
- Researchers & Developers: For advanced image understanding, chart interpretation, document analysis, and multimodal reasoning.
- Enterprise Teams: Ideal for RAG pipelines, document automation, analytics dashboards, and image-based chat assistants.
- Educational Users: Solve visual math problems, parse diagrams, or orbit large PDF/image datasets.
- Creators & Designers: Caption images, analyze visual styles, or generate insights from visual data.
- API Users & Cloud Engineers: Accessible via “`pixtral-large-latest`” API or downloadable for self-hosted deployment under Mistral Research or Commercial licenses.
How to Use Pixtral Large?
- Via API or Chat: Call it with `pixtral-large-latest` in Mistral’s API or through integrated chat platforms.
- Self-Host: Download weights under Mistral Research or Commercial license via Hugging Face.
- Submit Mixed Inputs: Send text plus images (base64/URL); the model supports 128K tokens for expansive multimodal context.
- Handle Vision Tasks: OCR, ChartQA, DocVQA, VQAv2, MathVista, and multimodal instructions with high accuracy.
- Deploy in Cloud: Available via Amazon Bedrock in multiple regions.
- Multimodal Decoder Setup: Merges strong text performance with robust vision understanding using a 1B encoder.
- Huge Context: 128K tokens processing long docs and dozens of images at once.
- Open Weights & Dual Licensing: Research access via MRL and commercial via dedicated license.
- Cloud-Ready: Managed, serverless API available on AWS Bedrock with global region support.
- SOTA performance across multimodal vision benchmarks
- Massive 128K-token capacity for expansive context
- Single model for text and image understanding
- Available under research/commercial licenses
- Fully integrated via API and self-host options
- OCR in non-European languages remains limited
- Requires substantial compute (200+ GB weights, powerful GPU)
- Commercial licensing may restrict local deployment use cases
Chat
0/$14.99/$24.99 per month
Free - $0
Pro - $14.99 per month
Enterprise - $24.99 per month
API
$2/$6 per 1M token
$6 per 1M output tokens
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.

GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.

OpenAI GPT Image 1
GPT-Image-1 is OpenAI's state-of-the-art vision model designed to understand and interpret images with human-like perception. It enables developers and businesses to analyze, summarize, and extract detailed insights from images using natural language. Whether you're building AI agents, accessibility tools, or image-driven workflows, GPT-Image-1 brings powerful multimodal capabilities into your applications with impressive accuracy. Optimized for use via API, it can handle diverse image types—charts, screenshots, photographs, documents, and more—making it one of the most versatile models in OpenAI’s portfolio.
OpenAI GPT Image 1
GPT-Image-1 is OpenAI's state-of-the-art vision model designed to understand and interpret images with human-like perception. It enables developers and businesses to analyze, summarize, and extract detailed insights from images using natural language. Whether you're building AI agents, accessibility tools, or image-driven workflows, GPT-Image-1 brings powerful multimodal capabilities into your applications with impressive accuracy. Optimized for use via API, it can handle diverse image types—charts, screenshots, photographs, documents, and more—making it one of the most versatile models in OpenAI’s portfolio.
OpenAI GPT Image 1
GPT-Image-1 is OpenAI's state-of-the-art vision model designed to understand and interpret images with human-like perception. It enables developers and businesses to analyze, summarize, and extract detailed insights from images using natural language. Whether you're building AI agents, accessibility tools, or image-driven workflows, GPT-Image-1 brings powerful multimodal capabilities into your applications with impressive accuracy. Optimized for use via API, it can handle diverse image types—charts, screenshots, photographs, documents, and more—making it one of the most versatile models in OpenAI’s portfolio.
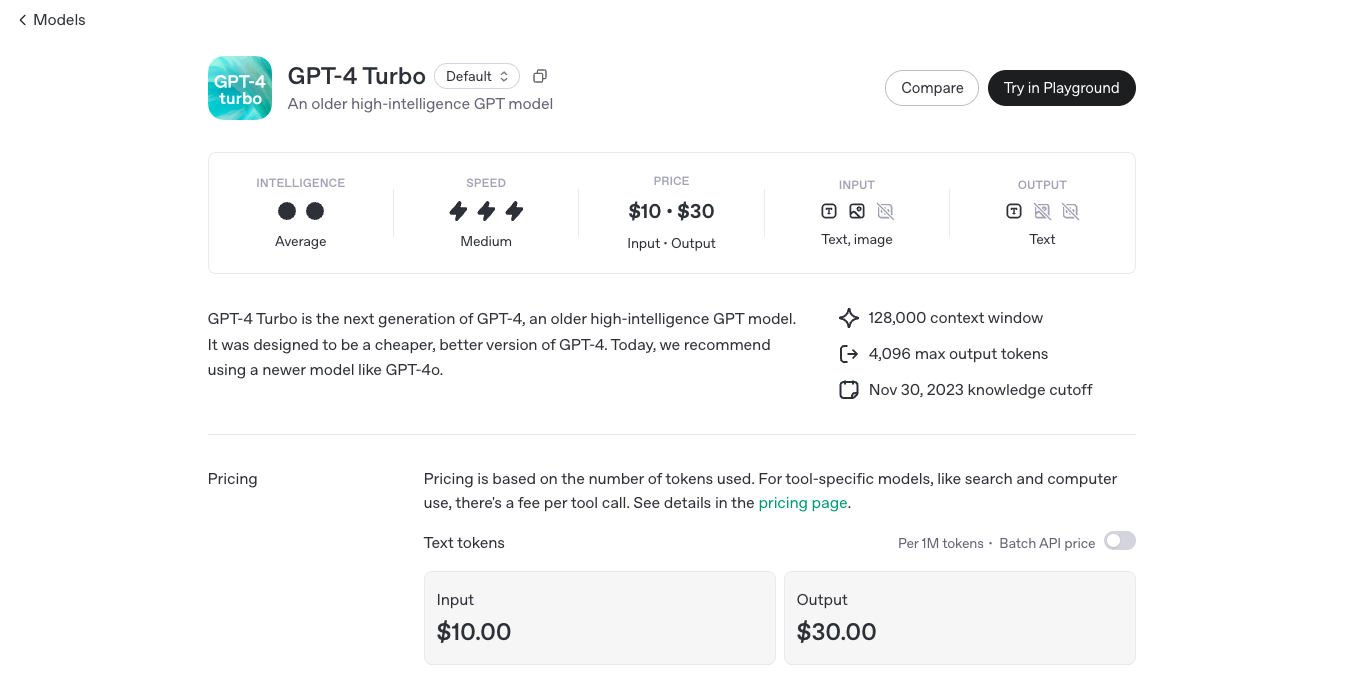
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

grok-2-vision
Grok 2 Vision (also known as Grok‑2‑Vision‑1212 or grok‑2‑vision‑latest) is xAI’s multimodal variant of Grok 2, designed specifically for advanced image understanding and generation. Launched in December 2024, it supports joint text+image inputs up to 32,768 tokens, excelling in visual math reasoning (MathVista), document question answering (DocVQA), object recognition, and style analysis—while also offering photorealistic image creation via the FLUX.1 model.
grok-2-vision
Grok 2 Vision (also known as Grok‑2‑Vision‑1212 or grok‑2‑vision‑latest) is xAI’s multimodal variant of Grok 2, designed specifically for advanced image understanding and generation. Launched in December 2024, it supports joint text+image inputs up to 32,768 tokens, excelling in visual math reasoning (MathVista), document question answering (DocVQA), object recognition, and style analysis—while also offering photorealistic image creation via the FLUX.1 model.
grok-2-vision
Grok 2 Vision (also known as Grok‑2‑Vision‑1212 or grok‑2‑vision‑latest) is xAI’s multimodal variant of Grok 2, designed specifically for advanced image understanding and generation. Launched in December 2024, it supports joint text+image inputs up to 32,768 tokens, excelling in visual math reasoning (MathVista), document question answering (DocVQA), object recognition, and style analysis—while also offering photorealistic image creation via the FLUX.1 model.
Grok 2 Vision is xAI’s advanced vision-enabled variant of Grok 2, launched in December 2024. It supports joint text + image inputs with a 32K-token context window, combining image understanding, document QA, visual math reasoning (e.g., MathVista, DocVQA), and photorealistic image generation via FLUX.1 (later complemented by Aurora). It scores state-of-the-art on multimodal tasks.
Grok 2 Vision is xAI’s advanced vision-enabled variant of Grok 2, launched in December 2024. It supports joint text + image inputs with a 32K-token context window, combining image understanding, document QA, visual math reasoning (e.g., MathVista, DocVQA), and photorealistic image generation via FLUX.1 (later complemented by Aurora). It scores state-of-the-art on multimodal tasks.
Grok 2 Vision is xAI’s advanced vision-enabled variant of Grok 2, launched in December 2024. It supports joint text + image inputs with a 32K-token context window, combining image understanding, document QA, visual math reasoning (e.g., MathVista, DocVQA), and photorealistic image generation via FLUX.1 (later complemented by Aurora). It scores state-of-the-art on multimodal tasks.

grok-2-vision-1212
Grok 2 Vision – 1212 is a December 2024 release of xAI’s multimodal large language model, fine-tuned specifically for image understanding and generation. It supports combined text and image inputs (up to 32,768 tokens) and excels in document question answering, visual math reasoning, object recognition, and photorealistic image generation powered by FLUX.1. It also supports API deployment for developers and enterprises.
grok-2-vision-1212
Grok 2 Vision – 1212 is a December 2024 release of xAI’s multimodal large language model, fine-tuned specifically for image understanding and generation. It supports combined text and image inputs (up to 32,768 tokens) and excels in document question answering, visual math reasoning, object recognition, and photorealistic image generation powered by FLUX.1. It also supports API deployment for developers and enterprises.
grok-2-vision-1212
Grok 2 Vision – 1212 is a December 2024 release of xAI’s multimodal large language model, fine-tuned specifically for image understanding and generation. It supports combined text and image inputs (up to 32,768 tokens) and excels in document question answering, visual math reasoning, object recognition, and photorealistic image generation powered by FLUX.1. It also supports API deployment for developers and enterprises.

Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Mistral Document AI is Mistral AI’s enterprise-grade document processing platform, launched May 2025. It combines state-of-the-art OCR model mistral-ocr-latest with structured data extraction, document Q&A, and natural language understanding—delivering 99%+ OCR accuracy, support for over 40 languages and complex layouts (tables, forms, handwriting), and blazing-fast processing at up to 2,000 pages/min per GPU.
Mistral Document AI is Mistral AI’s enterprise-grade document processing platform, launched May 2025. It combines state-of-the-art OCR model mistral-ocr-latest with structured data extraction, document Q&A, and natural language understanding—delivering 99%+ OCR accuracy, support for over 40 languages and complex layouts (tables, forms, handwriting), and blazing-fast processing at up to 2,000 pages/min per GPU.
Mistral Document AI is Mistral AI’s enterprise-grade document processing platform, launched May 2025. It combines state-of-the-art OCR model mistral-ocr-latest with structured data extraction, document Q&A, and natural language understanding—delivering 99%+ OCR accuracy, support for over 40 languages and complex layouts (tables, forms, handwriting), and blazing-fast processing at up to 2,000 pages/min per GPU.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai