
- Developers & Engineers: Analyze large codebases, run data pipelines, build multimodal apps with long-context logic.
- Researchers & Analysts: Summarize big reports, process hours of video/audio, extract insights from large documents.
- Enterprise App Builders: Integrate with Vertex AI and Gemini API for scalable, multimodal intelligence.
- Content & Media Teams: Generate summaries, transcriptions, translations, and visuals at scale.
- AI Students & Enthusiasts: Experiment with long-context reasoning, multimodal inputs, and in-context learning without full model size.
How to Use Gemini 1.5 Pro?
- Access the Model: Available in private preview via Google AI Studio and Vertex AI under the ID `gemini-1.5-pro`.
- Submit Multimodal Inputs: Upload text, code, images, audio, or video—up to 1 million tokens.
- Leverage Long Context: Analyze large files like PDFs, code repos, or hour-long media content in one prompt.
- Enable In-Context Learning: Teach the model new tasks mid-session via example inputs—no tuning required.
- Use Enterprise API Features: Supports grounding (Google Search), JSON mode, function calling, caching, and adjustable safety.
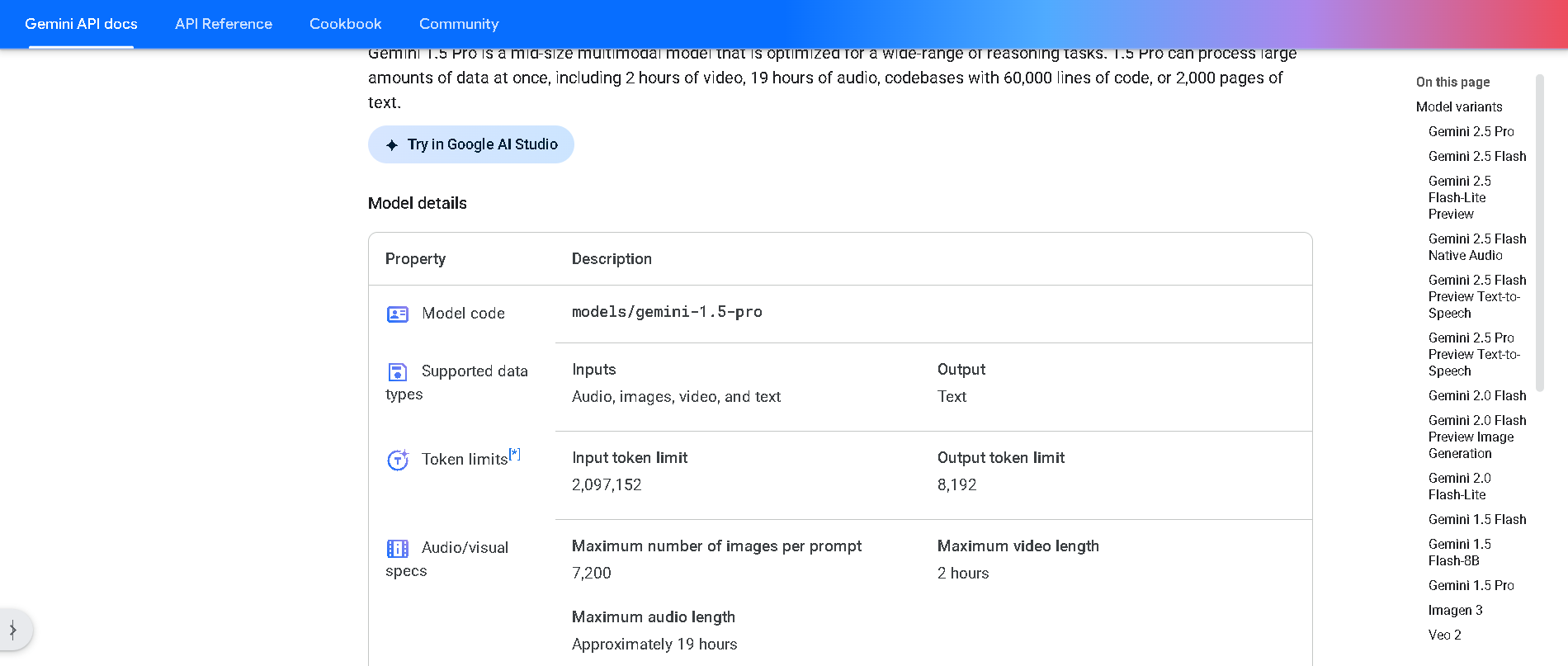
- 1 Million Token Context: Processes up to 700K words, codebases, videos, or datasets in one prompt.
- Mixture-of-Experts (MoE): Intelligent routing boosts efficiency and performance relative to dense models.
- Robust Multimodality: Handles text, image, audio, video, and code in a unified model.
- In-Context Learning: Adapts to new tasks via prompt examples (e.g., low-resource translation) without retraining.
- Leading Benchmark Results: Outperforms Gemini 1.0 Ultra on 87% of benchmark tasks and shows strong downstream gains.
- Support for massive inputs—text, code, audio, video—within 1 M tokens
- Balanced efficiency via MoE architecture
- Strong performance across reasoning, multimodal, and coding tasks
- In-context learning enables flexible task adaptation
- Enterprise-ready with grounding, function-calling, and safety controls
- Still in preview, not yet generally available
- Performance may dip beyond ~200K tokens—preview builds may lag
- Depth over speed—longest-context use cases may incur latency
Free
$ 0.00
API
Custom
- Input Price: 1) $1.25, prompts <= 128k tokens 2) $2.5, prompts > 128k tokens
- Output Price: 1) $5, prompts <= 128k tokens 2) $10, prompts > 128k tokens
- Context Caching Price: 1) $0.3125, prompts <= 128k tokens 2) $0.625, prompts > 128k tokens
- Context caching storage: $4.50 per hour
- Tuning Price: Not available
- Grounding with Google search: $35 / 1K grounding requests
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
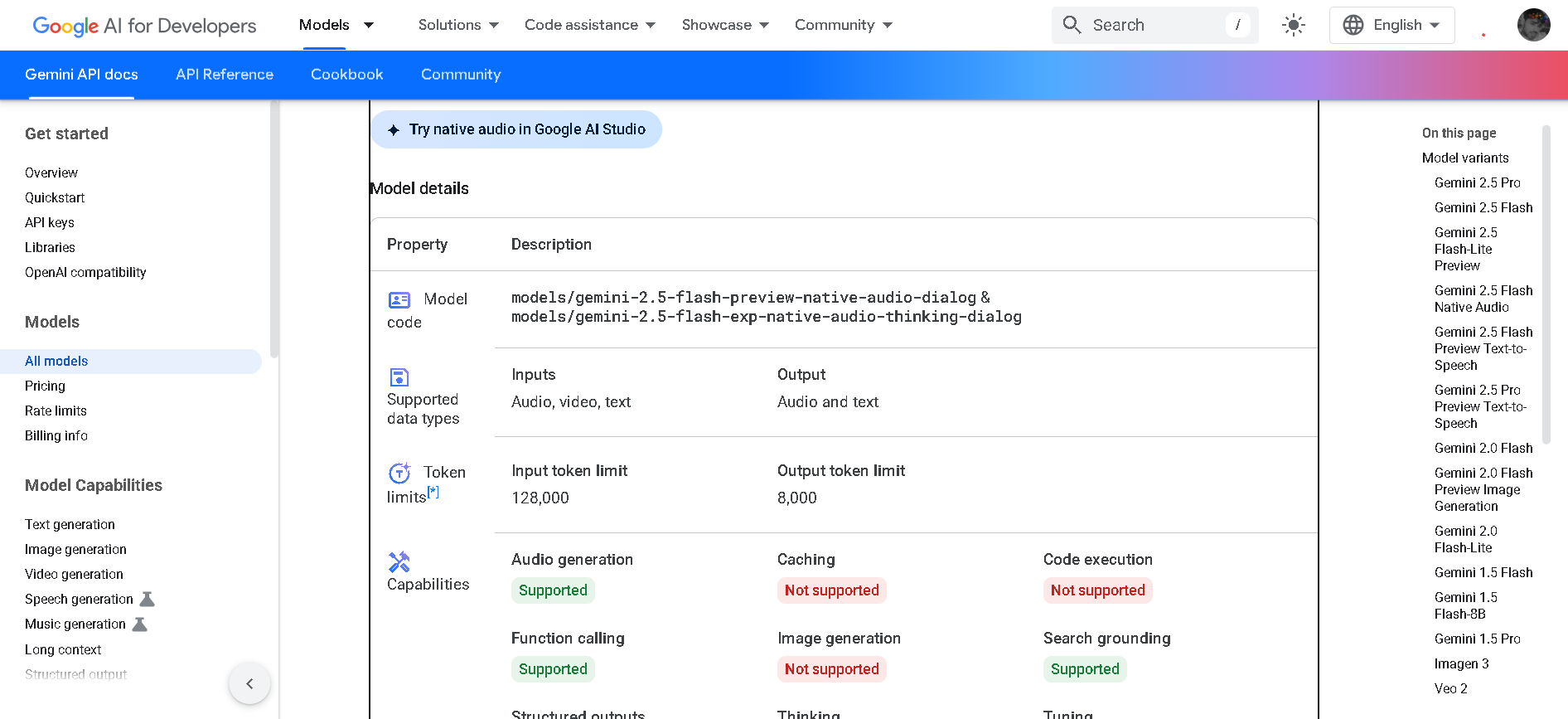
Gemini 2.5 Flash Native Audio is a preview variant of Google DeepMind’s fast, reasoning-enabled “Flash” model, enhanced to support natural, expressive audio dialogue. It allows real-time back-and-forth voice conversation—responding to tone, background noise, affect, and multilingual input—while maintaining its high-speed, multimodal, hybrid-reasoning capabilities.
Gemini 2.5 Flash Native Audio is a preview variant of Google DeepMind’s fast, reasoning-enabled “Flash” model, enhanced to support natural, expressive audio dialogue. It allows real-time back-and-forth voice conversation—responding to tone, background noise, affect, and multilingual input—while maintaining its high-speed, multimodal, hybrid-reasoning capabilities.
Gemini 2.5 Flash Native Audio is a preview variant of Google DeepMind’s fast, reasoning-enabled “Flash” model, enhanced to support natural, expressive audio dialogue. It allows real-time back-and-forth voice conversation—responding to tone, background noise, affect, and multilingual input—while maintaining its high-speed, multimodal, hybrid-reasoning capabilities.
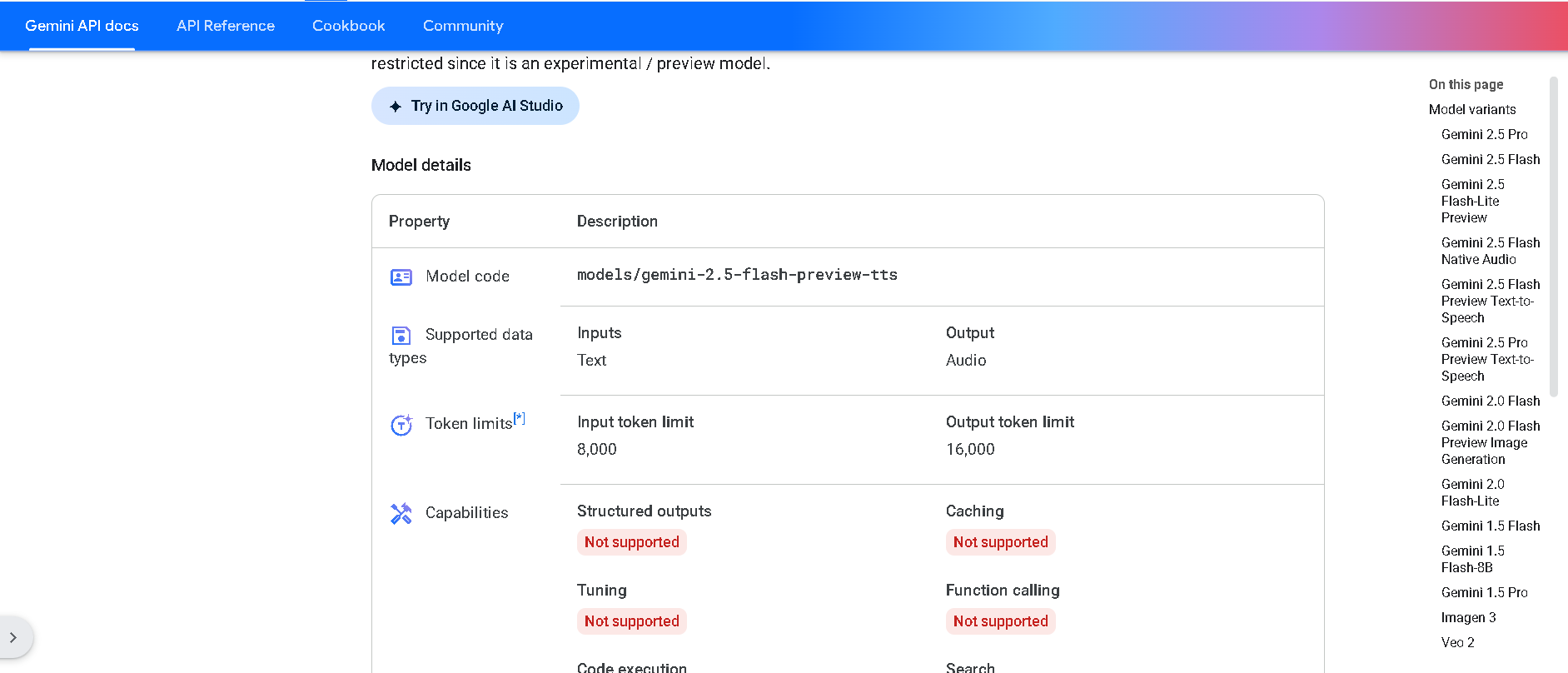
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
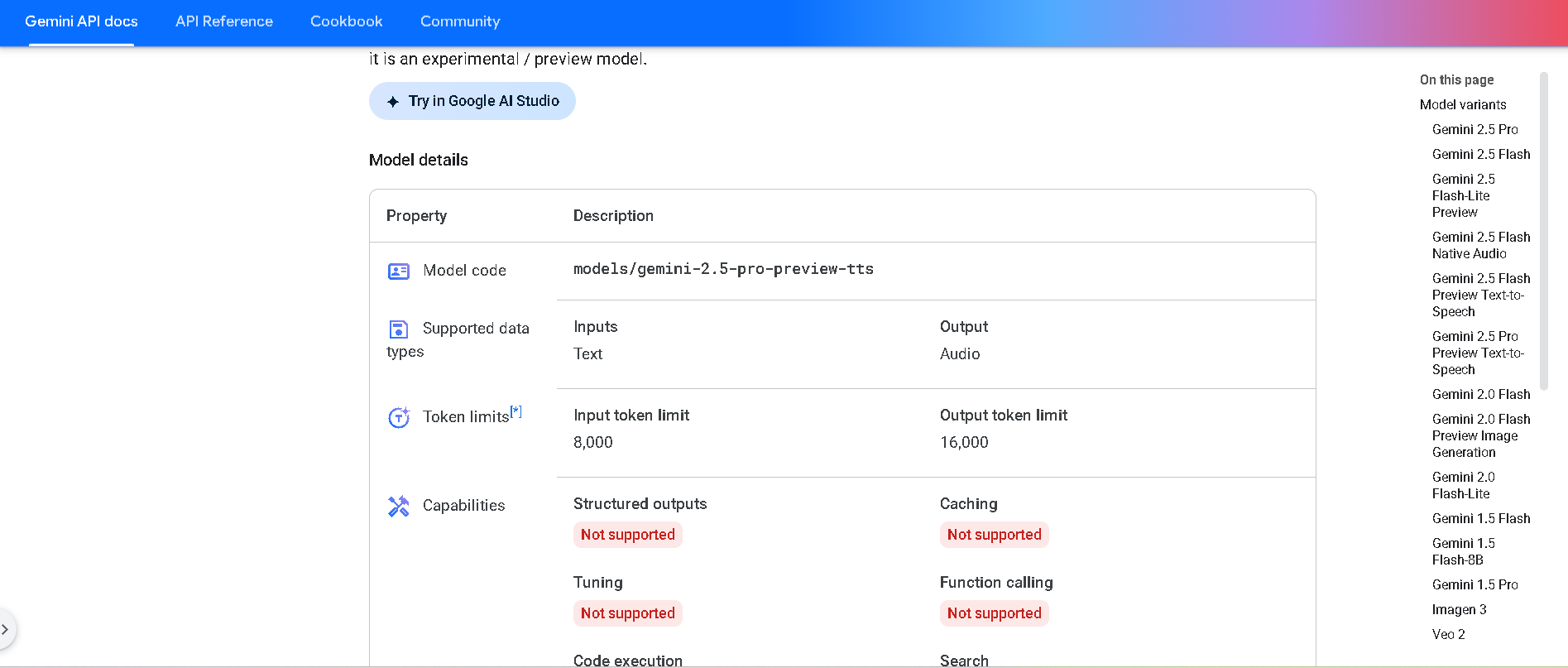
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
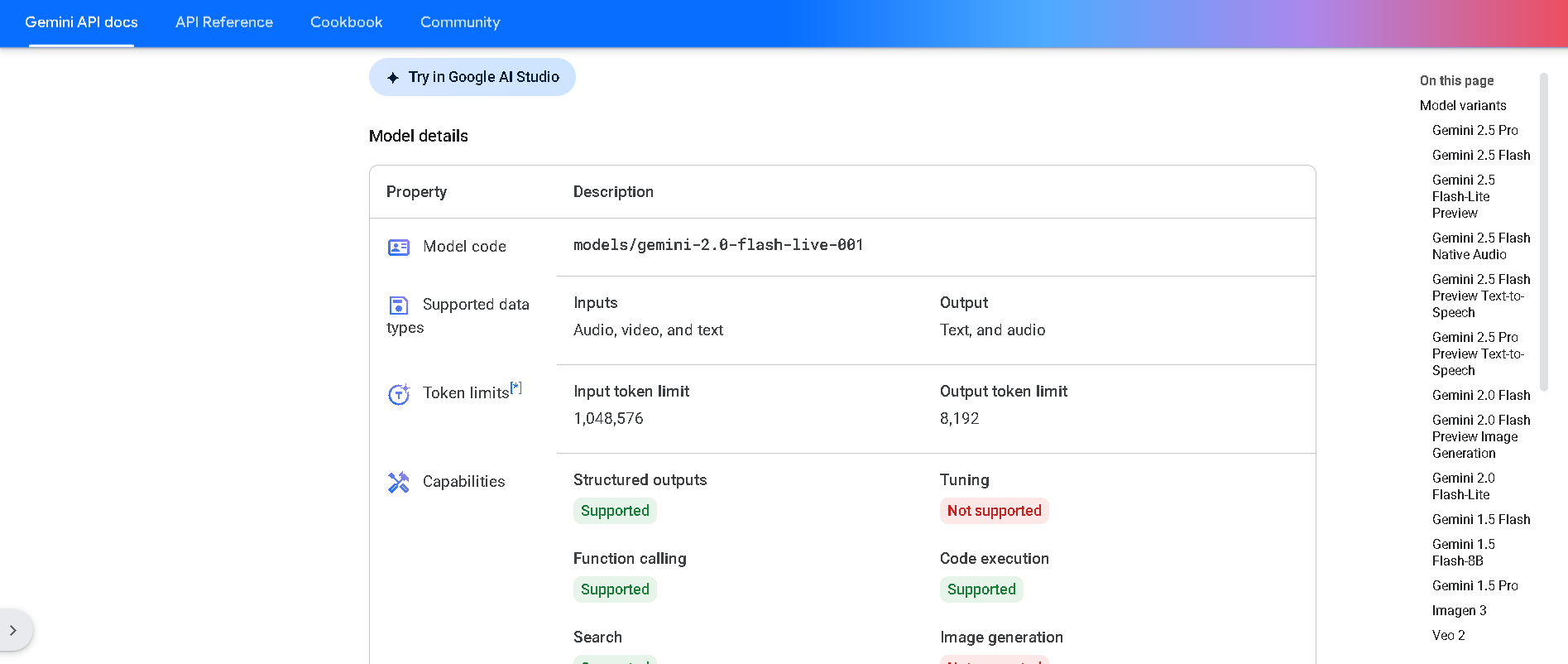
Gemini 2.0 Flash Live is Google DeepMind’s real-time, multimodal chatbot variant powered by the Live API. It supports simultaneous streaming of voice, video, and text inputs, and responds in both spoken audio and text, enabling rich, bidirectional live interactions with low latency and tool integration.
Gemini 2.0 Flash Live is Google DeepMind’s real-time, multimodal chatbot variant powered by the Live API. It supports simultaneous streaming of voice, video, and text inputs, and responds in both spoken audio and text, enabling rich, bidirectional live interactions with low latency and tool integration.
Gemini 2.0 Flash Live is Google DeepMind’s real-time, multimodal chatbot variant powered by the Live API. It supports simultaneous streaming of voice, video, and text inputs, and responds in both spoken audio and text, enabling rich, bidirectional live interactions with low latency and tool integration.

Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.

DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.
DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.
DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
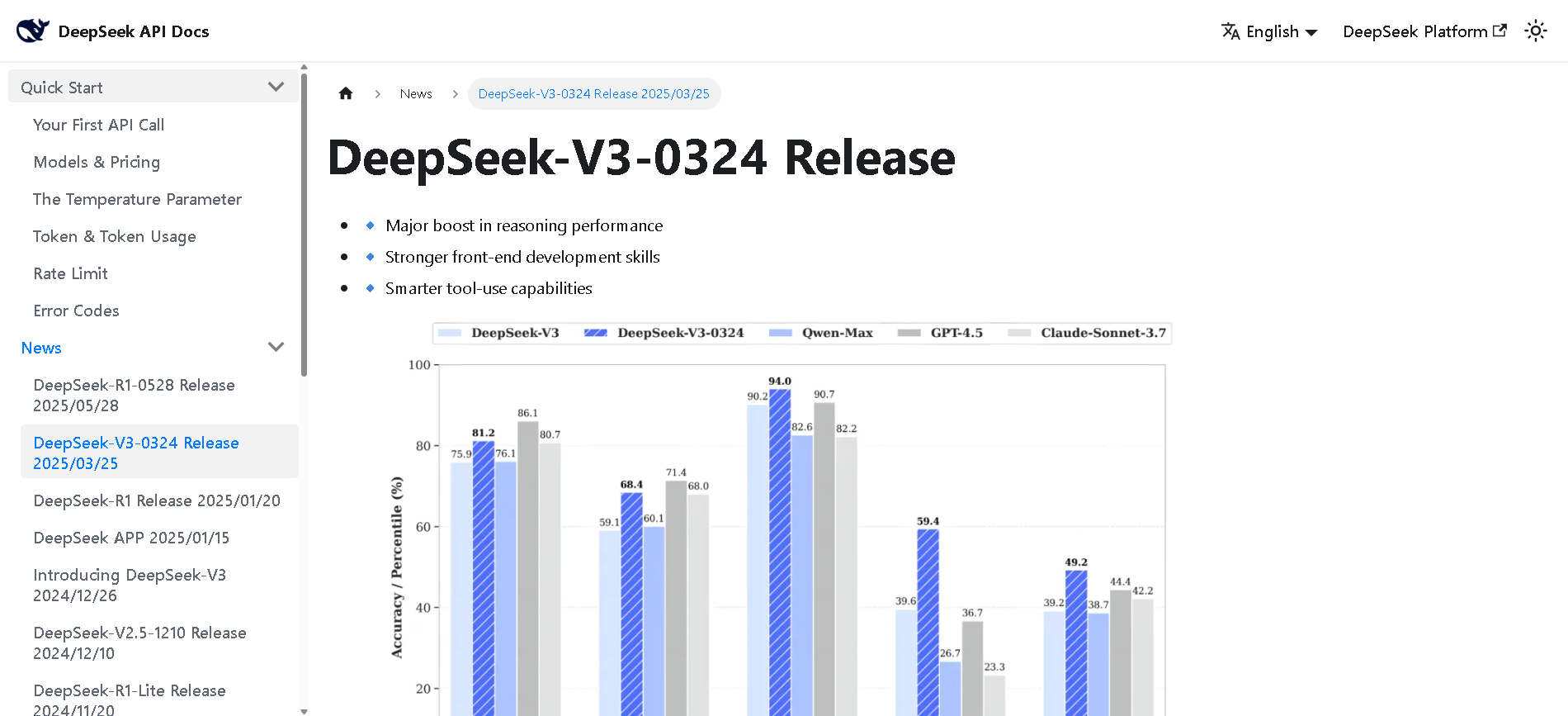
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.

Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.

LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai