
- Developers & Engineers: Integrate high-quality reasoning and coding LLMs without MoE complexity in your apps.
- Researchers & Students: Explore distilled chain-of-thought behaviors in smaller models with open access.
- Enterprises & Startups: Deploy efficient yet capable reasoning models in production systems.
- Open-Source Advocates: Utilize, adapt, and redistribute under permissive MIT licensing.
- Benchmarkers: Compare across sizes and capacities in math, coding, and reasoning challenges.
How to Use DeepSeek R1 Distill Qwen-32B?
- Load the Model: Available via Hugging Face (`deepseek-ai/DeepSeek-R1-Distill-Qwen-32B`) with MIT license.
- Deploy Locally or in Cloud: Use vLLM (`serve deepseek-ai/...`), SGLang, Ollama, or Hugging Face tools.
- Use Chain-of-Thought Prompts: Include step-by-step directives and use temperature 0.5–0.7 to maximize quality.
- Provide Up to 32K Tokens: Supports long contexts for coding, math, and complex reasoning.
- Quantize as Needed: Choose Q80 / Q4K formats (e.g. GGUF) to fit hardware constraints.
- Superior to o1-mini: Outperforms OpenAI’s dense 32B model across key reasoning benchmarks.
- Context Window Scalability: Built on Qwen 2.5 base with up to 32K tokens support.
- Efficient Deployment: Works well on consumer and server GPUs; quantized variants support lower-VRAM setups.
- Open-Source & Permissive: MIT licensed with derivations from Apache 2.0 base—no restrictive licensing.
- Top-tier dense reasoning performance
- Open-source with flexible licensing
- Deployable via popular frameworks
- Supports quantization for hardware efficiency
- Large context size supports complex tasks
- Lacks multimodal or MoE-level context window
- Some users report code-generation edge cases vs specialized coder models.
- GGUF variants may exhibit loading issues on certain platforms.
- Smaller distilled variants (14B and below) show noticeable drop-off in quality.
Custom
Custom
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
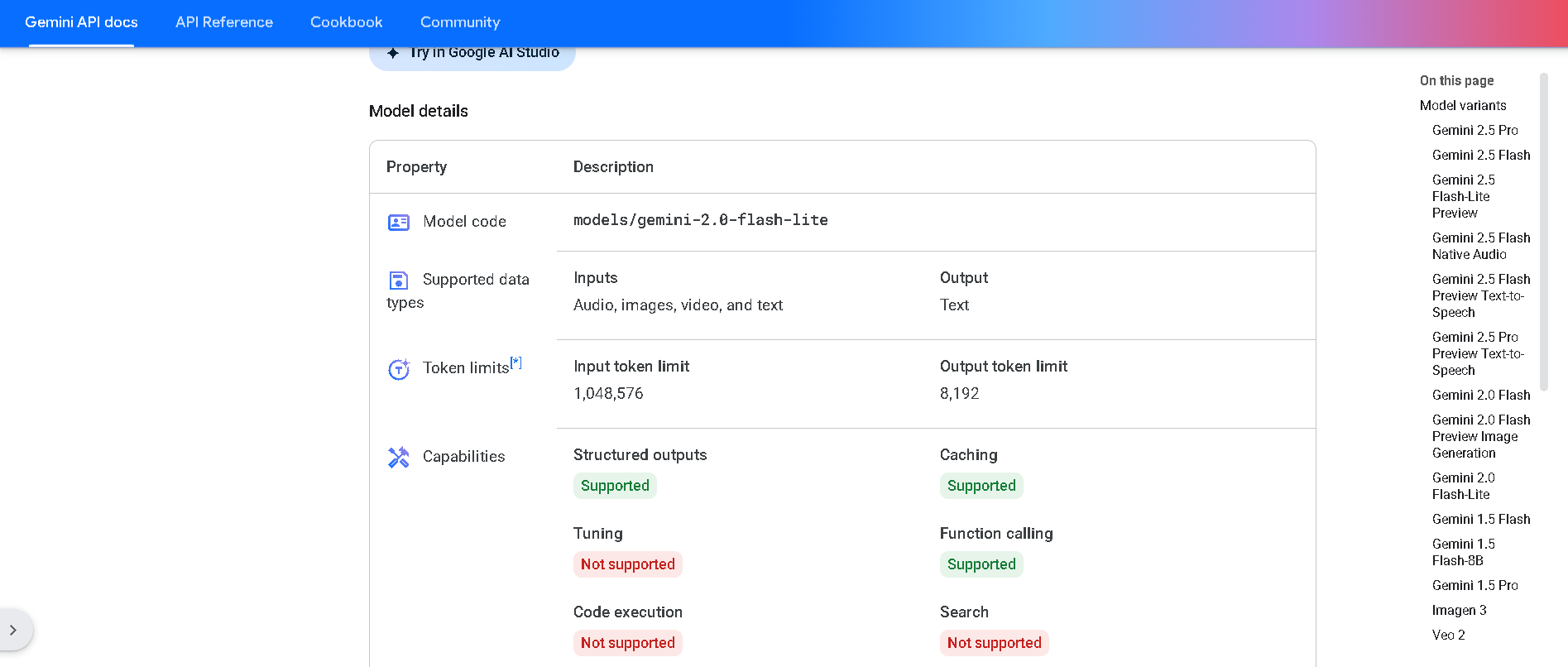
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
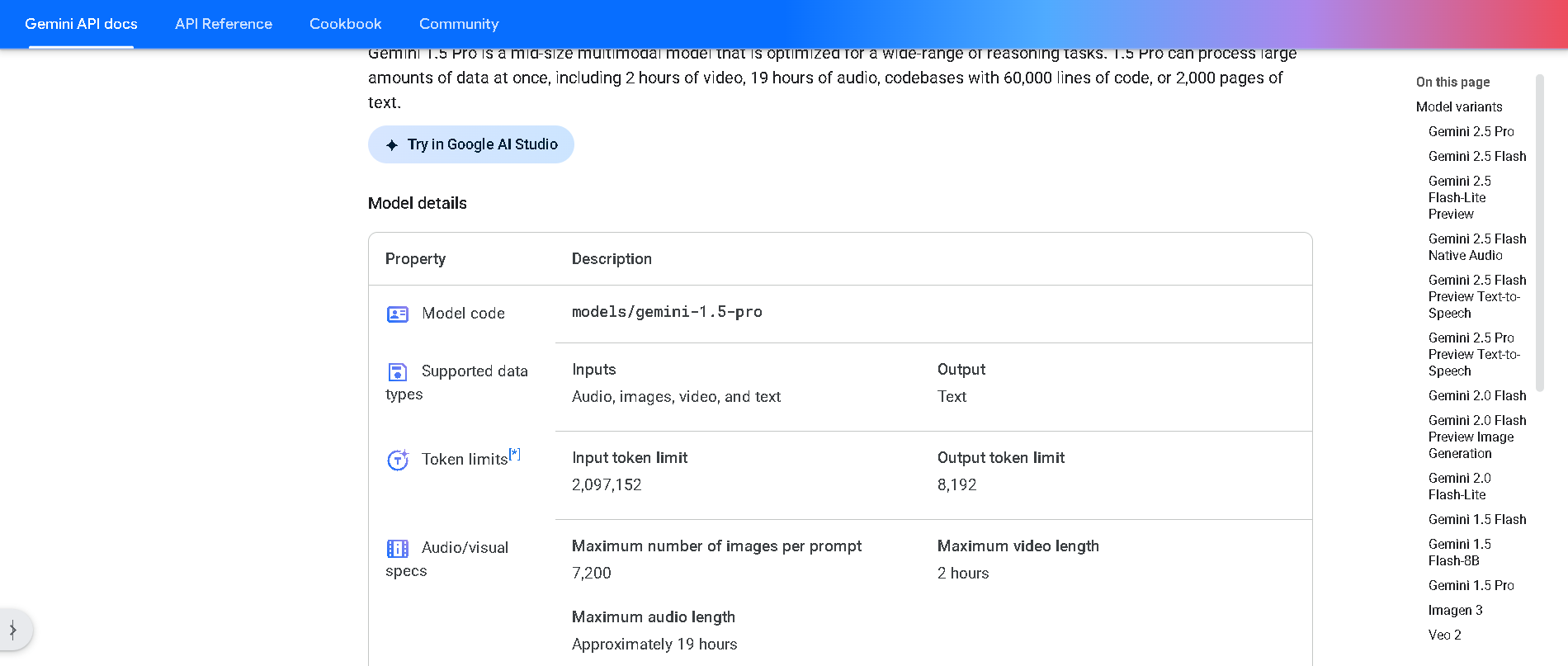

Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
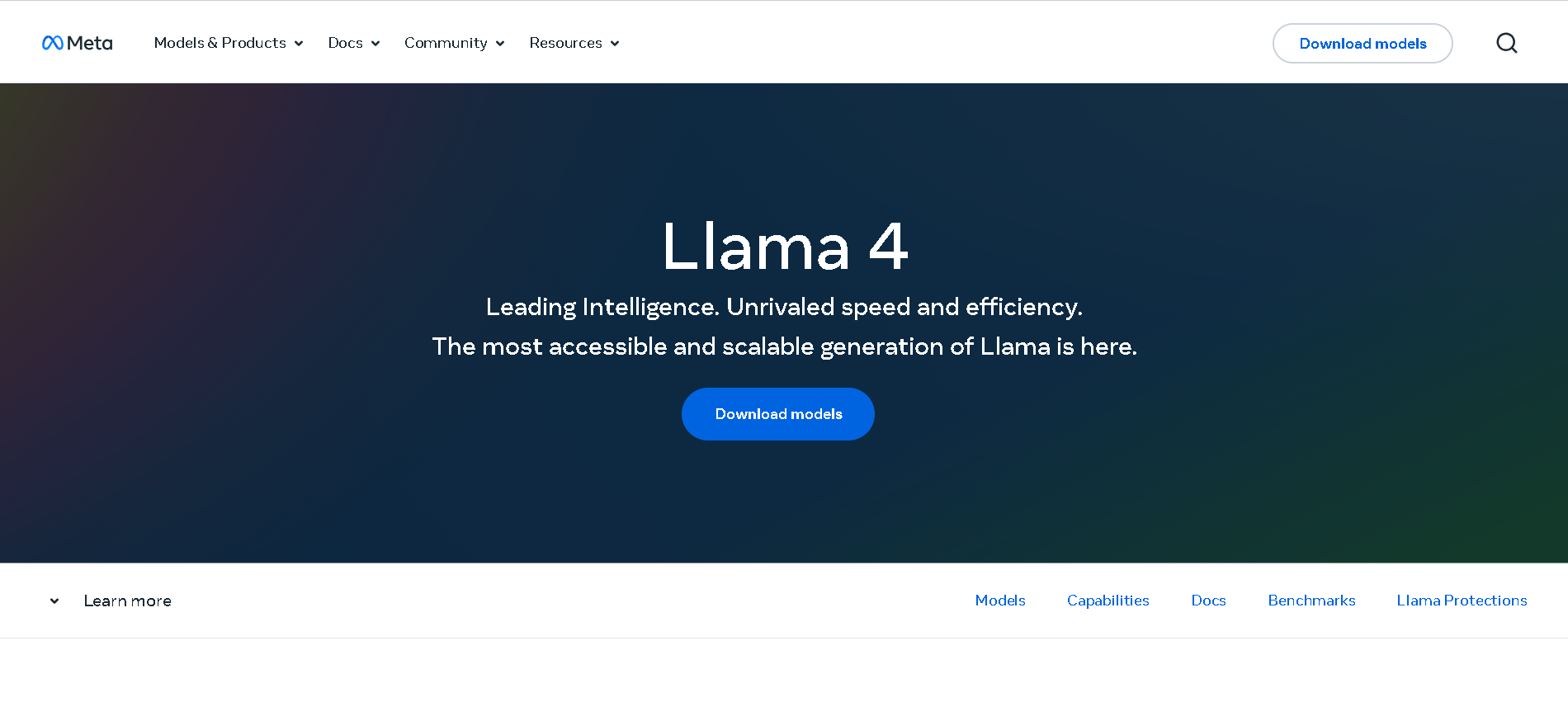

Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
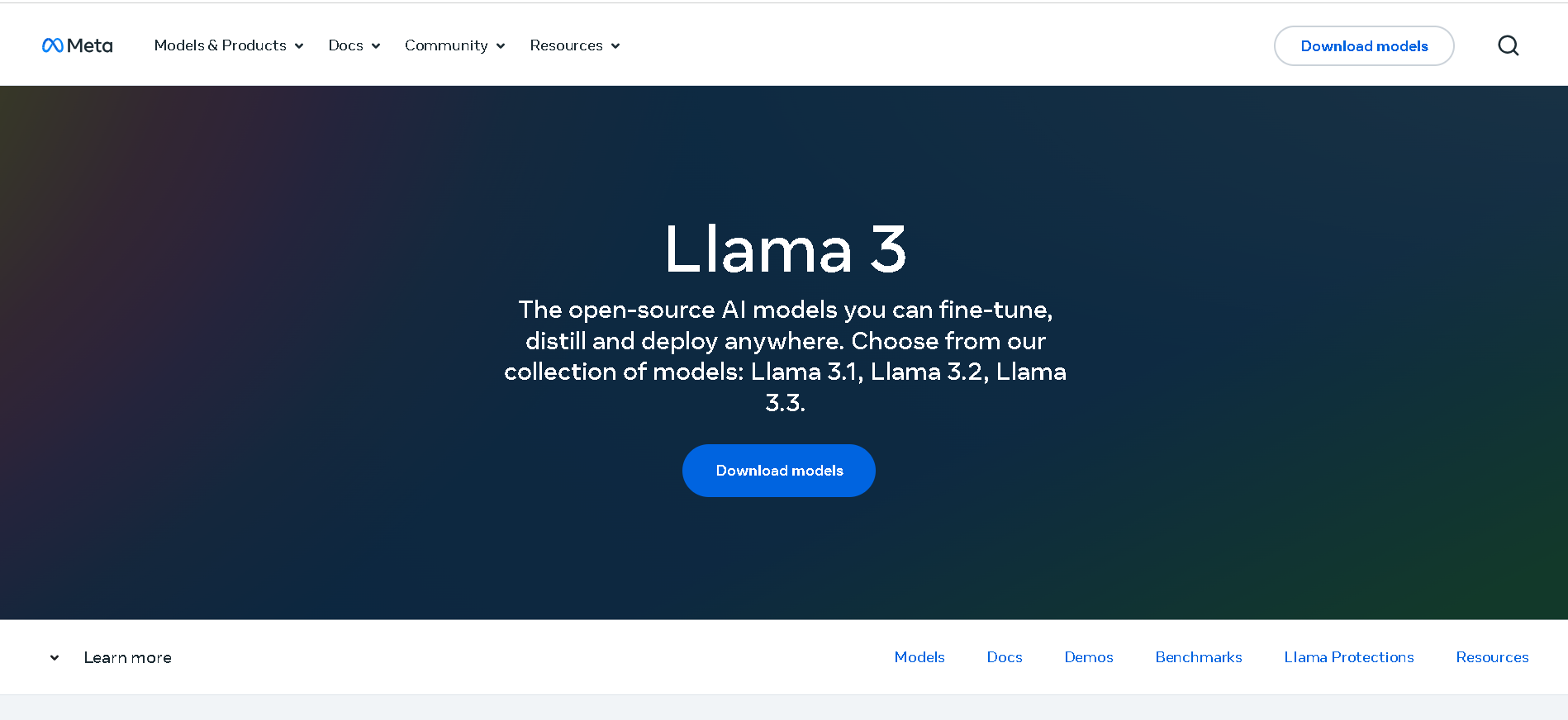

Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.

Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.
Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.
Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.

grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.
grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.
grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.

Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.

Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Meta Llama 3.2
Llama 3.2 is Meta’s multimodal and lightweight update to its Llama 3 line, released on September 25, 2024. The family includes 1B and 3B text-only models optimized for edge devices, as well as 11B and 90B Vision models capable of image understanding. It offers a 128K-token context window, Grouped-Query Attention for efficient inference, and opens up on-device, private AI with strong multilingual (e.g. Hindi, Spanish) support.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.

Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai