
- Researchers & Academics: Study multilingual and low-resource LLM development and instruction tuning.
- Developers & Engineers: Leverage models like Odia Llama 2-7B and BengaliGPT via Hugging Face or self-hosting.
- Educators & NGOs: Deploy Odia AI solutions for education, healthcare, governance, and local language technology.
- Open-Source Contributors: Join community efforts by contributing datasets, models, or tools under permissive licenses.
- Startups & Integrators: Build narrative chatbots, content generators, AI assistants, and domain-specific bots in Odia and related languages.
How to Use OdiaGenAI?
- Select a Model: Choose from options like Odia Llama 2-7B, BengaliGPT, or Qwen 1.5 Odia model via Hugging Face.
- Deploy or Call: Use through Hugging Face Spaces, API, or download locally for private development.
- Use Prebuilt Tools: Try Olive Farm for instruction set generation, Olive Scrapper for Odia content extraction, Olive Whisper for ASR+translation.
- Fine-Tune & Extend: Build your own domain-specialized models using their LORA pipelines and public datasets.
- Join Workshops & Events: Attend annual workshops (2023–2025) to collaborate and validate your solutions.
- Low-Resource Focus: Tailored for Odia, which suffers from poor performance on mainstream LLMs—with improved language understanding.
- Multi-Lingual Expansion: Includes BengaliGPT, Odia, and future Indic language models like Hindi.
- Open-Source Openness: Models, code, and datasets are available for research and non-commercial use (CC BY-NC-SA or Apache, MIT).
- Toolkit Ecosystem: Comes with ready tools—scraping, ASR, instruction creation and fine-tuning pipelines.
- Community-Driven Workshops: Hosts annual events supporting grassroots growth, fostering collaboration across Odisha and globally.
- Focused on underserved Indic languages with genuine low-resource investment
- Offers both pretrained and instruction‑tuned models (e.g., Odia Llama 2‑7B, Qwen_1.5_Odia)
- Includes practical tools like Olive Farm, Scrapper, Whisper for multilingual workflows
- Fully open-source with permissive licenses enabling customization
- Active community with regular workshops and development events
- Models still early-stage—performance lags behind major LLMs
- Limited ASR and translation quality may need refinement
- Restricted to non-commercial use—licensing limits production deployment
- Needs more Indic language expansion and more domain-specific tuning




Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
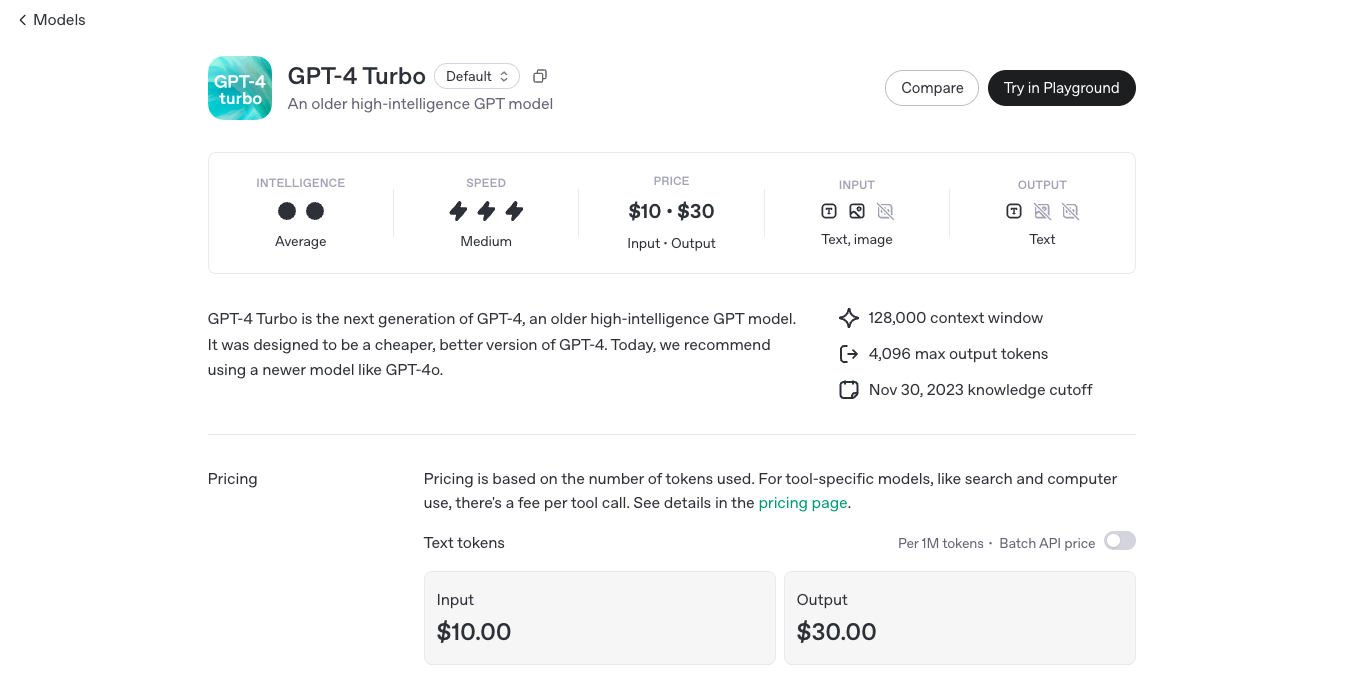
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
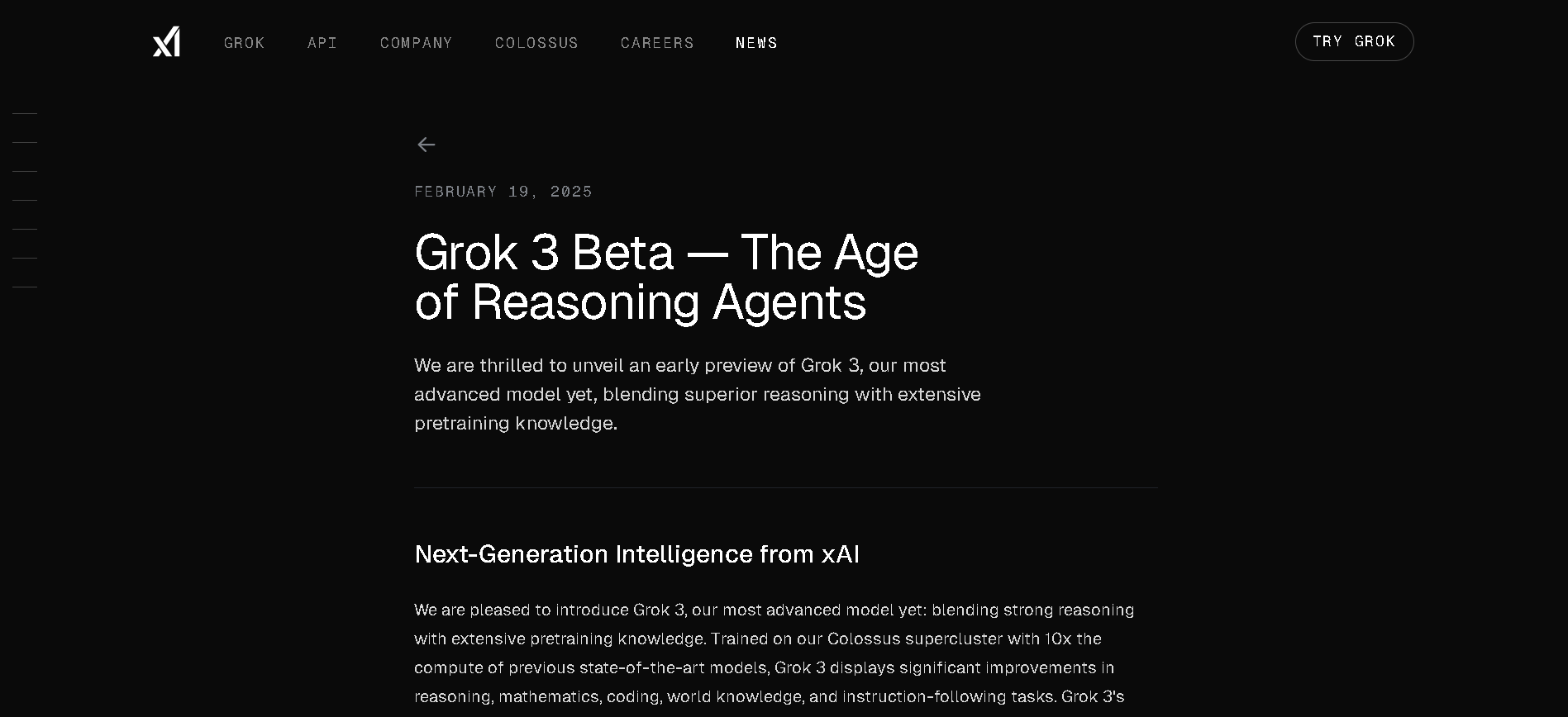

Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.

DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
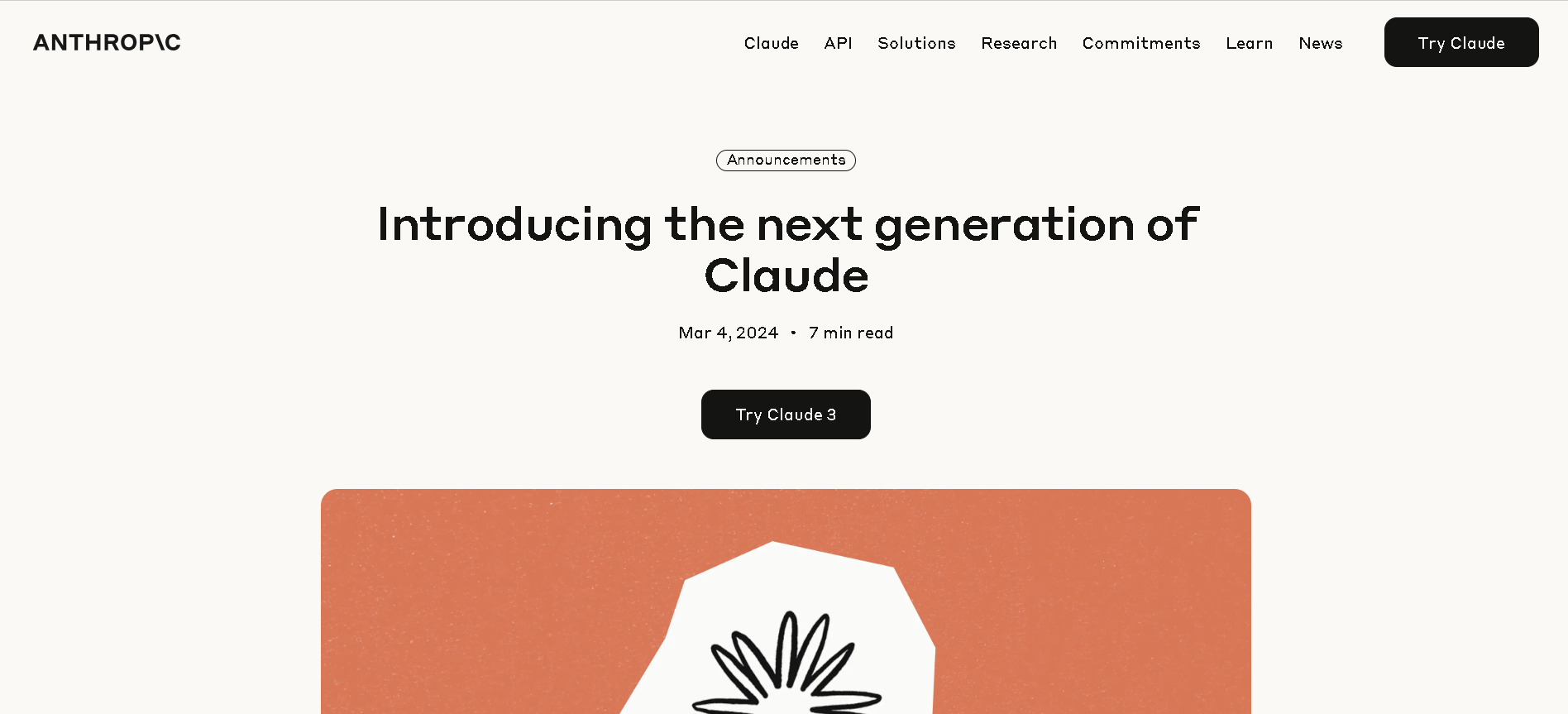

Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
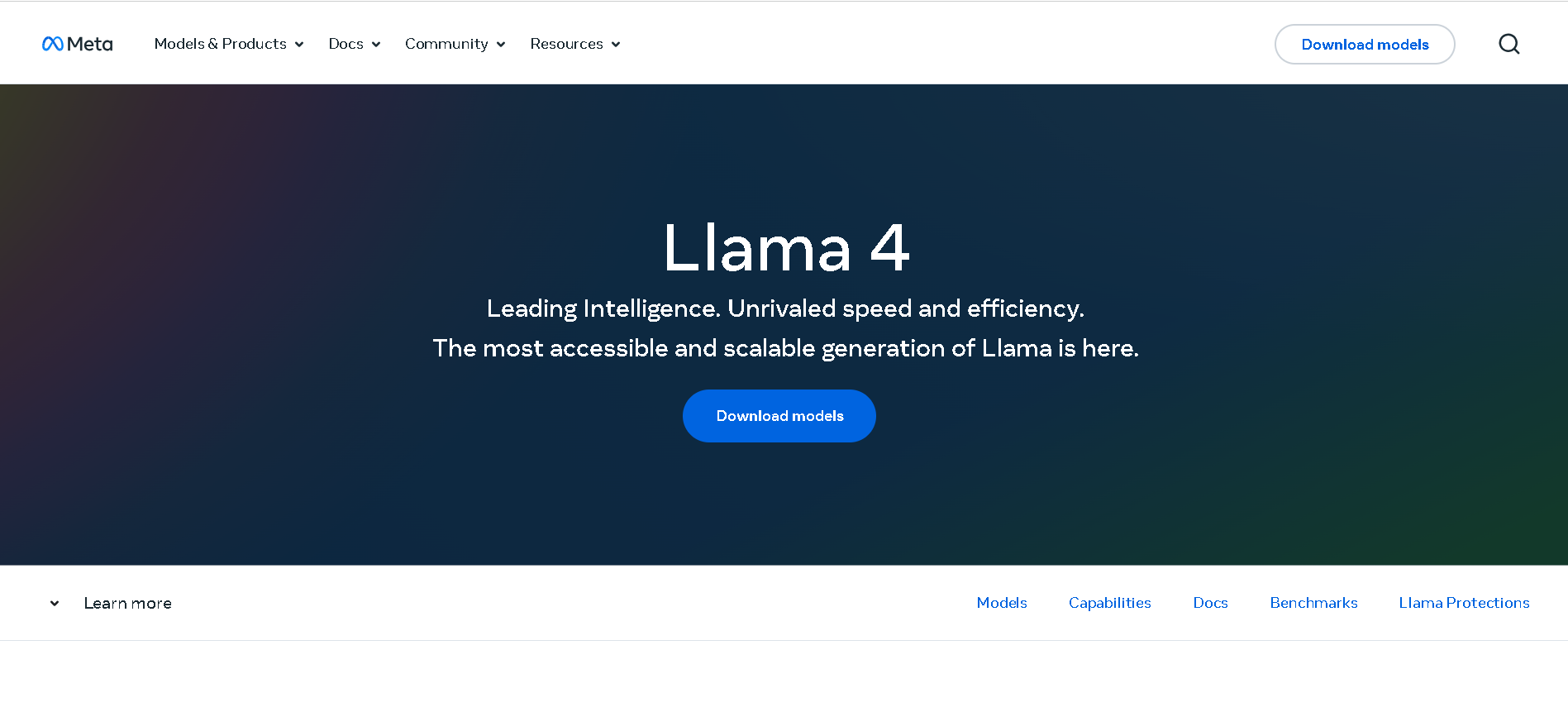
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.

DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.

Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.

Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
BharatGPT AI
BharatGPT is India’s first large-scale multilingual foundational model designed specifically for the Indian linguistic and cultural context. Developed by CoRover.ai in collaboration with the Indian government and major technology partners, BharatGPT aims to bring generative AI capabilities to India’s diverse population by supporting voice, text, and multimodal inputs across more than 22 Indian languages and 120 dialects. Unlike traditional English-centric LLMs, BharatGPT focuses on regional inclusivity — building AI agents that can understand, converse, and generate contextually accurate outputs in languages like Hindi, Tamil, Bengali, Marathi, Telugu, Kannada, and more. The platform is part of India’s broader initiative to create sovereign AI infrastructure, ensuring data residency, security, and compliance under Indian regulations.
BharatGPT AI
BharatGPT is India’s first large-scale multilingual foundational model designed specifically for the Indian linguistic and cultural context. Developed by CoRover.ai in collaboration with the Indian government and major technology partners, BharatGPT aims to bring generative AI capabilities to India’s diverse population by supporting voice, text, and multimodal inputs across more than 22 Indian languages and 120 dialects. Unlike traditional English-centric LLMs, BharatGPT focuses on regional inclusivity — building AI agents that can understand, converse, and generate contextually accurate outputs in languages like Hindi, Tamil, Bengali, Marathi, Telugu, Kannada, and more. The platform is part of India’s broader initiative to create sovereign AI infrastructure, ensuring data residency, security, and compliance under Indian regulations.
BharatGPT AI
BharatGPT is India’s first large-scale multilingual foundational model designed specifically for the Indian linguistic and cultural context. Developed by CoRover.ai in collaboration with the Indian government and major technology partners, BharatGPT aims to bring generative AI capabilities to India’s diverse population by supporting voice, text, and multimodal inputs across more than 22 Indian languages and 120 dialects. Unlike traditional English-centric LLMs, BharatGPT focuses on regional inclusivity — building AI agents that can understand, converse, and generate contextually accurate outputs in languages like Hindi, Tamil, Bengali, Marathi, Telugu, Kannada, and more. The platform is part of India’s broader initiative to create sovereign AI infrastructure, ensuring data residency, security, and compliance under Indian regulations.

LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai