
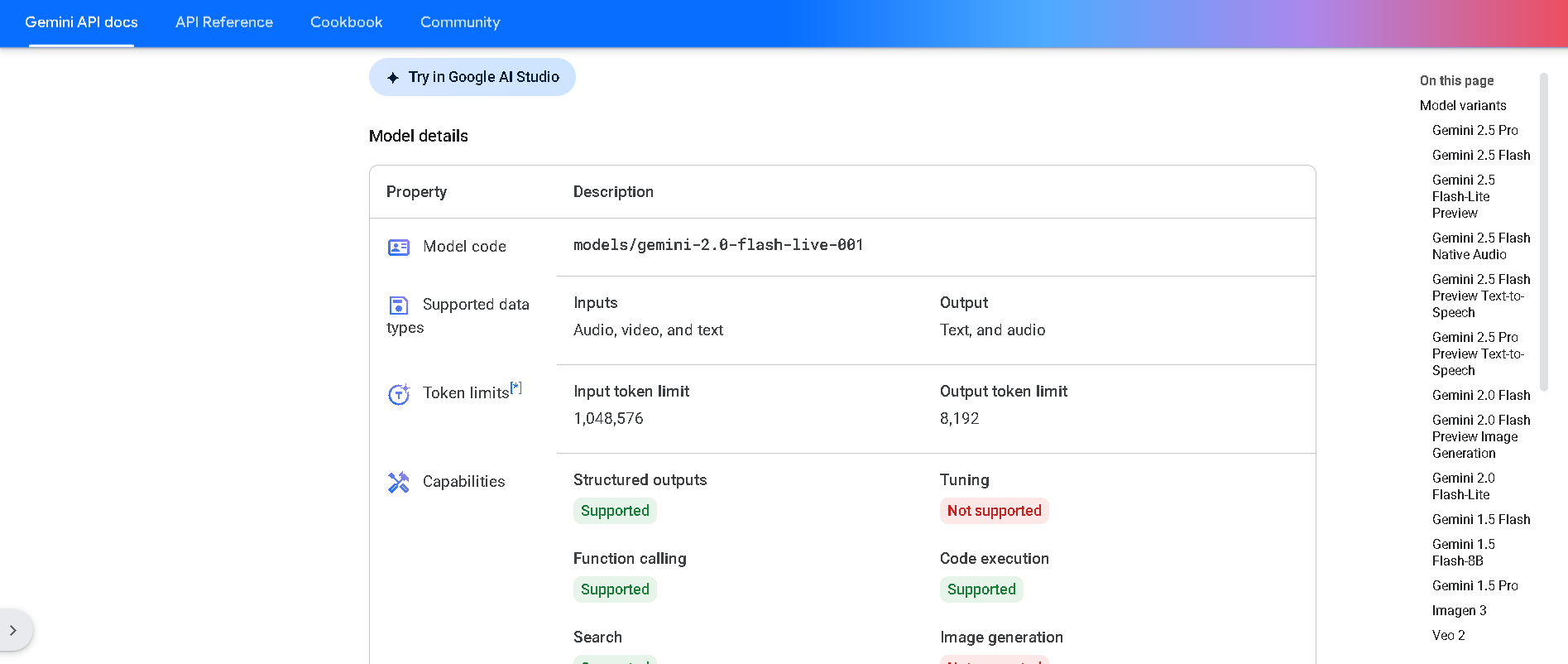
- Voice & Video App Developers: Build immersive live agents with microphone and camera interaction for customers or users.
- Call Center & Field Teams: Use live visual and voice intelligence to support frontline workers in troubleshooting or diagnostics.
- Productivity & Assistive Tech: Enable real-time multimodal assistance like reading screens or narrating video scenes.
- SaaS & Enterprise Tools: Integrate responsive live agents into apps via the Live API with session control and function-calling.
- Educators & Accessibility Teams: Craft interactive teaching tools or assistive interfaces that perceive and speak in real time.
How to Use Gemini 2.0 Flash Live?
- Access via Live API: Connect to the Live API Preview model (`gemini-2.0-flash-live`) via Vertex AI or Live API endpoints.
- Stream Inputs: Send live audio (microphone), video (camera or screen), and text in a continuous session.
- Receive Rich Outputs: Model responds via text and streaming audio, with support for function calling and real-time interruptions.
- Manage Sessions: Use session tokens for secure, long-running talks with voice activity detection, tool integration, and message control.
- Scale Deployment: Use SDKs like Firebase AI Logic or Vertex AI for real-time, server- or client-driven connections, and monitor for latency and usage.
- True Multimodal Live Chat: Streams voice, video, and text together, enabling natural live interaction.
- Low-Latency Voice and Video Response: Designed for sub-second voice and text responses during live sessions.
- Integrates Tools and Agents: Can call functions, access search, execute code, and use structured outputs during flow.
- Session Management & Interactivity: Voice activity detection lets users interrupt or pause the bot as needed in real time.
- Suitable for Enterprise-grade Use: SDK and API support from Google Cloud, with security and scalability via Vertex AI.
- True voice and video-enabled live chat experience
- Immediate, interactive responses with low latency
- Tool-enabled and function-calling capable
- Session-aware UI, including VAD and stream control
- Ready for enterprise apps via official SDKs and APIs
- Currently in preview—availability and stability may vary
- Requires more integration effort than basic chat models
- Live multimodal streaming requires robust infrastructure
Free
$ 0.00
API
Custom
Output: $1.50 (text), $8.50 (audio)
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI’s Real-Time API is a game-changing advancement in AI interaction, enabling developers to build apps that respond instantly—literally in milliseconds—to user inputs. It drastically reduces the response latency of OpenAI’s GPT-4o model to as low as 100 milliseconds, unlocking a whole new world of AI-powered experiences that feel more human, responsive, and conversational in real time. Whether you're building a live voice assistant, a responsive chatbot, or interactive multiplayer tools powered by AI, this API puts real in real-time AI.
OpenAI’s Real-Time API is a game-changing advancement in AI interaction, enabling developers to build apps that respond instantly—literally in milliseconds—to user inputs. It drastically reduces the response latency of OpenAI’s GPT-4o model to as low as 100 milliseconds, unlocking a whole new world of AI-powered experiences that feel more human, responsive, and conversational in real time. Whether you're building a live voice assistant, a responsive chatbot, or interactive multiplayer tools powered by AI, this API puts real in real-time AI.
OpenAI’s Real-Time API is a game-changing advancement in AI interaction, enabling developers to build apps that respond instantly—literally in milliseconds—to user inputs. It drastically reduces the response latency of OpenAI’s GPT-4o model to as low as 100 milliseconds, unlocking a whole new world of AI-powered experiences that feel more human, responsive, and conversational in real time. Whether you're building a live voice assistant, a responsive chatbot, or interactive multiplayer tools powered by AI, this API puts real in real-time AI.

GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.

Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.
Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.
Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.
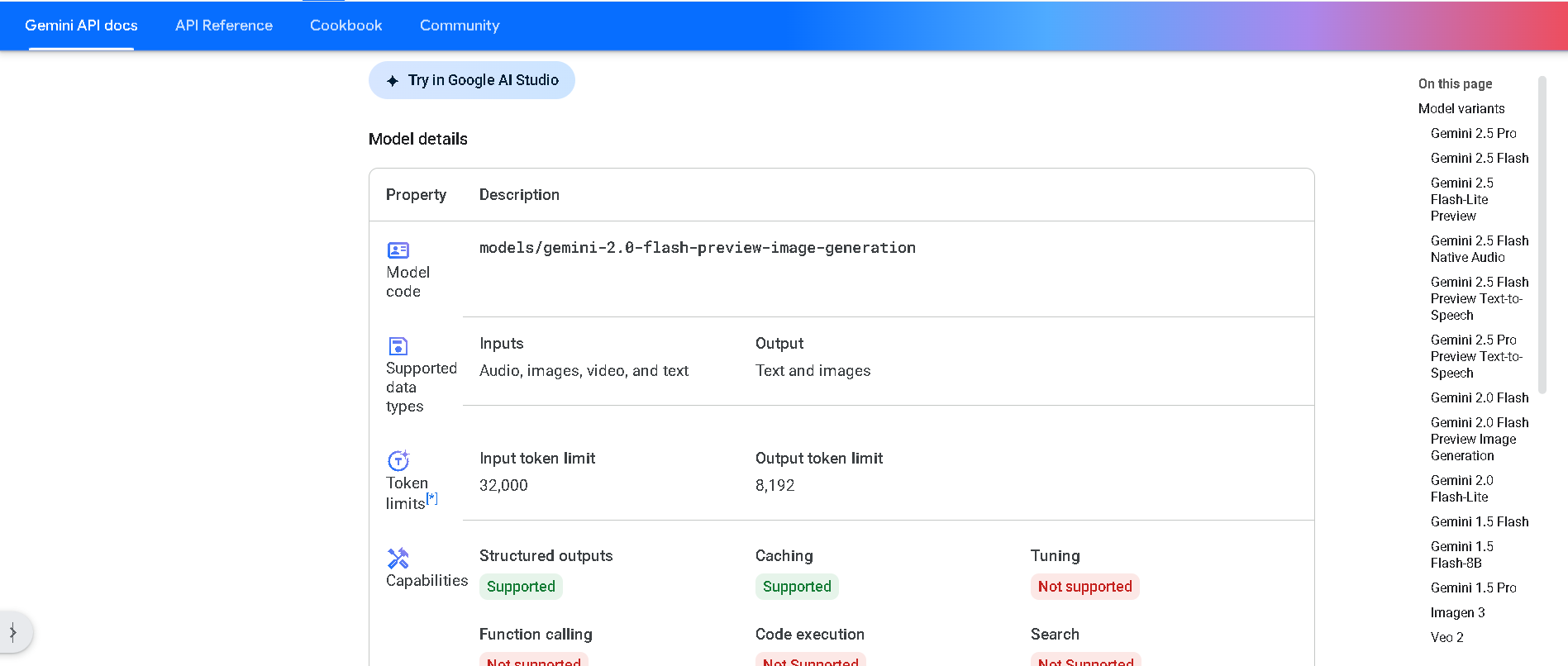
Gemini 2.0 Flash Preview Image Generation is Google’s experimental vision feature built into the Flash model. It enables developers to generate and edit images alongside text in a conversational manner and supports multi-turn, context-aware visual workflows via the Gemini API or Vertex AI.
Gemini 2.0 Flash Preview Image Generation is Google’s experimental vision feature built into the Flash model. It enables developers to generate and edit images alongside text in a conversational manner and supports multi-turn, context-aware visual workflows via the Gemini API or Vertex AI.
Gemini 2.0 Flash Preview Image Generation is Google’s experimental vision feature built into the Flash model. It enables developers to generate and edit images alongside text in a conversational manner and supports multi-turn, context-aware visual workflows via the Gemini API or Vertex AI.
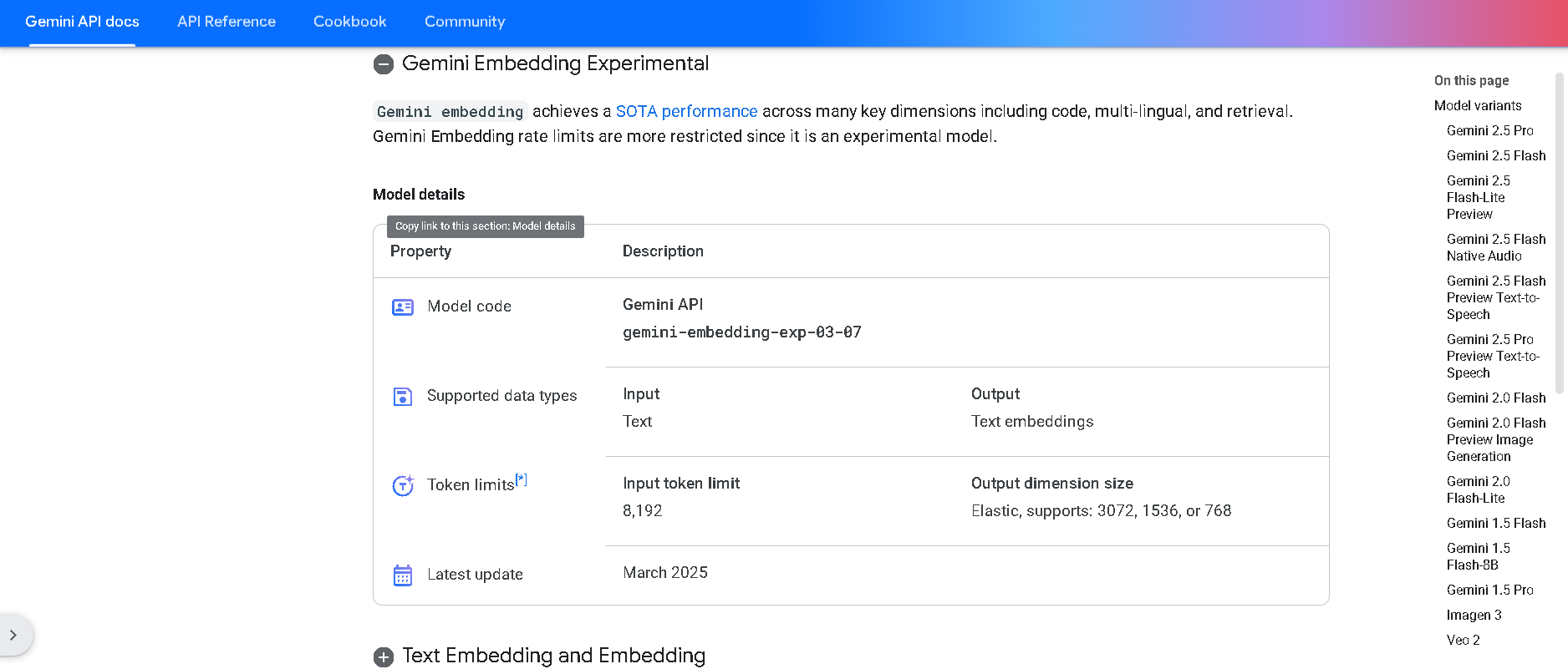

Gemini Embedding
Gemini Embedding is Google DeepMind’s state-of-the-art text embedding model, built on the powerful Gemini family. It transforms text into high-dimensional numerical vectors (up to 3,072 dimensions) with exceptional accuracy and generalization across over 100 languages and multiple modalities—including code. It achieves state-of-the-art results on the Massive Multilingual Text Embedding Benchmark (MMTEB), outperforming prior models across multilingual, English, and code-based tasks
Gemini Embedding
Gemini Embedding is Google DeepMind’s state-of-the-art text embedding model, built on the powerful Gemini family. It transforms text into high-dimensional numerical vectors (up to 3,072 dimensions) with exceptional accuracy and generalization across over 100 languages and multiple modalities—including code. It achieves state-of-the-art results on the Massive Multilingual Text Embedding Benchmark (MMTEB), outperforming prior models across multilingual, English, and code-based tasks
Gemini Embedding
Gemini Embedding is Google DeepMind’s state-of-the-art text embedding model, built on the powerful Gemini family. It transforms text into high-dimensional numerical vectors (up to 3,072 dimensions) with exceptional accuracy and generalization across over 100 languages and multiple modalities—including code. It achieves state-of-the-art results on the Massive Multilingual Text Embedding Benchmark (MMTEB), outperforming prior models across multilingual, English, and code-based tasks

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.

Google AI Studio
Google AI Studio is a web-based development environment that allows users to explore, prototype, and build applications using Google's cutting-edge generative AI models, such as Gemini. It provides a comprehensive set of tools for interacting with AI through chat prompts, generating various media types, and fine-tuning model behaviors for specific use cases.
Google AI Studio
Google AI Studio is a web-based development environment that allows users to explore, prototype, and build applications using Google's cutting-edge generative AI models, such as Gemini. It provides a comprehensive set of tools for interacting with AI through chat prompts, generating various media types, and fine-tuning model behaviors for specific use cases.
Google AI Studio
Google AI Studio is a web-based development environment that allows users to explore, prototype, and build applications using Google's cutting-edge generative AI models, such as Gemini. It provides a comprehensive set of tools for interacting with AI through chat prompts, generating various media types, and fine-tuning model behaviors for specific use cases.

Nano Banana
Gemini 2.5 Flash Image is Google's state-of-the-art AI image generation and editing model, nicknamed Nano Banana, designed for fast, high-quality creative workflows. It excels at blending multiple images into seamless compositions, maintaining character consistency across scenes, and making precise edits through natural language prompts like blurring backgrounds or changing poses. Accessible via Google AI Studio and Gemini API, it leverages Gemini's world knowledge for realistic transformations, style transfers, and conversational refinements without restarting from scratch. Developers love its low latency, token-based pricing at about $0.039 per image, and SynthID watermarking for easy AI identification. Perfect for product mockups, storytelling, education tools, and professional photo editing.
Nano Banana
Gemini 2.5 Flash Image is Google's state-of-the-art AI image generation and editing model, nicknamed Nano Banana, designed for fast, high-quality creative workflows. It excels at blending multiple images into seamless compositions, maintaining character consistency across scenes, and making precise edits through natural language prompts like blurring backgrounds or changing poses. Accessible via Google AI Studio and Gemini API, it leverages Gemini's world knowledge for realistic transformations, style transfers, and conversational refinements without restarting from scratch. Developers love its low latency, token-based pricing at about $0.039 per image, and SynthID watermarking for easy AI identification. Perfect for product mockups, storytelling, education tools, and professional photo editing.
Nano Banana
Gemini 2.5 Flash Image is Google's state-of-the-art AI image generation and editing model, nicknamed Nano Banana, designed for fast, high-quality creative workflows. It excels at blending multiple images into seamless compositions, maintaining character consistency across scenes, and making precise edits through natural language prompts like blurring backgrounds or changing poses. Accessible via Google AI Studio and Gemini API, it leverages Gemini's world knowledge for realistic transformations, style transfers, and conversational refinements without restarting from scratch. Developers love its low latency, token-based pricing at about $0.039 per image, and SynthID watermarking for easy AI identification. Perfect for product mockups, storytelling, education tools, and professional photo editing.


GlobalGPT
GlobalGPT is an all-in-one AI platform that unifies leading models for writing, coding, research, image generation, and video creation—accessible through a single account and subscription. It brings together top models like GPT-5, GPT-4.1, GPT-4o, GPT-o3, Claude Opus 4.1, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek V3, Unikorn (MJ-like) V7, Flux, Ideogram, and Google Veo 3 so you can chat, draft content, analyze documents, generate images, and produce cinematic videos without switching tools. Designed for over 2 million users worldwide, GlobalGPT also includes advanced research agents powered by GPT-4o and perplexity for deep web analysis, PDF summarization, and market insights, all wrapped in a clean interface with flexible credit-based plans.
GlobalGPT
GlobalGPT is an all-in-one AI platform that unifies leading models for writing, coding, research, image generation, and video creation—accessible through a single account and subscription. It brings together top models like GPT-5, GPT-4.1, GPT-4o, GPT-o3, Claude Opus 4.1, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek V3, Unikorn (MJ-like) V7, Flux, Ideogram, and Google Veo 3 so you can chat, draft content, analyze documents, generate images, and produce cinematic videos without switching tools. Designed for over 2 million users worldwide, GlobalGPT also includes advanced research agents powered by GPT-4o and perplexity for deep web analysis, PDF summarization, and market insights, all wrapped in a clean interface with flexible credit-based plans.
GlobalGPT
GlobalGPT is an all-in-one AI platform that unifies leading models for writing, coding, research, image generation, and video creation—accessible through a single account and subscription. It brings together top models like GPT-5, GPT-4.1, GPT-4o, GPT-o3, Claude Opus 4.1, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek V3, Unikorn (MJ-like) V7, Flux, Ideogram, and Google Veo 3 so you can chat, draft content, analyze documents, generate images, and produce cinematic videos without switching tools. Designed for over 2 million users worldwide, GlobalGPT also includes advanced research agents powered by GPT-4o and perplexity for deep web analysis, PDF summarization, and market insights, all wrapped in a clean interface with flexible credit-based plans.

Gemma
Gemma is a family of lightweight, state-of-the-art open models from Google DeepMind, built using the same research and technology that powers the Gemini models. Available in sizes from 270M to 27B parameters, they support multimodal understanding with text, image, video, and audio inputs while generating text outputs, alongside strong multilingual capabilities across over 140 languages. Specialized variants like CodeGemma for coding, PaliGemma for vision-language tasks, ShieldGemma for safety classification, MedGemma for medical imaging and text, and mobile-optimized Gemma 3n enable developers to create efficient AI apps that run on devices from phones to servers. These models excel in tasks like summarization, question answering, reasoning, code generation, and translation, with tools for fine-tuning and deployment.
Gemma
Gemma is a family of lightweight, state-of-the-art open models from Google DeepMind, built using the same research and technology that powers the Gemini models. Available in sizes from 270M to 27B parameters, they support multimodal understanding with text, image, video, and audio inputs while generating text outputs, alongside strong multilingual capabilities across over 140 languages. Specialized variants like CodeGemma for coding, PaliGemma for vision-language tasks, ShieldGemma for safety classification, MedGemma for medical imaging and text, and mobile-optimized Gemma 3n enable developers to create efficient AI apps that run on devices from phones to servers. These models excel in tasks like summarization, question answering, reasoning, code generation, and translation, with tools for fine-tuning and deployment.
Gemma
Gemma is a family of lightweight, state-of-the-art open models from Google DeepMind, built using the same research and technology that powers the Gemini models. Available in sizes from 270M to 27B parameters, they support multimodal understanding with text, image, video, and audio inputs while generating text outputs, alongside strong multilingual capabilities across over 140 languages. Specialized variants like CodeGemma for coding, PaliGemma for vision-language tasks, ShieldGemma for safety classification, MedGemma for medical imaging and text, and mobile-optimized Gemma 3n enable developers to create efficient AI apps that run on devices from phones to servers. These models excel in tasks like summarization, question answering, reasoning, code generation, and translation, with tools for fine-tuning and deployment.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai