
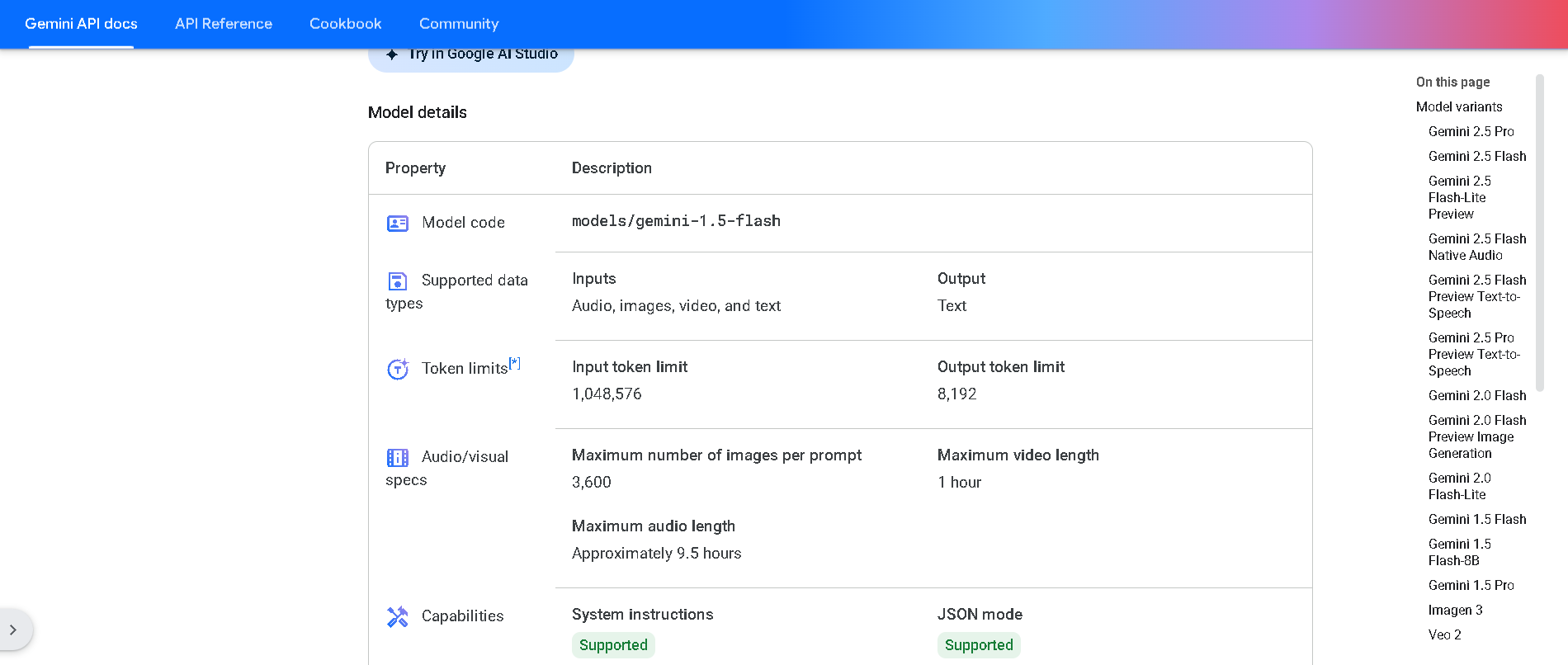
- Developers & Engineers: Integrate fast and cost-efficient multimodal AI into applications requiring high throughput and long-context understanding.
- Data & Document Teams: Rapidly analyze, classify, and summarize large datasets, documents, and visual content, including extracting information from PDFs and images.
- Customer Support & Chatbot Builders: Power real-time conversational agents, interactive content generation, and FAQ systems due to its low latency.
- Cost-Sensitive Projects: Ideal for large-scale deployments and applications where budget efficiency for both input and output tokens is a priority.
- Multimedia Content Processors: Transcribe, summarize, and extract information from long audio and video files efficiently.
How to Use Gemini 1.5 Flash?
- Access the Model: Available via Google AI Studio (free experimental access) and the Gemini API, also accessible through Google Cloud's Vertex AI Studio and CLI.
- Provide Multimodal Inputs: Submit prompts that include text, images, audio, video, or PDF files.
- Generate Text or Code Outputs: The model processes these mixed inputs swiftly to provide relevant text-based responses or generated code.
- Leverage Code Execution: Enable the code execution feature to allow the model to generate and run Python code iteratively for problem-solving.
- Optimize Usage: Utilize its long context window for large data processing; consider context caching in the API to reduce costs for repeated token usage.
- Optimized for Speed & Efficiency: Designed for rapid inference, offering significantly faster output speeds and higher throughput compared to other models, making it a leader in real-time applications.
- Remarkable 1 Million Token Context Window: Can process vast amounts of information—equivalent to hours of video, hundreds of pages of documents, or entire codebases—within a single prompt, offering unparalleled long-context understanding.
- Native Multimodality: Seamlessly handles and reasons across various data types (text, images, audio, video, PDFs) in one unified model, simplifying complex multimodal workflows.
- Exceptional Cost-Effectiveness: Offers highly competitive pricing for both input and output tokens, providing significant value for large-scale deployments and cost-sensitive projects.
- Built-in Code Execution: Features the ability to generate and execute Python code within a secure sandbox, enhancing its capabilities for complex problem-solving.
- Rapid, sub-second output for most prompts
- Handles various input formats seamlessly
- Supports very long context usage
- Available free in Gemini and via API
- Flash‑8B variant improves efficiency and cost
- Free-tier pruning: deeper features like code execution require Pro
- Flash-8B is slower than full Flash in edge cases
Free
$ 0.00
API
Custom
- Input Price: 1) $0.075, prompts <= 128k tokens 2) $0.15, prompts > 128k tokens
- Output Price: 1) $0.30, prompts <= 128k tokens 2) $0.60, prompts > 128k tokens
- Context Caching Price: 1) $0.01875, prompts <= 128k tokens 2) $0.0375, prompts > 128k tokens
- Context caching storage: $1.00 per hour
- Tuning Price: Token prices are the same for tuned models. Tuning service is free of charge.
- Grounding with Google search: $35 / 1K grounding requests
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
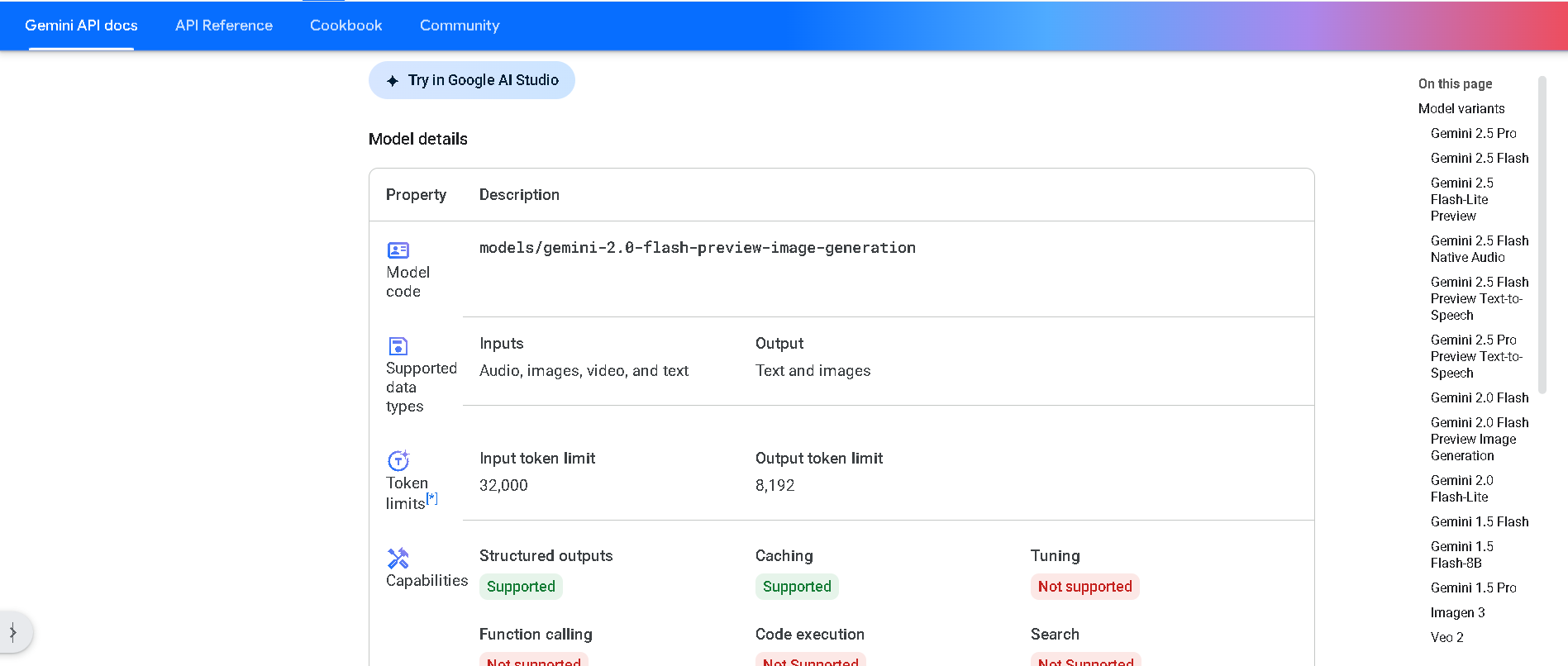
Gemini 2.0 Flash Preview Image Generation is Google’s experimental vision feature built into the Flash model. It enables developers to generate and edit images alongside text in a conversational manner and supports multi-turn, context-aware visual workflows via the Gemini API or Vertex AI.
Gemini 2.0 Flash Preview Image Generation is Google’s experimental vision feature built into the Flash model. It enables developers to generate and edit images alongside text in a conversational manner and supports multi-turn, context-aware visual workflows via the Gemini API or Vertex AI.
Gemini 2.0 Flash Preview Image Generation is Google’s experimental vision feature built into the Flash model. It enables developers to generate and edit images alongside text in a conversational manner and supports multi-turn, context-aware visual workflows via the Gemini API or Vertex AI.
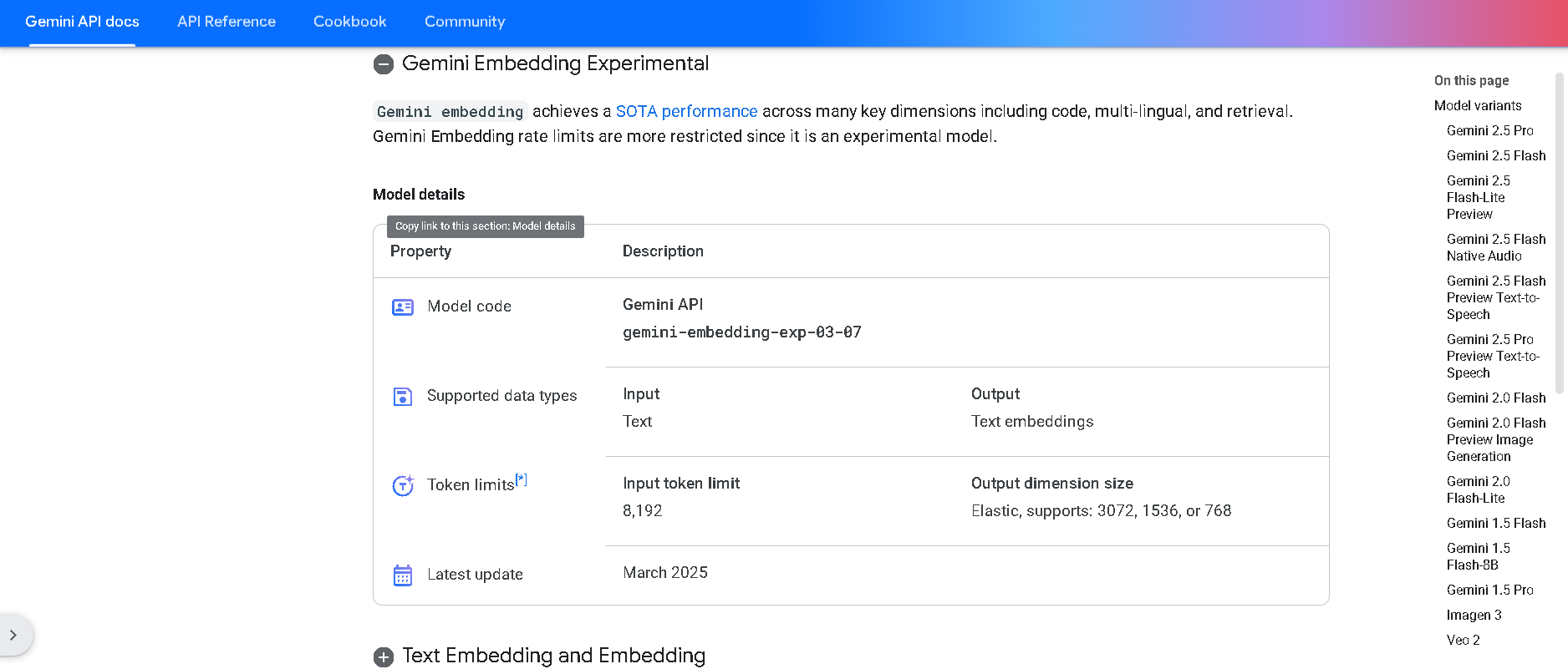

Gemini Embedding
Gemini Embedding is Google DeepMind’s state-of-the-art text embedding model, built on the powerful Gemini family. It transforms text into high-dimensional numerical vectors (up to 3,072 dimensions) with exceptional accuracy and generalization across over 100 languages and multiple modalities—including code. It achieves state-of-the-art results on the Massive Multilingual Text Embedding Benchmark (MMTEB), outperforming prior models across multilingual, English, and code-based tasks
Gemini Embedding
Gemini Embedding is Google DeepMind’s state-of-the-art text embedding model, built on the powerful Gemini family. It transforms text into high-dimensional numerical vectors (up to 3,072 dimensions) with exceptional accuracy and generalization across over 100 languages and multiple modalities—including code. It achieves state-of-the-art results on the Massive Multilingual Text Embedding Benchmark (MMTEB), outperforming prior models across multilingual, English, and code-based tasks
Gemini Embedding
Gemini Embedding is Google DeepMind’s state-of-the-art text embedding model, built on the powerful Gemini family. It transforms text into high-dimensional numerical vectors (up to 3,072 dimensions) with exceptional accuracy and generalization across over 100 languages and multiple modalities—including code. It achieves state-of-the-art results on the Massive Multilingual Text Embedding Benchmark (MMTEB), outperforming prior models across multilingual, English, and code-based tasks

Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.
Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.
Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
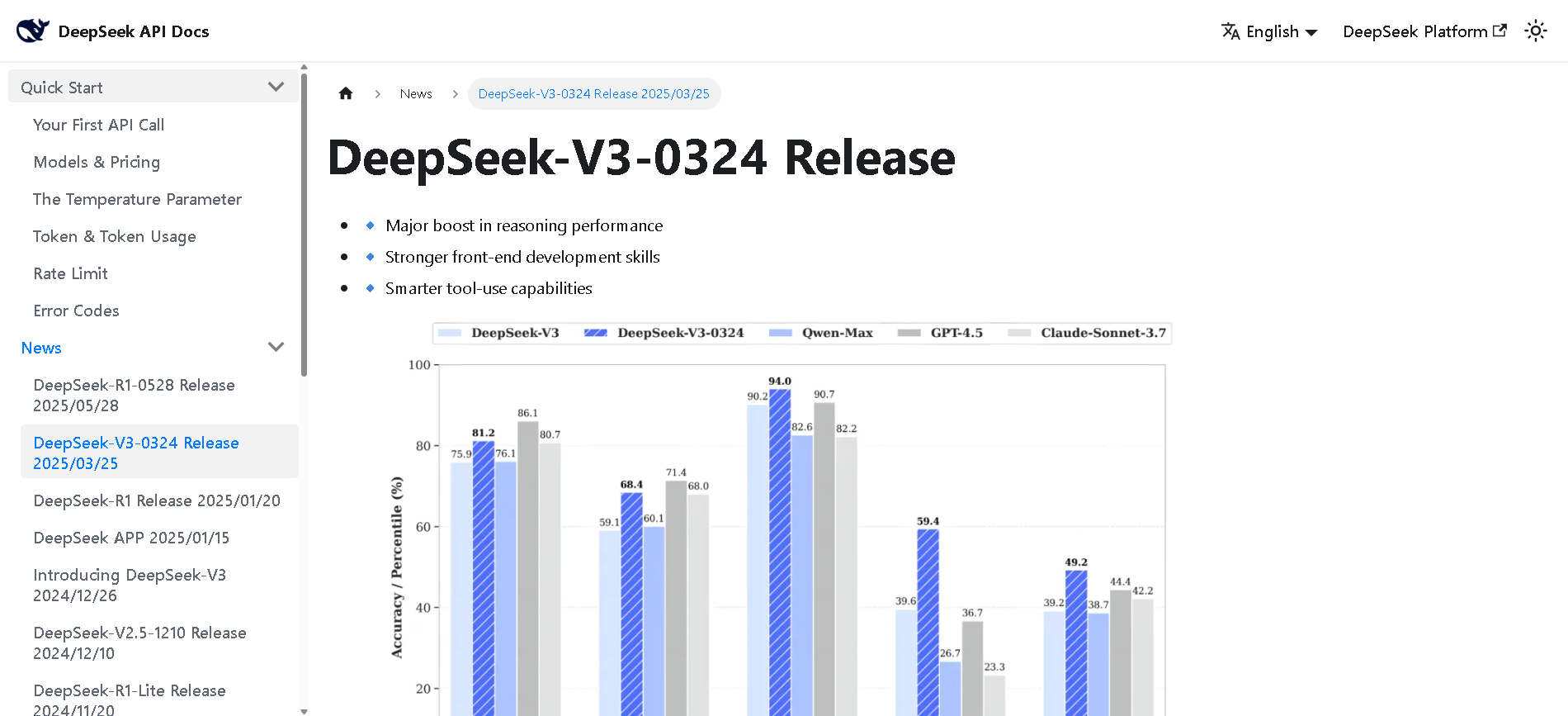
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Llama 4 Maverick is Meta’s powerful mid-sized model in the Llama 4 series, released April 5, 2025. Built with a mixture-of-experts (MoE) architecture featuring 17 B active parameters (out of 400 B total) and 128 experts, it supports a 1 million-token context window and native multimodality for text and image inputs. It ranks near the top of competitive benchmarks—surpassing GPT‑4o and Gemini 2.0 Flash in reasoning, coding, and visual tasks.
Llama 4 Maverick is Meta’s powerful mid-sized model in the Llama 4 series, released April 5, 2025. Built with a mixture-of-experts (MoE) architecture featuring 17 B active parameters (out of 400 B total) and 128 experts, it supports a 1 million-token context window and native multimodality for text and image inputs. It ranks near the top of competitive benchmarks—surpassing GPT‑4o and Gemini 2.0 Flash in reasoning, coding, and visual tasks.
Llama 4 Maverick is Meta’s powerful mid-sized model in the Llama 4 series, released April 5, 2025. Built with a mixture-of-experts (MoE) architecture featuring 17 B active parameters (out of 400 B total) and 128 experts, it supports a 1 million-token context window and native multimodality for text and image inputs. It ranks near the top of competitive benchmarks—surpassing GPT‑4o and Gemini 2.0 Flash in reasoning, coding, and visual tasks.

DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.

DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.

DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
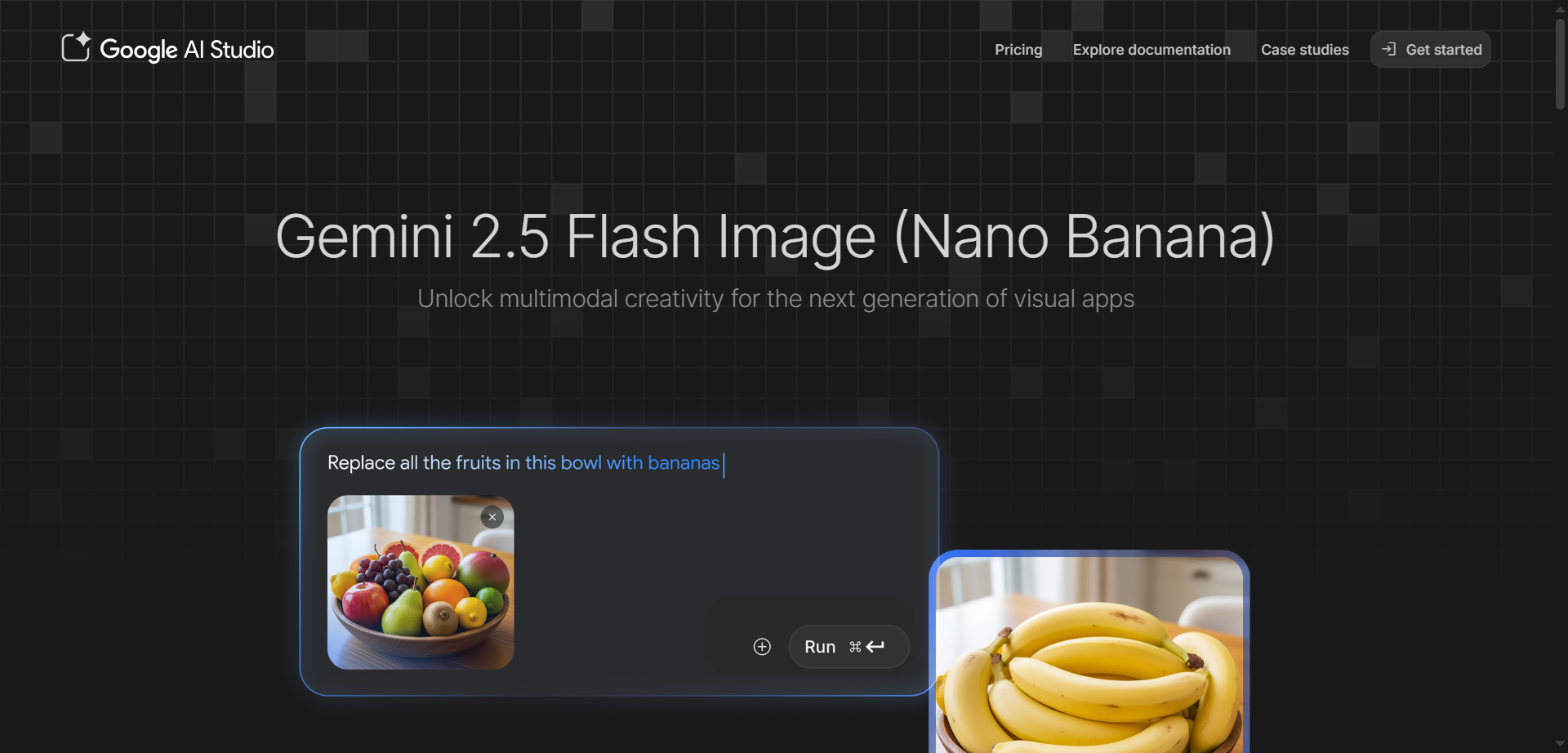

Nano Banana
Gemini 2.5 Flash Image is Google's state-of-the-art AI image generation and editing model, nicknamed Nano Banana, designed for fast, high-quality creative workflows. It excels at blending multiple images into seamless compositions, maintaining character consistency across scenes, and making precise edits through natural language prompts like blurring backgrounds or changing poses. Accessible via Google AI Studio and Gemini API, it leverages Gemini's world knowledge for realistic transformations, style transfers, and conversational refinements without restarting from scratch. Developers love its low latency, token-based pricing at about $0.039 per image, and SynthID watermarking for easy AI identification. Perfect for product mockups, storytelling, education tools, and professional photo editing.
Nano Banana
Gemini 2.5 Flash Image is Google's state-of-the-art AI image generation and editing model, nicknamed Nano Banana, designed for fast, high-quality creative workflows. It excels at blending multiple images into seamless compositions, maintaining character consistency across scenes, and making precise edits through natural language prompts like blurring backgrounds or changing poses. Accessible via Google AI Studio and Gemini API, it leverages Gemini's world knowledge for realistic transformations, style transfers, and conversational refinements without restarting from scratch. Developers love its low latency, token-based pricing at about $0.039 per image, and SynthID watermarking for easy AI identification. Perfect for product mockups, storytelling, education tools, and professional photo editing.
Nano Banana
Gemini 2.5 Flash Image is Google's state-of-the-art AI image generation and editing model, nicknamed Nano Banana, designed for fast, high-quality creative workflows. It excels at blending multiple images into seamless compositions, maintaining character consistency across scenes, and making precise edits through natural language prompts like blurring backgrounds or changing poses. Accessible via Google AI Studio and Gemini API, it leverages Gemini's world knowledge for realistic transformations, style transfers, and conversational refinements without restarting from scratch. Developers love its low latency, token-based pricing at about $0.039 per image, and SynthID watermarking for easy AI identification. Perfect for product mockups, storytelling, education tools, and professional photo editing.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai