
- Developers & Engineers: Build high-performance multimodal applications—code assistants, visual Q&A, document agents.
- Analysts & Researchers: Analyze long documents, charts, or code with deep contextual understanding.
- Enterprises & SMEs: Deploy open-weight AI with flagship-level capabilities for varied tasks.
- Content Creators & Designers: Generate images, captions, and text-based outputs in one pipeline.
- Multilingual Applications: Ideal for global deployments with support across multiple languages.
How to Use Llama 4 Maverick?
- Access via Platforms: Available on Hugging Face, Meta’s Llama.com, Databricks, AWS/Azure/GCP, and other enterprise providers.
- Send Mixed Inputs: Submit text and image prompts together (up to 1 million tokens context) via supported APIs.
- Optimizer Support: Includes fp8/BF16 and quantization for efficient deployment on H100 hardware.
- Deploy Locally or in Cloud: Runs on H100 DGX systems, available in enterprise cloud environments.
- Manage Cost: Approximately $0.19–$0.49 per million tokens, offering high performance at a lower price than closed-source alternatives.
- Native Multimodality: Processes text and images jointly using early-fusion training.
- Ultra-Long Context: 1 million-token window supports massive documents and complex workflows.
- Efficient MoE Design: Activates only a subset of experts per token, delivering cost-effective inference.
- Open-Weight & Flexible: Released under community license with cloud and local deployment support.
- Top-tier multimodal reasoning, coding, and visual understanding
- Massive 1 M-token context window ideal for large tasks
- Cost-effective token pricing compared to closed models
- Supports cloud and on-premise deployment with efficiency
- Open-weight availability fosters transparency and flexibility
- Released "experimental" benchmark variant not publicly available—raised transparency concerns
- Mixed user reviews—some underperformance in code and general chat vs legacy models
- MoE complexity may complicate deployment and tuning
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
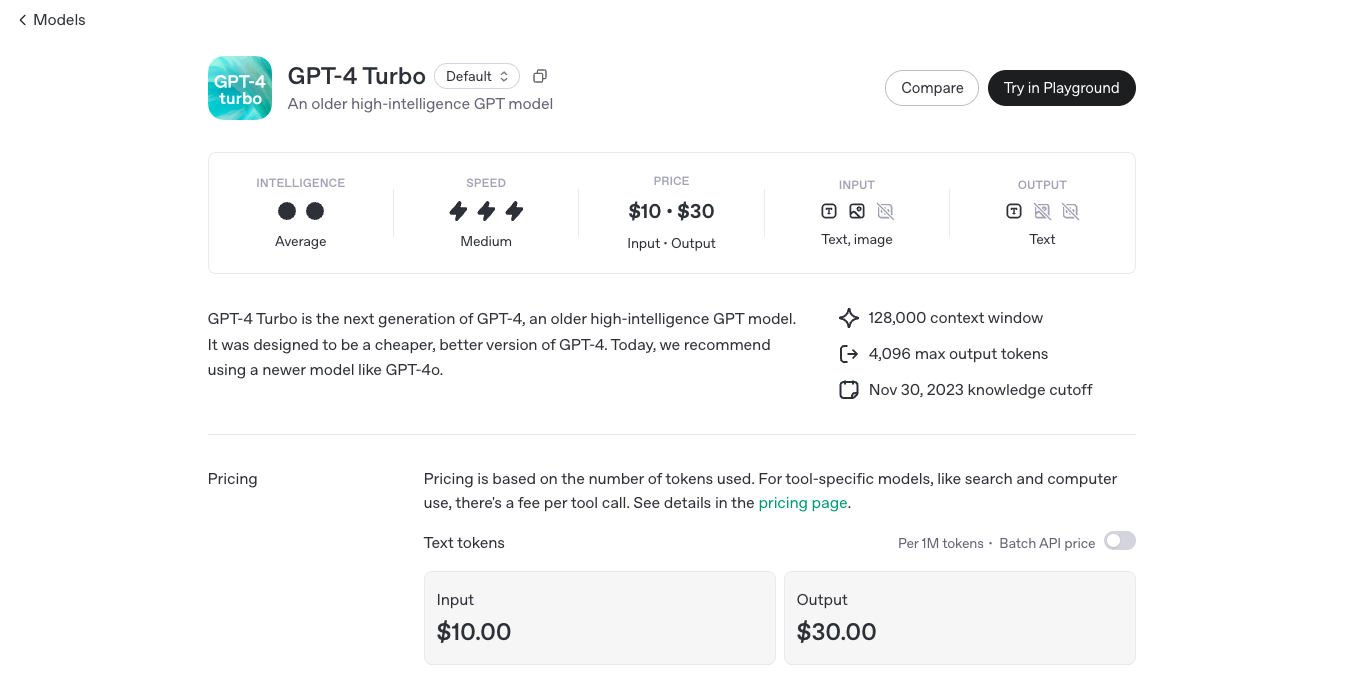
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
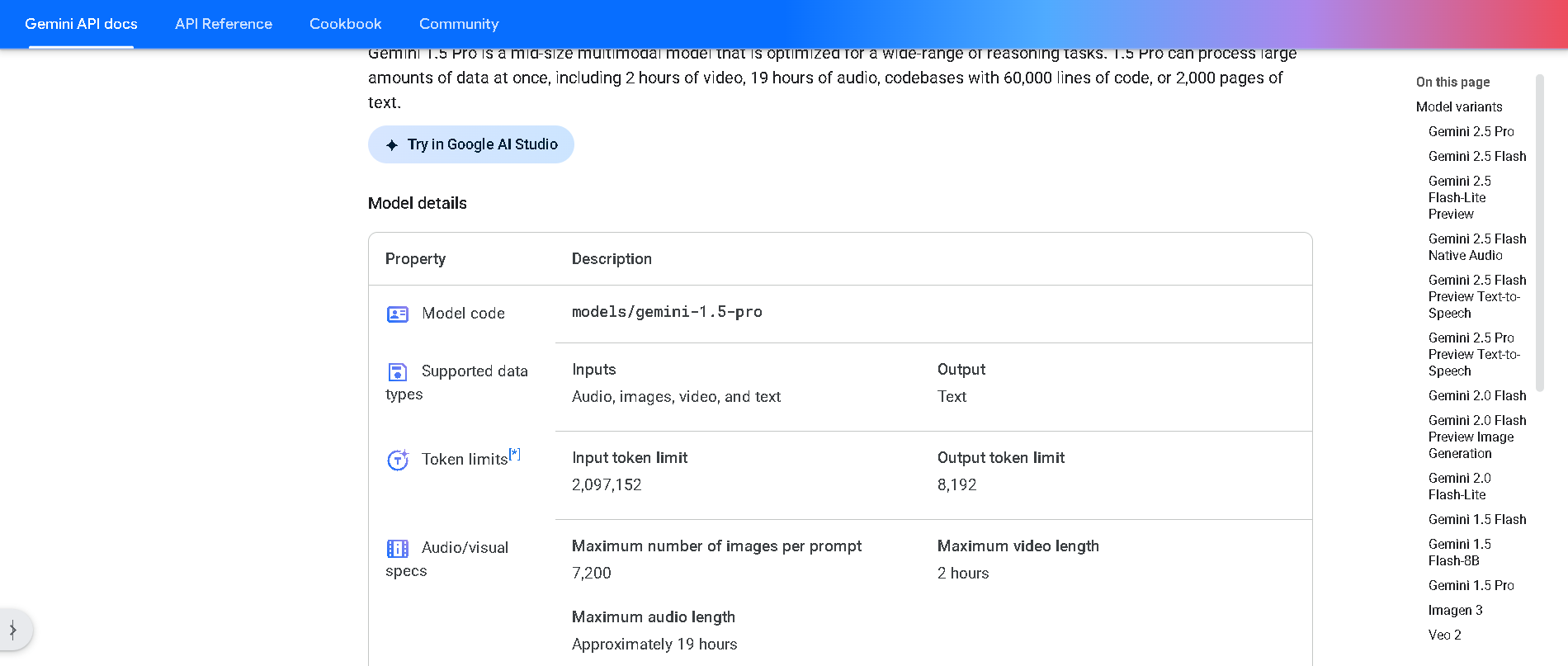

Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.

DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.

Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Grok 4
Grok 4 is the latest and most intelligent AI model developed by xAI, designed for expert-level reasoning and real-time knowledge integration. It combines large-scale reinforcement learning with native tool use, including code interpretation, web browsing, and advanced search capabilities, to provide highly accurate and up-to-date responses. Grok 4 excels across diverse domains such as math, coding, science, and complex reasoning, supporting multimodal inputs like text and vision. With its massive 256,000-token context window and advanced toolset, Grok 4 is built to push the boundaries of AI intelligence and practical utility for both developers and enterprises.
Grok 4
Grok 4 is the latest and most intelligent AI model developed by xAI, designed for expert-level reasoning and real-time knowledge integration. It combines large-scale reinforcement learning with native tool use, including code interpretation, web browsing, and advanced search capabilities, to provide highly accurate and up-to-date responses. Grok 4 excels across diverse domains such as math, coding, science, and complex reasoning, supporting multimodal inputs like text and vision. With its massive 256,000-token context window and advanced toolset, Grok 4 is built to push the boundaries of AI intelligence and practical utility for both developers and enterprises.
Grok 4
Grok 4 is the latest and most intelligent AI model developed by xAI, designed for expert-level reasoning and real-time knowledge integration. It combines large-scale reinforcement learning with native tool use, including code interpretation, web browsing, and advanced search capabilities, to provide highly accurate and up-to-date responses. Grok 4 excels across diverse domains such as math, coding, science, and complex reasoning, supporting multimodal inputs like text and vision. With its massive 256,000-token context window and advanced toolset, Grok 4 is built to push the boundaries of AI intelligence and practical utility for both developers and enterprises.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.
Llama Nemotron Ultra is NVIDIA’s open-source reasoning AI model engineered for deep problem solving, advanced coding, and scientific analysis across business, enterprise, and research applications. It leads open models in intelligence and reasoning benchmarks, excelling at scientific, mathematical, and programming challenges. Building on Meta Llama 3.1, it is trained for complex, human-aligned chat, agentic workflows, and retrieval-augmented generation. Llama Nemotron Ultra is designed to be efficient, cost-effective, and highly adaptable, available via Hugging Face and as an NVIDIA NIM inference microservice for scalable deployment.

polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai