
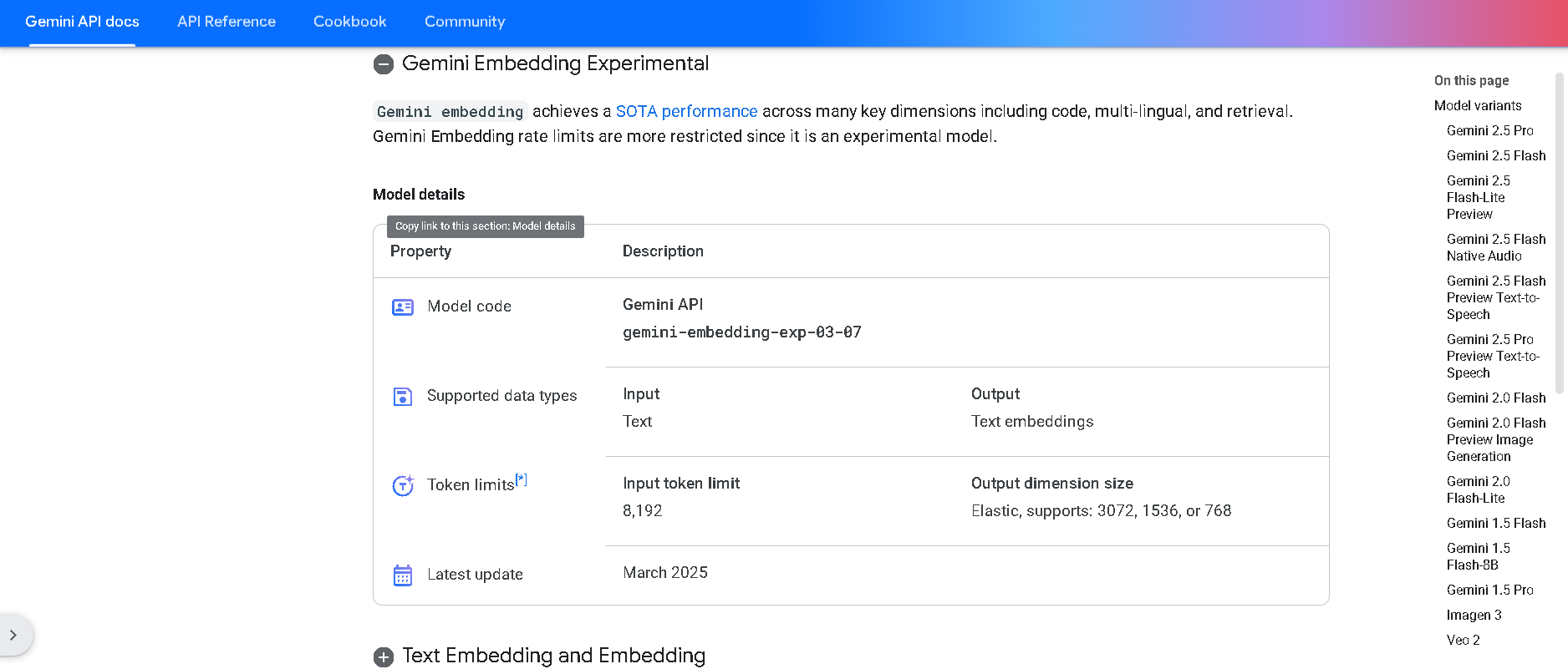
- Developers & Engineers: Build semantic search, RAG (Retrieval-Augmented Generation), recommendation systems, and clustering pipelines.
- Data Scientists: Use it for large-scale text or code similarity analysis, classification, or grouping.
- Product Teams: Power intelligent features like semantic search, content deduplication, and topic grouping.
- Enterprises: Apply embeddings for multilingual search, internal knowledge retrieval, and compliance.
- Researchers & Academics: Analyze cross-lingual data, evaluate semantics, or improve embedding quality in downstream research.
How to Use Gemini Embedding?
- Access via Gemini API or Vertex AI: Use model ID `gemini-embedding-exp-03-07` on the `embed_content` endpoint.
- Send Text or Code Input: Supports up to 8,000 tokens per request.
- Choose Task Type: Specify `SEMANTICSIMILARITY`, `CLASSIFICATION`, `CLUSTERING`, or `RETRIEVAL*` to fine-tune embedding behavior.
- Receive High-Dimensional Vectors: Outputs 3K-dimensional embeddings, with optional Matryoshka truncation for efficiency.
- Integrate Into Pipelines: Use in RAG, vector databases, clustering engines, or ML applications.
- Top Benchmark Performance: Achieves a mean score of 68.32 on MMTEB multilingual, +5.8 over the next best model.
- Multimodal & Multilingual: Supports over 100 languages, text and code input, and long-form inputs up to 8K tokens.
- High-Dimensional Embeddings: Outputs 3,072-dimension vectors, with Matryoshka Representation for storage flexibility.
- Unified vs. Specialized: One model surpasses task-specific embedding models—no need for separate variants per domain.
- Experimental Early Access: Developers can begin using it now via API, with stable GA release planned soon.
- Leading performance on global embedding benchmarks
- Handles long, complex inputs—up to 8,000 tokens
- High-dimensional vectors with flexible truncation
- Multilingual and multimodal in a single model
- Supports semantic tasks directly via task-type API
- Currently in experimental phase with limited API availability
- Rich, high-dimensional embeddings may increase storage/computation cost
- Full GA release and pricing details pending
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

text-embedding-3-large is OpenAI’s most advanced embedding model designed to convert natural language text into high-dimensional vector representations. With 3,072 dimensions per embedding and cutting-edge architecture, it offers best-in-class performance for tasks like semantic search, content recommendations, clustering, classification, and more. Built to deliver top-tier semantic understanding, this model is ideal when accuracy and relevance are mission-critical. It’s the spiritual successor to text-embedding-ada-002, bringing huge improvements in contextual understanding, generalization, and relevance scoring.
text-embedding-3-large is OpenAI’s most advanced embedding model designed to convert natural language text into high-dimensional vector representations. With 3,072 dimensions per embedding and cutting-edge architecture, it offers best-in-class performance for tasks like semantic search, content recommendations, clustering, classification, and more. Built to deliver top-tier semantic understanding, this model is ideal when accuracy and relevance are mission-critical. It’s the spiritual successor to text-embedding-ada-002, bringing huge improvements in contextual understanding, generalization, and relevance scoring.
text-embedding-3-large is OpenAI’s most advanced embedding model designed to convert natural language text into high-dimensional vector representations. With 3,072 dimensions per embedding and cutting-edge architecture, it offers best-in-class performance for tasks like semantic search, content recommendations, clustering, classification, and more. Built to deliver top-tier semantic understanding, this model is ideal when accuracy and relevance are mission-critical. It’s the spiritual successor to text-embedding-ada-002, bringing huge improvements in contextual understanding, generalization, and relevance scoring.
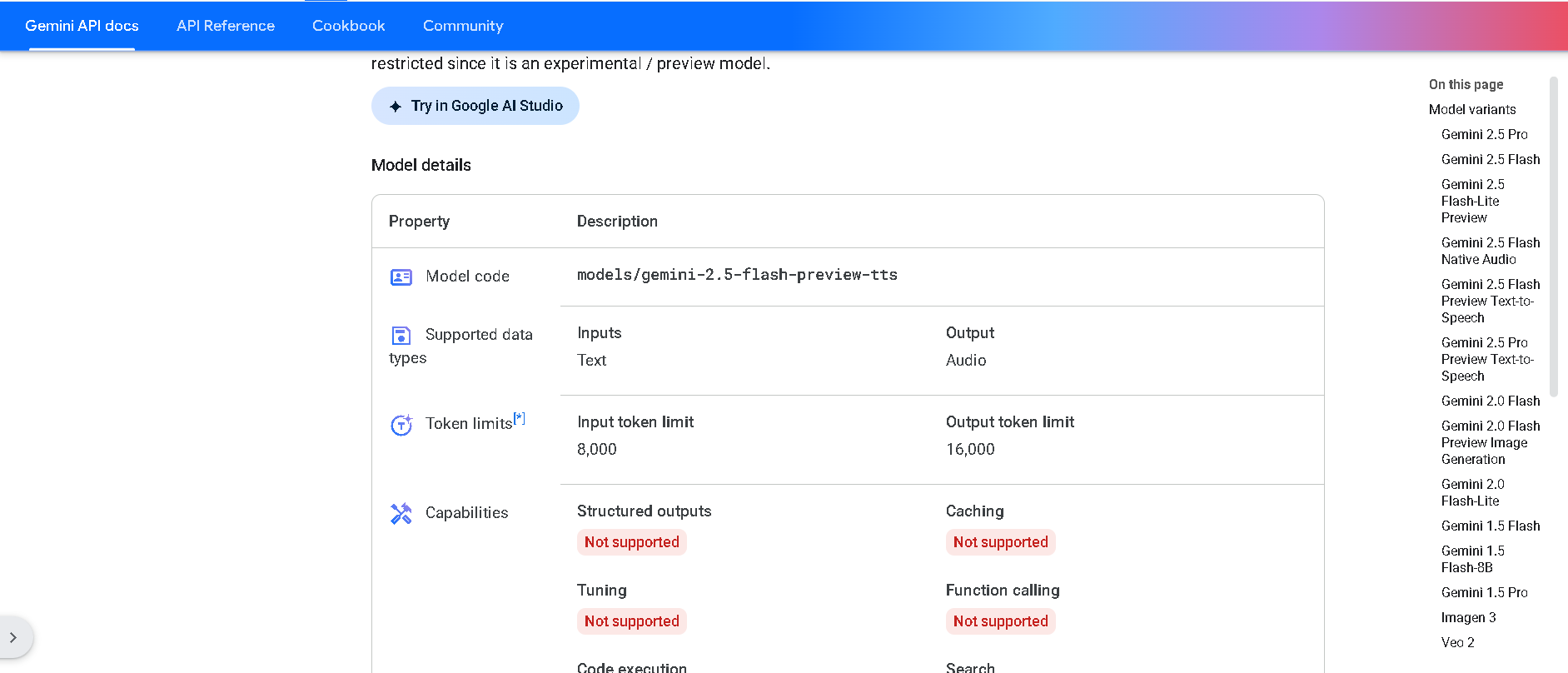
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
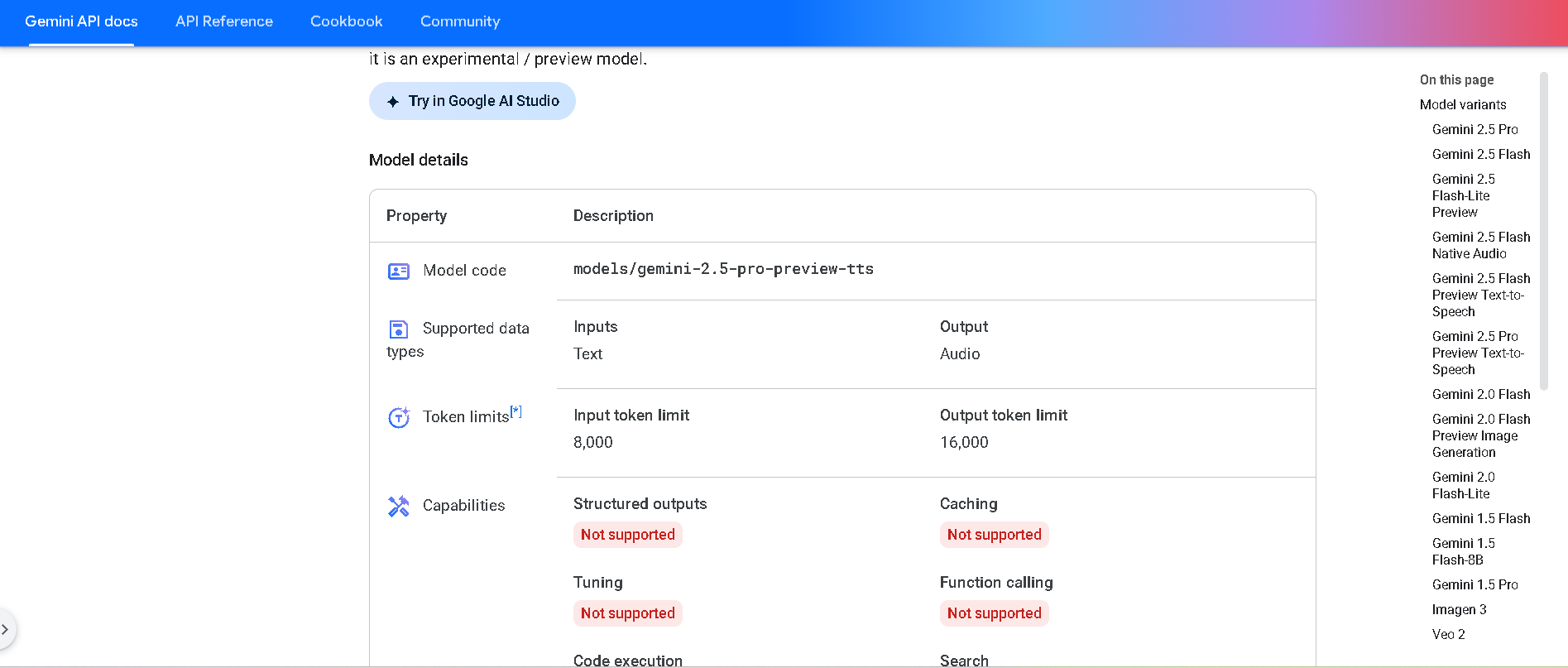
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
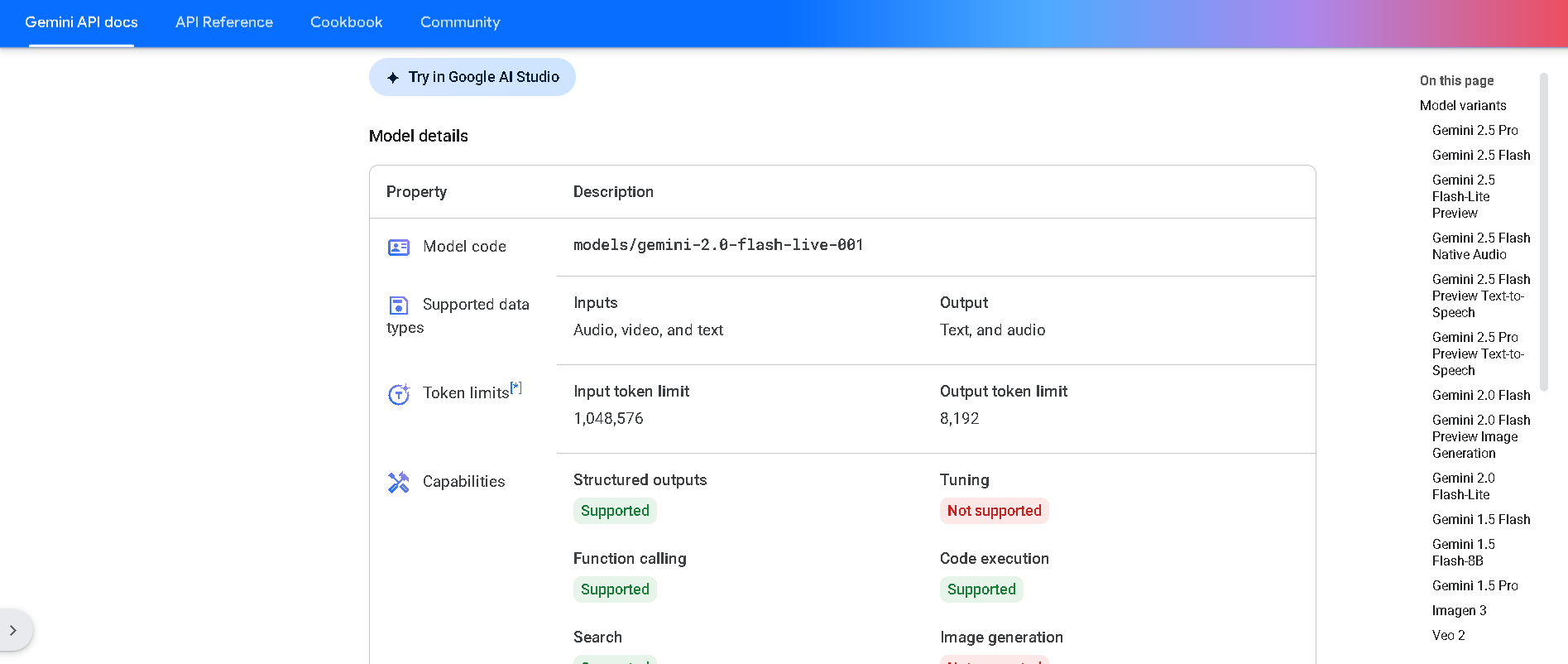
Gemini 2.0 Flash Live is Google DeepMind’s real-time, multimodal chatbot variant powered by the Live API. It supports simultaneous streaming of voice, video, and text inputs, and responds in both spoken audio and text, enabling rich, bidirectional live interactions with low latency and tool integration.
Gemini 2.0 Flash Live is Google DeepMind’s real-time, multimodal chatbot variant powered by the Live API. It supports simultaneous streaming of voice, video, and text inputs, and responds in both spoken audio and text, enabling rich, bidirectional live interactions with low latency and tool integration.
Gemini 2.0 Flash Live is Google DeepMind’s real-time, multimodal chatbot variant powered by the Live API. It supports simultaneous streaming of voice, video, and text inputs, and responds in both spoken audio and text, enabling rich, bidirectional live interactions with low latency and tool integration.

Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Meta Llama 4 Scout
Llama 4 Scout is Meta’s compact and high-performance entry in the Llama 4 family, released April 5, 2025. Built on a mixture-of-experts (MoE) architecture with 17B active parameters (109B total) and a staggering 10‑million-token context window, it delivers top-tier speed and long-context reasoning while fitting on a single Nvidia H100 GPU. It outperforms models like Google's Gemma 3, Gemini 2.0 Flash‑Lite, and Mistral 3.1 across benchmarks.
Llama 4 Maverick is Meta’s powerful mid-sized model in the Llama 4 series, released April 5, 2025. Built with a mixture-of-experts (MoE) architecture featuring 17 B active parameters (out of 400 B total) and 128 experts, it supports a 1 million-token context window and native multimodality for text and image inputs. It ranks near the top of competitive benchmarks—surpassing GPT‑4o and Gemini 2.0 Flash in reasoning, coding, and visual tasks.
Llama 4 Maverick is Meta’s powerful mid-sized model in the Llama 4 series, released April 5, 2025. Built with a mixture-of-experts (MoE) architecture featuring 17 B active parameters (out of 400 B total) and 128 experts, it supports a 1 million-token context window and native multimodality for text and image inputs. It ranks near the top of competitive benchmarks—surpassing GPT‑4o and Gemini 2.0 Flash in reasoning, coding, and visual tasks.
Llama 4 Maverick is Meta’s powerful mid-sized model in the Llama 4 series, released April 5, 2025. Built with a mixture-of-experts (MoE) architecture featuring 17 B active parameters (out of 400 B total) and 128 experts, it supports a 1 million-token context window and native multimodality for text and image inputs. It ranks near the top of competitive benchmarks—surpassing GPT‑4o and Gemini 2.0 Flash in reasoning, coding, and visual tasks.


GlobalGPT
GlobalGPT is an all-in-one AI platform that unifies leading models for writing, coding, research, image generation, and video creation—accessible through a single account and subscription. It brings together top models like GPT-5, GPT-4.1, GPT-4o, GPT-o3, Claude Opus 4.1, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek V3, Unikorn (MJ-like) V7, Flux, Ideogram, and Google Veo 3 so you can chat, draft content, analyze documents, generate images, and produce cinematic videos without switching tools. Designed for over 2 million users worldwide, GlobalGPT also includes advanced research agents powered by GPT-4o and perplexity for deep web analysis, PDF summarization, and market insights, all wrapped in a clean interface with flexible credit-based plans.
GlobalGPT
GlobalGPT is an all-in-one AI platform that unifies leading models for writing, coding, research, image generation, and video creation—accessible through a single account and subscription. It brings together top models like GPT-5, GPT-4.1, GPT-4o, GPT-o3, Claude Opus 4.1, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek V3, Unikorn (MJ-like) V7, Flux, Ideogram, and Google Veo 3 so you can chat, draft content, analyze documents, generate images, and produce cinematic videos without switching tools. Designed for over 2 million users worldwide, GlobalGPT also includes advanced research agents powered by GPT-4o and perplexity for deep web analysis, PDF summarization, and market insights, all wrapped in a clean interface with flexible credit-based plans.
GlobalGPT
GlobalGPT is an all-in-one AI platform that unifies leading models for writing, coding, research, image generation, and video creation—accessible through a single account and subscription. It brings together top models like GPT-5, GPT-4.1, GPT-4o, GPT-o3, Claude Opus 4.1, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek V3, Unikorn (MJ-like) V7, Flux, Ideogram, and Google Veo 3 so you can chat, draft content, analyze documents, generate images, and produce cinematic videos without switching tools. Designed for over 2 million users worldwide, GlobalGPT also includes advanced research agents powered by GPT-4o and perplexity for deep web analysis, PDF summarization, and market insights, all wrapped in a clean interface with flexible credit-based plans.
Gemini File Search
Gemini File Search is a fully managed Retrieval Augmented Generation (RAG) tool in the Gemini API that simplifies grounding AI responses in your private data by automatically handling file upload, chunking, embedding with Gemini models, indexing, and semantic retrieval for accurate, context-aware answers. Developers create persistent File Search stores to hold embeddings indefinitely, upload files directly or via Files API supporting formats like PDF, DOCX, TXT, JSON, code files, and more up to 100MB each, with custom chunking configs for optimal retrieval. It provides citations linking responses to source chunks for verification, metadata filtering for targeted searches, structured outputs for JSON schemas, and integrates seamlessly into generate Content calls without other tools. Free storage and query-time embeddings make it cost-effective, charging only initial indexing ($0.15/1M tokens) plus input/output tokens, with limits scaling by tier up to 1TB for enterprises.
Gemini File Search
Gemini File Search is a fully managed Retrieval Augmented Generation (RAG) tool in the Gemini API that simplifies grounding AI responses in your private data by automatically handling file upload, chunking, embedding with Gemini models, indexing, and semantic retrieval for accurate, context-aware answers. Developers create persistent File Search stores to hold embeddings indefinitely, upload files directly or via Files API supporting formats like PDF, DOCX, TXT, JSON, code files, and more up to 100MB each, with custom chunking configs for optimal retrieval. It provides citations linking responses to source chunks for verification, metadata filtering for targeted searches, structured outputs for JSON schemas, and integrates seamlessly into generate Content calls without other tools. Free storage and query-time embeddings make it cost-effective, charging only initial indexing ($0.15/1M tokens) plus input/output tokens, with limits scaling by tier up to 1TB for enterprises.
Gemini File Search
Gemini File Search is a fully managed Retrieval Augmented Generation (RAG) tool in the Gemini API that simplifies grounding AI responses in your private data by automatically handling file upload, chunking, embedding with Gemini models, indexing, and semantic retrieval for accurate, context-aware answers. Developers create persistent File Search stores to hold embeddings indefinitely, upload files directly or via Files API supporting formats like PDF, DOCX, TXT, JSON, code files, and more up to 100MB each, with custom chunking configs for optimal retrieval. It provides citations linking responses to source chunks for verification, metadata filtering for targeted searches, structured outputs for JSON schemas, and integrates seamlessly into generate Content calls without other tools. Free storage and query-time embeddings make it cost-effective, charging only initial indexing ($0.15/1M tokens) plus input/output tokens, with limits scaling by tier up to 1TB for enterprises.
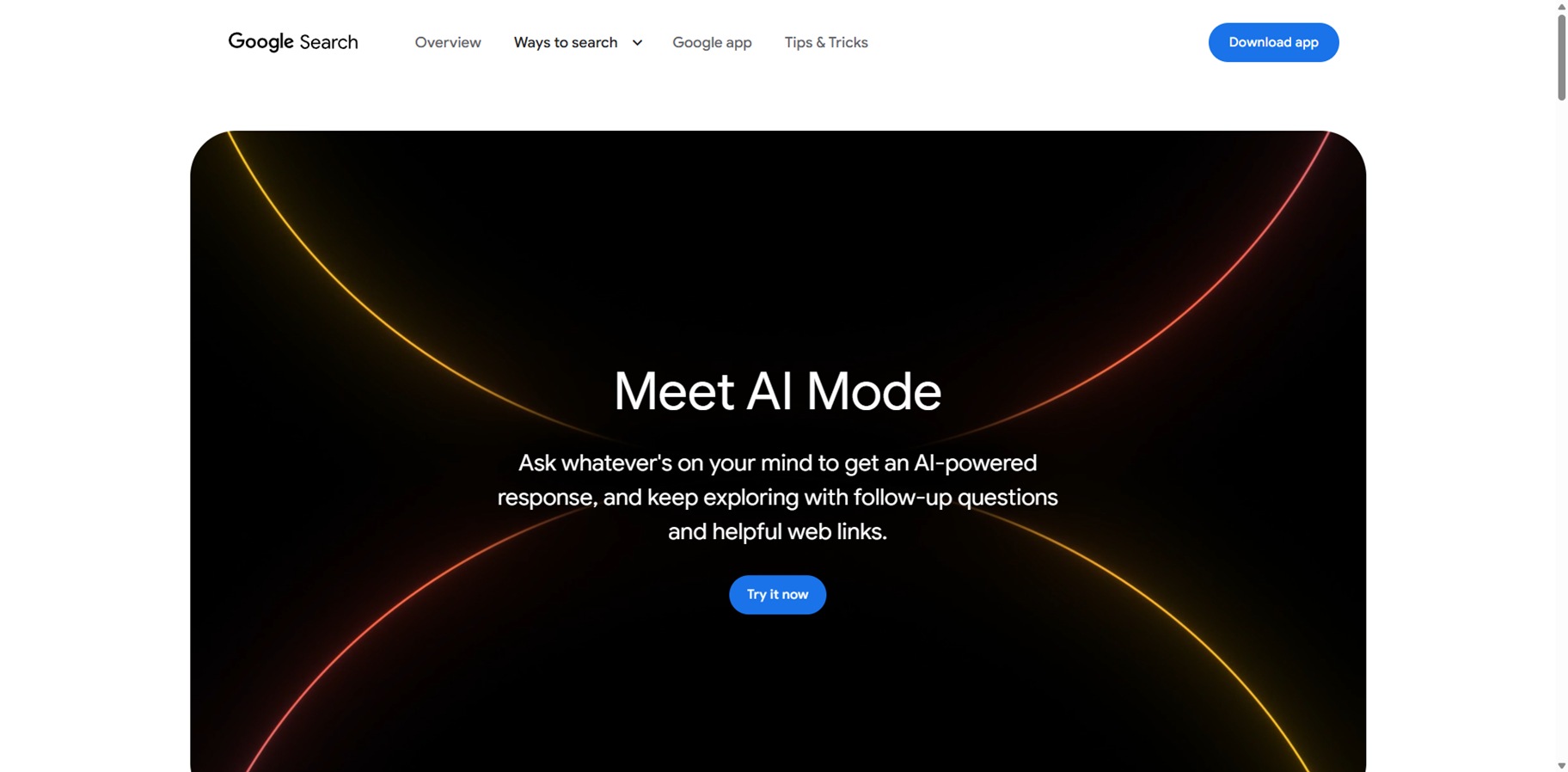

Google AI Mode
Google AI Mode is Google's most advanced generative AI search experience, powered by the Gemini model, designed to handle complex queries with deeper reasoning and multimodal inputs like text, voice, images, or photos. It breaks down your question into subtopics, fans out multiple searches across the web simultaneously, and synthesizes comprehensive, cited responses with links to high-quality sources for further exploration. Unlike traditional search results, it offers conversational follow-ups, personalized context from past interactions, and tools like Deep Search for thorough reports, making research intuitive and efficient for everything from product comparisons to in-depth topic dives. Available via google.com/ai, the Search bar, or the Google app, it's rolling out widely including in India.
Google AI Mode
Google AI Mode is Google's most advanced generative AI search experience, powered by the Gemini model, designed to handle complex queries with deeper reasoning and multimodal inputs like text, voice, images, or photos. It breaks down your question into subtopics, fans out multiple searches across the web simultaneously, and synthesizes comprehensive, cited responses with links to high-quality sources for further exploration. Unlike traditional search results, it offers conversational follow-ups, personalized context from past interactions, and tools like Deep Search for thorough reports, making research intuitive and efficient for everything from product comparisons to in-depth topic dives. Available via google.com/ai, the Search bar, or the Google app, it's rolling out widely including in India.
Google AI Mode
Google AI Mode is Google's most advanced generative AI search experience, powered by the Gemini model, designed to handle complex queries with deeper reasoning and multimodal inputs like text, voice, images, or photos. It breaks down your question into subtopics, fans out multiple searches across the web simultaneously, and synthesizes comprehensive, cited responses with links to high-quality sources for further exploration. Unlike traditional search results, it offers conversational follow-ups, personalized context from past interactions, and tools like Deep Search for thorough reports, making research intuitive and efficient for everything from product comparisons to in-depth topic dives. Available via google.com/ai, the Search bar, or the Google app, it's rolling out widely including in India.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai