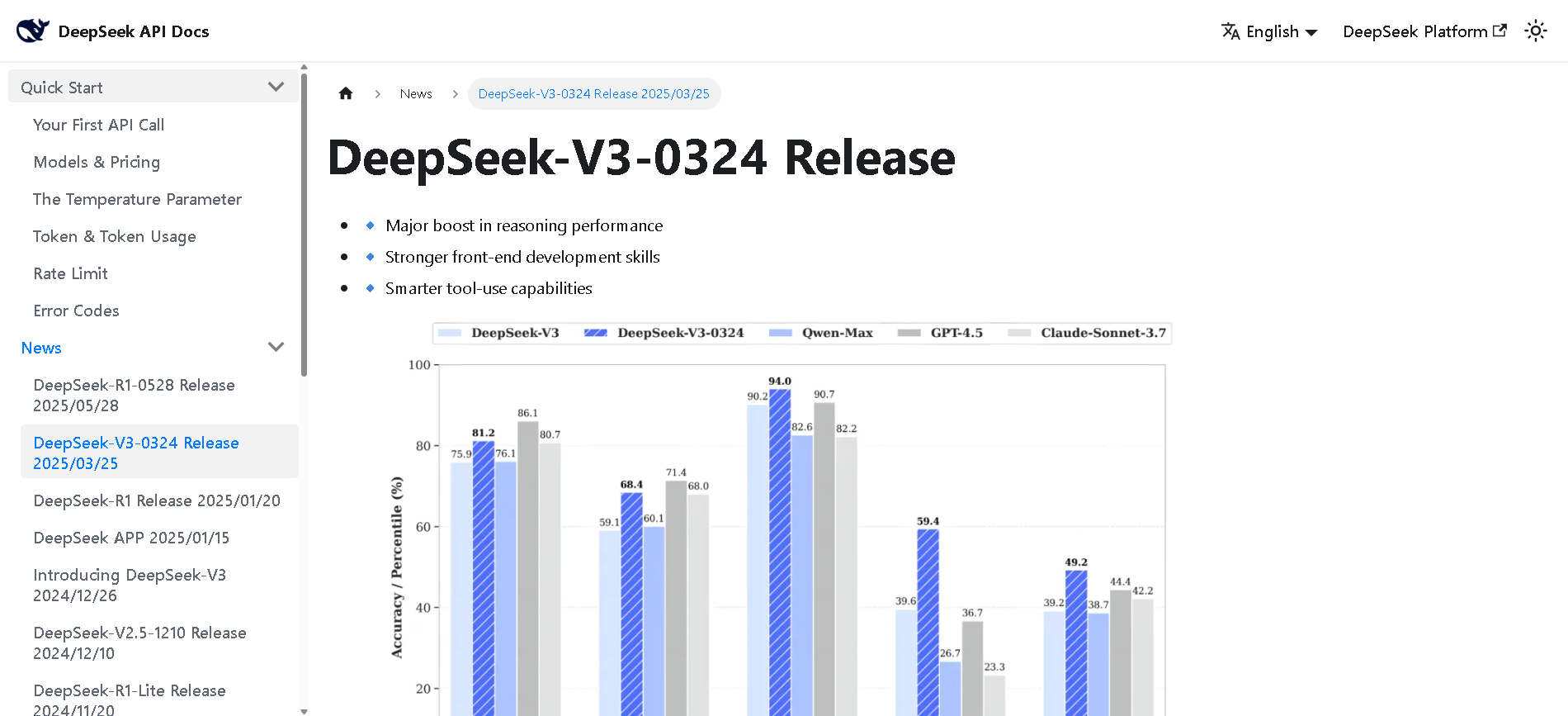
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.

Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.

Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.

Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.

DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai