- Developers & Platform Owners: Implement scalable, multilingual guardrails across apps, chatbots, forums, or user-generated content pipelines.
- Chat & Conversational AI Builders: Use the conversational endpoint for context-aware filtering of back-and-forth dialogues.
- Global Enterprises: Enforce compliance in 11 supported languages (e.g., Arabic, Chinese, English, French, German, Japanese, Korean, Portuguese, Russian, Spanish, Italian).
- Content Moderation Teams: Leverage raw scores to customize thresholds and fine-tune precision-recall balance for each category.
- Regulated Industries: Detect model-generated advice and PII to ensure safety and compliance in sensitive sectors.
How to Use Mistral Moderation API?
- Choose Endpoint: Use `classifiers.moderate` for raw text or `classifiers.moderate_chat` for conversational turns.
- Send Payload: Provide inputs as strings (raw) or conversation arrays (conversational endpoint) to Mistral’s Python, TypeScript, or cURL clients.
- Receive Category Scores: The API returns boolean flags and confidence scores for each category (e.g., `‘violenceandthreats’: true, score 0.999`).
- Adjust Policy Thresholds: Use raw scores to tailor sensitivity per use case, or rely on default thresholds (precision 0.8–0.9, recall 0.7–0.99).
- Scale Safely: Use batch endpoint to reduce latency and cost (~25% savings for high-volume requests).
- Multilingual by Design: Supports 11 major languages beyond English, a key advantage over many moderation APIs.
- Dual-Endpoint Support: Handles both raw text and conversational filtering with context awareness.
- Fine-Grained Risk Scoring: Provides category-level confidence scores empowering nuanced policy control.
- Industry-Grade Guardrails: Designed to filter model-generated advice, PII, and harmful claims to improve downstream safety.
- Batching for Efficiency: Built-in batch API reduces cost and improves scalability for high-volume moderation needs.
- Strong multilingual support in 11 languages
- Both raw-text and conversational moderation endpoints
- Category-level scoring enables customizable policy tuning
- Backed by Ministral 8B with robust safety precision/recall
- Batch endpoint reduces costs and improves throughput
- Being early-stage, benchmark comparisons to alternatives like OpenAI or Perspective are limited
- Potential bias and false positives (e.g., in AAVE or disability-related terms) may still exist
- Not yet as customizable as full on-prem policy engines
API only
$0.1 per 1M input tokens
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

omni-moderation-latest is OpenAI’s most advanced content moderation model, designed to detect and flag harmful, unsafe, or policy-violating content across a wide range of modalities and languages. Built on the GPT-4o architecture, it leverages multimodal understanding and multilingual capabilities to provide robust moderation for text, images, and audio inputs. This model is particularly effective in identifying nuanced and culturally specific toxic content, including implicit insults, sarcasm, and aggression that general-purpose systems might overlook.
omni-moderation-latest is OpenAI’s most advanced content moderation model, designed to detect and flag harmful, unsafe, or policy-violating content across a wide range of modalities and languages. Built on the GPT-4o architecture, it leverages multimodal understanding and multilingual capabilities to provide robust moderation for text, images, and audio inputs. This model is particularly effective in identifying nuanced and culturally specific toxic content, including implicit insults, sarcasm, and aggression that general-purpose systems might overlook.
omni-moderation-latest is OpenAI’s most advanced content moderation model, designed to detect and flag harmful, unsafe, or policy-violating content across a wide range of modalities and languages. Built on the GPT-4o architecture, it leverages multimodal understanding and multilingual capabilities to provide robust moderation for text, images, and audio inputs. This model is particularly effective in identifying nuanced and culturally specific toxic content, including implicit insults, sarcasm, and aggression that general-purpose systems might overlook.
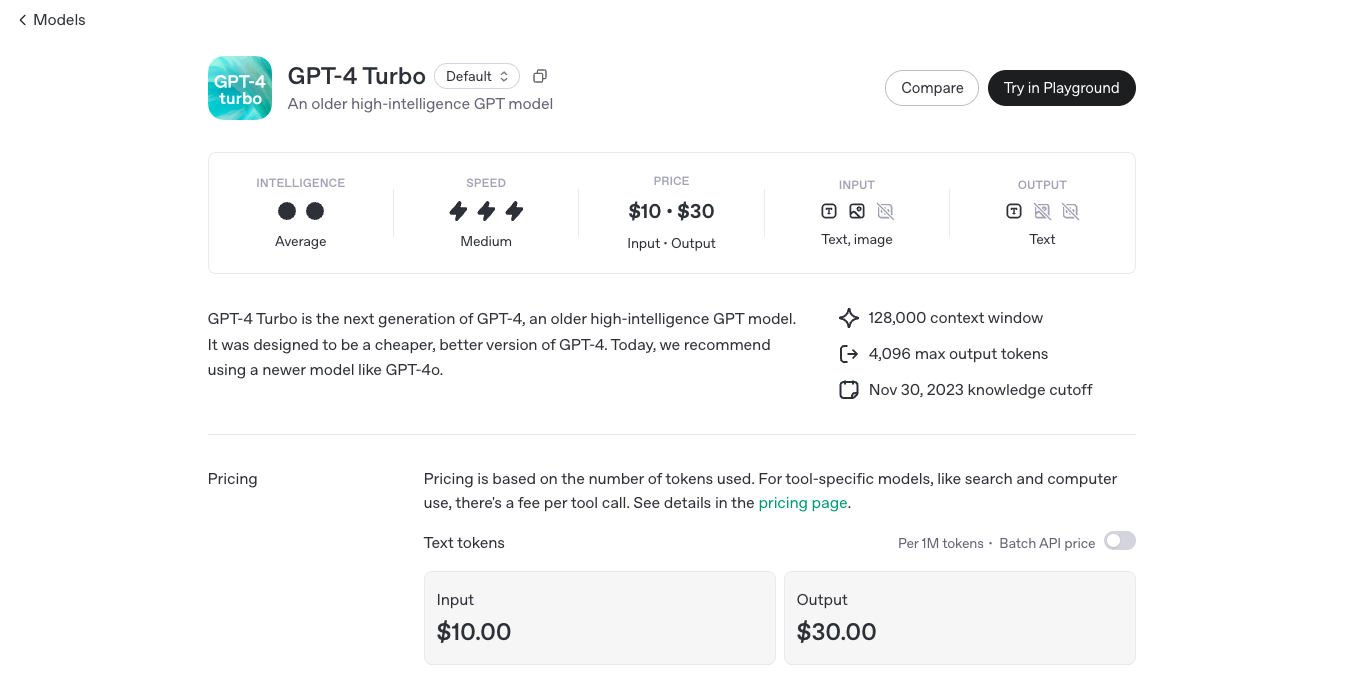
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
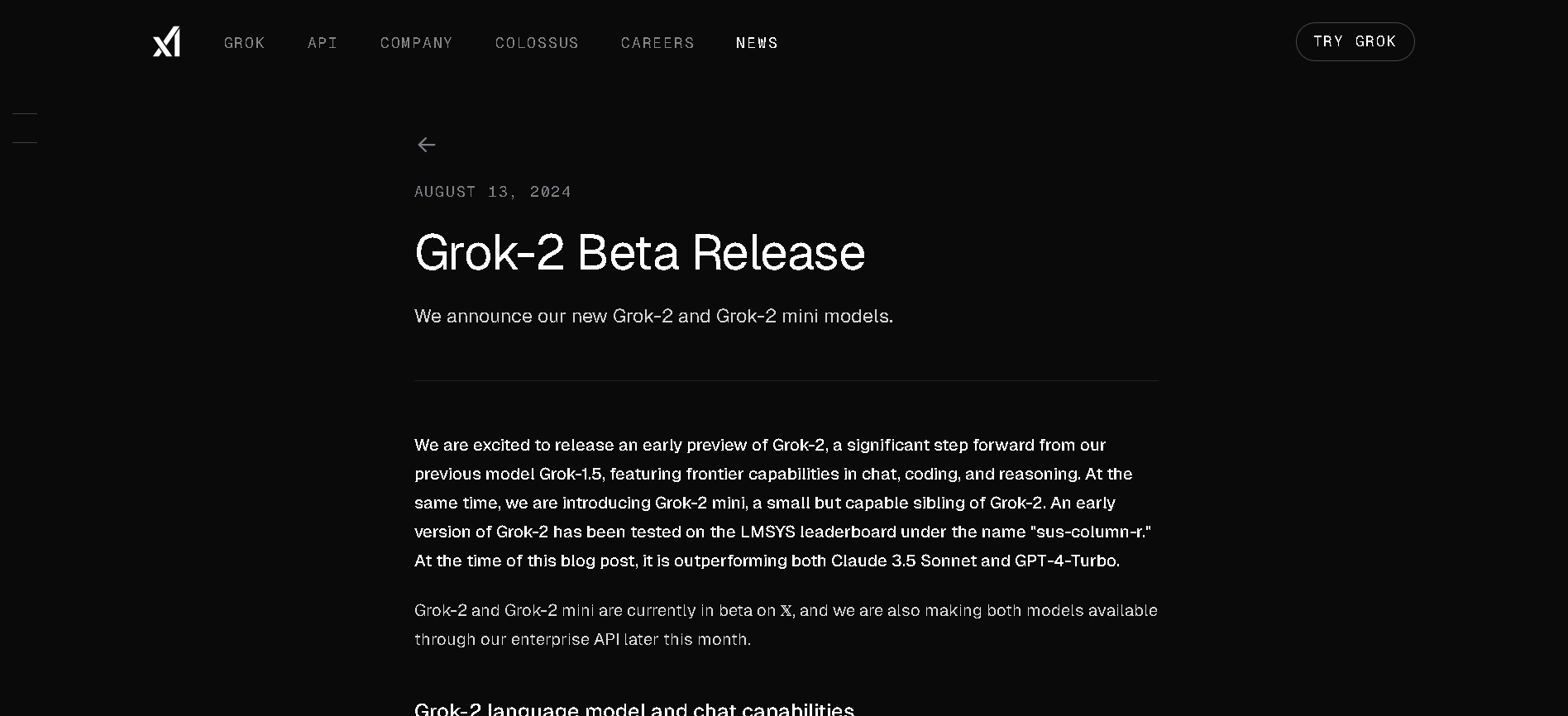

Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.
Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.
Grok 2
Grok 2 is xAI’s second-generation chatbot that extends Grok’s capabilities to include real-time web access, multimodal output (text, vision, image generation via FLUX.1), and improved reasoning performance. It’s available to X Premium and Premium+ users and through xAI’s enterprise API.

Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.

DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.
grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.
grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.
Llama 4 Maverick is Meta’s powerful mid-sized model in the Llama 4 series, released April 5, 2025. Built with a mixture-of-experts (MoE) architecture featuring 17 B active parameters (out of 400 B total) and 128 experts, it supports a 1 million-token context window and native multimodality for text and image inputs. It ranks near the top of competitive benchmarks—surpassing GPT‑4o and Gemini 2.0 Flash in reasoning, coding, and visual tasks.
Llama 4 Maverick is Meta’s powerful mid-sized model in the Llama 4 series, released April 5, 2025. Built with a mixture-of-experts (MoE) architecture featuring 17 B active parameters (out of 400 B total) and 128 experts, it supports a 1 million-token context window and native multimodality for text and image inputs. It ranks near the top of competitive benchmarks—surpassing GPT‑4o and Gemini 2.0 Flash in reasoning, coding, and visual tasks.
Llama 4 Maverick is Meta’s powerful mid-sized model in the Llama 4 series, released April 5, 2025. Built with a mixture-of-experts (MoE) architecture featuring 17 B active parameters (out of 400 B total) and 128 experts, it supports a 1 million-token context window and native multimodality for text and image inputs. It ranks near the top of competitive benchmarks—surpassing GPT‑4o and Gemini 2.0 Flash in reasoning, coding, and visual tasks.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.
Llama 3.2 Vision is Meta’s first open-source multimodal Llama model series, released on September 25, 2024. Available in 11 B and 90 B parameter sizes, it merges advanced image understanding with a massive 128 K‑token text context. Optimized for vision reasoning, captioning, document QA, and visual math tasks, it outperforms many closed-source multimodal models.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
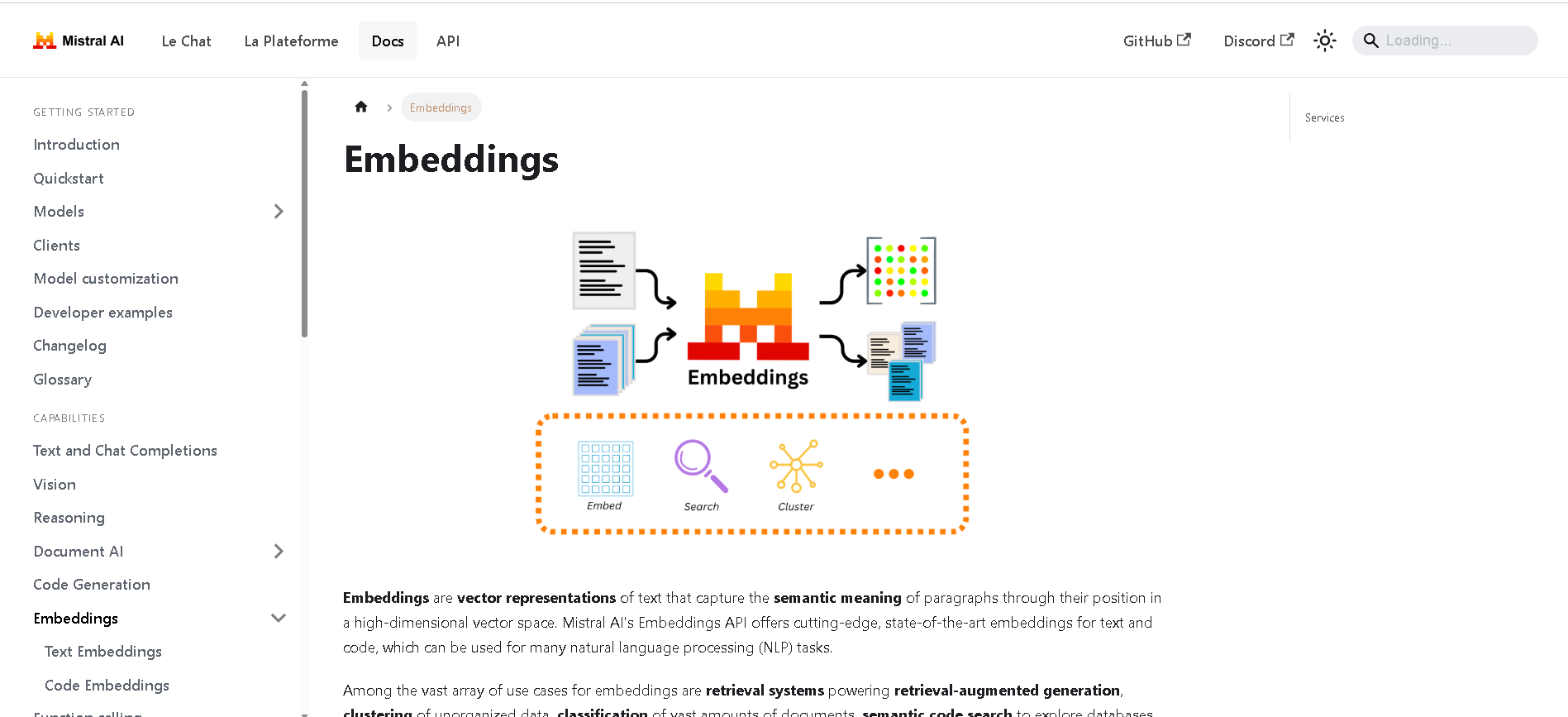
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
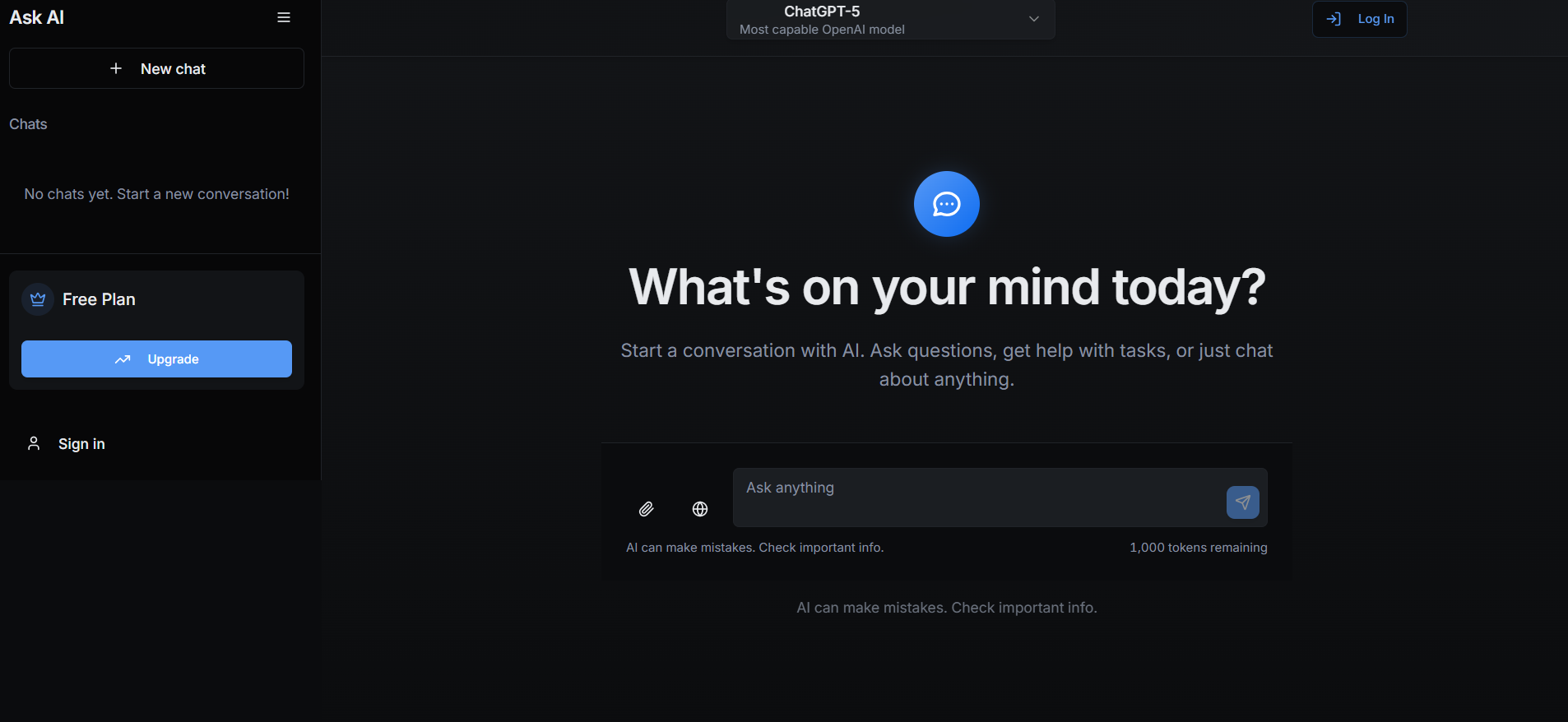
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai