- Developers: Building applications that rely on structured data output from LLMs.
- Machine Learning Engineers: Integrating LLMs into workflows where reliable data formats are crucial.
- Data Scientists: Extracting specific, structured information from large volumes of text generated by LLMs.
- AI Researchers: Experimenting with and optimizing LLM interactions for structured output.
- Anyone working with LLMs: Who struggles with inconsistent or verbose LLM responses and needs clean, formatted data.
- Software Architects: Designing robust systems that leverage LLMs for data processing and automation.
How to Use BoundaryML.com?
- Installation: Begin by installing BAML into your Python environment using pip: `pip install baml-py`.
- Define Schema & Functions: Use BAML's expressive syntax to define the desired output schema (e.g., JSON structure) and functions for your LLM interactions. This transforms prompt engineering into a more structured coding approach.
- Integrate with LLMs: Connect BAML with your chosen LLM (e.g., GPT-3.5, GPT-4o). BAML's parser and function-calling capabilities work across various models.
- Develop in Playground: Utilize the BAML playground environment to develop, test, and refine your structured text generation workflows.
- Get Structured Output: Execute your BAML code. The parser ensures robust JSON error correction, handles "LLM yapping," and coerces output to your defined schema, providing reliable structured data.
- LLM-Specific Parser: Features a robust parser built from the ground up for LLMs, offering superior JSON error correction, immunity to irrelevant LLM chatter ("LLM yapping"), and automatic schema coercion.
- Universal Function-Calling: Enables reliable function-calling across virtually every LLM, providing consistent performance regardless of the underlying model.
- State-of-the-Art Performance: Achieves benchmark-setting results in function-calling, particularly noted for its efficiency and token reduction with models like GPT 3.5.
- Prompt Engineering as Code: Transforms the often-unpredictable art of prompt engineering into a structured, type-safe coding process with features like classifiers, multimodal inputs, and dynamic prompts.
- Static Analysis & Type-Safety: Provides static analysis and type-safety for LLM interactions, reducing errors and increasing reliability in development.
- Simplifies the complex task of getting structured data from LLMs.
- Robust parser with excellent JSON error correction and "anti-yapping" capabilities.
- Enables reliable function-calling across a wide range of LLM models.
- Transforms prompt engineering into a more reliable and systematic coding process.
- Achieves state-of-the-art results in LLM function-calling benchmarks.
- Offers features like static analysis and type-safety for increased development reliability.
- Supports multi-modal inputs, expanding LLM interaction possibilities.
- Includes a dedicated playground for easier development and testing.
- Helps in reducing token usage and improving efficiency for LLM interactions.
- Primarily a developer tool, not suitable for non-technical users seeking a no-code solution.
- Requires installation and familiarity with coding environments (e.g., Python).
- Learning curve associated with adopting a new language syntax (BAML).
- Currently focused on structured text generation; might not cover all LLM interaction needs.
- Specific performance gains or limitations for lesser-known LLMs are not explicitly detailed.
Starter
$ 0.00
VSCode playground testing, with multimodal capabilities
VSCode playground real-time prompt preview
Community support via Discord and Github
Enterprise
custom
Dedicated Slack channel
Architectural reviews with our experienced AI engineers
Prioritized feature requests
Access to Boundary Studio
Boundary Studio includes observability, data labeling, fine-tuning engineering support and more
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
Codestral 25.01 is Mistral AI’s upgraded code-generation model, released January 13, 2025. Featuring a more efficient architecture and improved tokenizer, it delivers code completion and intelligence about 2× faster than its predecessor, with support for fill-in-the-middle (FIM), code correction, test generation, and proficiency in over 80 programming languages, all within a 256K-token context window.
Codestral 25.01 is Mistral AI’s upgraded code-generation model, released January 13, 2025. Featuring a more efficient architecture and improved tokenizer, it delivers code completion and intelligence about 2× faster than its predecessor, with support for fill-in-the-middle (FIM), code correction, test generation, and proficiency in over 80 programming languages, all within a 256K-token context window.
Codestral 25.01 is Mistral AI’s upgraded code-generation model, released January 13, 2025. Featuring a more efficient architecture and improved tokenizer, it delivers code completion and intelligence about 2× faster than its predecessor, with support for fill-in-the-middle (FIM), code correction, test generation, and proficiency in over 80 programming languages, all within a 256K-token context window.
Ministral refers to Mistral AI’s new “Les Ministraux” series—comprising Ministral 3B and Ministral 8B—launched in October 2024. These are ultra-efficient, open-weight LLMs optimized for on-device and edge computing, with a massive 128 K‑token context window. They offer strong reasoning, knowledge, multilingual support, and function-calling capabilities, outperforming previous models in the sub‑10B parameter class
Ministral refers to Mistral AI’s new “Les Ministraux” series—comprising Ministral 3B and Ministral 8B—launched in October 2024. These are ultra-efficient, open-weight LLMs optimized for on-device and edge computing, with a massive 128 K‑token context window. They offer strong reasoning, knowledge, multilingual support, and function-calling capabilities, outperforming previous models in the sub‑10B parameter class
Ministral refers to Mistral AI’s new “Les Ministraux” series—comprising Ministral 3B and Ministral 8B—launched in October 2024. These are ultra-efficient, open-weight LLMs optimized for on-device and edge computing, with a massive 128 K‑token context window. They offer strong reasoning, knowledge, multilingual support, and function-calling capabilities, outperforming previous models in the sub‑10B parameter class
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.

Teammately
Teammately.ai is an AI agent specifically designed for AI engineers to streamline and accelerate the development of robust, production-level AI applications. Its primary purpose is to automate various critical stages of the AI development lifecycle, from prompt generation and self-refinement to comprehensive evaluation, efficient RAG (Retrieval Augmented Generation) building, and interpretable observability, ensuring AI solutions are robust and less prone to failure.
Teammately
Teammately.ai is an AI agent specifically designed for AI engineers to streamline and accelerate the development of robust, production-level AI applications. Its primary purpose is to automate various critical stages of the AI development lifecycle, from prompt generation and self-refinement to comprehensive evaluation, efficient RAG (Retrieval Augmented Generation) building, and interpretable observability, ensuring AI solutions are robust and less prone to failure.
Teammately
Teammately.ai is an AI agent specifically designed for AI engineers to streamline and accelerate the development of robust, production-level AI applications. Its primary purpose is to automate various critical stages of the AI development lifecycle, from prompt generation and self-refinement to comprehensive evaluation, efficient RAG (Retrieval Augmented Generation) building, and interpretable observability, ensuring AI solutions are robust and less prone to failure.
Chat 01 AI
Chat01.ai is a platform that offers free and unlimited chat with OpenAI 01, a new series of AI models. These models are specifically designed for complex reasoning and problem-solving in areas such as science, coding, and math, by employing a "think more before responding" approach, trying different strategies, and recognizing mistakes.
Chat 01 AI
Chat01.ai is a platform that offers free and unlimited chat with OpenAI 01, a new series of AI models. These models are specifically designed for complex reasoning and problem-solving in areas such as science, coding, and math, by employing a "think more before responding" approach, trying different strategies, and recognizing mistakes.
Chat 01 AI
Chat01.ai is a platform that offers free and unlimited chat with OpenAI 01, a new series of AI models. These models are specifically designed for complex reasoning and problem-solving in areas such as science, coding, and math, by employing a "think more before responding" approach, trying different strategies, and recognizing mistakes.

inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
Genloop AI
Genloop is a platform that empowers enterprises to build, deploy, and manage custom, private large language models (LLMs) tailored to their business data and requirements — all with minimal development effort. It turns enterprise data into intelligent, conversational insights, allowing users to ask business questions in natural language and receive actionable analysis instantly. The platform enables organizations to confidently manage their data-driven decision-making by offering advanced fine-tuning, automation, and deployment tools. Businesses can transform their existing datasets into private AI assistants that deliver accurate insights, while maintaining complete security and compliance. Genloop’s focus is on bridging the gap between AI and enterprise data operations, providing a scalable, trustworthy, and adaptive solution for teams that want to leverage AI without extensive coding or infrastructure complexity.
Genloop AI
Genloop is a platform that empowers enterprises to build, deploy, and manage custom, private large language models (LLMs) tailored to their business data and requirements — all with minimal development effort. It turns enterprise data into intelligent, conversational insights, allowing users to ask business questions in natural language and receive actionable analysis instantly. The platform enables organizations to confidently manage their data-driven decision-making by offering advanced fine-tuning, automation, and deployment tools. Businesses can transform their existing datasets into private AI assistants that deliver accurate insights, while maintaining complete security and compliance. Genloop’s focus is on bridging the gap between AI and enterprise data operations, providing a scalable, trustworthy, and adaptive solution for teams that want to leverage AI without extensive coding or infrastructure complexity.
Genloop AI
Genloop is a platform that empowers enterprises to build, deploy, and manage custom, private large language models (LLMs) tailored to their business data and requirements — all with minimal development effort. It turns enterprise data into intelligent, conversational insights, allowing users to ask business questions in natural language and receive actionable analysis instantly. The platform enables organizations to confidently manage their data-driven decision-making by offering advanced fine-tuning, automation, and deployment tools. Businesses can transform their existing datasets into private AI assistants that deliver accurate insights, while maintaining complete security and compliance. Genloop’s focus is on bridging the gap between AI and enterprise data operations, providing a scalable, trustworthy, and adaptive solution for teams that want to leverage AI without extensive coding or infrastructure complexity.
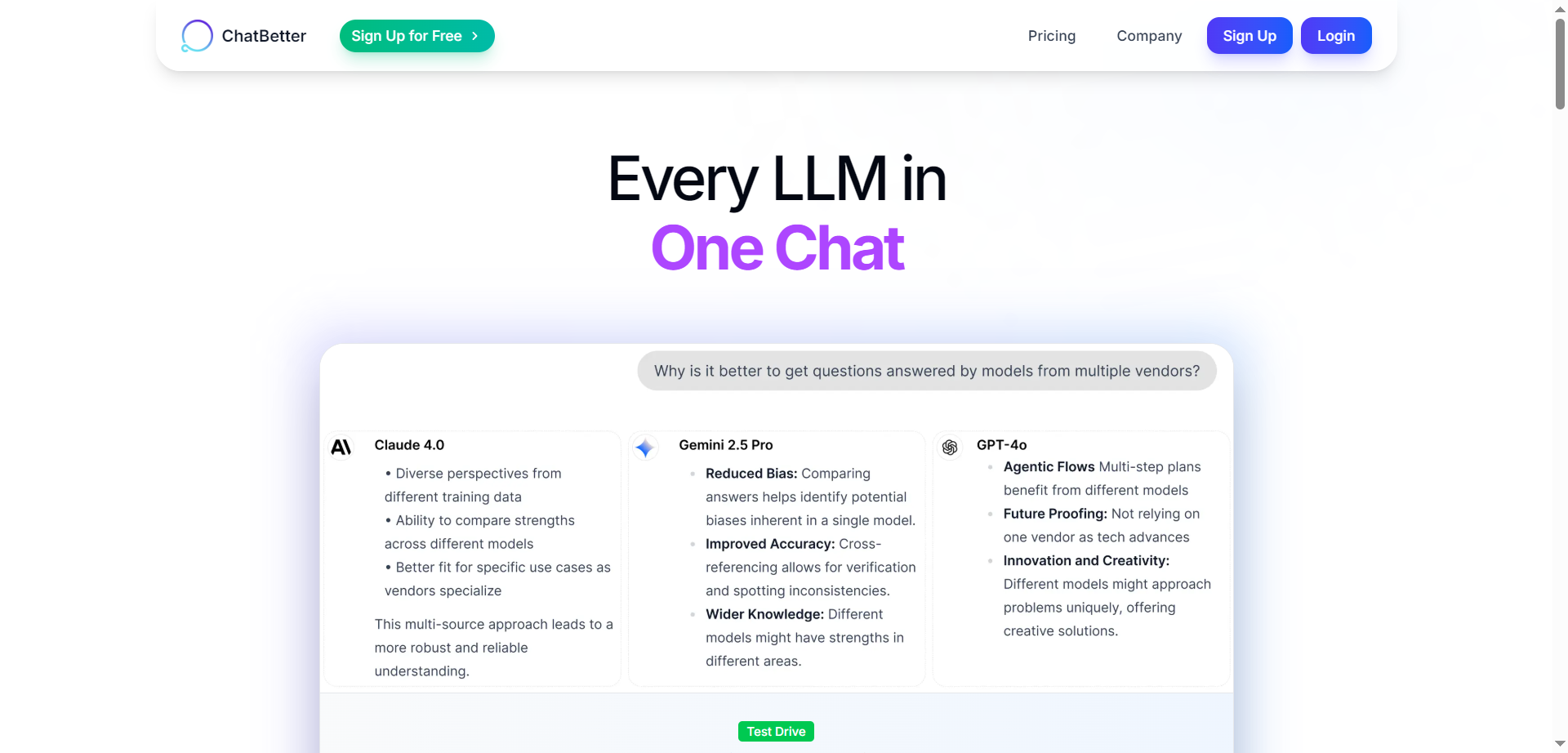

ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
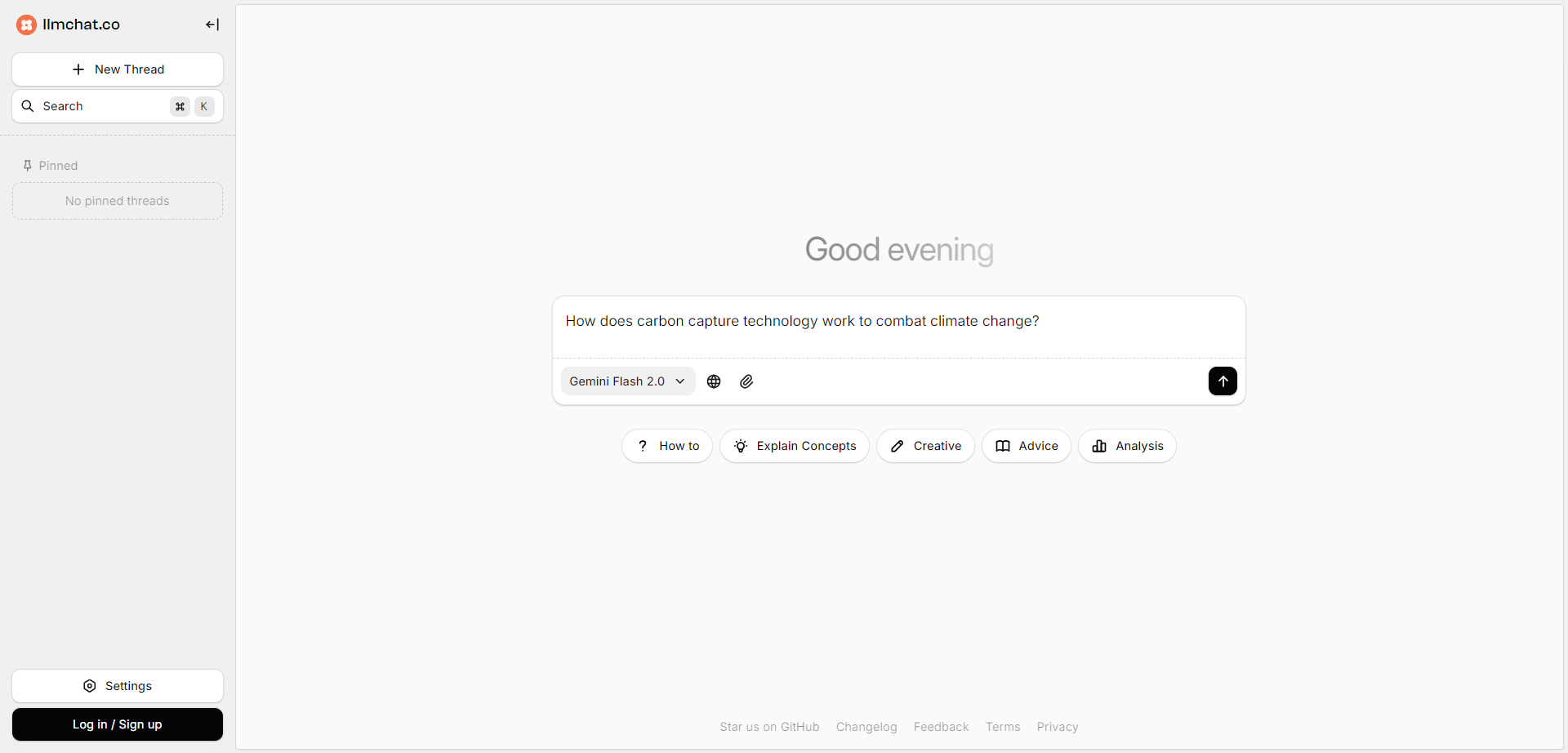

LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
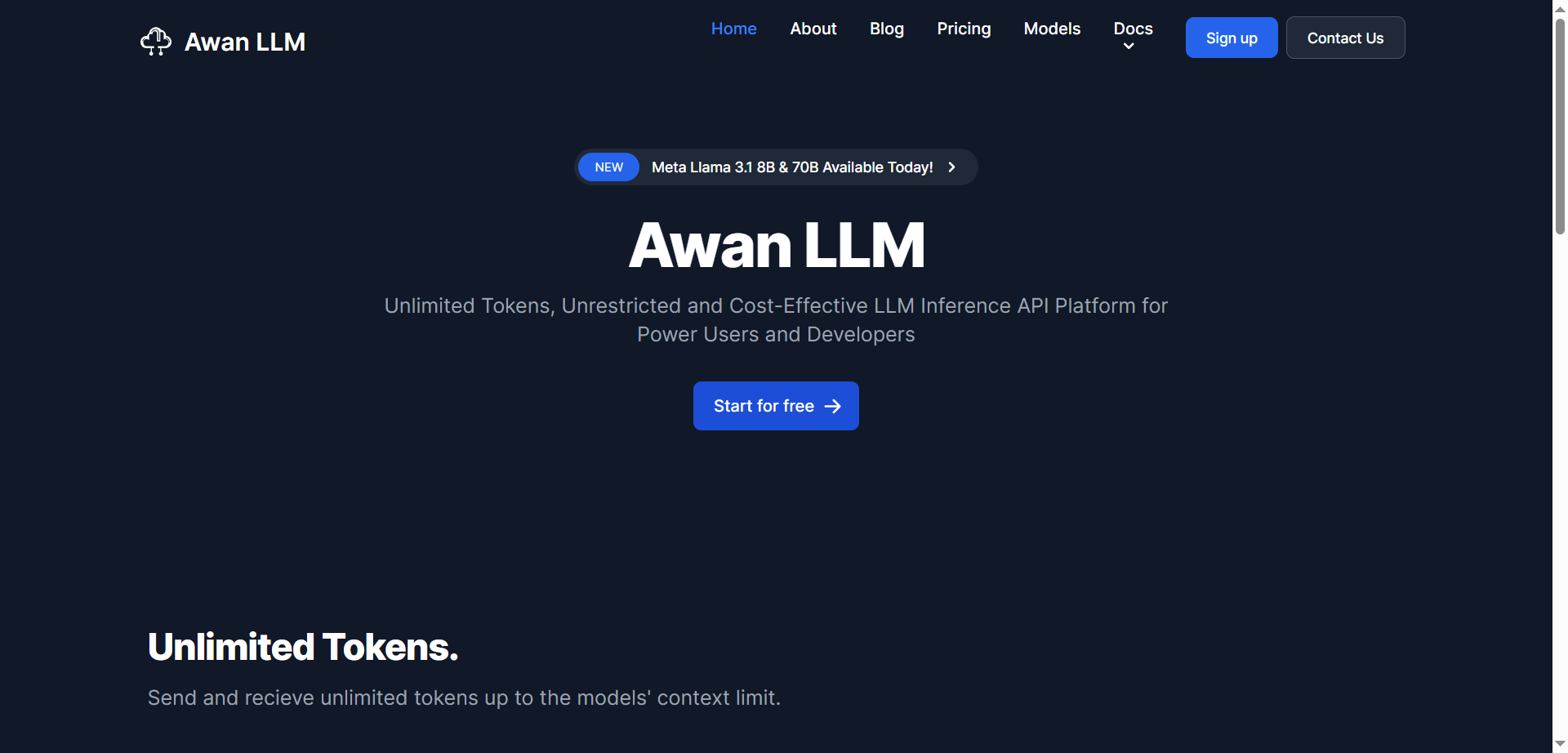

Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
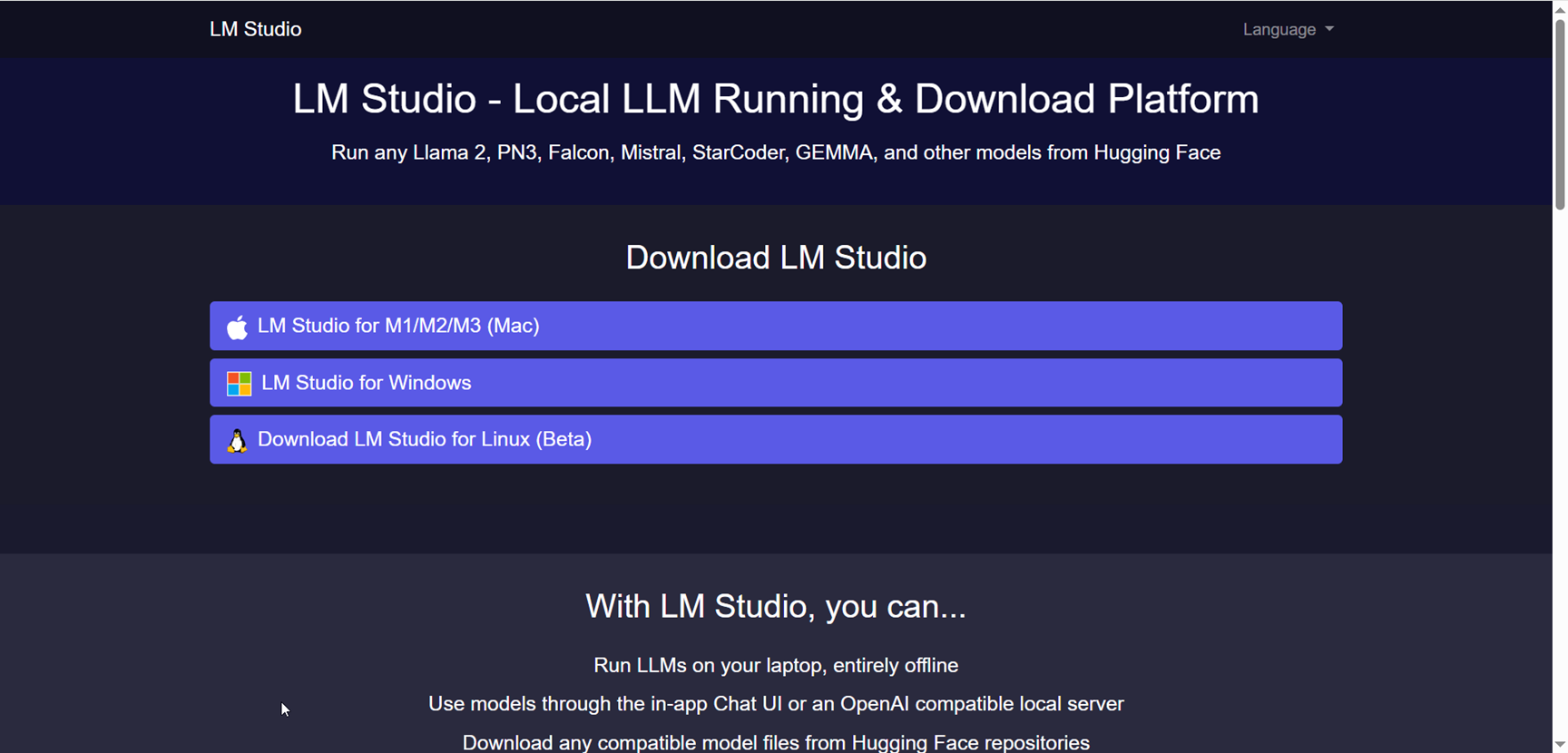
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
ModelRiver
ModelRiver is a unified AI integration platform that allows developers to access multiple AI providers through a single API. Instead of integrating each model separately, teams integrate once and gain access to a wide range of AI services. Built-in failover ensures applications remain online even if one provider experiences issues. ModelRiver is designed for reliability, scalability, and simplicity, making it ideal for production environments that depend on AI availability.
ModelRiver
ModelRiver is a unified AI integration platform that allows developers to access multiple AI providers through a single API. Instead of integrating each model separately, teams integrate once and gain access to a wide range of AI services. Built-in failover ensures applications remain online even if one provider experiences issues. ModelRiver is designed for reliability, scalability, and simplicity, making it ideal for production environments that depend on AI availability.
ModelRiver
ModelRiver is a unified AI integration platform that allows developers to access multiple AI providers through a single API. Instead of integrating each model separately, teams integrate once and gain access to a wide range of AI services. Built-in failover ensures applications remain online even if one provider experiences issues. ModelRiver is designed for reliability, scalability, and simplicity, making it ideal for production environments that depend on AI availability.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai