
- Developers & Engineers: Integrate state-of-the-art reasoning and function calling in chatbots, code assistants, and automation pipelines.
- Researchers & Benchmarkers: Study large-token chain-of-thought behaviors and compare performance on open-source models.
- Enterprises & API Users: Deploy via DeepSeek’s API or private instances for production systems.
- Tool Makers: Utilize JSON output & function calling to build structured workflows.
- Open-Source Advocates: Use permissively licensed weights for fine-tuning or distillation.
How to Use DeepSeek R1 0528?
- Via API or Chat Website: Continue using the DeepSeek-R1 endpoint; “DeepThink” mode activates deeper reasoning.
- Download Weights: Available under MIT license on Hugging Face (`deepseek-ai/DeepSeek-R1-0528`).
- Call Features: Supports JSON output, function calling, context caching, and multi-round conversation.
- Performance Settings: Uses temperature
0.6, top_p 0.95, max gen length64K tokens. - Scale Up: Use distilled Qwen3-8B variant for lighter deployment with similar reasoning behavior.
- Benchmarks Leap: MMLU+
1 pt, GPQA Diamond jumps from71.5% to81.0%, AIME accuracy87.5%. - Deeper Reasoning Chains: Now uses ~23K tokens per reasoning step—nearly double previous depth.
- Structured Output & Functions: Supports JSON, function calling, and persistent context caching for structured applications.
- Open-Source Release: Fully MIT licensed and available for private deployment or fine-tuning.
- Significant boosts in reasoning and coding benchmarks
- Supports function calling and structured JSON output
- Reduced hallucination rates in complex tasks
- “DeepThink” mode enables deeper thought chains
- Fully open-source weights under permissive license
- Increased compute and memory demands due to deeper reasoning
- Still slightly behind OpenAI's o4‑mini in some coding benchmarks
- Distilled variants (Qwen3‑8B) may not fully match full model across all tasks
Custom
Custom
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.

Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
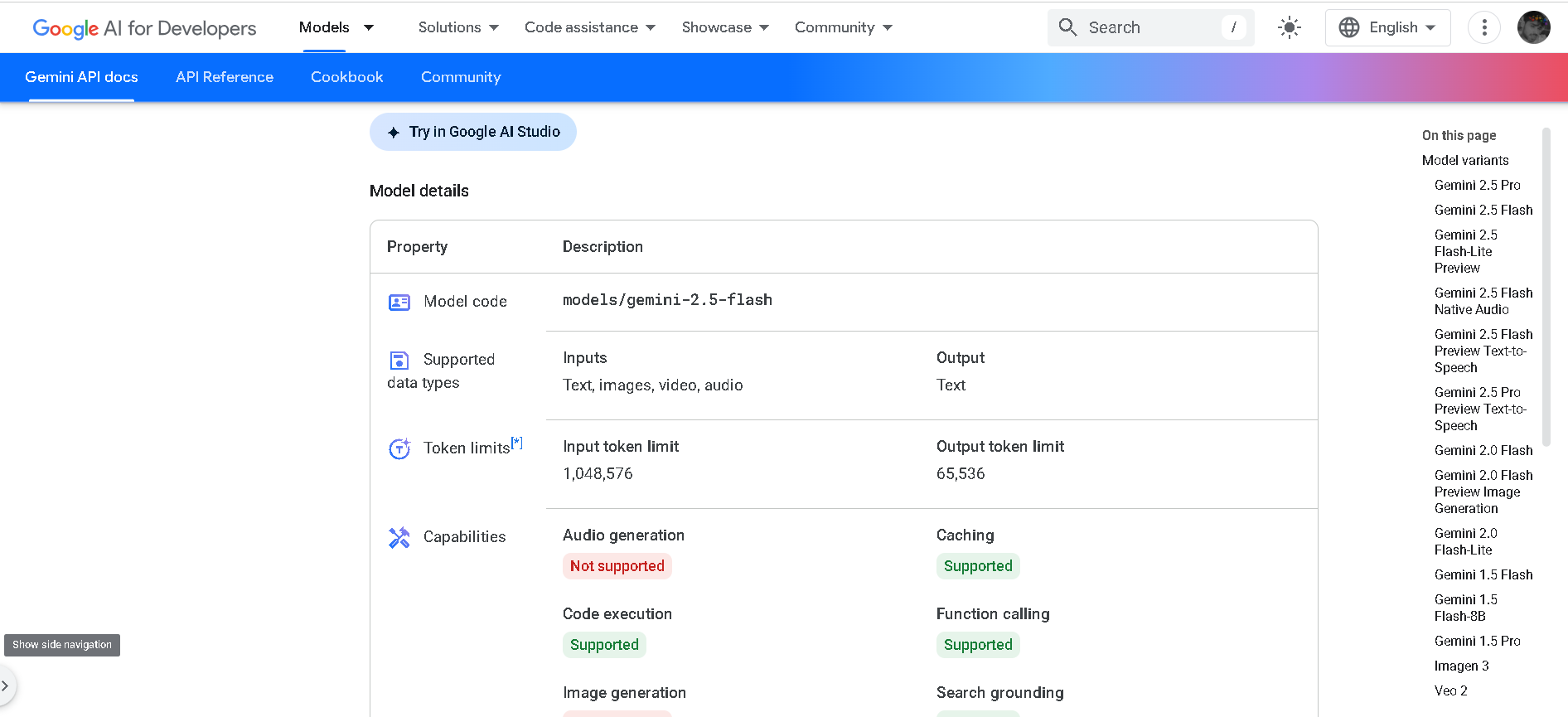

Gemini 2.5 Flash
Gemini 2.5 Flash is Google DeepMind’s cost-efficient, low-latency hybrid-reasoning model. Designed for large-scale, real-time tasks that require thinking—like classification, translation, conversational AI, and agent behaviors—it supports text, image, audio, and video input, and offers developer control over its reasoning depth. It balances high speed with strong multimodal intelligence.
Gemini 2.5 Flash
Gemini 2.5 Flash is Google DeepMind’s cost-efficient, low-latency hybrid-reasoning model. Designed for large-scale, real-time tasks that require thinking—like classification, translation, conversational AI, and agent behaviors—it supports text, image, audio, and video input, and offers developer control over its reasoning depth. It balances high speed with strong multimodal intelligence.
Gemini 2.5 Flash
Gemini 2.5 Flash is Google DeepMind’s cost-efficient, low-latency hybrid-reasoning model. Designed for large-scale, real-time tasks that require thinking—like classification, translation, conversational AI, and agent behaviors—it supports text, image, audio, and video input, and offers developer control over its reasoning depth. It balances high speed with strong multimodal intelligence.
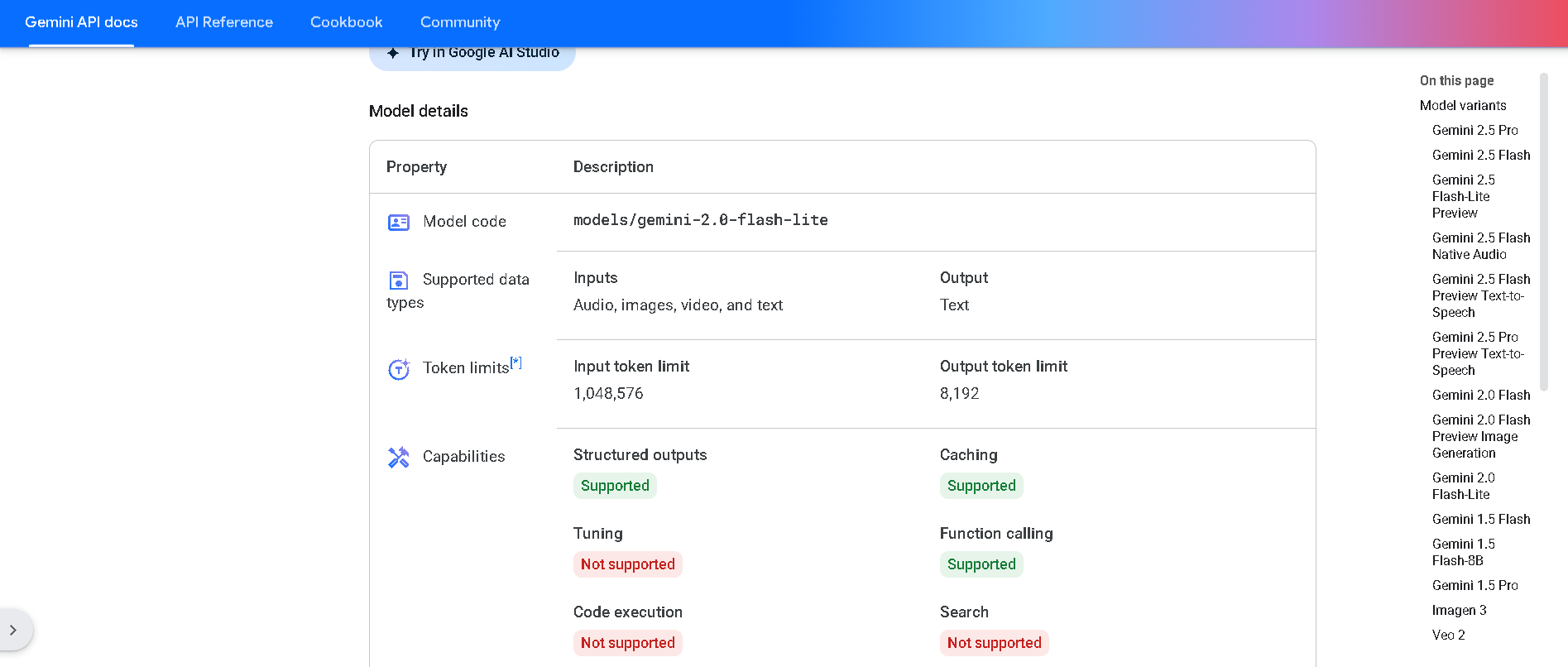
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
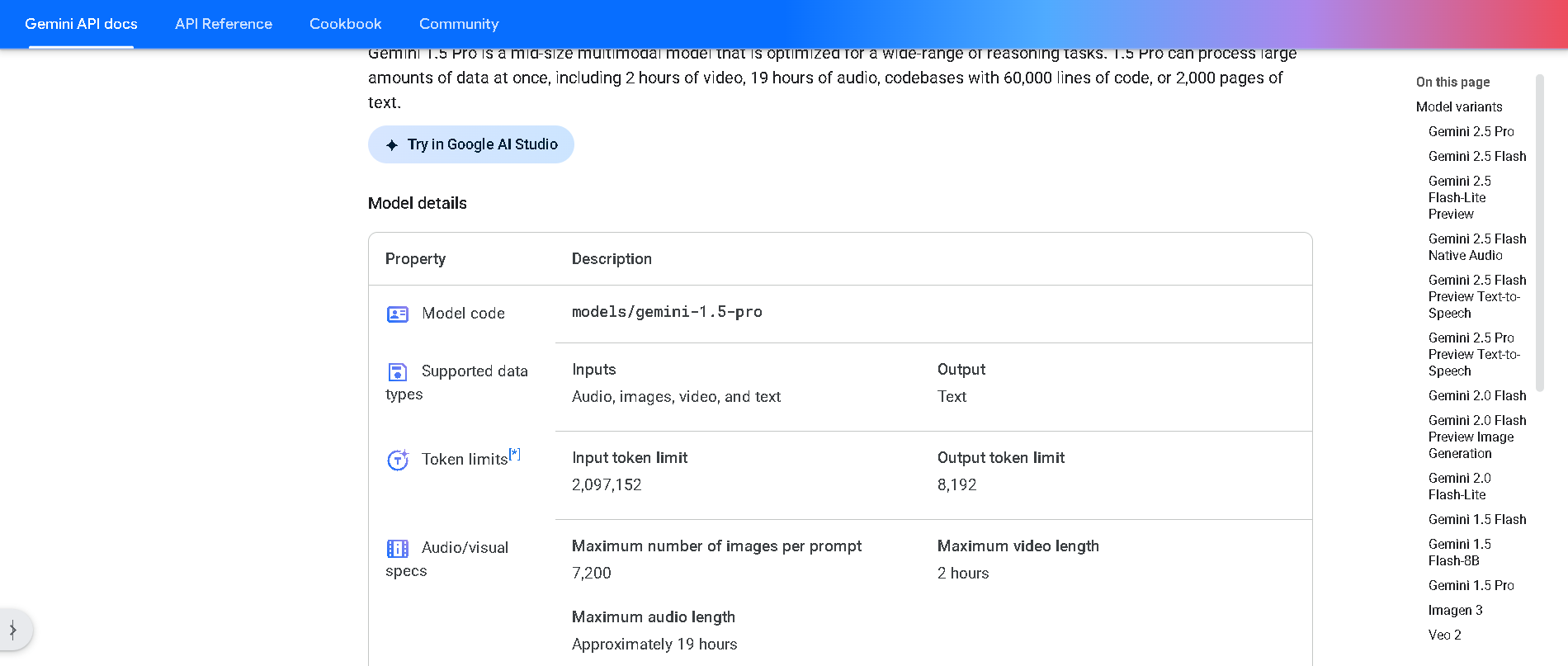

Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.

Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.

Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.
Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.
Janus-Pro-7B
anus Pro 7B is DeepSeek’s flagship open-source multimodal AI model, unifying vision understanding and text-to-image generation within a single transformer architecture. Built on DeepSeek‑LLM‑7B, it uses a decoupled visual encoding approach paired with SigLIP‑L and VQ tokenizer, delivering superior visual fidelity, prompt alignment, and stability across tasks—benchmarked ahead of OpenAI’s DALL‑E 3 and Stable Diffusion variants.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.

Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.

Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.

Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai