
- Developers & Engineers: Build reasoning workflows, coding assistants, math solvers, or deploy via Amazon Bedrock or Hugging Face.
- Data Scientists & Analysts: Automate complex math, reasoning, or code-based analysis at scale.
- Researchers & Academics: Study reinforcement learning-first training and open-source MoE models.
- Enterprises: Use R1 in AWS Bedrock with enterprise-grade security, guardrails, and compliance.
- Open-Source Community: Download and fine-tune on Hugging Face under the MIT license; also use distilled smaller versions.
How to Use DeepSeek-R1?
- Access the Model: Use Hugging Face or its API; or deploy via Amazon Bedrock for fully managed use.
- Submit Prompts: Send tasks in math, code, reasoning—R1 includes chain-of-thought outputs by default.
- Choose Deployment Path: Pick self-hosted (open-source) or managed (Amazon Bedrock) depending on scale and compliance needs.
- Leverage Distilled Versions: Use lighter R1-Lite or distilled 1.5B–70B variants for on-device inference.
- Deploy Responsibly: Enable Bedrock Guardrails and monitor output as R1 can exhibit geopolitical bias or safety gaps.
- MoE Architecture: 671B total params but only ~37B activated per task—combining power with efficiency.
- Reinforcement-Learning-First Reasoning: R1-Zero self-learns chains of thought; R1 adds supervised fine-tuning for clarity.
- Benchmark Leader: Scores 79.8% on AIME, 97.3% MATH-500, Codeforces Elo 2029, GPQA 71.5%—matching or surpassing o1.
- Open-Source with Commercial License: MIT-licensed weight availability enables self-hosting or managed deployment.
- Cost-Effective: Inference runs at 90–95% lower cost than o1; in AWS, provides managed deployment with guardrails.
- Frontier-level reasoning on par with closed-source systems
- Chain-of-thought outputs for transparency
- Open-source nature fosters collaboration and experimentation
- Lightweight distilled variants for diverse hardware
- Managed deployment with enterprise-grade security
- Bias issues: pro-CCP content found within reasoning outputs
- Safety vulnerabilities: full safety evaluations still ongoing
- Distilled quality vs full model: trade-offs in reasoning may occur at smaller sizes
Free
Free
Cached
$0.14/$2.19 per 1M tokens
- InputL $0.14 & Ouput: $2.19
- Offpeak/Discount: $0.035 (75% off, 16:30–00:30 UTC) - Off-peak/discount pricing applies daily between 16:30 and 00:30 UTC
Uncached
$0.55/$2.19
- InputL $0.55 & Ouput: $2.19
- Offpeak/Discount: $0.135 (75% off, 16:30–00:30 UTC) - Off-peak/discount pricing applies daily between 16:30 and 00:30 UTC
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.

GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.

Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
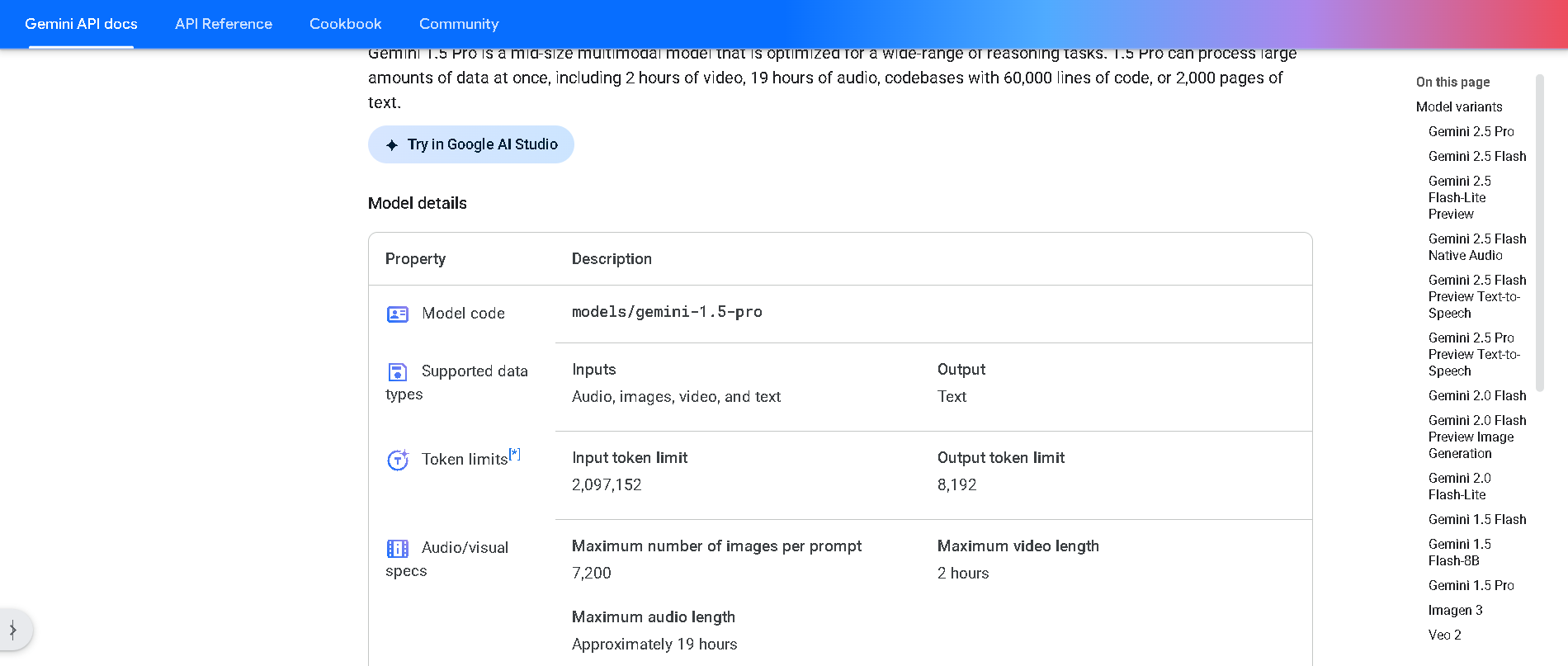

Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.
Meta Llama 3.1
Llama 3.1 is Meta’s most advanced open-source Llama 3 model, released on July 23, 2024. It comes in three sizes—8B, 70B, and 405B parameters—with an expanded 128K-token context window and improved multilingual and multimodal capabilities. It significantly outperforms Llama 3 and rivals proprietary models across benchmarks like GSM8K, MMLU, HumanEval, ARC, and tool-augmented reasoning tasks.

Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.

Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
Soket AI
Soket AI is an Indian deep-tech startup building sovereign, multilingual foundational AI models and real-time voice/speech APIs designed for Indic languages and global scale. By focusing on language diversity, cultural context and ethical AI, Soket AI aims to develop models that recognise and respond across many languages, while delivering enterprise-grade capabilities for sectors such as defence, healthcare, education and governance.
Soket AI
Soket AI is an Indian deep-tech startup building sovereign, multilingual foundational AI models and real-time voice/speech APIs designed for Indic languages and global scale. By focusing on language diversity, cultural context and ethical AI, Soket AI aims to develop models that recognise and respond across many languages, while delivering enterprise-grade capabilities for sectors such as defence, healthcare, education and governance.
Soket AI
Soket AI is an Indian deep-tech startup building sovereign, multilingual foundational AI models and real-time voice/speech APIs designed for Indic languages and global scale. By focusing on language diversity, cultural context and ethical AI, Soket AI aims to develop models that recognise and respond across many languages, while delivering enterprise-grade capabilities for sectors such as defence, healthcare, education and governance.

polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai