- General Users & Chat Enthusiasts: Engage in natural dialogue across multiple formats—text, images, voice, and video.
- Content Creators & Designers: Generate visuals, analyze documents, interpret images, or extract information from media.
- Developers & Enterprises: Build multimodal assistants with capabilities like agent behavior, tool integration, and reasoning.
- Analysts & Researchers: Perform document Q&A, chart interpretation, code debugging, or audio transcription.
- Language & Audio Users: Translate, transcribe, and analyze language, speech, and music with Qwen-Audio support.
How to Use Qwen Chat?
- Choose a Model Variant: Options include Qwen-7B-Chat, Qwen1.5-7B-Chat, Qwen2.5-Max, Qwen-VL, Qwen-Audio, and Qwen2.5-Omni, based on needed modalities.
- Access via Interface: Use the web chat platform or call via API (OpenAI-compatible) through Alibaba Cloud Model Studio.
- Provide Mixed Inputs: Send text, images, audio, or video interleaved in one conversation.
- Activate Tools & Agents: Enable reasoning ("thinking" mode), use functions or agent tools for tasks like data retrieval or translation.
- Receive Rich Outputs: Get text responses, generated images, document analysis, transcripts, or code—all in chat.
- Multimodal Mastery: Supports text, image, audio, and video in a single assistant.
- Unified Chat Experience: Conduct all modalities via one interface—no separate tools needed.
- High-End Reasoning & Tool Use: Qwen3 introduces a “thinking” mode and reasoning budget control for depth.
- Open-Source Backing: Most Qwen models are released under Apache 2.0 or similar permissive licenses.
- High Performance: Qwen2.5-Max and QwQ-32B rival top open and closed models in benchmarks for reasoning, coding, math.
- Truly multimodal—text, image, audio, and video all in one assistant
- “Thinking” mode for deeper chain-of-thought reasoning
- Open-source, widely accessible with flexible deployment
- Enterprise-ready via Alibaba Cloud API and Model Studio
- Strong performance in benchmarks for reasoning and coding
- Full multimodal capability limited by user’s chosen variant and resource access
- Some models may require high compute or cloud usage costs
- Advanced features may need Alibaba Cloud account or premium setup
Web interface
$ 0.00
Custom
Custom
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.

Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.

Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.
Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.
Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
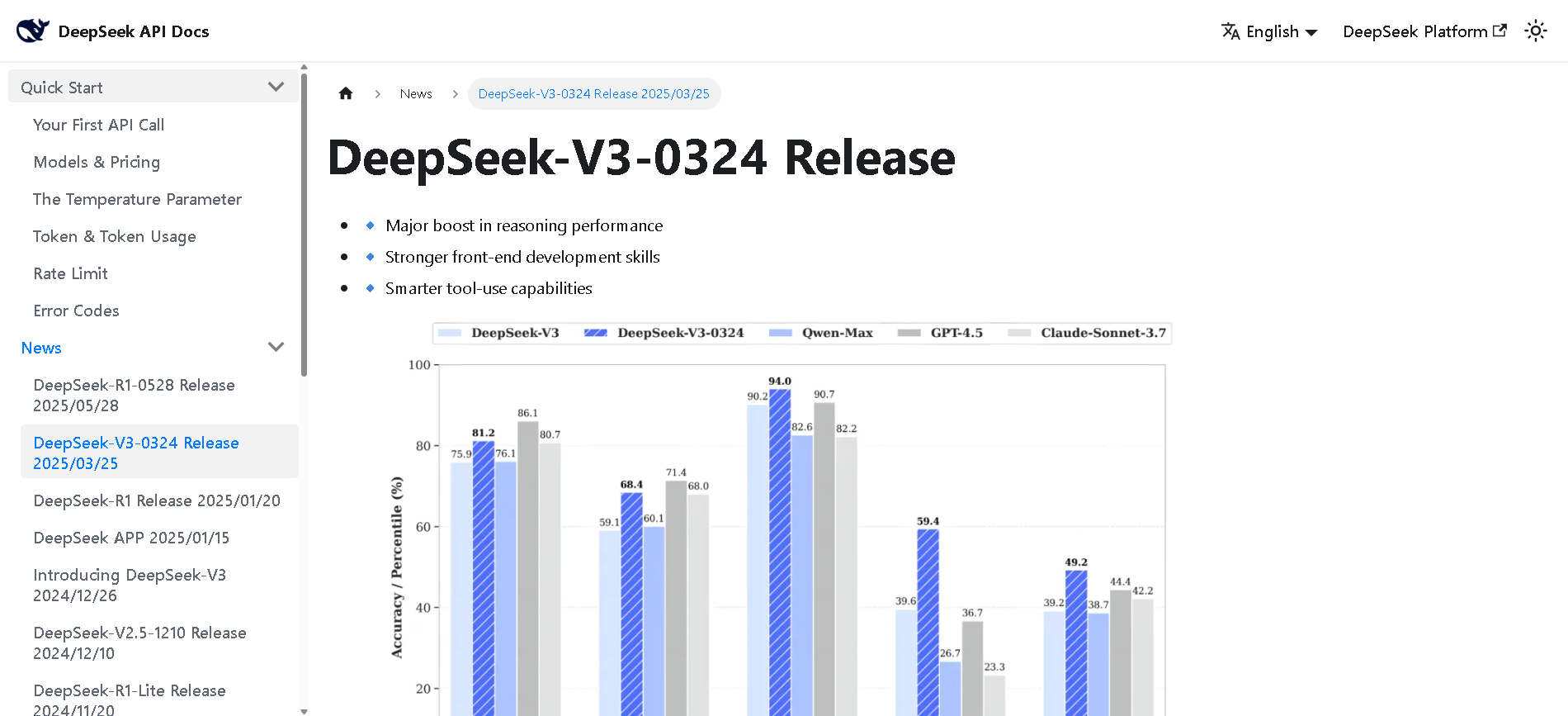
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
Llama 4 Maverick is Meta’s powerful mid-sized model in the Llama 4 series, released April 5, 2025. Built with a mixture-of-experts (MoE) architecture featuring 17 B active parameters (out of 400 B total) and 128 experts, it supports a 1 million-token context window and native multimodality for text and image inputs. It ranks near the top of competitive benchmarks—surpassing GPT‑4o and Gemini 2.0 Flash in reasoning, coding, and visual tasks.
Llama 4 Maverick is Meta’s powerful mid-sized model in the Llama 4 series, released April 5, 2025. Built with a mixture-of-experts (MoE) architecture featuring 17 B active parameters (out of 400 B total) and 128 experts, it supports a 1 million-token context window and native multimodality for text and image inputs. It ranks near the top of competitive benchmarks—surpassing GPT‑4o and Gemini 2.0 Flash in reasoning, coding, and visual tasks.
Llama 4 Maverick is Meta’s powerful mid-sized model in the Llama 4 series, released April 5, 2025. Built with a mixture-of-experts (MoE) architecture featuring 17 B active parameters (out of 400 B total) and 128 experts, it supports a 1 million-token context window and native multimodality for text and image inputs. It ranks near the top of competitive benchmarks—surpassing GPT‑4o and Gemini 2.0 Flash in reasoning, coding, and visual tasks.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.

DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.

Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Chat 01 AI
Chat01.ai is a platform that offers free and unlimited chat with OpenAI 01, a new series of AI models. These models are specifically designed for complex reasoning and problem-solving in areas such as science, coding, and math, by employing a "think more before responding" approach, trying different strategies, and recognizing mistakes.
Chat 01 AI
Chat01.ai is a platform that offers free and unlimited chat with OpenAI 01, a new series of AI models. These models are specifically designed for complex reasoning and problem-solving in areas such as science, coding, and math, by employing a "think more before responding" approach, trying different strategies, and recognizing mistakes.
Chat 01 AI
Chat01.ai is a platform that offers free and unlimited chat with OpenAI 01, a new series of AI models. These models are specifically designed for complex reasoning and problem-solving in areas such as science, coding, and math, by employing a "think more before responding" approach, trying different strategies, and recognizing mistakes.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
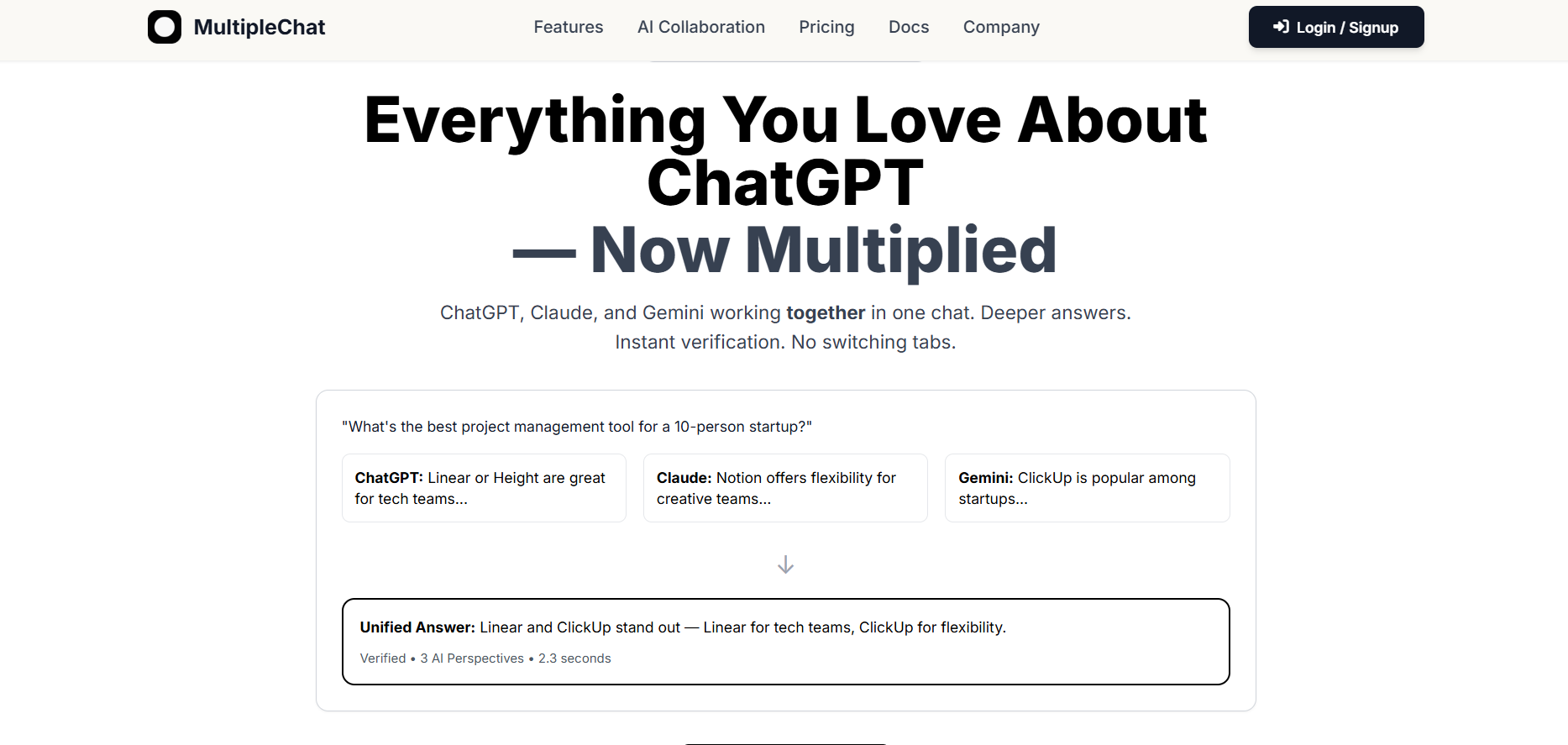
Multiple Chat
Multiple is a multi-model AI chat platform that allows users to interact with several leading AI models within a single interface. By combining responses from different AI systems, it enables deeper exploration, comparison, and verification of answers without switching tabs. The platform is designed for users who rely heavily on conversational AI and want improved accuracy, broader perspectives, and more confident outputs.
Multiple Chat
Multiple is a multi-model AI chat platform that allows users to interact with several leading AI models within a single interface. By combining responses from different AI systems, it enables deeper exploration, comparison, and verification of answers without switching tabs. The platform is designed for users who rely heavily on conversational AI and want improved accuracy, broader perspectives, and more confident outputs.
Multiple Chat
Multiple is a multi-model AI chat platform that allows users to interact with several leading AI models within a single interface. By combining responses from different AI systems, it enables deeper exploration, comparison, and verification of answers without switching tabs. The platform is designed for users who rely heavily on conversational AI and want improved accuracy, broader perspectives, and more confident outputs.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai