- AI Researchers & Model Developers: To benchmark their models and understand strengths/weaknesses in human judgments.
- AI Labs & Open-Source Projects: Wanting fair, transparent comparisons across many models.
- Prompt Engineers: Curious about which prompts lead to “wins” in human preference.
- Product Teams: Choosing which LLM to embed based on user perception of quality.
- AI Enthusiasts & Early Adopters: Who enjoy exploring model performance across different tasks.
- Enterprises Considering LLM Adoption: Want to pick models that perform well in realistic usage, not just in paper benchmarks.
How to Use It?
- Visit the Platform: Access the leaderboard or voting arena.
- Choose a Prompt: Use existing prompts or enter your own to compare model responses.
- View Model Responses: Two or more models respond to the same prompt.
- Cast a Vote: Decide which response you prefer.
- See Leaderboard Updates: As more votes accrue, rankings shift in real time.
- Use Additional Features: Try style control, prompt-based leaderboards, or view sampling rules.
- Human-Centered Evaluation: Feedback comes directly from people, capturing nuance beyond metrics.
- Transparent Methodology: Publishes rules for model sampling, evaluation standards, style/formatting controls.
- Prompt-to-Leaderboard Feature: Enables leaderboards customized to specific prompts.
- Community-Driven & Open Data: Large volume of votes, open feedback, and frequent feature suggestions.
- Real-Time Rankings: Leaderboards shift as new votes are cast, reflecting current preferences.
- Multi-Modal and Expanding Domains: While starting with chat, expanding into image models, different task types.
- Captures human judgments which reflect real-use quality
- Very transparent about how evaluations are done
- Allows custom prompt leaderboards for precise comparisons
- Frequent updates and active community engagement
- Useful for anyone choosing between LLMs based on how people perceive output
- Crowd-voted human preference can be noisy or subjective
- Models with more “visibility” may accrue more votes, biasing the leaderboard
- Some advanced features or enterprise evaluation services may be behind paywalls or require custom agreements
- Users need to try prompts multiple times to avoid outlier votes or misleading results
Free
Free
Custom
Custom Pricing.
- Premium features might require subscription.
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Yes — basic features (voting, leaderboards) are usable freely by anyone.
Yes — users can use built-in prompts or enter custom ones to compare model outputs.
Yes — rankings are updated in real time as more votes are cast.
Yes — the platform publishes sampling rules, evaluation methods, and style control information.
Yes — there are “AI Evaluations” services for labs and enterprises to get deeper, auditable feedback with SLAs.
Similar AI Tools

LM Studio
LM Studio is a local AI toolkit that empowers users to discover, download, and run Large Language Models (LLMs) directly on their personal computers. It provides a user-friendly interface to chat with models, set up a local LLM server for applications, and ensures complete data privacy as all processes occur locally on your machine.
LM Studio
LM Studio is a local AI toolkit that empowers users to discover, download, and run Large Language Models (LLMs) directly on their personal computers. It provides a user-friendly interface to chat with models, set up a local LLM server for applications, and ensures complete data privacy as all processes occur locally on your machine.
LM Studio
LM Studio is a local AI toolkit that empowers users to discover, download, and run Large Language Models (LLMs) directly on their personal computers. It provides a user-friendly interface to chat with models, set up a local LLM server for applications, and ensures complete data privacy as all processes occur locally on your machine.
PromptsLabs
PromptsLabs is an open-source library of curated prompts designed to test and evaluate the performance of large language models (LLMs). It allows users to explore, contribute, and request prompts to better understand LLM capabilities.
PromptsLabs
PromptsLabs is an open-source library of curated prompts designed to test and evaluate the performance of large language models (LLMs). It allows users to explore, contribute, and request prompts to better understand LLM capabilities.
PromptsLabs
PromptsLabs is an open-source library of curated prompts designed to test and evaluate the performance of large language models (LLMs). It allows users to explore, contribute, and request prompts to better understand LLM capabilities.
Genloop AI
Genloop is a platform that empowers enterprises to build, deploy, and manage custom, private large language models (LLMs) tailored to their business data and requirements — all with minimal development effort. It turns enterprise data into intelligent, conversational insights, allowing users to ask business questions in natural language and receive actionable analysis instantly. The platform enables organizations to confidently manage their data-driven decision-making by offering advanced fine-tuning, automation, and deployment tools. Businesses can transform their existing datasets into private AI assistants that deliver accurate insights, while maintaining complete security and compliance. Genloop’s focus is on bridging the gap between AI and enterprise data operations, providing a scalable, trustworthy, and adaptive solution for teams that want to leverage AI without extensive coding or infrastructure complexity.
Genloop AI
Genloop is a platform that empowers enterprises to build, deploy, and manage custom, private large language models (LLMs) tailored to their business data and requirements — all with minimal development effort. It turns enterprise data into intelligent, conversational insights, allowing users to ask business questions in natural language and receive actionable analysis instantly. The platform enables organizations to confidently manage their data-driven decision-making by offering advanced fine-tuning, automation, and deployment tools. Businesses can transform their existing datasets into private AI assistants that deliver accurate insights, while maintaining complete security and compliance. Genloop’s focus is on bridging the gap between AI and enterprise data operations, providing a scalable, trustworthy, and adaptive solution for teams that want to leverage AI without extensive coding or infrastructure complexity.
Genloop AI
Genloop is a platform that empowers enterprises to build, deploy, and manage custom, private large language models (LLMs) tailored to their business data and requirements — all with minimal development effort. It turns enterprise data into intelligent, conversational insights, allowing users to ask business questions in natural language and receive actionable analysis instantly. The platform enables organizations to confidently manage their data-driven decision-making by offering advanced fine-tuning, automation, and deployment tools. Businesses can transform their existing datasets into private AI assistants that deliver accurate insights, while maintaining complete security and compliance. Genloop’s focus is on bridging the gap between AI and enterprise data operations, providing a scalable, trustworthy, and adaptive solution for teams that want to leverage AI without extensive coding or infrastructure complexity.

ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.

Pruna AI
Pruna.ai is an AI optimization engine designed to make machine learning models faster, smaller, cheaper, and greener with minimal overhead. It leverages advanced compression algorithms like pruning, quantization, distillation, caching, and compilation to reduce model size and accelerate inference times. The platform supports various AI models including large language models, vision transformers, and speech recognition models, making it ideal for real-time applications such as autonomous systems and recommendation engines. Pruna.ai aims to lower computational costs, decrease energy consumption, and improve deployment scalability across cloud and on-premise environments while ensuring minimal loss of model quality.
Pruna AI
Pruna.ai is an AI optimization engine designed to make machine learning models faster, smaller, cheaper, and greener with minimal overhead. It leverages advanced compression algorithms like pruning, quantization, distillation, caching, and compilation to reduce model size and accelerate inference times. The platform supports various AI models including large language models, vision transformers, and speech recognition models, making it ideal for real-time applications such as autonomous systems and recommendation engines. Pruna.ai aims to lower computational costs, decrease energy consumption, and improve deployment scalability across cloud and on-premise environments while ensuring minimal loss of model quality.
Pruna AI
Pruna.ai is an AI optimization engine designed to make machine learning models faster, smaller, cheaper, and greener with minimal overhead. It leverages advanced compression algorithms like pruning, quantization, distillation, caching, and compilation to reduce model size and accelerate inference times. The platform supports various AI models including large language models, vision transformers, and speech recognition models, making it ideal for real-time applications such as autonomous systems and recommendation engines. Pruna.ai aims to lower computational costs, decrease energy consumption, and improve deployment scalability across cloud and on-premise environments while ensuring minimal loss of model quality.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
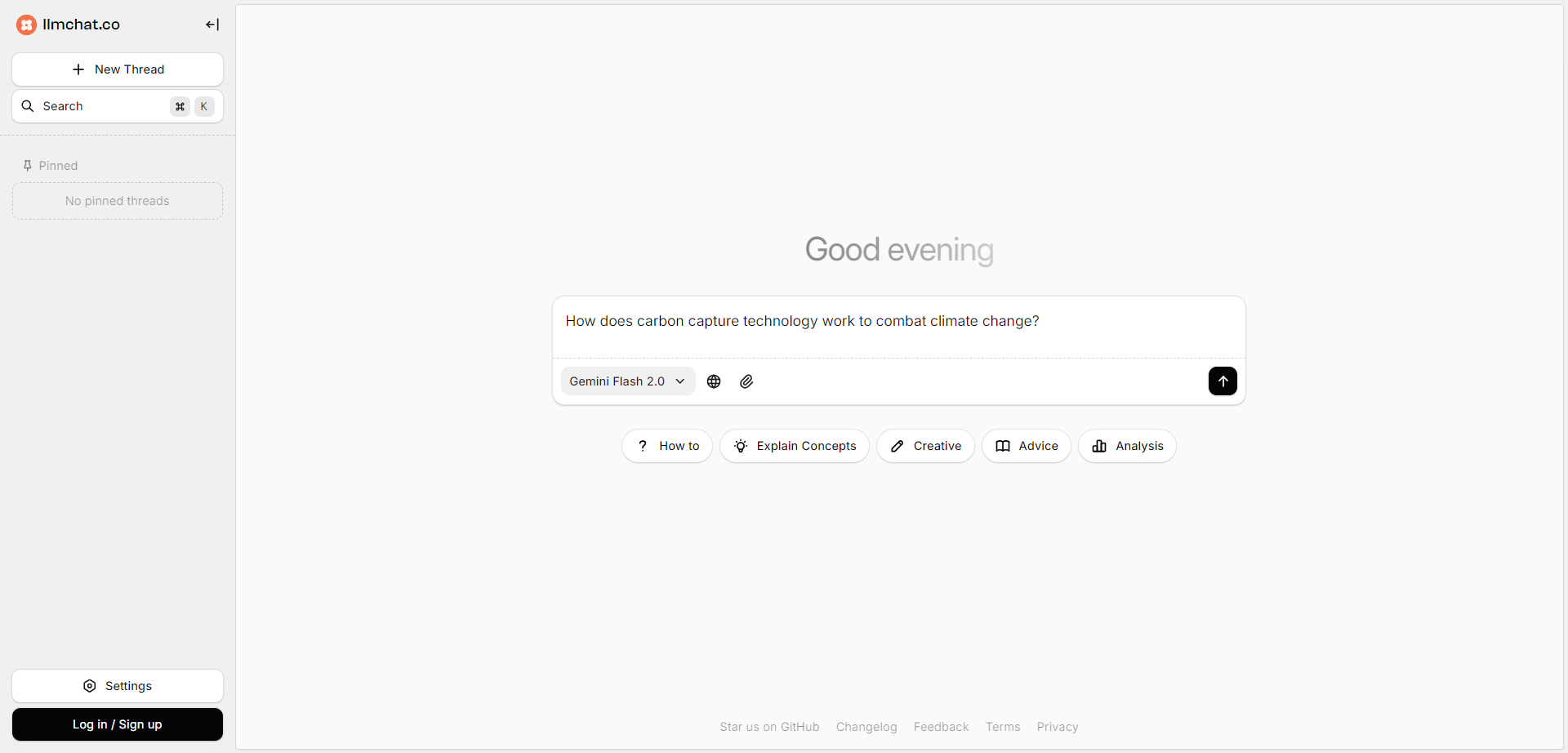

LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
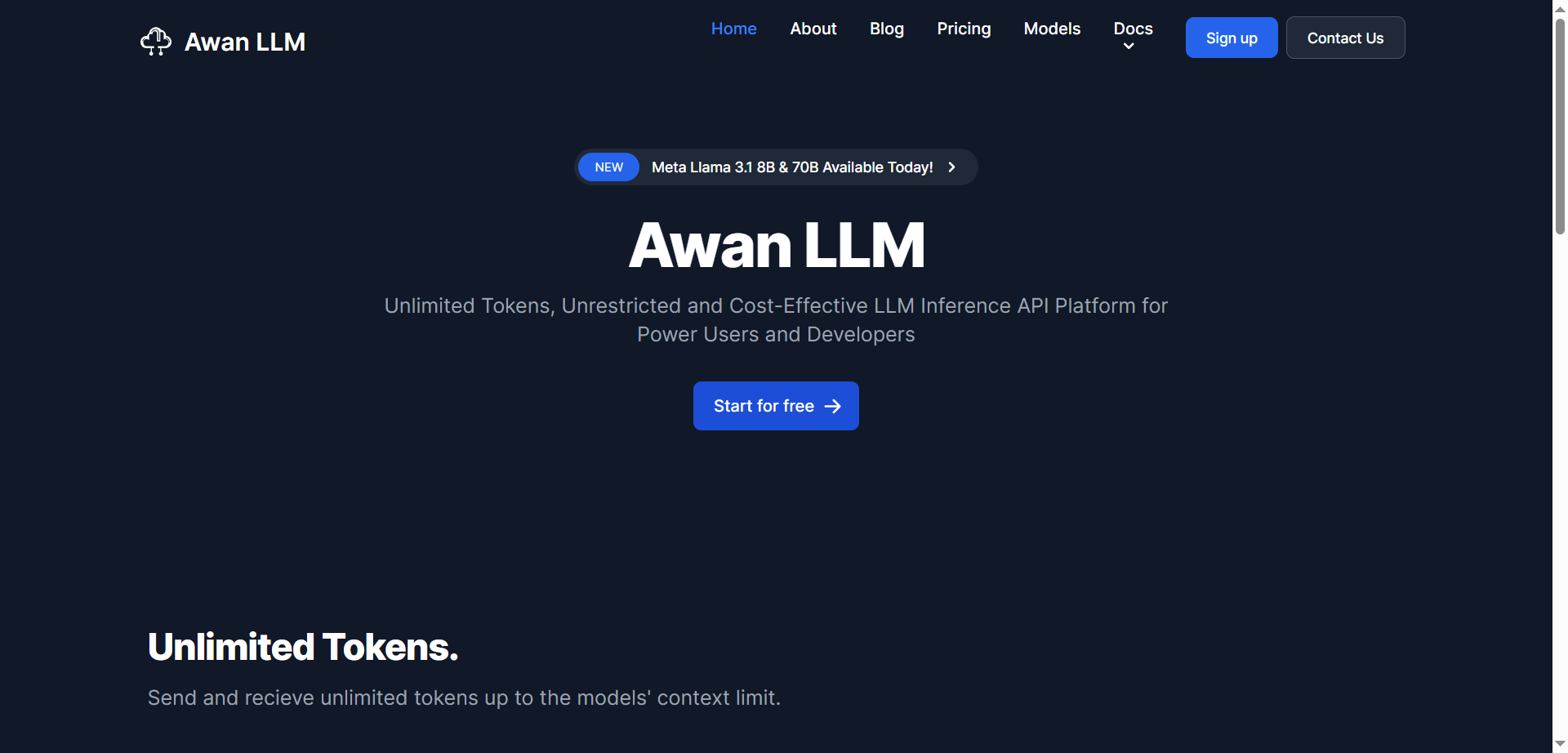

Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
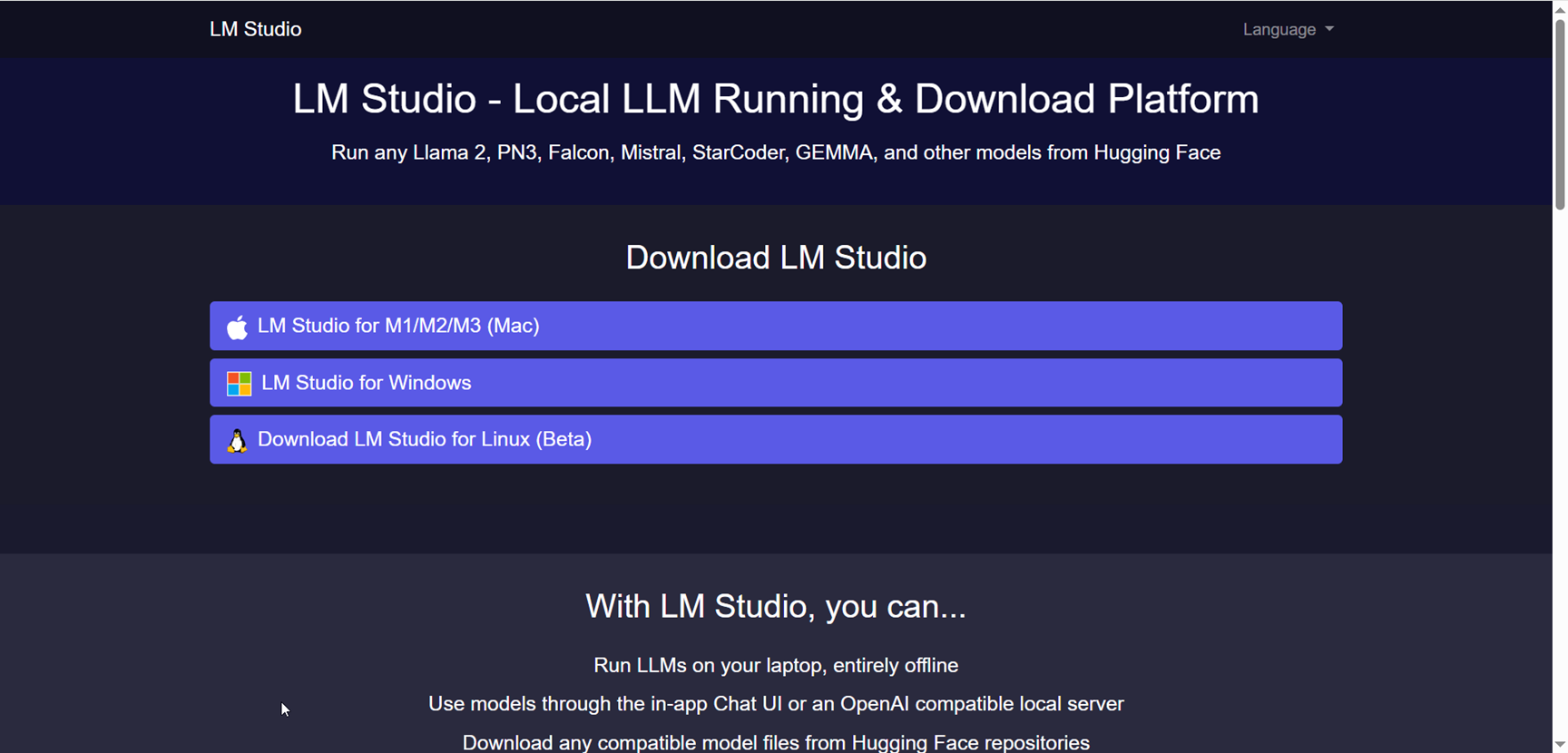
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
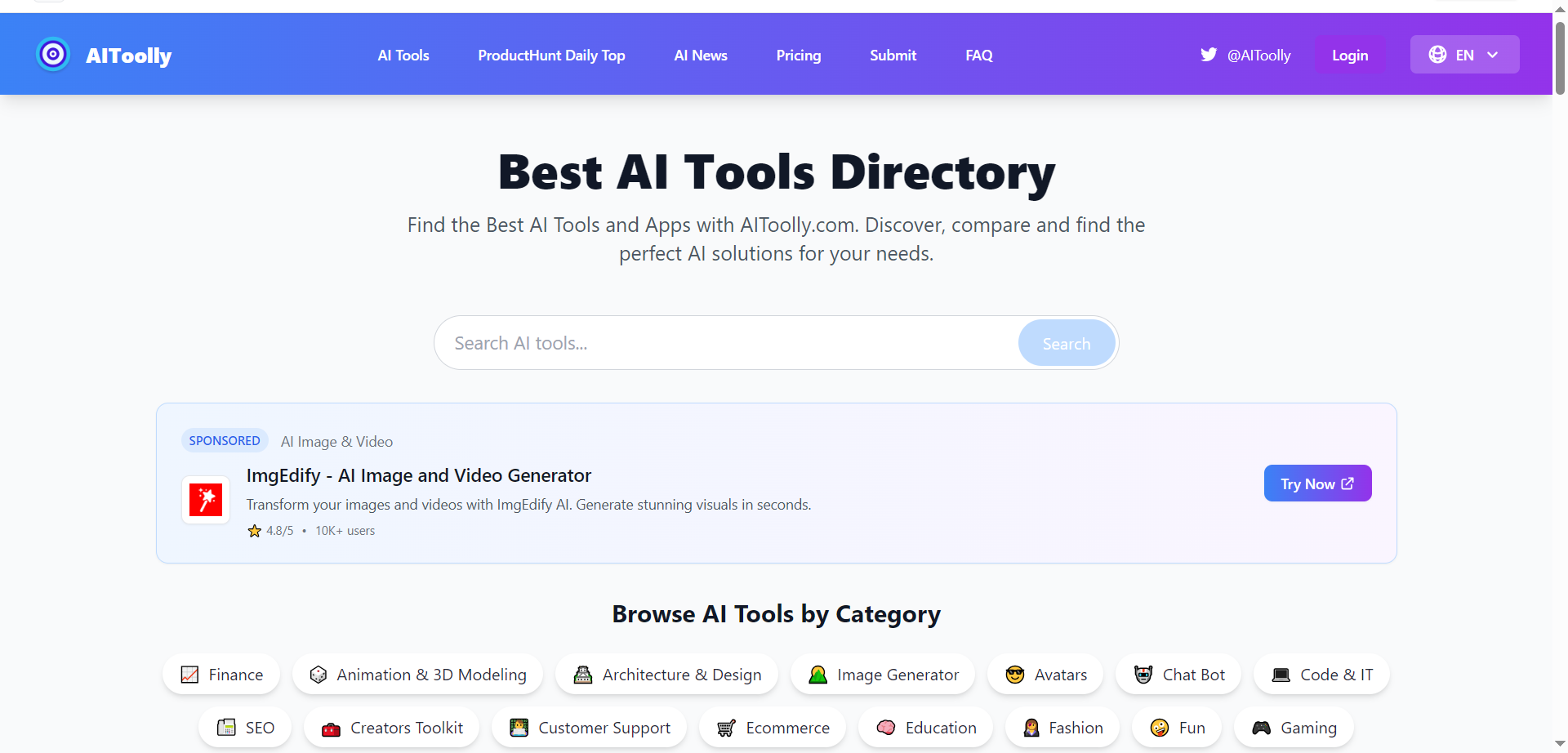
AIToolly
AIToolly is a comprehensive directory showcasing the best AI tools and applications across diverse categories like image generation, video editing, music creation, chatbots, gaming, and productivity solutions. Users can discover, compare, and explore curated listings of cutting-edge AI software with detailed descriptions, ratings, user stats, and direct links to try tools instantly. Featuring latest additions like Nano Banana for image editing, JSON to Video for structured cinematic clips, OCMaker AI for anime characters, and RoomDesignAI for interior visuals, the platform simplifies finding perfect AI solutions through searchable categories, weekly updates, and sponsored highlights for quick decision-making.
AIToolly
AIToolly is a comprehensive directory showcasing the best AI tools and applications across diverse categories like image generation, video editing, music creation, chatbots, gaming, and productivity solutions. Users can discover, compare, and explore curated listings of cutting-edge AI software with detailed descriptions, ratings, user stats, and direct links to try tools instantly. Featuring latest additions like Nano Banana for image editing, JSON to Video for structured cinematic clips, OCMaker AI for anime characters, and RoomDesignAI for interior visuals, the platform simplifies finding perfect AI solutions through searchable categories, weekly updates, and sponsored highlights for quick decision-making.
AIToolly
AIToolly is a comprehensive directory showcasing the best AI tools and applications across diverse categories like image generation, video editing, music creation, chatbots, gaming, and productivity solutions. Users can discover, compare, and explore curated listings of cutting-edge AI software with detailed descriptions, ratings, user stats, and direct links to try tools instantly. Featuring latest additions like Nano Banana for image editing, JSON to Video for structured cinematic clips, OCMaker AI for anime characters, and RoomDesignAI for interior visuals, the platform simplifies finding perfect AI solutions through searchable categories, weekly updates, and sponsored highlights for quick decision-making.
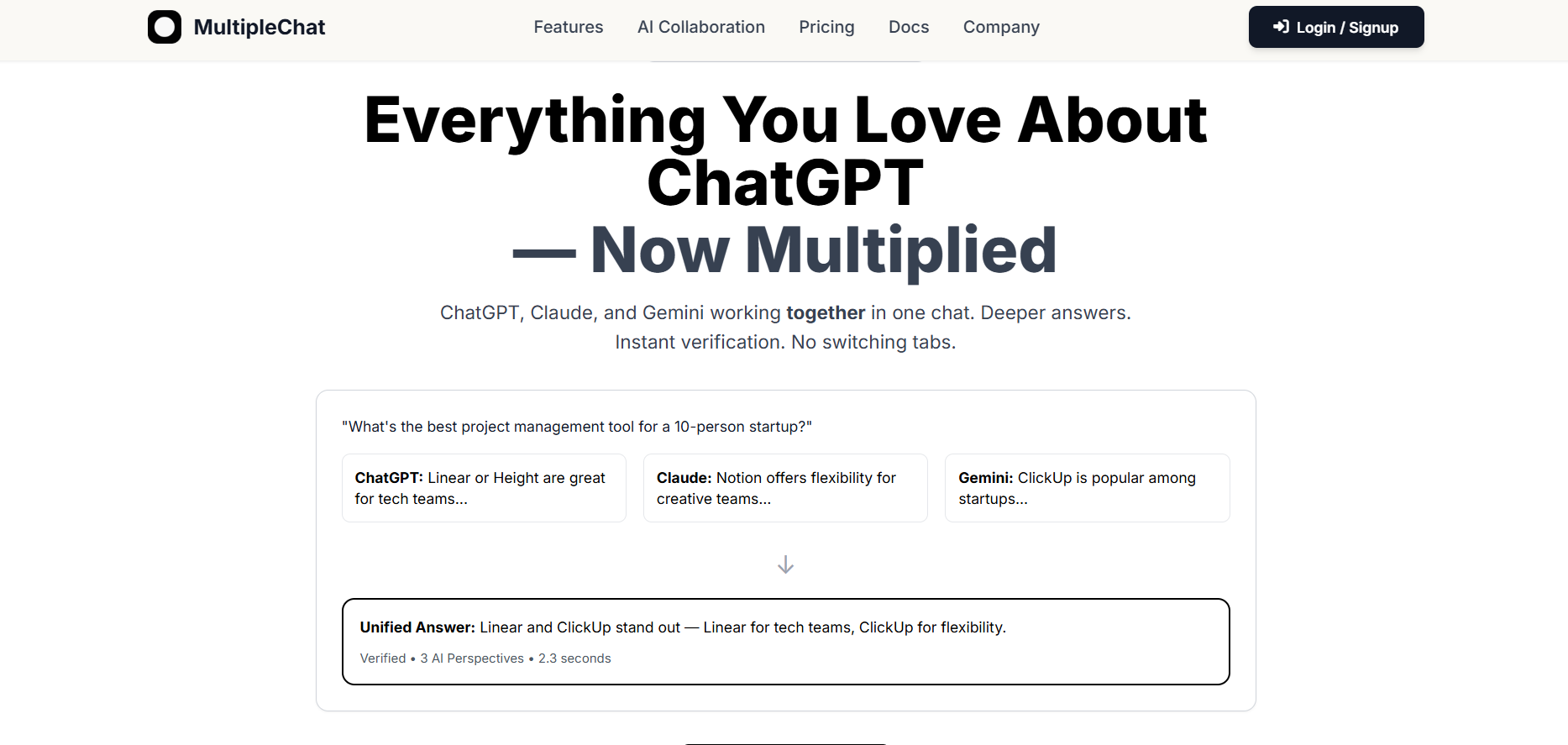
Multiple Chat
Multiple is a multi-model AI chat platform that allows users to interact with several leading AI models within a single interface. By combining responses from different AI systems, it enables deeper exploration, comparison, and verification of answers without switching tabs. The platform is designed for users who rely heavily on conversational AI and want improved accuracy, broader perspectives, and more confident outputs.
Multiple Chat
Multiple is a multi-model AI chat platform that allows users to interact with several leading AI models within a single interface. By combining responses from different AI systems, it enables deeper exploration, comparison, and verification of answers without switching tabs. The platform is designed for users who rely heavily on conversational AI and want improved accuracy, broader perspectives, and more confident outputs.
Multiple Chat
Multiple is a multi-model AI chat platform that allows users to interact with several leading AI models within a single interface. By combining responses from different AI systems, it enables deeper exploration, comparison, and verification of answers without switching tabs. The platform is designed for users who rely heavily on conversational AI and want improved accuracy, broader perspectives, and more confident outputs.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai