
- App Developers: Build rich interfaces with combined text and image outputs for storytelling, UX prototyping, or educational tools.
- Design & Marketing Teams: Quickly generate visuals, create brand assets, or edit imagery with iterative prompts.
- Content Creators: Produce illustrated content, recipes, manuals, and comic-style visuals in one flow.
- Researchers & Educators: Visualize diagrams, step-by-step explanations, or historical reconstructions.
- Experimenting Developers: Test visual workflows at scale via Google AI Studio or Vertex AI.
How to Use Gemini 2.0 Flash Image Generation?
- Enable the Preview Model: Use the model `gemini-2.0-flash-preview-image-generation` in AI Studio or Vertex AI.
- Include Text + Image Output: Set `responseModalities` to include both text and images.
- Send Prompts & Images: Provide text descriptions or upload existing images for editing.
- Iterate Conversationally: Refine outputs through multi-turn prompts—e.g., adjust styles, zoom levels, or colors.
- Scale Production: Handle thousands of image requests per prompt, up to 10 images at 1024px, with enhanced rate limits.
- Conversational Image Generation & Editing: Supports back-and-forth refinements with context awareness.
- Text Rendering in Images: Optimized for high-quality text overlays in visuals like banners and educational diagrams.
- Multi-modal Storytelling: Enables longform illustrated narratives—comics, recipes, how-tos—with consistent style.
- Developer-Centric: Higher rate limits, robust pricing, and API integration via Studio and Vertex.
- High Fidelity & Control: Better watermarking and image fidelity, with early guardrails and SynthID marking.
- Supports both generation and editing of images in chat
- Great text integration in visuals for media output
- Maintains artistic consistency across multi-turn sessions
- API-supported with high throughput and strong safety measures
- Ideal for illustrated storytelling and developer experimentation
- Still in preview—no SLA or production guarantees
- Tool limitations: no function calling or audio generation
- Access restricted in some regions (e.g., certain countries in EMEA)
Free
$ 0.00
API
Custom
- Input price: 1) $0.10 (text / image / video) 2) $0.70 (audio)
- Output price: $0.40
- Context caching price: 1) $0.025 / 1,000,000 tokens (text/image/video)
- Context caching (storage): $1.00 / 1,000,000 tokens per hour
- Image generation pricing: $0.039 per image*
- Grounding with Google Search: 1,500 RPD (free), then $35 / 1,000 requests
- Live APIs: Input: $0.35 (text), $2.10 (audio / image [video])
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
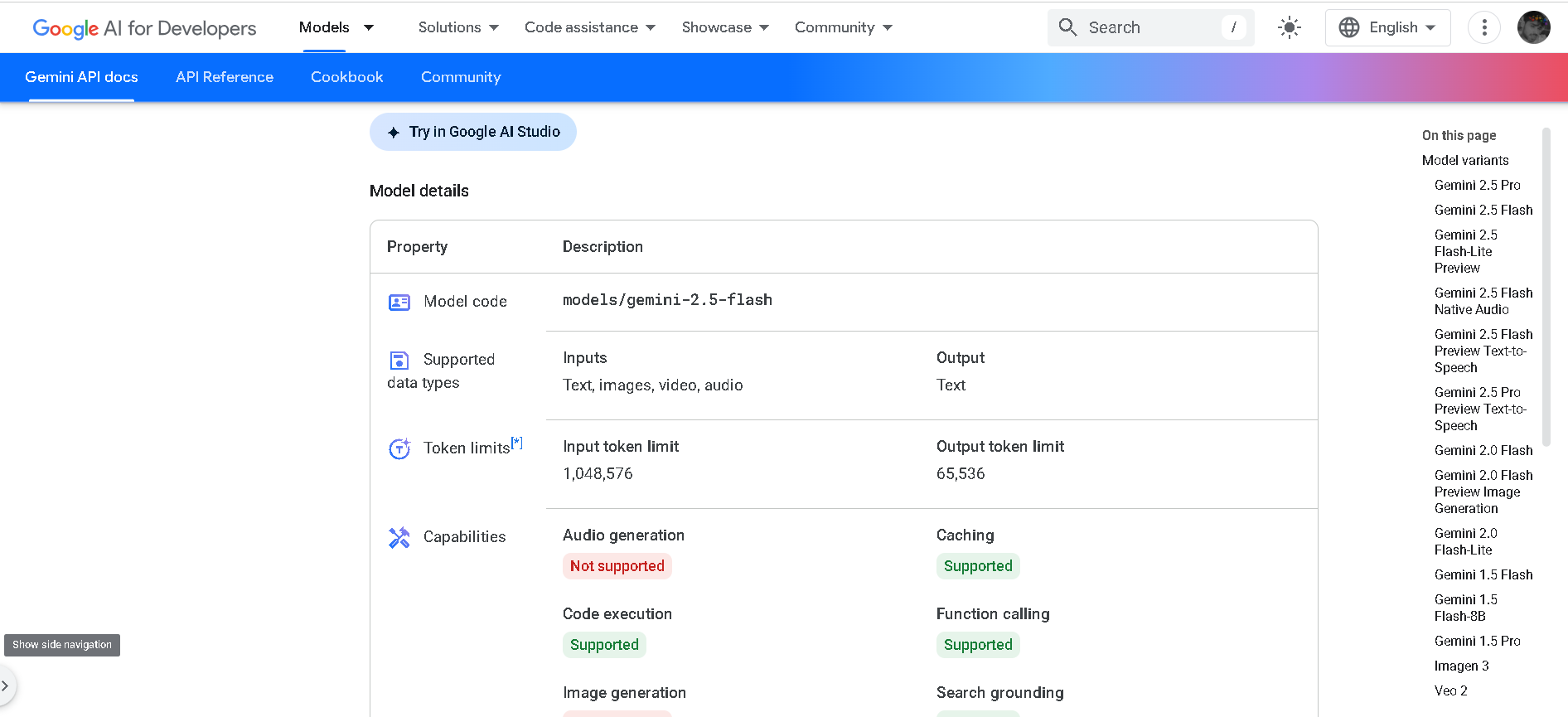

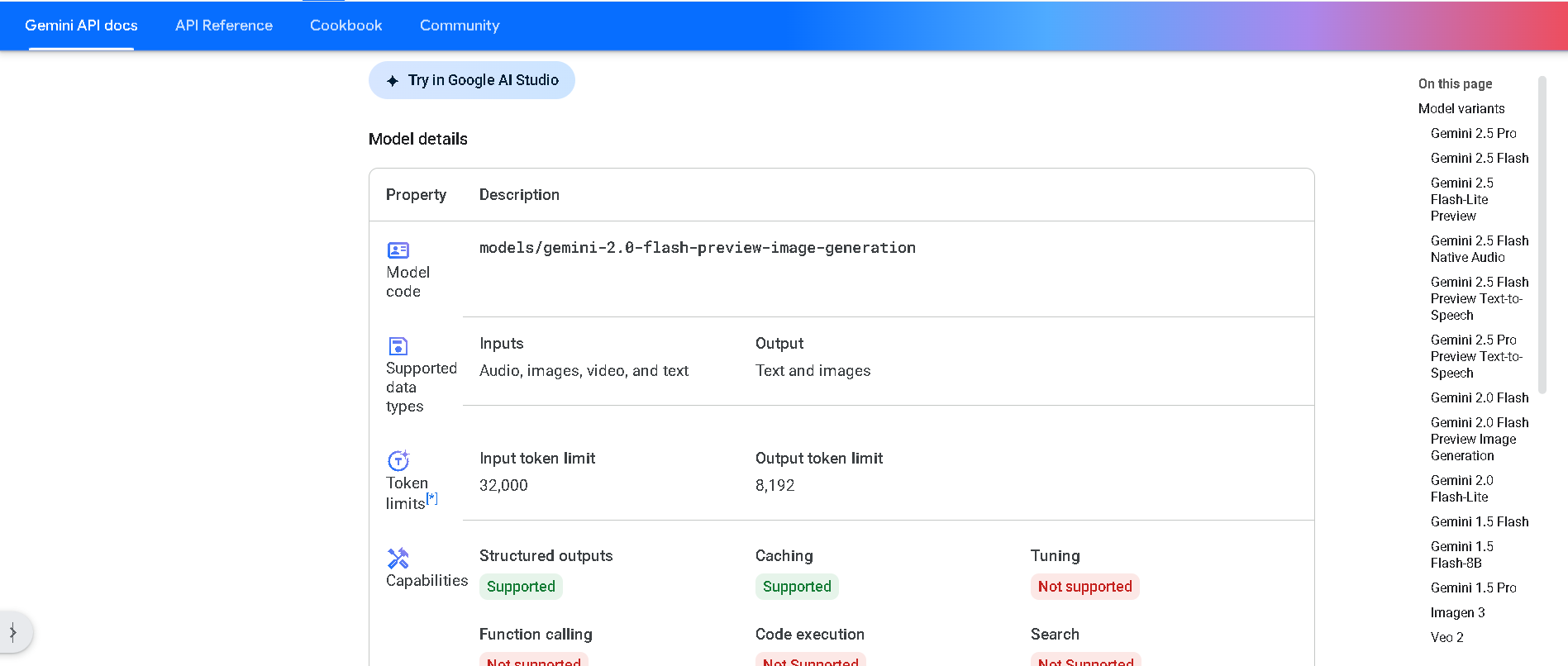
Gemini 2.5 Flash
Gemini 2.5 Flash is Google DeepMind’s cost-efficient, low-latency hybrid-reasoning model. Designed for large-scale, real-time tasks that require thinking—like classification, translation, conversational AI, and agent behaviors—it supports text, image, audio, and video input, and offers developer control over its reasoning depth. It balances high speed with strong multimodal intelligence.
Gemini 2.5 Flash
Gemini 2.5 Flash is Google DeepMind’s cost-efficient, low-latency hybrid-reasoning model. Designed for large-scale, real-time tasks that require thinking—like classification, translation, conversational AI, and agent behaviors—it supports text, image, audio, and video input, and offers developer control over its reasoning depth. It balances high speed with strong multimodal intelligence.
Gemini 2.5 Flash
Gemini 2.5 Flash is Google DeepMind’s cost-efficient, low-latency hybrid-reasoning model. Designed for large-scale, real-time tasks that require thinking—like classification, translation, conversational AI, and agent behaviors—it supports text, image, audio, and video input, and offers developer control over its reasoning depth. It balances high speed with strong multimodal intelligence.
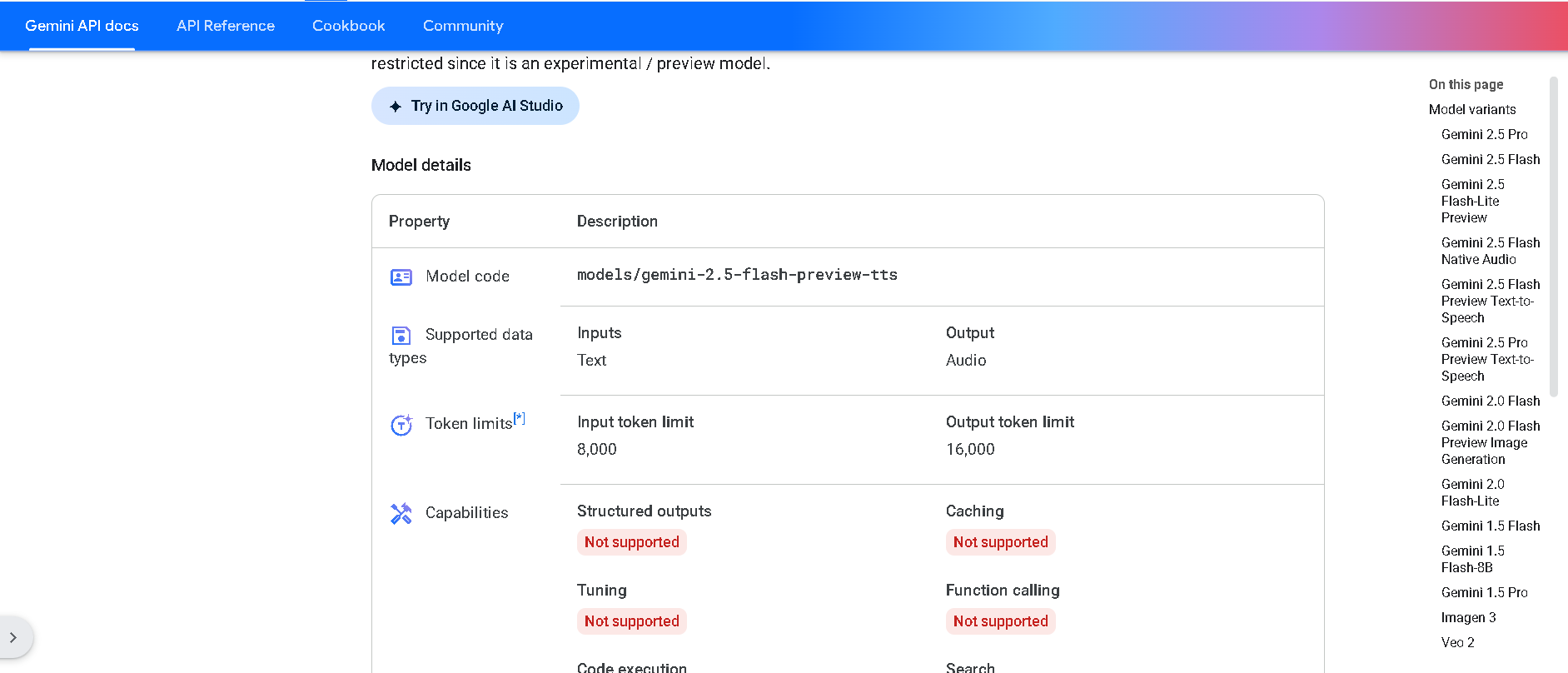
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
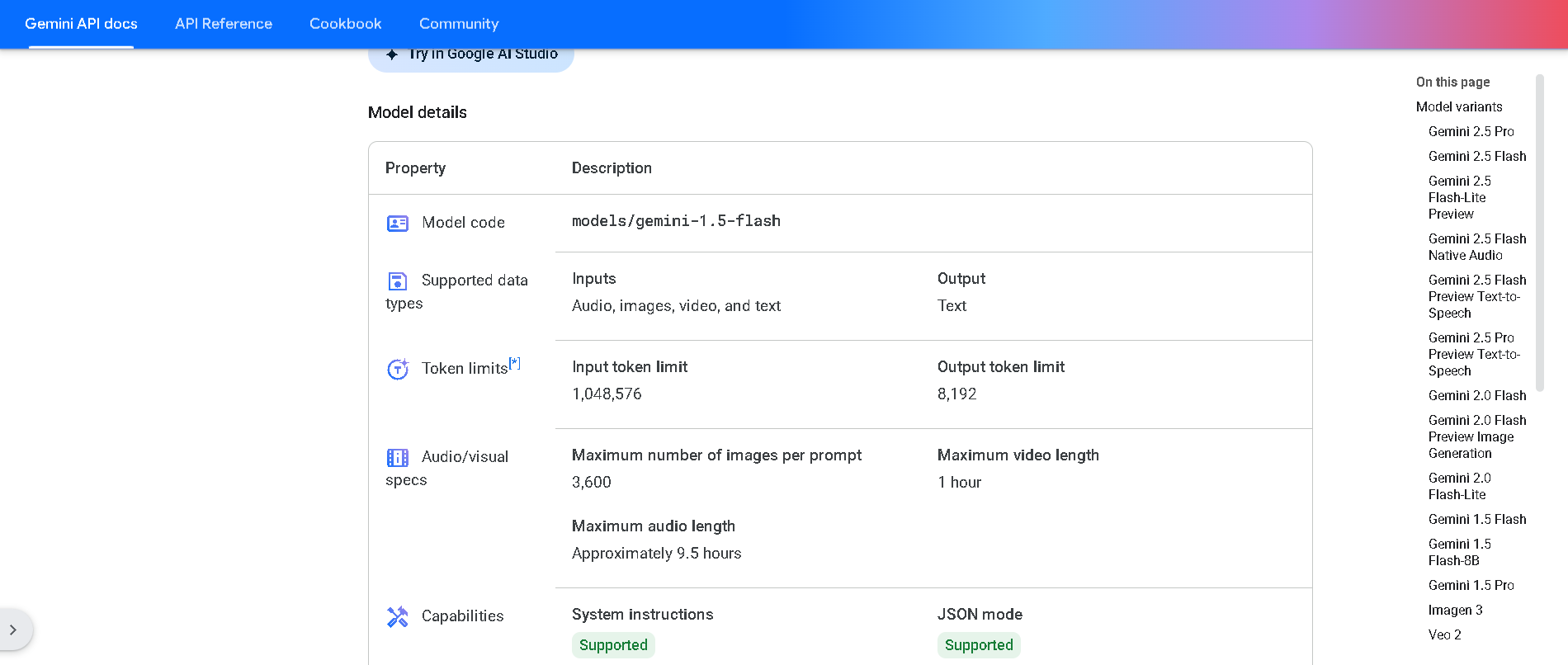

Gemini 1.5 Flash
Gemini 1.5 Flash is Google DeepMind’s high-speed, multimodal AI model distilled from the 1.5 Pro variant. It supports text, images, audio, video, PDFs, and large context windows up to 1 million tokens. Designed for real-time, large-scale use, it delivers sub-second first-token latency and retains strong reasoning, summarization, and multimodal understanding capabilities.
Gemini 1.5 Flash
Gemini 1.5 Flash is Google DeepMind’s high-speed, multimodal AI model distilled from the 1.5 Pro variant. It supports text, images, audio, video, PDFs, and large context windows up to 1 million tokens. Designed for real-time, large-scale use, it delivers sub-second first-token latency and retains strong reasoning, summarization, and multimodal understanding capabilities.
Gemini 1.5 Flash
Gemini 1.5 Flash is Google DeepMind’s high-speed, multimodal AI model distilled from the 1.5 Pro variant. It supports text, images, audio, video, PDFs, and large context windows up to 1 million tokens. Designed for real-time, large-scale use, it delivers sub-second first-token latency and retains strong reasoning, summarization, and multimodal understanding capabilities.
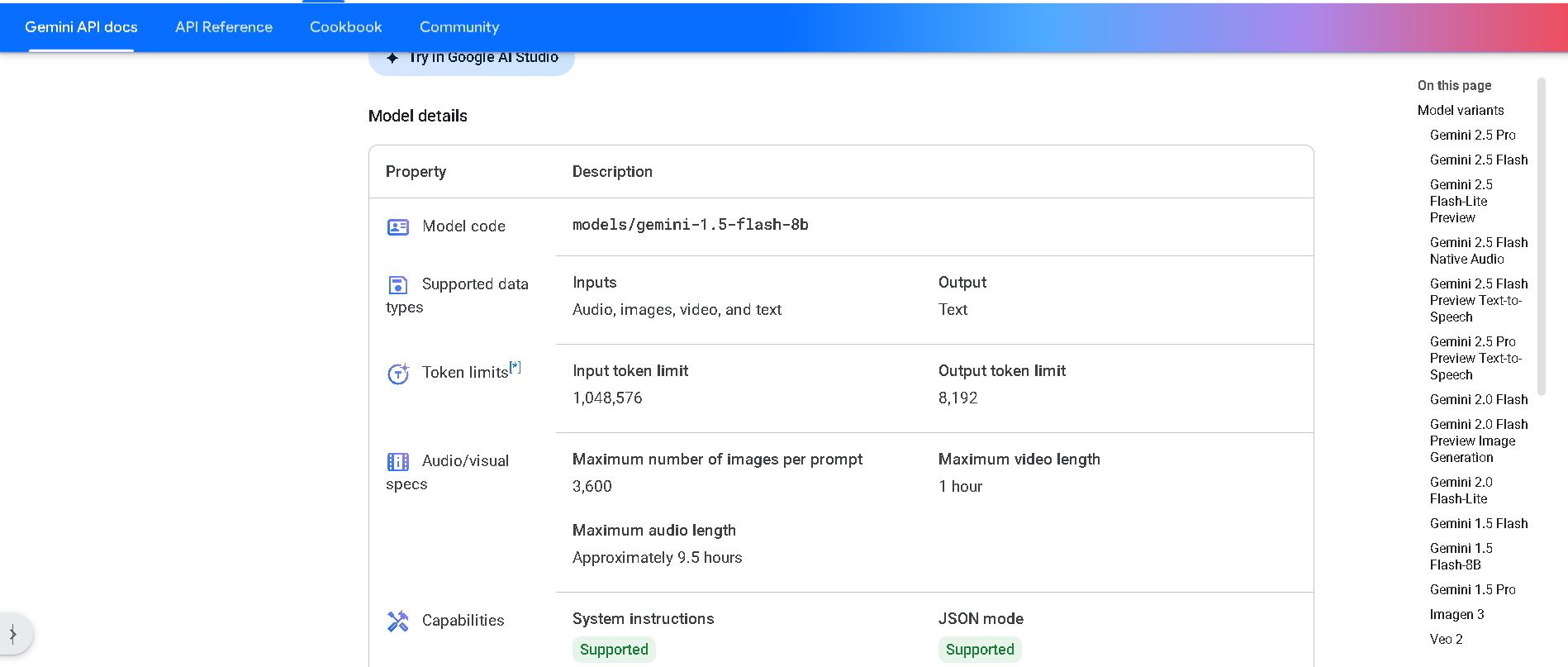
Gemini 1.5 Flash‑8B is Google DeepMind’s lightweight, high-volume variant of the 1.5 Flash model, optimized for efficiency and scale. It maintains multimodal abilities (text, image, audio, video) and a massive 1 million token context window—while offering 50 % lower pricing, 2× higher rate limits, and lower latency on small prompts compared to standard Flash.
Gemini 1.5 Flash‑8B is Google DeepMind’s lightweight, high-volume variant of the 1.5 Flash model, optimized for efficiency and scale. It maintains multimodal abilities (text, image, audio, video) and a massive 1 million token context window—while offering 50 % lower pricing, 2× higher rate limits, and lower latency on small prompts compared to standard Flash.
Gemini 1.5 Flash‑8B is Google DeepMind’s lightweight, high-volume variant of the 1.5 Flash model, optimized for efficiency and scale. It maintains multimodal abilities (text, image, audio, video) and a massive 1 million token context window—while offering 50 % lower pricing, 2× higher rate limits, and lower latency on small prompts compared to standard Flash.
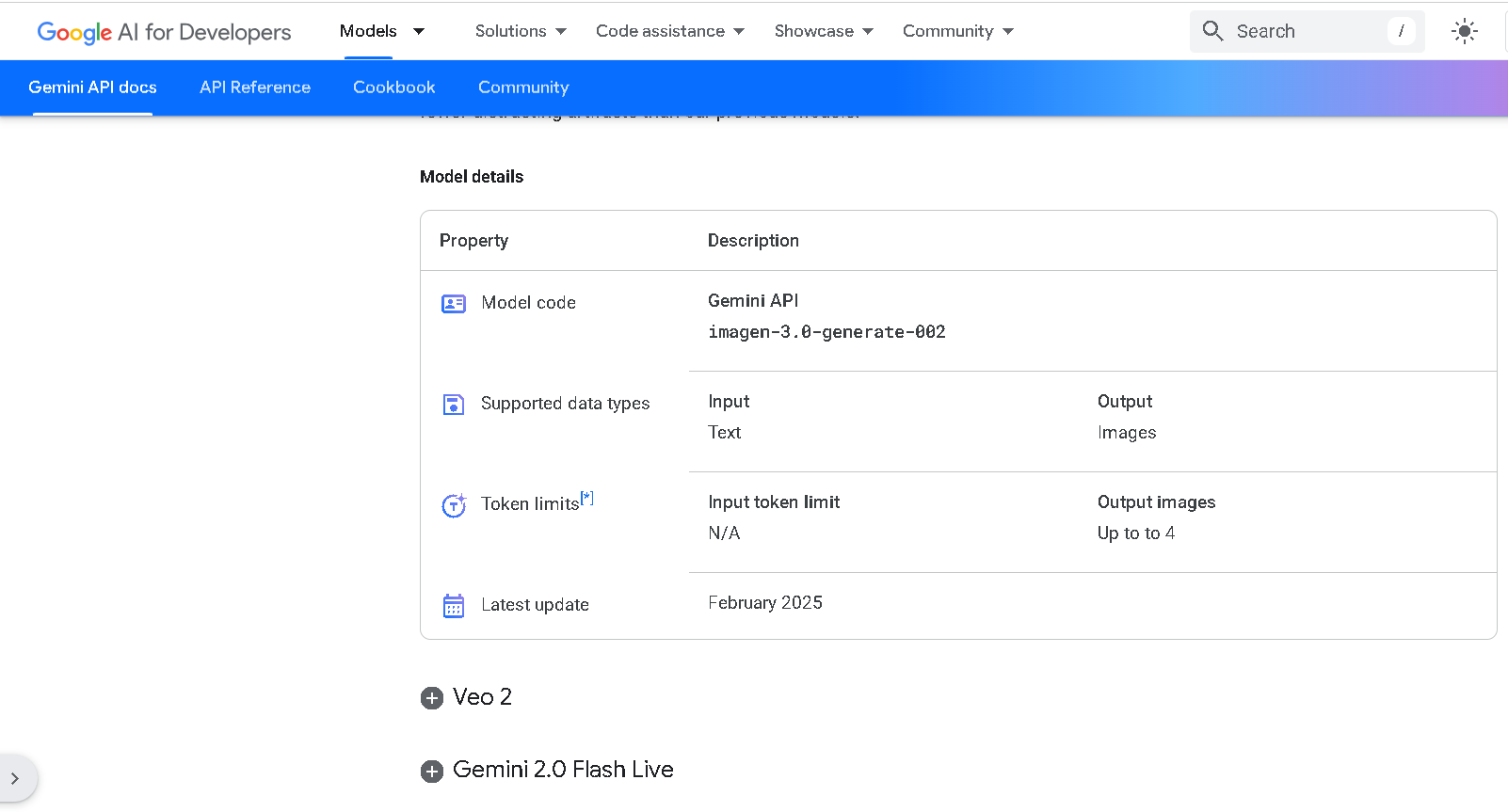

Imagen 3
Imagen 3 is Google DeepMind’s latest state-of-the-art text-to-image model, capable of creating photorealistic or stylized visuals from simple, natural language prompts. It excels in detail, lighting, text rendering, and prompt fidelity, supporting image editing like inpainting/outpainting and generating output at high resolution with fewer visual artifacts.
Imagen 3
Imagen 3 is Google DeepMind’s latest state-of-the-art text-to-image model, capable of creating photorealistic or stylized visuals from simple, natural language prompts. It excels in detail, lighting, text rendering, and prompt fidelity, supporting image editing like inpainting/outpainting and generating output at high resolution with fewer visual artifacts.
Imagen 3
Imagen 3 is Google DeepMind’s latest state-of-the-art text-to-image model, capable of creating photorealistic or stylized visuals from simple, natural language prompts. It excels in detail, lighting, text rendering, and prompt fidelity, supporting image editing like inpainting/outpainting and generating output at high resolution with fewer visual artifacts.
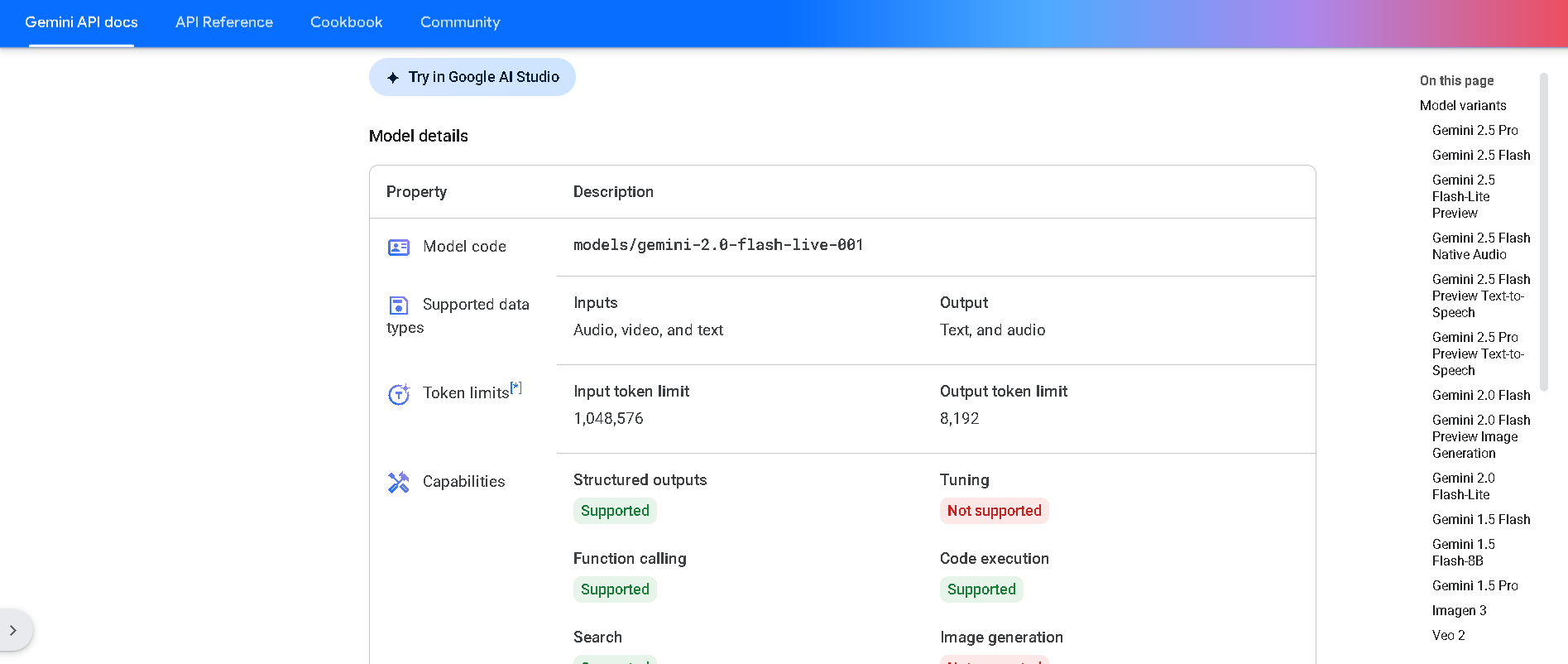
Gemini 2.0 Flash Live is Google DeepMind’s real-time, multimodal chatbot variant powered by the Live API. It supports simultaneous streaming of voice, video, and text inputs, and responds in both spoken audio and text, enabling rich, bidirectional live interactions with low latency and tool integration.
Gemini 2.0 Flash Live is Google DeepMind’s real-time, multimodal chatbot variant powered by the Live API. It supports simultaneous streaming of voice, video, and text inputs, and responds in both spoken audio and text, enabling rich, bidirectional live interactions with low latency and tool integration.
Gemini 2.0 Flash Live is Google DeepMind’s real-time, multimodal chatbot variant powered by the Live API. It supports simultaneous streaming of voice, video, and text inputs, and responds in both spoken audio and text, enabling rich, bidirectional live interactions with low latency and tool integration.
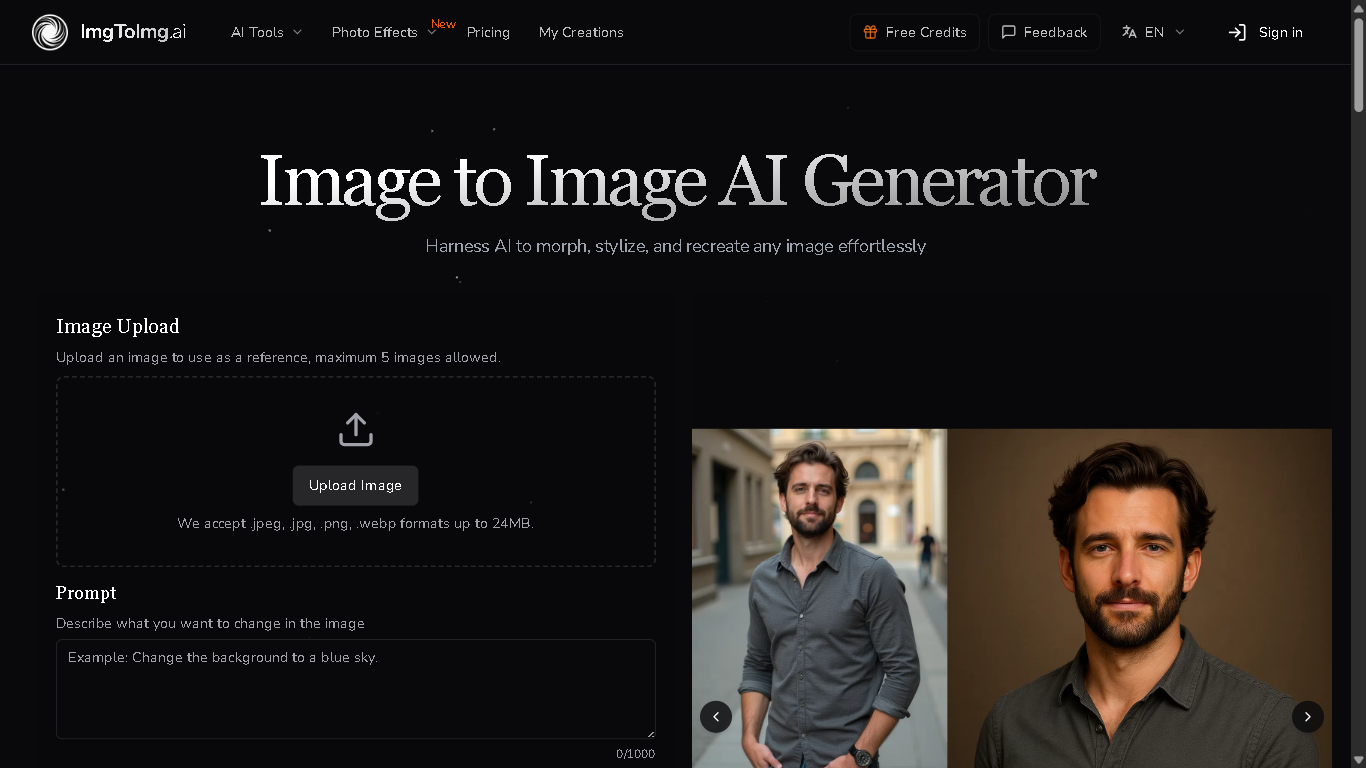
Image To Image AI
imgtoimg.ai is an AI-powered image generation platform that allows users to transform images into various artistic styles and formats. It utilizes advanced AI models to upscale, enhance, and modify images based on user-provided prompts and parameters, offering a range of creative possibilities for both personal and professional use.
Image To Image AI
imgtoimg.ai is an AI-powered image generation platform that allows users to transform images into various artistic styles and formats. It utilizes advanced AI models to upscale, enhance, and modify images based on user-provided prompts and parameters, offering a range of creative possibilities for both personal and professional use.
Image To Image AI
imgtoimg.ai is an AI-powered image generation platform that allows users to transform images into various artistic styles and formats. It utilizes advanced AI models to upscale, enhance, and modify images based on user-provided prompts and parameters, offering a range of creative possibilities for both personal and professional use.
Filtrix AI
Filtrix.ai is an AI-powered image transformation platform designed to convert ordinary photos into artistic masterpieces. With specialized filters like Studio Ghibli, Sesame Street, and Pixar, Filtrix offers unique style transformations that cater to various creative needs. Whether you're a content creator, marketer, or e-commerce seller, Filtrix provides tools to enhance your visuals effortlessly.
Filtrix AI
Filtrix.ai is an AI-powered image transformation platform designed to convert ordinary photos into artistic masterpieces. With specialized filters like Studio Ghibli, Sesame Street, and Pixar, Filtrix offers unique style transformations that cater to various creative needs. Whether you're a content creator, marketer, or e-commerce seller, Filtrix provides tools to enhance your visuals effortlessly.
Filtrix AI
Filtrix.ai is an AI-powered image transformation platform designed to convert ordinary photos into artistic masterpieces. With specialized filters like Studio Ghibli, Sesame Street, and Pixar, Filtrix offers unique style transformations that cater to various creative needs. Whether you're a content creator, marketer, or e-commerce seller, Filtrix provides tools to enhance your visuals effortlessly.

StarryAI
starryai is a free-to-start AI art generator that turns text prompts and reference images into unique visuals in seconds. It offers a generous daily free tier, a vast library of styles and models, and a prompt builder to fine-tune results without advanced technical skills. Users can choose methods like Art, Photos, Illustrations, or create Custom Styles, then customize canvas sizes and aspect ratios for social posts, print, or web. The platform supports upscaling, in-painting, and iterative refinement so ideas evolve quickly from draft to polished artwork. Full ownership rights allow use across personal and commercial projects, with Pro plans unlocking higher limits and priority generation.
StarryAI
starryai is a free-to-start AI art generator that turns text prompts and reference images into unique visuals in seconds. It offers a generous daily free tier, a vast library of styles and models, and a prompt builder to fine-tune results without advanced technical skills. Users can choose methods like Art, Photos, Illustrations, or create Custom Styles, then customize canvas sizes and aspect ratios for social posts, print, or web. The platform supports upscaling, in-painting, and iterative refinement so ideas evolve quickly from draft to polished artwork. Full ownership rights allow use across personal and commercial projects, with Pro plans unlocking higher limits and priority generation.
StarryAI
starryai is a free-to-start AI art generator that turns text prompts and reference images into unique visuals in seconds. It offers a generous daily free tier, a vast library of styles and models, and a prompt builder to fine-tune results without advanced technical skills. Users can choose methods like Art, Photos, Illustrations, or create Custom Styles, then customize canvas sizes and aspect ratios for social posts, print, or web. The platform supports upscaling, in-painting, and iterative refinement so ideas evolve quickly from draft to polished artwork. Full ownership rights allow use across personal and commercial projects, with Pro plans unlocking higher limits and priority generation.

Stitch
Stitch is Google's AI-powered UI design tool that transforms text prompts, sketches, or screenshots into responsive mobile and web interfaces in minutes. Powered by Gemini models—Flash for quick standard mode or Pro for high-fidelity experimental—it generates layouts, visuals, and clean frontend code like HTML/CSS or React. Edit themes, create variants, and refine conversationally, then export directly to Figma or your IDE for handoff. Free via Google Labs with quotas, it's ideal for rapid prototyping, speeding ideation without design expertise, and bridging designers and developers seamlessly.
Stitch
Stitch is Google's AI-powered UI design tool that transforms text prompts, sketches, or screenshots into responsive mobile and web interfaces in minutes. Powered by Gemini models—Flash for quick standard mode or Pro for high-fidelity experimental—it generates layouts, visuals, and clean frontend code like HTML/CSS or React. Edit themes, create variants, and refine conversationally, then export directly to Figma or your IDE for handoff. Free via Google Labs with quotas, it's ideal for rapid prototyping, speeding ideation without design expertise, and bridging designers and developers seamlessly.
Stitch
Stitch is Google's AI-powered UI design tool that transforms text prompts, sketches, or screenshots into responsive mobile and web interfaces in minutes. Powered by Gemini models—Flash for quick standard mode or Pro for high-fidelity experimental—it generates layouts, visuals, and clean frontend code like HTML/CSS or React. Edit themes, create variants, and refine conversationally, then export directly to Figma or your IDE for handoff. Free via Google Labs with quotas, it's ideal for rapid prototyping, speeding ideation without design expertise, and bridging designers and developers seamlessly.


Whisk
Whisk is Google's experimental AI tool for creating images and short videos by using uploaded images as visual prompts alongside optional text. Upload photos for subject (main focus), scene (environment), and style (artistic vibe), and Gemini analyzes them into detailed captions fed to Google's Imagen model for creative outputs, no prompting expertise needed. Refine results conversationally, animate images with Veo, browse inspiration galleries, and remix ideas visually like chatting with a creative friend. Free for 18+ users in supported countries via Google sign-in, with credits (e.g., 100 monthly for Workspace), it's perfect for fast ideation, storytelling, and visual experimentation.
Whisk
Whisk is Google's experimental AI tool for creating images and short videos by using uploaded images as visual prompts alongside optional text. Upload photos for subject (main focus), scene (environment), and style (artistic vibe), and Gemini analyzes them into detailed captions fed to Google's Imagen model for creative outputs, no prompting expertise needed. Refine results conversationally, animate images with Veo, browse inspiration galleries, and remix ideas visually like chatting with a creative friend. Free for 18+ users in supported countries via Google sign-in, with credits (e.g., 100 monthly for Workspace), it's perfect for fast ideation, storytelling, and visual experimentation.
Whisk
Whisk is Google's experimental AI tool for creating images and short videos by using uploaded images as visual prompts alongside optional text. Upload photos for subject (main focus), scene (environment), and style (artistic vibe), and Gemini analyzes them into detailed captions fed to Google's Imagen model for creative outputs, no prompting expertise needed. Refine results conversationally, animate images with Veo, browse inspiration galleries, and remix ideas visually like chatting with a creative friend. Free for 18+ users in supported countries via Google sign-in, with credits (e.g., 100 monthly for Workspace), it's perfect for fast ideation, storytelling, and visual experimentation.

Gemini 3
Gemini 3 is Google's most advanced AI model family, including Gemini 3 Pro and Gemini 3 Flash, excelling in state-of-the-art reasoning, multimodal understanding across text, images, video, audio, and code, with exceptional agentic capabilities for handling complex, multi-step tasks autonomously. Accessible directly in Google AI Studio for developers to experiment, tune prompts, and build apps, it shines in vibe coding, generating interactive experiences from ideas, superior tool use like Google Search integration, and conversational editing for images. With a massive 1M token context window, Deep Think mode for ultra-complex problem-solving, and features like structured outputs and function calling, it powers everything from personal assistants to sophisticated workflows, outperforming predecessors on benchmarks like GPQA and ARC-AGI.
Gemini 3
Gemini 3 is Google's most advanced AI model family, including Gemini 3 Pro and Gemini 3 Flash, excelling in state-of-the-art reasoning, multimodal understanding across text, images, video, audio, and code, with exceptional agentic capabilities for handling complex, multi-step tasks autonomously. Accessible directly in Google AI Studio for developers to experiment, tune prompts, and build apps, it shines in vibe coding, generating interactive experiences from ideas, superior tool use like Google Search integration, and conversational editing for images. With a massive 1M token context window, Deep Think mode for ultra-complex problem-solving, and features like structured outputs and function calling, it powers everything from personal assistants to sophisticated workflows, outperforming predecessors on benchmarks like GPQA and ARC-AGI.
Gemini 3
Gemini 3 is Google's most advanced AI model family, including Gemini 3 Pro and Gemini 3 Flash, excelling in state-of-the-art reasoning, multimodal understanding across text, images, video, audio, and code, with exceptional agentic capabilities for handling complex, multi-step tasks autonomously. Accessible directly in Google AI Studio for developers to experiment, tune prompts, and build apps, it shines in vibe coding, generating interactive experiences from ideas, superior tool use like Google Search integration, and conversational editing for images. With a massive 1M token context window, Deep Think mode for ultra-complex problem-solving, and features like structured outputs and function calling, it powers everything from personal assistants to sophisticated workflows, outperforming predecessors on benchmarks like GPQA and ARC-AGI.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai