
- Developers & Engineers: Build multimodal apps like visual assistants, document parsers, and image Q&A tools.
- Analysts & Researchers: Automate chart analysis, document image understanding, and multimodal content summarization.
- Educators & Students: Solve visual math problems, analyze diagrams, and work with text-image inputs in education.
- Enterprises & Teams: Deploy large-context QA systems, OCR pipelines, and image-based chat assistants via API/cloud.
- Open-Source & Edge Advocates: Innovate on a transparent multimodal foundation model with expansive support.
How to Use Llama 3.2 Vision?
- Select Model Size: Choose 11B or 90B based on your compute and accuracy needs.
- Deploy via Platforms: Available on Hugging Face, Oracle OCI, AWS Bedrock, Databricks, Vertex AI, Ollama, and local setups.
- Submit Image+Text: Send mixed prompts—images plus text—within 128K-token context for reasoning or captioning.
- Perform Vision Tasks: Handle image captioning, visual QA (VQAv2), chart or diagram interpretation (ChartQA, DocVQA), and photoreal understanding.
- Optimize Inference: Use grouped-query attention (GQA), quantization, and efficient pipelines—edge variants available for low-latency use.
- Vision Excellence: Achieves top-tier scores—DocVQA
70.7% and AI2 Diagram75.3% (11B) or90.1% &92.3% (90B). - Visual Math & Charts: ChartQA
85.5% and MathVista57.3% with chain-of-thought reasoning. - Massive Context Window: 128K tokens for long-form, multimodal workflows.
- Open-Source Availability: Licensed under Meta’s Community License; commercial-friendly with some usage restrictions.
- Wide Platform Reach: Available across major cloud & local platforms—accessible to developers everywhere.
- Outstanding vision reasoning benchmarks in open-source models
- Large context supports document and image workflows
- Multimodal in a single pipeline—no separate vision endpoint
- Available on multiple platforms, from cloud to edge
- Efficient inference via GQA and quantization options
- Vision focused—doesn’t support audio or video modalities
- In-context window, though large, may still limit ultra-long docs
- 90 B variant requires heavier compute resources
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI GPT Image 1
GPT-Image-1 is OpenAI's state-of-the-art vision model designed to understand and interpret images with human-like perception. It enables developers and businesses to analyze, summarize, and extract detailed insights from images using natural language. Whether you're building AI agents, accessibility tools, or image-driven workflows, GPT-Image-1 brings powerful multimodal capabilities into your applications with impressive accuracy. Optimized for use via API, it can handle diverse image types—charts, screenshots, photographs, documents, and more—making it one of the most versatile models in OpenAI’s portfolio.
OpenAI GPT Image 1
GPT-Image-1 is OpenAI's state-of-the-art vision model designed to understand and interpret images with human-like perception. It enables developers and businesses to analyze, summarize, and extract detailed insights from images using natural language. Whether you're building AI agents, accessibility tools, or image-driven workflows, GPT-Image-1 brings powerful multimodal capabilities into your applications with impressive accuracy. Optimized for use via API, it can handle diverse image types—charts, screenshots, photographs, documents, and more—making it one of the most versatile models in OpenAI’s portfolio.
OpenAI GPT Image 1
GPT-Image-1 is OpenAI's state-of-the-art vision model designed to understand and interpret images with human-like perception. It enables developers and businesses to analyze, summarize, and extract detailed insights from images using natural language. Whether you're building AI agents, accessibility tools, or image-driven workflows, GPT-Image-1 brings powerful multimodal capabilities into your applications with impressive accuracy. Optimized for use via API, it can handle diverse image types—charts, screenshots, photographs, documents, and more—making it one of the most versatile models in OpenAI’s portfolio.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.

DeepSeek VL
DeepSeek VL is DeepSeek’s open-source vision-language model designed for real-world multimodal understanding. It employs a hybrid vision encoder (SigLIP‑L + SAM), processes high-resolution images (up to 1024×1024), and supports both base and chat variants across two sizes: 1.3B and 7B parameters. It excels on tasks like OCR, diagram reasoning, webpage parsing, and visual Q&A—while preserving strong language ability.
DeepSeek VL
DeepSeek VL is DeepSeek’s open-source vision-language model designed for real-world multimodal understanding. It employs a hybrid vision encoder (SigLIP‑L + SAM), processes high-resolution images (up to 1024×1024), and supports both base and chat variants across two sizes: 1.3B and 7B parameters. It excels on tasks like OCR, diagram reasoning, webpage parsing, and visual Q&A—while preserving strong language ability.
DeepSeek VL
DeepSeek VL is DeepSeek’s open-source vision-language model designed for real-world multimodal understanding. It employs a hybrid vision encoder (SigLIP‑L + SAM), processes high-resolution images (up to 1024×1024), and supports both base and chat variants across two sizes: 1.3B and 7B parameters. It excels on tasks like OCR, diagram reasoning, webpage parsing, and visual Q&A—while preserving strong language ability.

grok-2-vision
Grok 2 Vision (also known as Grok‑2‑Vision‑1212 or grok‑2‑vision‑latest) is xAI’s multimodal variant of Grok 2, designed specifically for advanced image understanding and generation. Launched in December 2024, it supports joint text+image inputs up to 32,768 tokens, excelling in visual math reasoning (MathVista), document question answering (DocVQA), object recognition, and style analysis—while also offering photorealistic image creation via the FLUX.1 model.
grok-2-vision
Grok 2 Vision (also known as Grok‑2‑Vision‑1212 or grok‑2‑vision‑latest) is xAI’s multimodal variant of Grok 2, designed specifically for advanced image understanding and generation. Launched in December 2024, it supports joint text+image inputs up to 32,768 tokens, excelling in visual math reasoning (MathVista), document question answering (DocVQA), object recognition, and style analysis—while also offering photorealistic image creation via the FLUX.1 model.
grok-2-vision
Grok 2 Vision (also known as Grok‑2‑Vision‑1212 or grok‑2‑vision‑latest) is xAI’s multimodal variant of Grok 2, designed specifically for advanced image understanding and generation. Launched in December 2024, it supports joint text+image inputs up to 32,768 tokens, excelling in visual math reasoning (MathVista), document question answering (DocVQA), object recognition, and style analysis—while also offering photorealistic image creation via the FLUX.1 model.
Grok 2 Vision is xAI’s advanced vision-enabled variant of Grok 2, launched in December 2024. It supports joint text + image inputs with a 32K-token context window, combining image understanding, document QA, visual math reasoning (e.g., MathVista, DocVQA), and photorealistic image generation via FLUX.1 (later complemented by Aurora). It scores state-of-the-art on multimodal tasks.
Grok 2 Vision is xAI’s advanced vision-enabled variant of Grok 2, launched in December 2024. It supports joint text + image inputs with a 32K-token context window, combining image understanding, document QA, visual math reasoning (e.g., MathVista, DocVQA), and photorealistic image generation via FLUX.1 (later complemented by Aurora). It scores state-of-the-art on multimodal tasks.
Grok 2 Vision is xAI’s advanced vision-enabled variant of Grok 2, launched in December 2024. It supports joint text + image inputs with a 32K-token context window, combining image understanding, document QA, visual math reasoning (e.g., MathVista, DocVQA), and photorealistic image generation via FLUX.1 (later complemented by Aurora). It scores state-of-the-art on multimodal tasks.

grok-2-vision-1212
Grok 2 Vision – 1212 is a December 2024 release of xAI’s multimodal large language model, fine-tuned specifically for image understanding and generation. It supports combined text and image inputs (up to 32,768 tokens) and excels in document question answering, visual math reasoning, object recognition, and photorealistic image generation powered by FLUX.1. It also supports API deployment for developers and enterprises.
grok-2-vision-1212
Grok 2 Vision – 1212 is a December 2024 release of xAI’s multimodal large language model, fine-tuned specifically for image understanding and generation. It supports combined text and image inputs (up to 32,768 tokens) and excels in document question answering, visual math reasoning, object recognition, and photorealistic image generation powered by FLUX.1. It also supports API deployment for developers and enterprises.
grok-2-vision-1212
Grok 2 Vision – 1212 is a December 2024 release of xAI’s multimodal large language model, fine-tuned specifically for image understanding and generation. It supports combined text and image inputs (up to 32,768 tokens) and excels in document question answering, visual math reasoning, object recognition, and photorealistic image generation powered by FLUX.1. It also supports API deployment for developers and enterprises.

Pixtral Large is Mistral AI’s latest multimodal powerhouse, launched November 18, 2024. Built atop the 123B‑parameter Mistral Large 2, it features a 124B‑parameter multimodal decoder paired with a 1B‑parameter vision encoder, and supports a massive 128K‑token context window—enabling it to process up to 30 high-resolution images or ~300-page documents.
Pixtral Large is Mistral AI’s latest multimodal powerhouse, launched November 18, 2024. Built atop the 123B‑parameter Mistral Large 2, it features a 124B‑parameter multimodal decoder paired with a 1B‑parameter vision encoder, and supports a massive 128K‑token context window—enabling it to process up to 30 high-resolution images or ~300-page documents.
Pixtral Large is Mistral AI’s latest multimodal powerhouse, launched November 18, 2024. Built atop the 123B‑parameter Mistral Large 2, it features a 124B‑parameter multimodal decoder paired with a 1B‑parameter vision encoder, and supports a massive 128K‑token context window—enabling it to process up to 30 high-resolution images or ~300-page documents.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
Prompt Llama
Prompt Llama is a tool for creatives and AI enthusiasts that lets you gather high-quality text-to-image prompts and test how different generative AI models respond to the same prompts. It’s made for comparing model outputs side by side, so you can see strengths and weaknesses, styles, fidelity, and prompt adherence across models without doing the prompt-engineering yourself every time.
Prompt Llama
Prompt Llama is a tool for creatives and AI enthusiasts that lets you gather high-quality text-to-image prompts and test how different generative AI models respond to the same prompts. It’s made for comparing model outputs side by side, so you can see strengths and weaknesses, styles, fidelity, and prompt adherence across models without doing the prompt-engineering yourself every time.
Prompt Llama
Prompt Llama is a tool for creatives and AI enthusiasts that lets you gather high-quality text-to-image prompts and test how different generative AI models respond to the same prompts. It’s made for comparing model outputs side by side, so you can see strengths and weaknesses, styles, fidelity, and prompt adherence across models without doing the prompt-engineering yourself every time.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
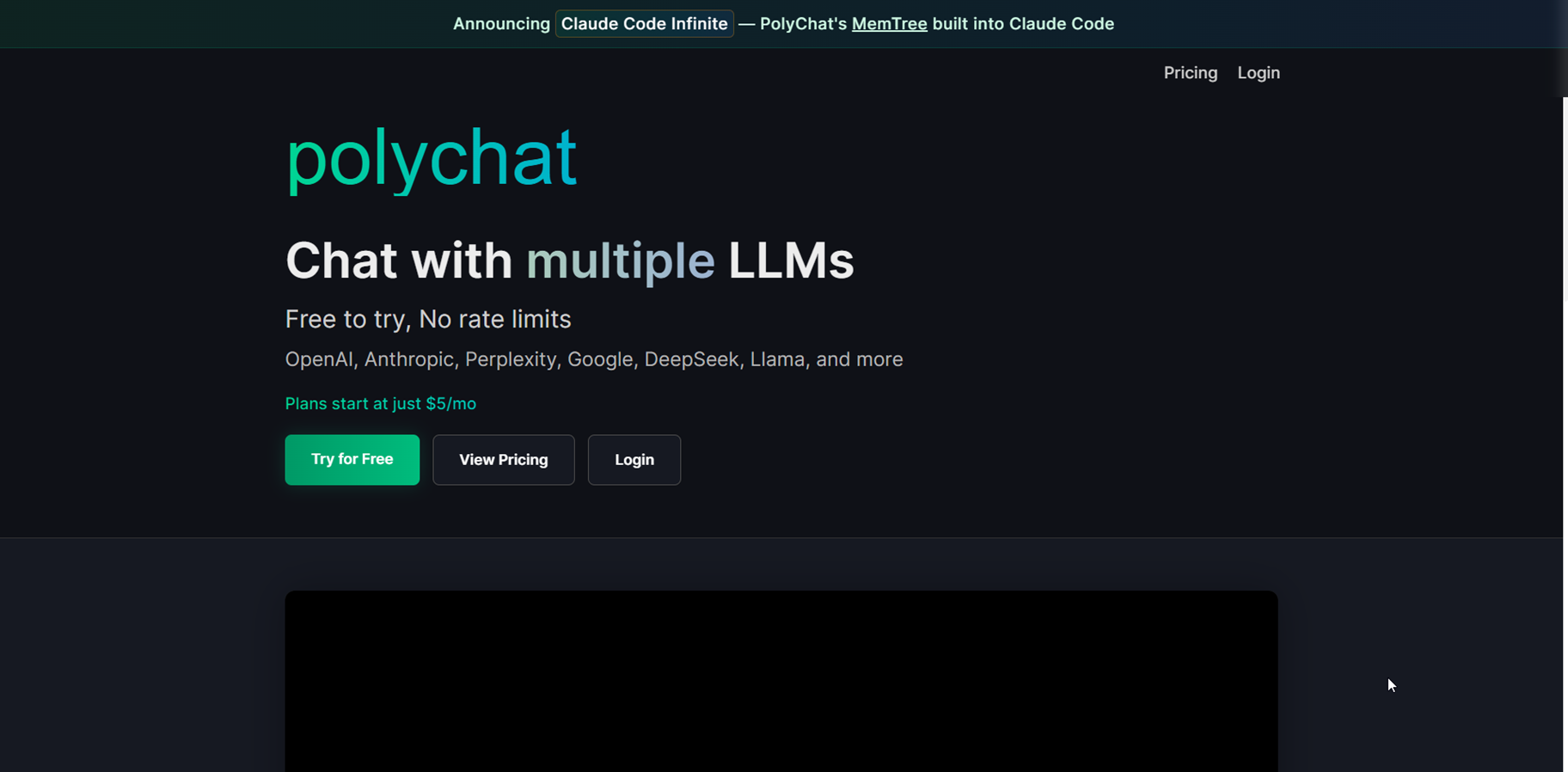

polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai