- Developers & Engineers: Build efficient retrieval systems, search features, and RAG pipelines for text-heavy datasets.
- Data Scientists & Analysts: Cluster and classify large corpora of documents or logs semantically.
- AI Researchers: Use it for semantic search benchmarking or powering LLM retrieval pipelines.
- Enterprises & Product Teams: Integrate document similarity and search features into applications and platforms.
- Open-Source Advocates: Access via LangChain, Pinecone, Meilisearch, Zilliz, and other developer-friendly ecosystems.
How to Use Mistral Embed?
- Call the API: Use endpoint `mistral-embed` via Mistral’s API with appropriate API key.
- Process Text Inputs: Submit batches up to 8,192 tokens to generate 1,024-dimensional embeddings.
- Integrate With Vector DBs: Push embeddings to stores like Pinecone, Meilisearch, or Zilliz; perform semantic search and RAG.
- Optimize Retrieval: Use cosine or dot-product similarity on normalized vectors; adjust hybrid search configurations as needed.
- Scale via SDKs: Utilize LangChain’s `MistralAIEmbeddings` for seamless embedding integration in Python workflows.
- High Capacity: Supports embedding long documents (up to 8K tokens)—ideal for summaries and larger texts.
- Modern Architecture: Outperforms or matches other top embedding models despite its relatively smaller size.
- Developer-Friendly: Easily integrates with major vector databases via open SDKs and ecosystem tools.
- Optimized for Retrieval: Designed to deliver accurate similarity results for RAG, classification, and clustering.
- Handles longer inputs (up to 8K tokens) better than many competitors
- Embeds down to 1,024 dimensions—efficient embedding size
- Broad integration via Pinecone, Zilliz, Meilisearch, LangChain, etc.
- Suitable for semantic search, classification, and clustering
- Developer ecosystem and SDK support smooth adoption
- Proprietary model—not open-source, restricted to Mistral API use
- Larger vector size (1,024 dims) may raise storage costs
- No official code embedding support in mistral-embed—there’s separate model for that
API only
$0.1 per 1M input tokens
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

jina
Jina AI is a Berlin-based software company that provides a "search foundation" platform, offering various AI-powered tools designed to help developers build the next generation of search applications for unstructured data. Its mission is to enable businesses to create reliable and high-quality Generative AI (GenAI) and multimodal search applications by combining Embeddings, Rerankers, and Small Language Models (SLMs). Jina AI's tools are designed to provide real-time, accurate, and unbiased information, optimized for LLMs and AI agents.
jina
Jina AI is a Berlin-based software company that provides a "search foundation" platform, offering various AI-powered tools designed to help developers build the next generation of search applications for unstructured data. Its mission is to enable businesses to create reliable and high-quality Generative AI (GenAI) and multimodal search applications by combining Embeddings, Rerankers, and Small Language Models (SLMs). Jina AI's tools are designed to provide real-time, accurate, and unbiased information, optimized for LLMs and AI agents.
jina
Jina AI is a Berlin-based software company that provides a "search foundation" platform, offering various AI-powered tools designed to help developers build the next generation of search applications for unstructured data. Its mission is to enable businesses to create reliable and high-quality Generative AI (GenAI) and multimodal search applications by combining Embeddings, Rerankers, and Small Language Models (SLMs). Jina AI's tools are designed to provide real-time, accurate, and unbiased information, optimized for LLMs and AI agents.
Text-Embedding-3-Small is OpenAI’s ultra-efficient embedding model that converts text into high-dimensional numerical vectors, optimized for performance and affordability. With just 1536 dimensions and a significantly lower cost than its larger counterpart (text-embedding-3-large), this model offers state-of-the-art performance for semantic search, recommendation systems, clustering, classification, and more—all while being 5x cheaper. Despite its “small” label, this model punches well above its weight, providing excellent performance for the vast majority of use cases where embedding is key.
Text-Embedding-3-Small is OpenAI’s ultra-efficient embedding model that converts text into high-dimensional numerical vectors, optimized for performance and affordability. With just 1536 dimensions and a significantly lower cost than its larger counterpart (text-embedding-3-large), this model offers state-of-the-art performance for semantic search, recommendation systems, clustering, classification, and more—all while being 5x cheaper. Despite its “small” label, this model punches well above its weight, providing excellent performance for the vast majority of use cases where embedding is key.
Text-Embedding-3-Small is OpenAI’s ultra-efficient embedding model that converts text into high-dimensional numerical vectors, optimized for performance and affordability. With just 1536 dimensions and a significantly lower cost than its larger counterpart (text-embedding-3-large), this model offers state-of-the-art performance for semantic search, recommendation systems, clustering, classification, and more—all while being 5x cheaper. Despite its “small” label, this model punches well above its weight, providing excellent performance for the vast majority of use cases where embedding is key.

OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.

GPT-4o Search Preview is a powerful experimental feature of OpenAI’s GPT-4o model, designed to act as a high-performance retrieval system. Rather than just generating answers from training data, it allows the model to search through large datasets, documents, or knowledge bases to surface relevant results with context-aware accuracy. Think of it as your AI assistant with built-in research superpowers—faster, smarter, and surprisingly precise. This preview gives developers a taste of what’s coming next: an intelligent search engine built directly into the GPT-4o ecosystem.
GPT-4o Search Preview is a powerful experimental feature of OpenAI’s GPT-4o model, designed to act as a high-performance retrieval system. Rather than just generating answers from training data, it allows the model to search through large datasets, documents, or knowledge bases to surface relevant results with context-aware accuracy. Think of it as your AI assistant with built-in research superpowers—faster, smarter, and surprisingly precise. This preview gives developers a taste of what’s coming next: an intelligent search engine built directly into the GPT-4o ecosystem.
GPT-4o Search Preview is a powerful experimental feature of OpenAI’s GPT-4o model, designed to act as a high-performance retrieval system. Rather than just generating answers from training data, it allows the model to search through large datasets, documents, or knowledge bases to surface relevant results with context-aware accuracy. Think of it as your AI assistant with built-in research superpowers—faster, smarter, and surprisingly precise. This preview gives developers a taste of what’s coming next: an intelligent search engine built directly into the GPT-4o ecosystem.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.

DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.

Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Codestral 25.01 is Mistral AI’s upgraded code-generation model, released January 13, 2025. Featuring a more efficient architecture and improved tokenizer, it delivers code completion and intelligence about 2× faster than its predecessor, with support for fill-in-the-middle (FIM), code correction, test generation, and proficiency in over 80 programming languages, all within a 256K-token context window.
Codestral 25.01 is Mistral AI’s upgraded code-generation model, released January 13, 2025. Featuring a more efficient architecture and improved tokenizer, it delivers code completion and intelligence about 2× faster than its predecessor, with support for fill-in-the-middle (FIM), code correction, test generation, and proficiency in over 80 programming languages, all within a 256K-token context window.
Codestral 25.01 is Mistral AI’s upgraded code-generation model, released January 13, 2025. Featuring a more efficient architecture and improved tokenizer, it delivers code completion and intelligence about 2× faster than its predecessor, with support for fill-in-the-middle (FIM), code correction, test generation, and proficiency in over 80 programming languages, all within a 256K-token context window.
Mistral Saba
Mistral Saba is a 24 billion‑parameter regional language model launched by Mistral AI on February 17, 2025. Designed for native fluency in Arabic and South Asian languages (like Tamil, Malayalam, and Urdu), it delivers culturally-aware responses on single‑GPU systems—faster and more precise than much larger general models.
Mistral Saba
Mistral Saba is a 24 billion‑parameter regional language model launched by Mistral AI on February 17, 2025. Designed for native fluency in Arabic and South Asian languages (like Tamil, Malayalam, and Urdu), it delivers culturally-aware responses on single‑GPU systems—faster and more precise than much larger general models.
Mistral Saba
Mistral Saba is a 24 billion‑parameter regional language model launched by Mistral AI on February 17, 2025. Designed for native fluency in Arabic and South Asian languages (like Tamil, Malayalam, and Urdu), it delivers culturally-aware responses on single‑GPU systems—faster and more precise than much larger general models.
Mistral Document AI is Mistral AI’s enterprise-grade document processing platform, launched May 2025. It combines state-of-the-art OCR model mistral-ocr-latest with structured data extraction, document Q&A, and natural language understanding—delivering 99%+ OCR accuracy, support for over 40 languages and complex layouts (tables, forms, handwriting), and blazing-fast processing at up to 2,000 pages/min per GPU.
Mistral Document AI is Mistral AI’s enterprise-grade document processing platform, launched May 2025. It combines state-of-the-art OCR model mistral-ocr-latest with structured data extraction, document Q&A, and natural language understanding—delivering 99%+ OCR accuracy, support for over 40 languages and complex layouts (tables, forms, handwriting), and blazing-fast processing at up to 2,000 pages/min per GPU.
Mistral Document AI is Mistral AI’s enterprise-grade document processing platform, launched May 2025. It combines state-of-the-art OCR model mistral-ocr-latest with structured data extraction, document Q&A, and natural language understanding—delivering 99%+ OCR accuracy, support for over 40 languages and complex layouts (tables, forms, handwriting), and blazing-fast processing at up to 2,000 pages/min per GPU.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
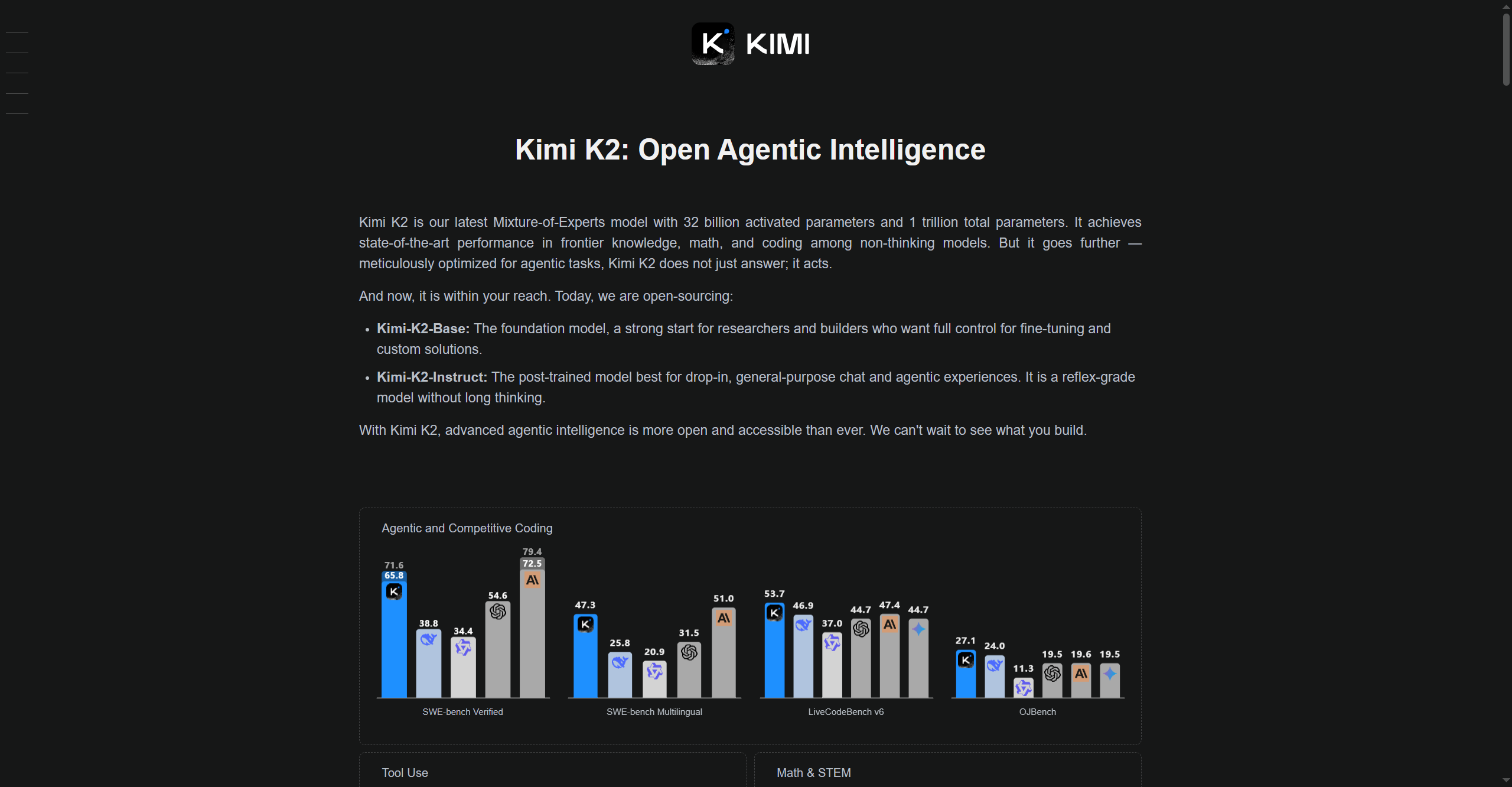

Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai