
- Voice Assistant & Call Center Developers: Create interactive agents that speak back naturally and respond in context.
- Interactive Media & Game Designers: Build characters or NPCs with rich audio dialogues, emotional tone, and multilingual capabilities.
- Accessibility & Education: Provide conversational audio interfaces for audiobooks, language learning, or tutoring apps.
- Enterprise Conversational AI Teams: Deploy voice-enabled customer support with nuanced tone awareness and tool integration.
- Multilingual Voice App Builders: Support seamless transitions among 24+ languages with accent and tone control.
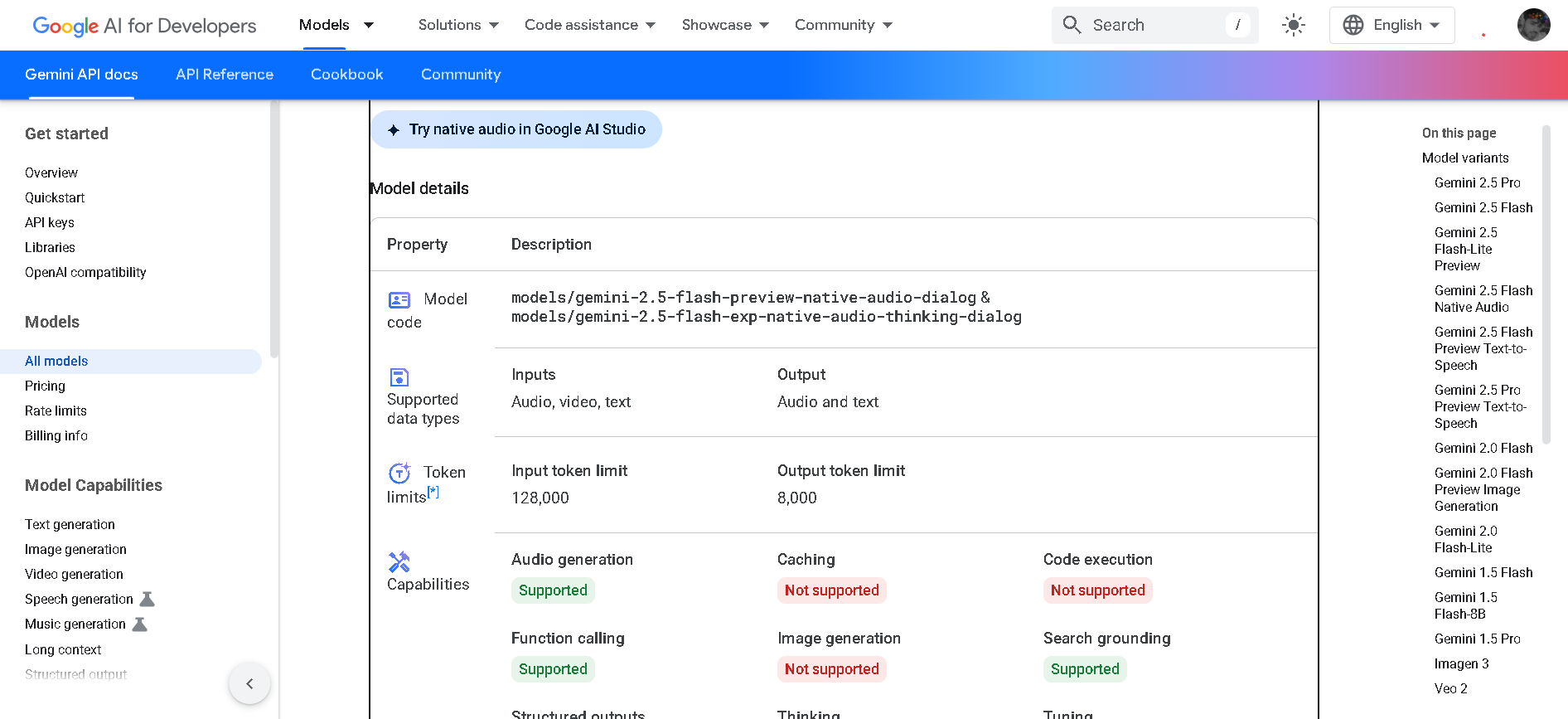
How to Use Gemini 2.5 Flash Native Audio?
- Access via Live API: Use the preview model names (`gemini-2.5-flash-preview-native-audio-dialog` or `gemini-2.5-flash-exp-native-audio-thinking-dialog`) via the Gemini API or Vertex AI Live API.
- Stream Audio & Video: Send live voice input (or video with audio); receive responsive speech output in real time.
- Adjust Thinking: Choose between Native Audio (standard speed with natural voice) and Thinking Audio (delivers deeper reasoning audio output).
- Customize Voice Behavior: Control tone, accent, expression, pace, and emotion; model recognizes when to pause or defer—e.g., in noisy environments.
- Integrate with Tools: Works alongside tool calling, context-aware actions, and structured output—perfect for agentic workflows.
- Truly Conversational Voice Interface: Gemini responds vocally in real time, recognizing tone and emotions.
- Thinking-Enabled Voice: Supports an advanced thinking-dialog version for deeper, multi-step reasoning with speech output.
- Multilingual & Expressive: Handles over 24 languages and accent shifts, with expressive control for various emotional or narrative delivery.
- Built on Flash’s Fast Reasoning Core: Delivers low-latency responses with cost savings and token efficiency.
- Enterprise-Grade Integration: Works with Live API, supports function calling, structured outputs, and tool invocation for production use.
- Natural, expressive real-time speech in API workflows
- Voice interfaces that sense tone, emotion, and environment
- Dual-mode: standard audio or thinking-depth audio output
- Supports multilingual, accent-aware dialogue experiences
- Combines voice with reasoning and tool-driven actions
- Still in preview—API may change before GA
- Requires Live API streaming and custom integration
- Thinking audio increases latency and compute usage
API
Custom
Output price (including thinking tokens): $2.00 (text) & $12.00 (audio)
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
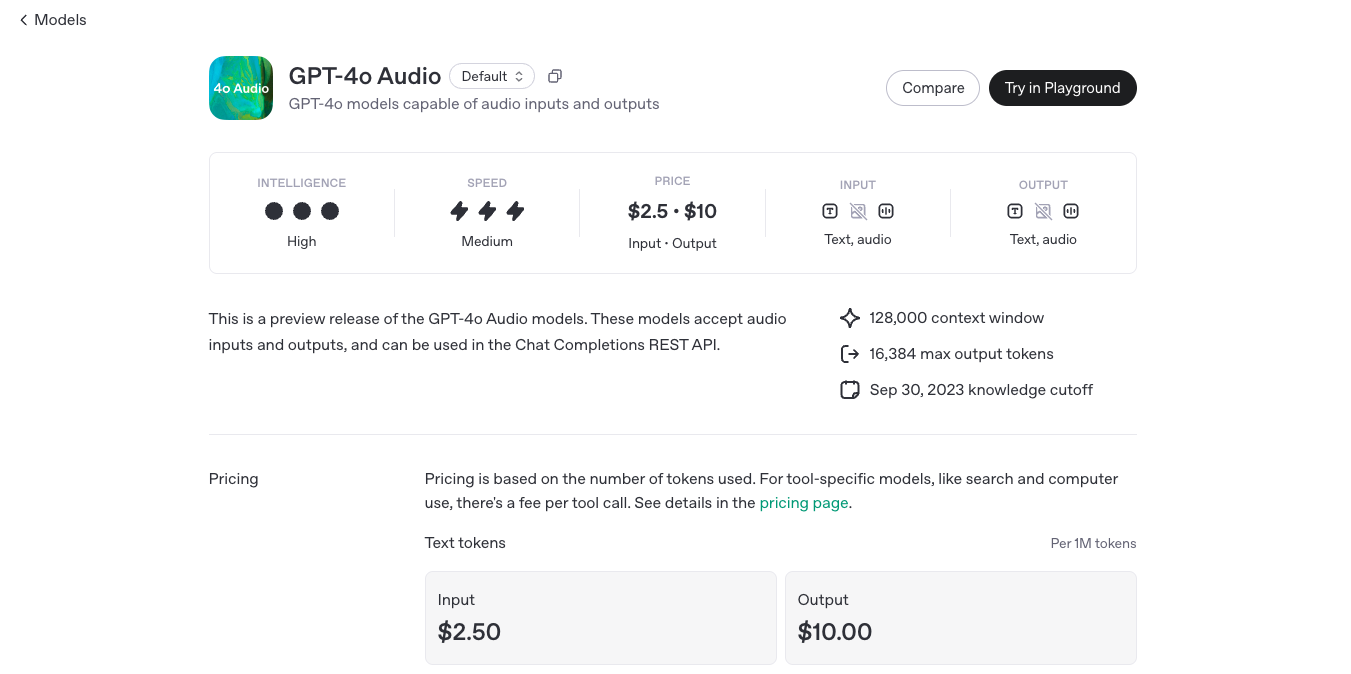
OpenAI GPT-4o Audio is an advanced real-time AI-powered voice assistant that enables instant, natural, and expressive conversations with AI. Unlike previous AI voice models, GPT-4o Audio can listen, understand, and respond within milliseconds, making interactions feel fluid and human-like. This model is designed to process and generate speech with emotion, tone, and contextual awareness, making it suitable for applications such as AI assistants, voice interactions, real-time translations, and accessibility tools.
OpenAI GPT-4o Audio is an advanced real-time AI-powered voice assistant that enables instant, natural, and expressive conversations with AI. Unlike previous AI voice models, GPT-4o Audio can listen, understand, and respond within milliseconds, making interactions feel fluid and human-like. This model is designed to process and generate speech with emotion, tone, and contextual awareness, making it suitable for applications such as AI assistants, voice interactions, real-time translations, and accessibility tools.
OpenAI GPT-4o Audio is an advanced real-time AI-powered voice assistant that enables instant, natural, and expressive conversations with AI. Unlike previous AI voice models, GPT-4o Audio can listen, understand, and respond within milliseconds, making interactions feel fluid and human-like. This model is designed to process and generate speech with emotion, tone, and contextual awareness, making it suitable for applications such as AI assistants, voice interactions, real-time translations, and accessibility tools.

GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
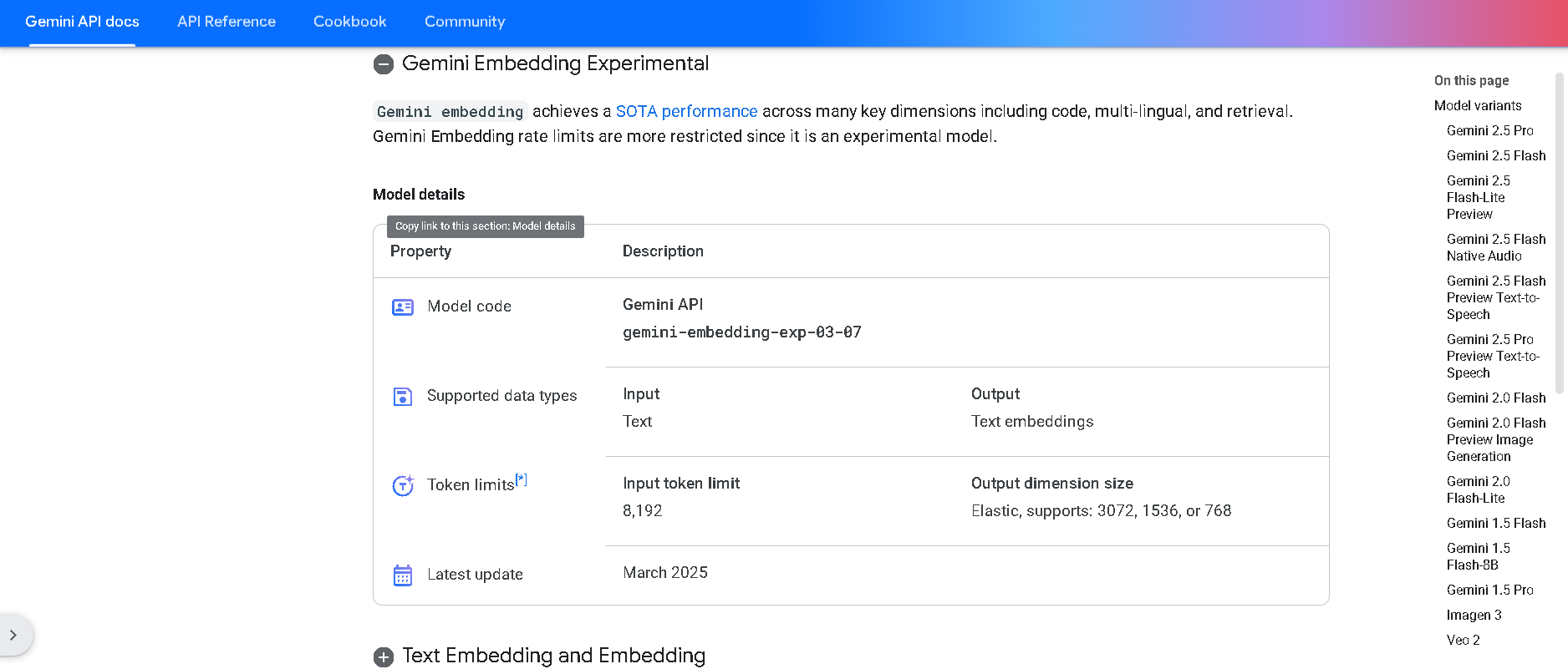

Gemini Embedding
Gemini Embedding is Google DeepMind’s state-of-the-art text embedding model, built on the powerful Gemini family. It transforms text into high-dimensional numerical vectors (up to 3,072 dimensions) with exceptional accuracy and generalization across over 100 languages and multiple modalities—including code. It achieves state-of-the-art results on the Massive Multilingual Text Embedding Benchmark (MMTEB), outperforming prior models across multilingual, English, and code-based tasks
Gemini Embedding
Gemini Embedding is Google DeepMind’s state-of-the-art text embedding model, built on the powerful Gemini family. It transforms text into high-dimensional numerical vectors (up to 3,072 dimensions) with exceptional accuracy and generalization across over 100 languages and multiple modalities—including code. It achieves state-of-the-art results on the Massive Multilingual Text Embedding Benchmark (MMTEB), outperforming prior models across multilingual, English, and code-based tasks
Gemini Embedding
Gemini Embedding is Google DeepMind’s state-of-the-art text embedding model, built on the powerful Gemini family. It transforms text into high-dimensional numerical vectors (up to 3,072 dimensions) with exceptional accuracy and generalization across over 100 languages and multiple modalities—including code. It achieves state-of-the-art results on the Massive Multilingual Text Embedding Benchmark (MMTEB), outperforming prior models across multilingual, English, and code-based tasks
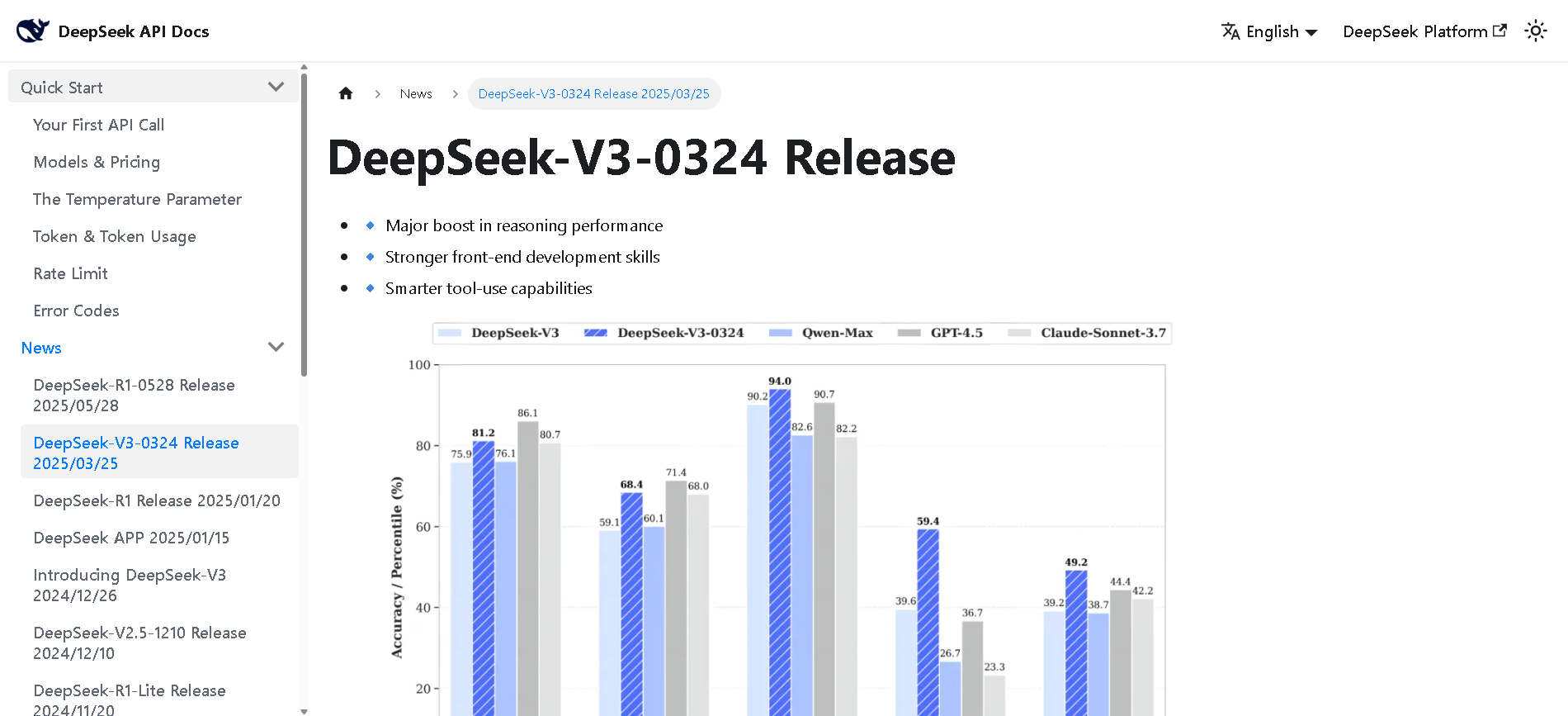
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.

Twin Mind
TwinMind is an AI-powered personal assistant platform that provides advanced note-taking, transcription, and meeting summarization services. It works across meetings, lectures, and conversations, capturing notes proactively and offering real-time transcription with high accuracy in over 140 languages. TwinMind operates with offline mode ensuring 100% privacy by processing audio on-device without recording, and it stores transcripts locally with optional encrypted cloud backups. The platform also integrates AI models for generating summaries, action items, follow-up emails, and study guides, helping users stay organized and efficient. TwinMind supports desktop, mobile, and browser extensions, enabling seamless integration into users’ daily workflows.
Twin Mind
TwinMind is an AI-powered personal assistant platform that provides advanced note-taking, transcription, and meeting summarization services. It works across meetings, lectures, and conversations, capturing notes proactively and offering real-time transcription with high accuracy in over 140 languages. TwinMind operates with offline mode ensuring 100% privacy by processing audio on-device without recording, and it stores transcripts locally with optional encrypted cloud backups. The platform also integrates AI models for generating summaries, action items, follow-up emails, and study guides, helping users stay organized and efficient. TwinMind supports desktop, mobile, and browser extensions, enabling seamless integration into users’ daily workflows.
Twin Mind
TwinMind is an AI-powered personal assistant platform that provides advanced note-taking, transcription, and meeting summarization services. It works across meetings, lectures, and conversations, capturing notes proactively and offering real-time transcription with high accuracy in over 140 languages. TwinMind operates with offline mode ensuring 100% privacy by processing audio on-device without recording, and it stores transcripts locally with optional encrypted cloud backups. The platform also integrates AI models for generating summaries, action items, follow-up emails, and study guides, helping users stay organized and efficient. TwinMind supports desktop, mobile, and browser extensions, enabling seamless integration into users’ daily workflows.

Nano Banana
Gemini 2.5 Flash Image is Google's state-of-the-art AI image generation and editing model, nicknamed Nano Banana, designed for fast, high-quality creative workflows. It excels at blending multiple images into seamless compositions, maintaining character consistency across scenes, and making precise edits through natural language prompts like blurring backgrounds or changing poses. Accessible via Google AI Studio and Gemini API, it leverages Gemini's world knowledge for realistic transformations, style transfers, and conversational refinements without restarting from scratch. Developers love its low latency, token-based pricing at about $0.039 per image, and SynthID watermarking for easy AI identification. Perfect for product mockups, storytelling, education tools, and professional photo editing.
Nano Banana
Gemini 2.5 Flash Image is Google's state-of-the-art AI image generation and editing model, nicknamed Nano Banana, designed for fast, high-quality creative workflows. It excels at blending multiple images into seamless compositions, maintaining character consistency across scenes, and making precise edits through natural language prompts like blurring backgrounds or changing poses. Accessible via Google AI Studio and Gemini API, it leverages Gemini's world knowledge for realistic transformations, style transfers, and conversational refinements without restarting from scratch. Developers love its low latency, token-based pricing at about $0.039 per image, and SynthID watermarking for easy AI identification. Perfect for product mockups, storytelling, education tools, and professional photo editing.
Nano Banana
Gemini 2.5 Flash Image is Google's state-of-the-art AI image generation and editing model, nicknamed Nano Banana, designed for fast, high-quality creative workflows. It excels at blending multiple images into seamless compositions, maintaining character consistency across scenes, and making precise edits through natural language prompts like blurring backgrounds or changing poses. Accessible via Google AI Studio and Gemini API, it leverages Gemini's world knowledge for realistic transformations, style transfers, and conversational refinements without restarting from scratch. Developers love its low latency, token-based pricing at about $0.039 per image, and SynthID watermarking for easy AI identification. Perfect for product mockups, storytelling, education tools, and professional photo editing.

Gemma
Gemma is a family of lightweight, state-of-the-art open models from Google DeepMind, built using the same research and technology that powers the Gemini models. Available in sizes from 270M to 27B parameters, they support multimodal understanding with text, image, video, and audio inputs while generating text outputs, alongside strong multilingual capabilities across over 140 languages. Specialized variants like CodeGemma for coding, PaliGemma for vision-language tasks, ShieldGemma for safety classification, MedGemma for medical imaging and text, and mobile-optimized Gemma 3n enable developers to create efficient AI apps that run on devices from phones to servers. These models excel in tasks like summarization, question answering, reasoning, code generation, and translation, with tools for fine-tuning and deployment.
Gemma
Gemma is a family of lightweight, state-of-the-art open models from Google DeepMind, built using the same research and technology that powers the Gemini models. Available in sizes from 270M to 27B parameters, they support multimodal understanding with text, image, video, and audio inputs while generating text outputs, alongside strong multilingual capabilities across over 140 languages. Specialized variants like CodeGemma for coding, PaliGemma for vision-language tasks, ShieldGemma for safety classification, MedGemma for medical imaging and text, and mobile-optimized Gemma 3n enable developers to create efficient AI apps that run on devices from phones to servers. These models excel in tasks like summarization, question answering, reasoning, code generation, and translation, with tools for fine-tuning and deployment.
Gemma
Gemma is a family of lightweight, state-of-the-art open models from Google DeepMind, built using the same research and technology that powers the Gemini models. Available in sizes from 270M to 27B parameters, they support multimodal understanding with text, image, video, and audio inputs while generating text outputs, alongside strong multilingual capabilities across over 140 languages. Specialized variants like CodeGemma for coding, PaliGemma for vision-language tasks, ShieldGemma for safety classification, MedGemma for medical imaging and text, and mobile-optimized Gemma 3n enable developers to create efficient AI apps that run on devices from phones to servers. These models excel in tasks like summarization, question answering, reasoning, code generation, and translation, with tools for fine-tuning and deployment.

Gemini 3
Gemini 3 is Google's most advanced AI model family, including Gemini 3 Pro and Gemini 3 Flash, excelling in state-of-the-art reasoning, multimodal understanding across text, images, video, audio, and code, with exceptional agentic capabilities for handling complex, multi-step tasks autonomously. Accessible directly in Google AI Studio for developers to experiment, tune prompts, and build apps, it shines in vibe coding, generating interactive experiences from ideas, superior tool use like Google Search integration, and conversational editing for images. With a massive 1M token context window, Deep Think mode for ultra-complex problem-solving, and features like structured outputs and function calling, it powers everything from personal assistants to sophisticated workflows, outperforming predecessors on benchmarks like GPQA and ARC-AGI.
Gemini 3
Gemini 3 is Google's most advanced AI model family, including Gemini 3 Pro and Gemini 3 Flash, excelling in state-of-the-art reasoning, multimodal understanding across text, images, video, audio, and code, with exceptional agentic capabilities for handling complex, multi-step tasks autonomously. Accessible directly in Google AI Studio for developers to experiment, tune prompts, and build apps, it shines in vibe coding, generating interactive experiences from ideas, superior tool use like Google Search integration, and conversational editing for images. With a massive 1M token context window, Deep Think mode for ultra-complex problem-solving, and features like structured outputs and function calling, it powers everything from personal assistants to sophisticated workflows, outperforming predecessors on benchmarks like GPQA and ARC-AGI.
Gemini 3
Gemini 3 is Google's most advanced AI model family, including Gemini 3 Pro and Gemini 3 Flash, excelling in state-of-the-art reasoning, multimodal understanding across text, images, video, audio, and code, with exceptional agentic capabilities for handling complex, multi-step tasks autonomously. Accessible directly in Google AI Studio for developers to experiment, tune prompts, and build apps, it shines in vibe coding, generating interactive experiences from ideas, superior tool use like Google Search integration, and conversational editing for images. With a massive 1M token context window, Deep Think mode for ultra-complex problem-solving, and features like structured outputs and function calling, it powers everything from personal assistants to sophisticated workflows, outperforming predecessors on benchmarks like GPQA and ARC-AGI.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai