- Researchers & Academics: Study transparent multi-step reasoning and RL-enhanced inference.
- Developers & Engineers: Integrate logic-driven models into applications—like simulators or decision-tree systems.
- Business & Finance Teams: Automate risk assessments, forecasting, and structured calculations with auditability.
- Legal & Compliance Experts: Use traceable reasoning to meet regulatory and audit requirements.
- Content Creators & Strategists: Apply rigorous logic to storytelling, planning, or strategy briefs.
- Multilingual Teams: Reason accurately in English, French, Spanish, German, Italian, Arabic, Russian, Chinese, and more.
How to Use Magistral?
- Choose Your Variant: Use Magistral Small (24B, open-source Apache 2.0) or Magistral Medium (enterprise version).
- Deploy It: Load Small via Hugging Face or Ollama (supports 128K context, recommended up to 39–40K). Medium available via Le Chat and API, and planned for cloud platforms.
- Activate “Think” Mode: Medium supports Flash Answers in Le Chat—delivering reasoning 10× faster.
- Provide Prompts: Include multi-step logic or domain-specific tasks—chain-of-thought is natively tagged and traceable.
- Receive Reasoned Outputs: Answers come with step-by-step transparent reasoning you can audit.
- Transparent Chain-of-Thought: Clearly tagged `
... ` reasoning steps for auditability. - Multilingual Reasoning: Native logic support in multiple languages and alphabets.
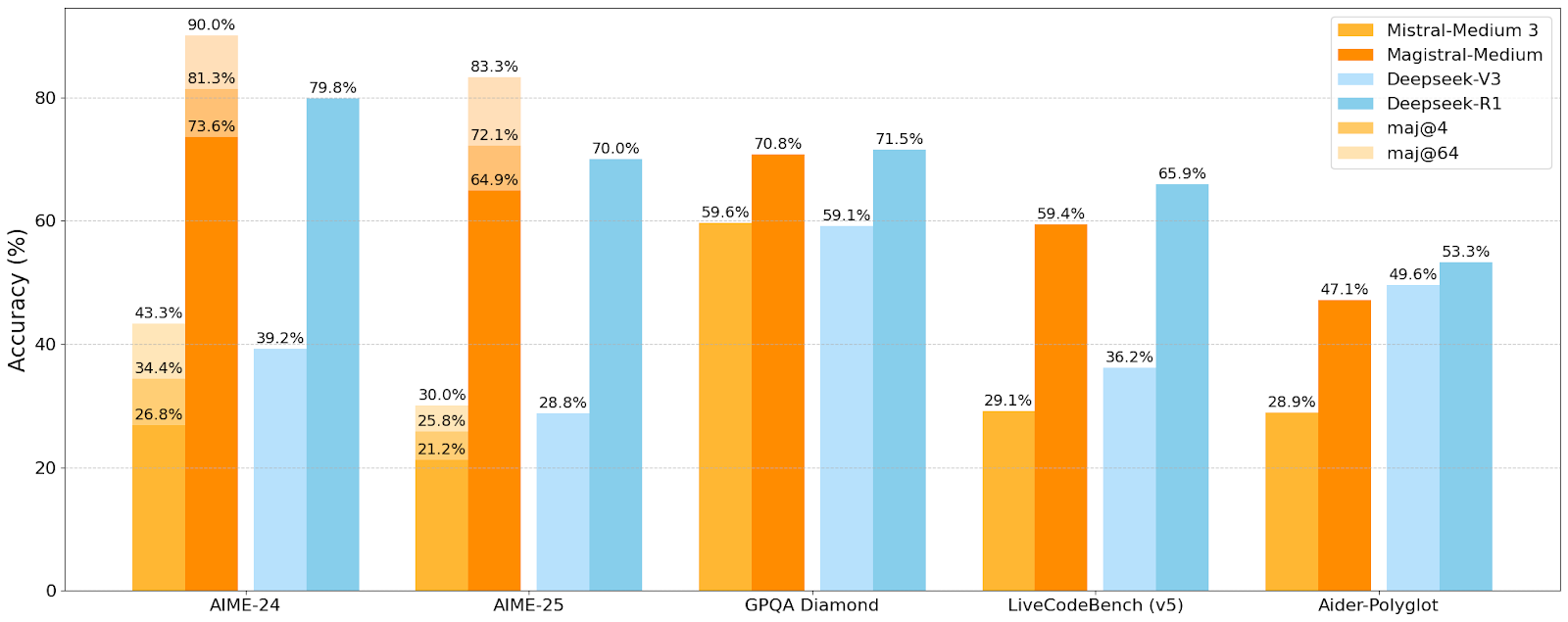
- Benchmark Strong: Medium scored 73.6% (90% with majority voting) on AIME2024; Small scored 70.7% (83.3% with voting).
- High-Speed Inference: Flash Answers enable approximately 10× faster reasoning on Medium.
- Open-Source Accessibility: Small is Apache 2.0 licensed—fully downloadable and customizable, ideal for researchers and developers.
- Full transparency—ideal for compliance-driven use cases
- Strong reasoning performance on math benchmarks
- Multilingual support across major global languages
- Flash Answers deliver low-latency reasoning
- Open-licensed Small model is accessible and modifiable
- 128K context degrades past ~40K tokens, limiting long-form tasks in Small.
- Medium remains proprietary and cloud-gated—no open weights yet.
- Focused on reasoning—less optimal for general chat or creative writing tasks

Chat
0/$14.99/$24.99 per month
Free - $0
Pro - $14.99 per month
Enterprise - $24.99 per month
API
$2/$5 per 1M tokens
Output tokens: $5.00 per 1 million tokens
Blended price (3:1 input:output): $2.75 per 1 million tokens
Significantly cheaper than many competitors for reasoning tasks
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.

DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.
DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.
DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.

Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.

DeepSeek-R1-Zero
DeepSeek R1 Zero is an open-source large language model introduced in January 2025 by DeepSeek AI. It is a reinforcement learning–only version of DeepSeek R1, trained without supervised fine-tuning. With 671B total parameters (37B active) and a 128K-token context window, it demonstrates strong chain-of-thought reasoning, self-verification, and reflection.
DeepSeek-R1-Zero
DeepSeek R1 Zero is an open-source large language model introduced in January 2025 by DeepSeek AI. It is a reinforcement learning–only version of DeepSeek R1, trained without supervised fine-tuning. With 671B total parameters (37B active) and a 128K-token context window, it demonstrates strong chain-of-thought reasoning, self-verification, and reflection.
DeepSeek-R1-Zero
DeepSeek R1 Zero is an open-source large language model introduced in January 2025 by DeepSeek AI. It is a reinforcement learning–only version of DeepSeek R1, trained without supervised fine-tuning. With 671B total parameters (37B active) and a 128K-token context window, it demonstrates strong chain-of-thought reasoning, self-verification, and reflection.

DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.

DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.

DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.

DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai