
- Developers & Engineers: Embed visual understanding into chatbots, assistants, or document pipelines.
- Researchers & Analysts: Analyze charts, PDFs, screenshots, or scientific figures with multimodal input.
- Content & Data Teams: Automate captioning, data extraction, and QA on images or mixed documents.
- Product Designers: Prototype apps with image-and-text interaction via Gradio or custom APIs.
- Open-Source Enthusiasts: Run models locally (1.3B or 7B) under MIT license on consumer hardware.
How to Use DeepSeek VL?
- Download the Model: Available on Hugging Face as `DeepSeek-VL-1.3B-base/chat` and `...-7B-base/chat`.
- Install & Initialize: Use Python (≥3.8), PyTorch/Transformers, and vision-text processors for inference.
- Submit Mixed Inputs: Provide a high-res image along with a text prompt (e.g., “Describe this chart.”).
- Choose Variant: Use `-chat` for conversational Q&A; `-base` for raw inference.
- Deploy in Projects: Integrate into apps via Hugging Face pipelines or local server for inference.
- Hybrid Vision Encoder: Efficiently processes high-resolution images (up to 1024×1024) with cross-modal adaptors.
- Real-World Task Training: Instruction-tuned on diverse formats—webpages, diagrams, formulas, charts, and PDFs.
- Open-Source & Versatile: Available under MIT; supports base and chat versions in two sizes.
- Strong Benchmarking: Achieves state-of-the-art or competitive performance across VL benchmarks compared to models of similar size.
- Processes rich, high-resolution visual inputs efficiently
- Great performance on real-world image-text tasks
- Dual base/chat variants for flexible usage
- Open-source under MIT license
- Easy to integrate via Hugging Face tools
- High VRAM requirement for 7B variant (≥24 GB)
- Lags behind newer VL2 models in advanced tasks
- Limited support for image generation or editing
Custom
Custom
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
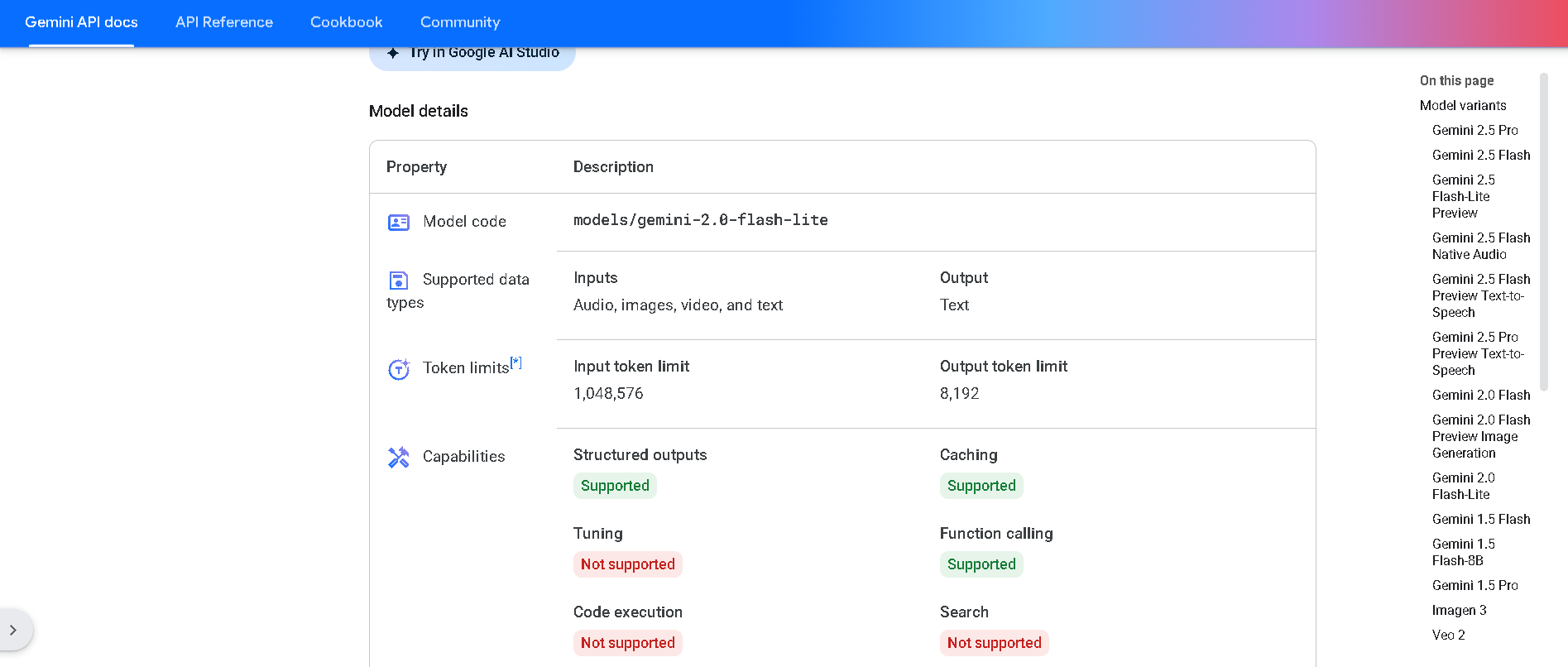
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
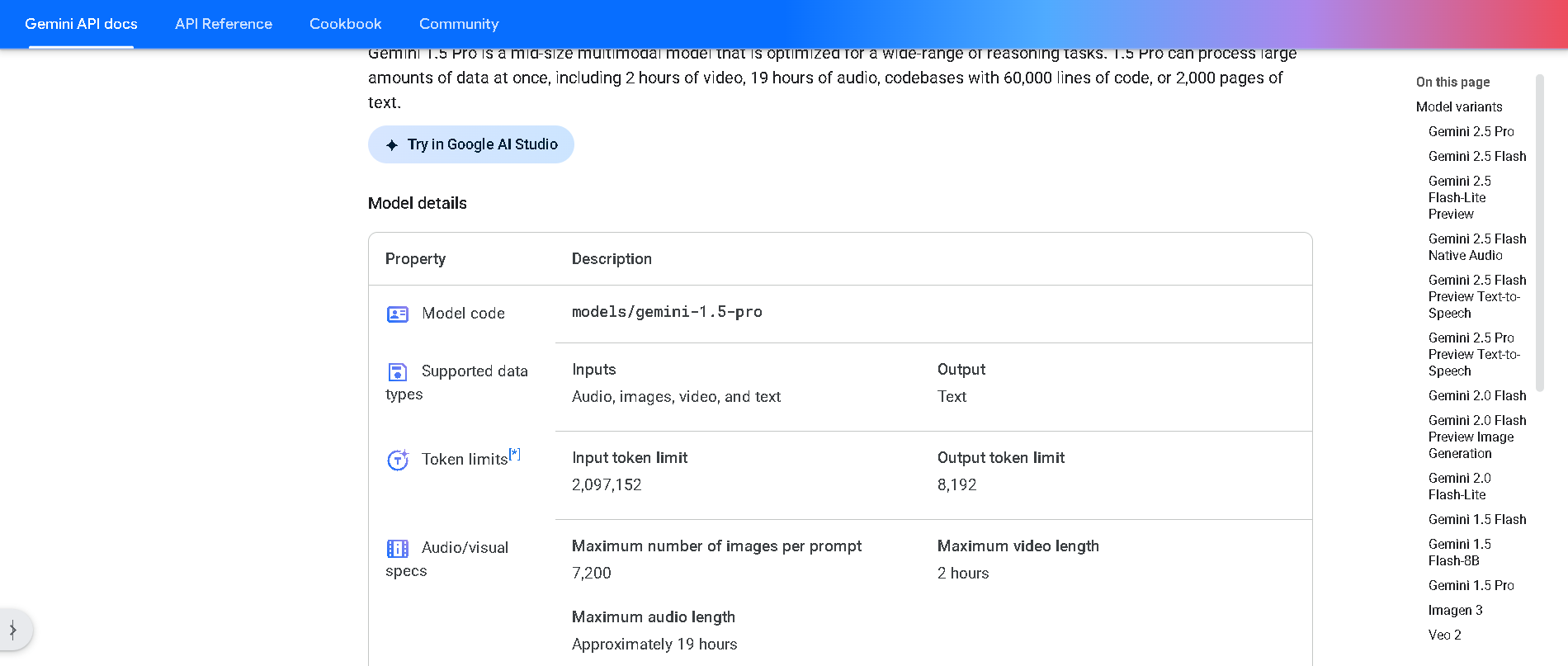

Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.

Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.

DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.
DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.
DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.

DeepSeek-Math
DeepSeek Math (also called DeepSeekMath) is DeepSeek’s specialized, open-source, math-centric large language model. Built on DeepSeek‑Coder‑Base‑7B and further pre-trained on ~500B tokens—including 120B from its own math-focused corpus—it excels at competition-level reasoning, achieving 51.7 % on the MATH benchmark and ~64.2 % on GSM8K, rivaling models like GPT‑4 and Gemini‑Ultra—all without external toolkits or voting methods .
DeepSeek-Math
DeepSeek Math (also called DeepSeekMath) is DeepSeek’s specialized, open-source, math-centric large language model. Built on DeepSeek‑Coder‑Base‑7B and further pre-trained on ~500B tokens—including 120B from its own math-focused corpus—it excels at competition-level reasoning, achieving 51.7 % on the MATH benchmark and ~64.2 % on GSM8K, rivaling models like GPT‑4 and Gemini‑Ultra—all without external toolkits or voting methods .
DeepSeek-Math
DeepSeek Math (also called DeepSeekMath) is DeepSeek’s specialized, open-source, math-centric large language model. Built on DeepSeek‑Coder‑Base‑7B and further pre-trained on ~500B tokens—including 120B from its own math-focused corpus—it excels at competition-level reasoning, achieving 51.7 % on the MATH benchmark and ~64.2 % on GSM8K, rivaling models like GPT‑4 and Gemini‑Ultra—all without external toolkits or voting methods .

grok-2-vision
Grok 2 Vision (also known as Grok‑2‑Vision‑1212 or grok‑2‑vision‑latest) is xAI’s multimodal variant of Grok 2, designed specifically for advanced image understanding and generation. Launched in December 2024, it supports joint text+image inputs up to 32,768 tokens, excelling in visual math reasoning (MathVista), document question answering (DocVQA), object recognition, and style analysis—while also offering photorealistic image creation via the FLUX.1 model.
grok-2-vision
Grok 2 Vision (also known as Grok‑2‑Vision‑1212 or grok‑2‑vision‑latest) is xAI’s multimodal variant of Grok 2, designed specifically for advanced image understanding and generation. Launched in December 2024, it supports joint text+image inputs up to 32,768 tokens, excelling in visual math reasoning (MathVista), document question answering (DocVQA), object recognition, and style analysis—while also offering photorealistic image creation via the FLUX.1 model.
grok-2-vision
Grok 2 Vision (also known as Grok‑2‑Vision‑1212 or grok‑2‑vision‑latest) is xAI’s multimodal variant of Grok 2, designed specifically for advanced image understanding and generation. Launched in December 2024, it supports joint text+image inputs up to 32,768 tokens, excelling in visual math reasoning (MathVista), document question answering (DocVQA), object recognition, and style analysis—while also offering photorealistic image creation via the FLUX.1 model.
Grok 2 Vision is xAI’s advanced vision-enabled variant of Grok 2, launched in December 2024. It supports joint text + image inputs with a 32K-token context window, combining image understanding, document QA, visual math reasoning (e.g., MathVista, DocVQA), and photorealistic image generation via FLUX.1 (later complemented by Aurora). It scores state-of-the-art on multimodal tasks.
Grok 2 Vision is xAI’s advanced vision-enabled variant of Grok 2, launched in December 2024. It supports joint text + image inputs with a 32K-token context window, combining image understanding, document QA, visual math reasoning (e.g., MathVista, DocVQA), and photorealistic image generation via FLUX.1 (later complemented by Aurora). It scores state-of-the-art on multimodal tasks.
Grok 2 Vision is xAI’s advanced vision-enabled variant of Grok 2, launched in December 2024. It supports joint text + image inputs with a 32K-token context window, combining image understanding, document QA, visual math reasoning (e.g., MathVista, DocVQA), and photorealistic image generation via FLUX.1 (later complemented by Aurora). It scores state-of-the-art on multimodal tasks.

DeepSeek-R1-Zero
DeepSeek R1 Zero is an open-source large language model introduced in January 2025 by DeepSeek AI. It is a reinforcement learning–only version of DeepSeek R1, trained without supervised fine-tuning. With 671B total parameters (37B active) and a 128K-token context window, it demonstrates strong chain-of-thought reasoning, self-verification, and reflection.
DeepSeek-R1-Zero
DeepSeek R1 Zero is an open-source large language model introduced in January 2025 by DeepSeek AI. It is a reinforcement learning–only version of DeepSeek R1, trained without supervised fine-tuning. With 671B total parameters (37B active) and a 128K-token context window, it demonstrates strong chain-of-thought reasoning, self-verification, and reflection.
DeepSeek-R1-Zero
DeepSeek R1 Zero is an open-source large language model introduced in January 2025 by DeepSeek AI. It is a reinforcement learning–only version of DeepSeek R1, trained without supervised fine-tuning. With 671B total parameters (37B active) and a 128K-token context window, it demonstrates strong chain-of-thought reasoning, self-verification, and reflection.

DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.

Pixtral Large is Mistral AI’s latest multimodal powerhouse, launched November 18, 2024. Built atop the 123B‑parameter Mistral Large 2, it features a 124B‑parameter multimodal decoder paired with a 1B‑parameter vision encoder, and supports a massive 128K‑token context window—enabling it to process up to 30 high-resolution images or ~300-page documents.
Pixtral Large is Mistral AI’s latest multimodal powerhouse, launched November 18, 2024. Built atop the 123B‑parameter Mistral Large 2, it features a 124B‑parameter multimodal decoder paired with a 1B‑parameter vision encoder, and supports a massive 128K‑token context window—enabling it to process up to 30 high-resolution images or ~300-page documents.
Pixtral Large is Mistral AI’s latest multimodal powerhouse, launched November 18, 2024. Built atop the 123B‑parameter Mistral Large 2, it features a 124B‑parameter multimodal decoder paired with a 1B‑parameter vision encoder, and supports a massive 128K‑token context window—enabling it to process up to 30 high-resolution images or ~300-page documents.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai