- Mobile & Edge Developers: Deploy powerful LLMs on laptops, smartphones, IoT, or robotics.
- Privacy-focused Teams: Use local AI for translation, assistants, or diagnostics without cloud dependency.
- Analysts & Researchers: Process long documents or datasets locally with large-context support.
- Enterprises & Integrators: Use as compact agents or function-calling intermediaries in multi-step workflows.
- Open-Source Advocates: Access open-weight models for customization, quantization, and fine-tuning.
How to Use Ministral?
- Choose a Model: `ministral-3b-latest` or `ministral-8b-latest` with 128K-token context via Mistral API or cloud partners.
- Run Locally or API: Weights available under research or commercial license; deployment via Hugging Face, Ollama, vLLM.
- Provide Prompts: Submit up to 128K tokens of text—or code—to tap into reasoning and generation features.
- Use for Functions & Chains: Integrates reasoning with function-calling and modular workflows.
- Monitor Cost: Input + output token pricing: $0.04/m for 3B, $0.10/m for 8B via API.
- Top Edge Performance: In sub-10B class, surpasses earlier Mistral 7B and rivals like Gemma 2 2B, Llama 3.1/3.2 8B.
- Massive Context Window: 128K tokens let you treat long documents like a novel or extensive codebase in one prompt.
- Function-Calling & Reasoning: Excellent at structured tasks, reasoning, and modular workflows.
- Low-Cost Edge Deployment: Token pricing makes them viable for local or hybrid AI products.
- Open Access & Licensing: Research weights for 8B; commercial license for 3B; full flexibility for developers.
- World-class edge LLM performance under 10B parameters
- Massive context window—128K tokens—for long workflows
- Supports reasoning and structured function-calling
- Cost-effective token pricing at $0.04–0.10 / M tokens
- Open-weight and accessible for customization
- Still not multimodal; text-only capability
- Requires quantization and edge-optimized runtime for efficient on-device use
- Commercial licensing needed for some uses of the 3B model
API only
$0.04/$0.04 per 1M tokens
$0.04 per 1M output tokens
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Embed
Mistral Embed is Mistral AI’s high-performance text embedding model designed for semantic retrieval, clustering, classification, and retrieval-augmented generation (RAG). With support for up to 8,192 tokens and producing 1,024-dimensional vectors, it delivers state-of-the-art semantic similarity and organization capabilities.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Mistral Moderation API is a content moderation service released in November 2024, powered by a fine-tuned version of Mistral’s Ministral 8B model. It classifies text across nine safety categories—sexual content, hate/discrimination, violence/threats, dangerous/criminal instructions, self‑harm, health, financial, legal, and personally identifiable information (PII). It offers two endpoints: one for raw text and one optimized for conversational content.
Boundary AI
BoundaryML.com introduces BAML, an expressive language specifically designed for structured text generation with Large Language Models (LLMs). Its primary purpose is to simplify and enhance the process of obtaining structured data (like JSON) from LLMs, moving beyond the challenges of traditional methods by providing robust parsing, error correction, and reliable function-calling capabilities.
Boundary AI
BoundaryML.com introduces BAML, an expressive language specifically designed for structured text generation with Large Language Models (LLMs). Its primary purpose is to simplify and enhance the process of obtaining structured data (like JSON) from LLMs, moving beyond the challenges of traditional methods by providing robust parsing, error correction, and reliable function-calling capabilities.
Boundary AI
BoundaryML.com introduces BAML, an expressive language specifically designed for structured text generation with Large Language Models (LLMs). Its primary purpose is to simplify and enhance the process of obtaining structured data (like JSON) from LLMs, moving beyond the challenges of traditional methods by providing robust parsing, error correction, and reliable function-calling capabilities.
Batteries Included
Batteries Included is a self-hosted AI platform designed to provide the necessary infrastructure for building and deploying AI applications. Its primary purpose is to simplify the deployment of large language models (LLMs), vector databases, and Jupyter notebooks, offering enterprise-grade tools similar to those used by hyperscalers, but within a user's self-hosted environment.
Batteries Included
Batteries Included is a self-hosted AI platform designed to provide the necessary infrastructure for building and deploying AI applications. Its primary purpose is to simplify the deployment of large language models (LLMs), vector databases, and Jupyter notebooks, offering enterprise-grade tools similar to those used by hyperscalers, but within a user's self-hosted environment.
Batteries Included
Batteries Included is a self-hosted AI platform designed to provide the necessary infrastructure for building and deploying AI applications. Its primary purpose is to simplify the deployment of large language models (LLMs), vector databases, and Jupyter notebooks, offering enterprise-grade tools similar to those used by hyperscalers, but within a user's self-hosted environment.
Solar Mini is Upstage’s compact, high-performance large language model (LLM) with under 30 billion parameters, engineered for exceptional speed and efficiency without sacrificing quality. It outperforms comparable models like Llama2, Mistral 7B, and Ko-Alpaca on major benchmarks, delivering responses similar to GPT-3.5 but 2.5 times faster. Thanks to its innovative Depth Up-scaling (DUS) and continued pre-training, Solar Mini is easily customized for domain-specific tasks, supports on-device deployment, and is especially suited for decentralized, responsive AI applications.
Solar Mini is Upstage’s compact, high-performance large language model (LLM) with under 30 billion parameters, engineered for exceptional speed and efficiency without sacrificing quality. It outperforms comparable models like Llama2, Mistral 7B, and Ko-Alpaca on major benchmarks, delivering responses similar to GPT-3.5 but 2.5 times faster. Thanks to its innovative Depth Up-scaling (DUS) and continued pre-training, Solar Mini is easily customized for domain-specific tasks, supports on-device deployment, and is especially suited for decentralized, responsive AI applications.
Solar Mini is Upstage’s compact, high-performance large language model (LLM) with under 30 billion parameters, engineered for exceptional speed and efficiency without sacrificing quality. It outperforms comparable models like Llama2, Mistral 7B, and Ko-Alpaca on major benchmarks, delivering responses similar to GPT-3.5 but 2.5 times faster. Thanks to its innovative Depth Up-scaling (DUS) and continued pre-training, Solar Mini is easily customized for domain-specific tasks, supports on-device deployment, and is especially suited for decentralized, responsive AI applications.
WebDev Arena
LMArena is an open, crowdsourced platform for evaluating large language models (LLMs) based on human preferences. Rather than relying purely on automated benchmarks, it presents paired responses from different models to users, who vote for which is better. These votes build live leaderboards, revealing which models perform best in real-use scenarios. Key features include prompt-to-leaderboard comparison, transparent evaluation methods, style control for how responses are formatted, and auditability of feedback data. The platform is particularly valuable for researchers, developers, and AI labs that want to understand how their models compare when judged by real people, not just metrics.
WebDev Arena
LMArena is an open, crowdsourced platform for evaluating large language models (LLMs) based on human preferences. Rather than relying purely on automated benchmarks, it presents paired responses from different models to users, who vote for which is better. These votes build live leaderboards, revealing which models perform best in real-use scenarios. Key features include prompt-to-leaderboard comparison, transparent evaluation methods, style control for how responses are formatted, and auditability of feedback data. The platform is particularly valuable for researchers, developers, and AI labs that want to understand how their models compare when judged by real people, not just metrics.
WebDev Arena
LMArena is an open, crowdsourced platform for evaluating large language models (LLMs) based on human preferences. Rather than relying purely on automated benchmarks, it presents paired responses from different models to users, who vote for which is better. These votes build live leaderboards, revealing which models perform best in real-use scenarios. Key features include prompt-to-leaderboard comparison, transparent evaluation methods, style control for how responses are formatted, and auditability of feedback data. The platform is particularly valuable for researchers, developers, and AI labs that want to understand how their models compare when judged by real people, not just metrics.

Unsloth AI
Unsloth.AI is an open-source platform designed to accelerate and simplify the fine-tuning of large language models (LLMs). By leveraging manual mathematical derivations, custom GPU kernels, and efficient optimization techniques, Unsloth achieves up to 30x faster training speeds compared to traditional methods, without compromising model accuracy. It supports a wide range of popular models, including Llama, Mistral, Gemma, and BERT, and works seamlessly on various GPUs, from consumer-grade Tesla T4 to high-end H100, as well as AMD and Intel GPUs. Unsloth empowers developers, researchers, and AI enthusiasts to fine-tune models efficiently, even with limited computational resources, democratizing access to advanced AI model customization. With a focus on performance, scalability, and flexibility, Unsloth.AI is suitable for both academic research and commercial applications, helping users deploy specialized AI solutions faster and more effectively.
Unsloth AI
Unsloth.AI is an open-source platform designed to accelerate and simplify the fine-tuning of large language models (LLMs). By leveraging manual mathematical derivations, custom GPU kernels, and efficient optimization techniques, Unsloth achieves up to 30x faster training speeds compared to traditional methods, without compromising model accuracy. It supports a wide range of popular models, including Llama, Mistral, Gemma, and BERT, and works seamlessly on various GPUs, from consumer-grade Tesla T4 to high-end H100, as well as AMD and Intel GPUs. Unsloth empowers developers, researchers, and AI enthusiasts to fine-tune models efficiently, even with limited computational resources, democratizing access to advanced AI model customization. With a focus on performance, scalability, and flexibility, Unsloth.AI is suitable for both academic research and commercial applications, helping users deploy specialized AI solutions faster and more effectively.
Unsloth AI
Unsloth.AI is an open-source platform designed to accelerate and simplify the fine-tuning of large language models (LLMs). By leveraging manual mathematical derivations, custom GPU kernels, and efficient optimization techniques, Unsloth achieves up to 30x faster training speeds compared to traditional methods, without compromising model accuracy. It supports a wide range of popular models, including Llama, Mistral, Gemma, and BERT, and works seamlessly on various GPUs, from consumer-grade Tesla T4 to high-end H100, as well as AMD and Intel GPUs. Unsloth empowers developers, researchers, and AI enthusiasts to fine-tune models efficiently, even with limited computational resources, democratizing access to advanced AI model customization. With a focus on performance, scalability, and flexibility, Unsloth.AI is suitable for both academic research and commercial applications, helping users deploy specialized AI solutions faster and more effectively.
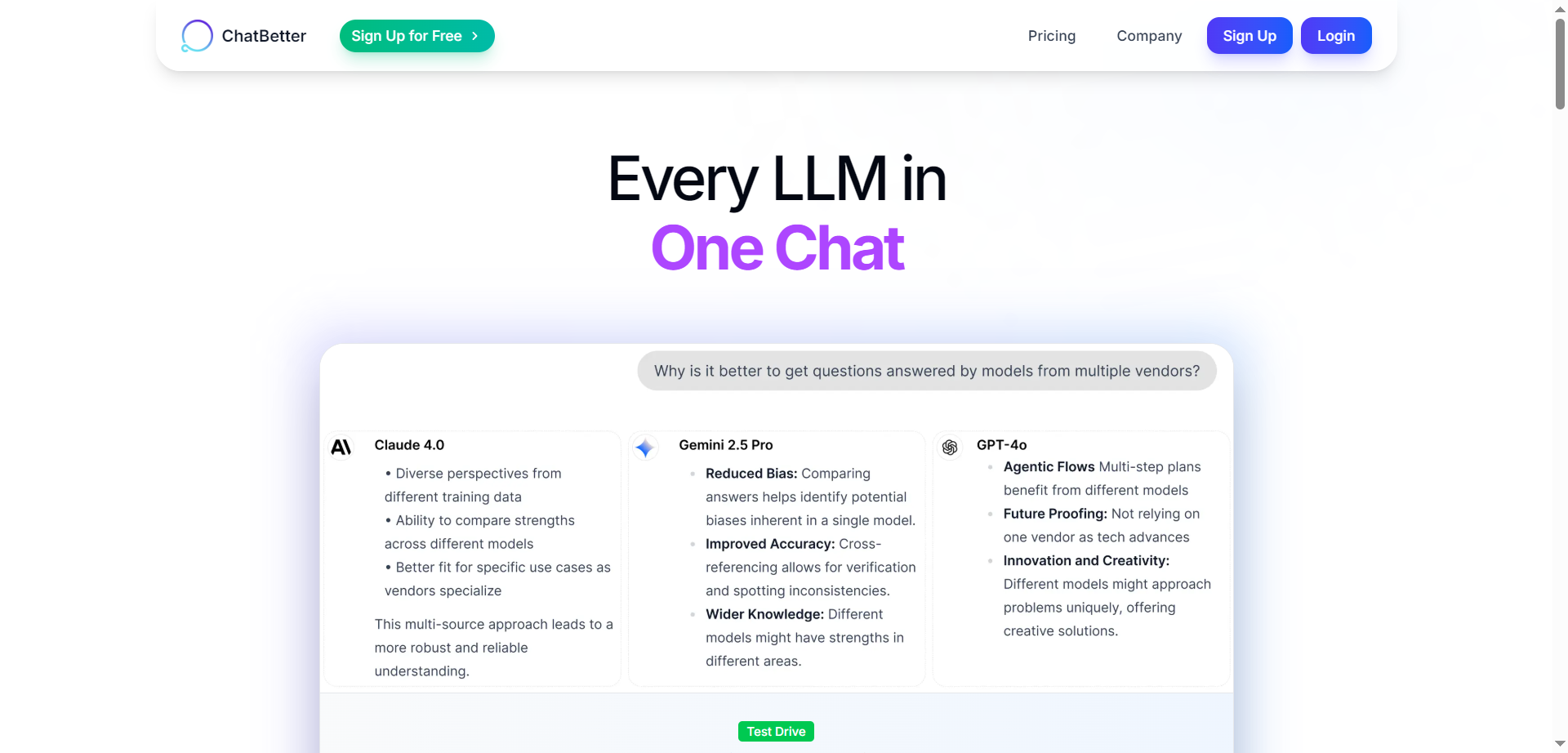

ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
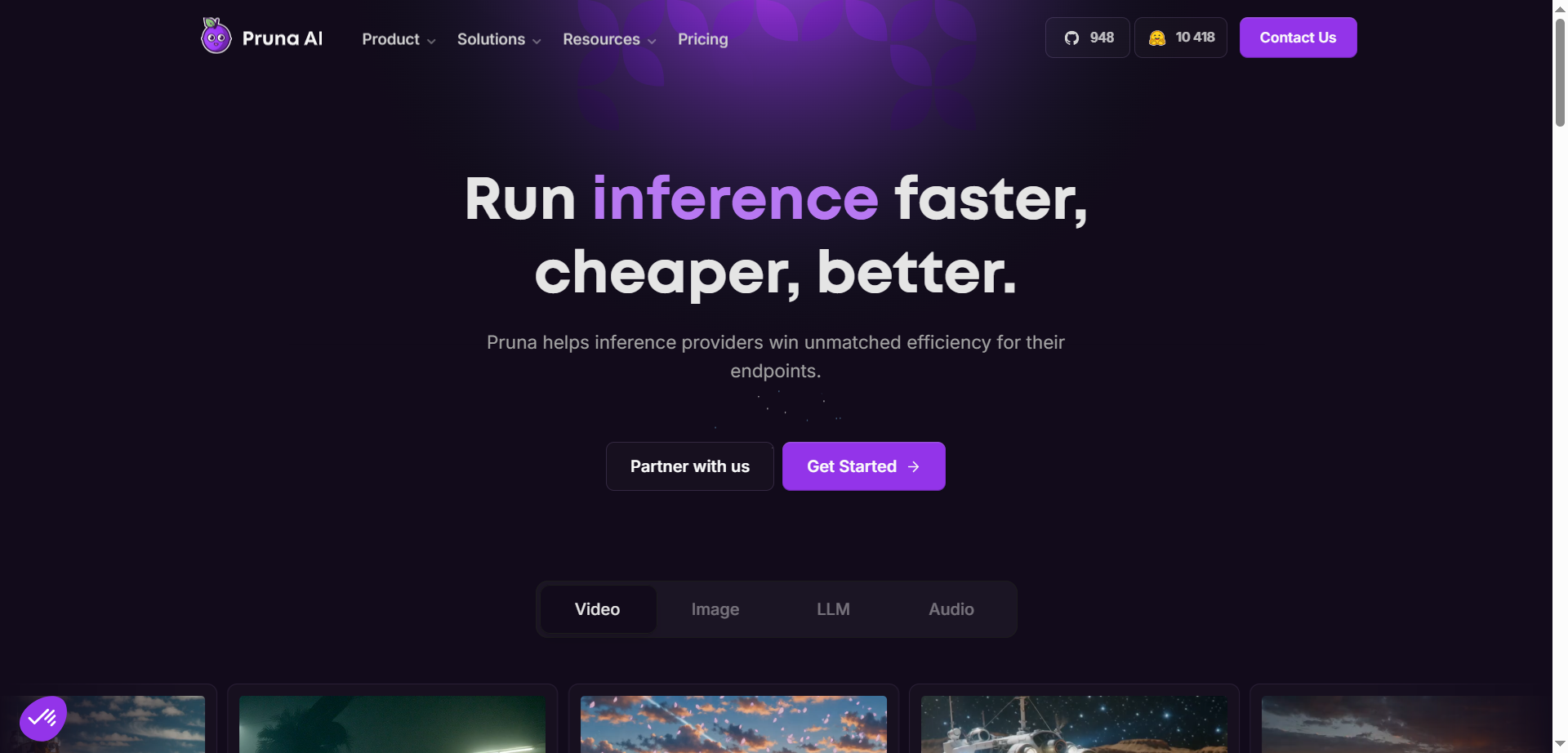

Pruna AI
Pruna.ai is an AI optimization engine designed to make machine learning models faster, smaller, cheaper, and greener with minimal overhead. It leverages advanced compression algorithms like pruning, quantization, distillation, caching, and compilation to reduce model size and accelerate inference times. The platform supports various AI models including large language models, vision transformers, and speech recognition models, making it ideal for real-time applications such as autonomous systems and recommendation engines. Pruna.ai aims to lower computational costs, decrease energy consumption, and improve deployment scalability across cloud and on-premise environments while ensuring minimal loss of model quality.
Pruna AI
Pruna.ai is an AI optimization engine designed to make machine learning models faster, smaller, cheaper, and greener with minimal overhead. It leverages advanced compression algorithms like pruning, quantization, distillation, caching, and compilation to reduce model size and accelerate inference times. The platform supports various AI models including large language models, vision transformers, and speech recognition models, making it ideal for real-time applications such as autonomous systems and recommendation engines. Pruna.ai aims to lower computational costs, decrease energy consumption, and improve deployment scalability across cloud and on-premise environments while ensuring minimal loss of model quality.
Pruna AI
Pruna.ai is an AI optimization engine designed to make machine learning models faster, smaller, cheaper, and greener with minimal overhead. It leverages advanced compression algorithms like pruning, quantization, distillation, caching, and compilation to reduce model size and accelerate inference times. The platform supports various AI models including large language models, vision transformers, and speech recognition models, making it ideal for real-time applications such as autonomous systems and recommendation engines. Pruna.ai aims to lower computational costs, decrease energy consumption, and improve deployment scalability across cloud and on-premise environments while ensuring minimal loss of model quality.
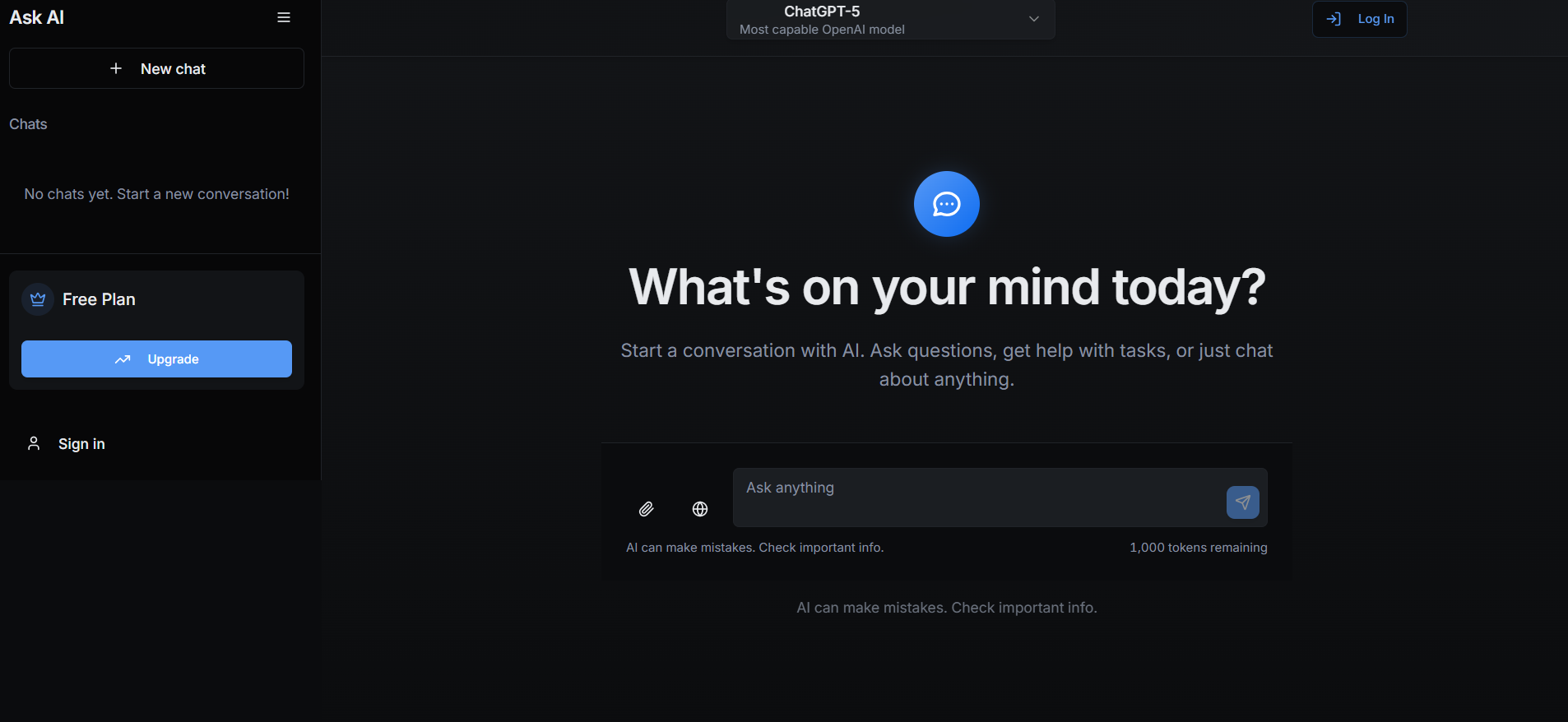
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
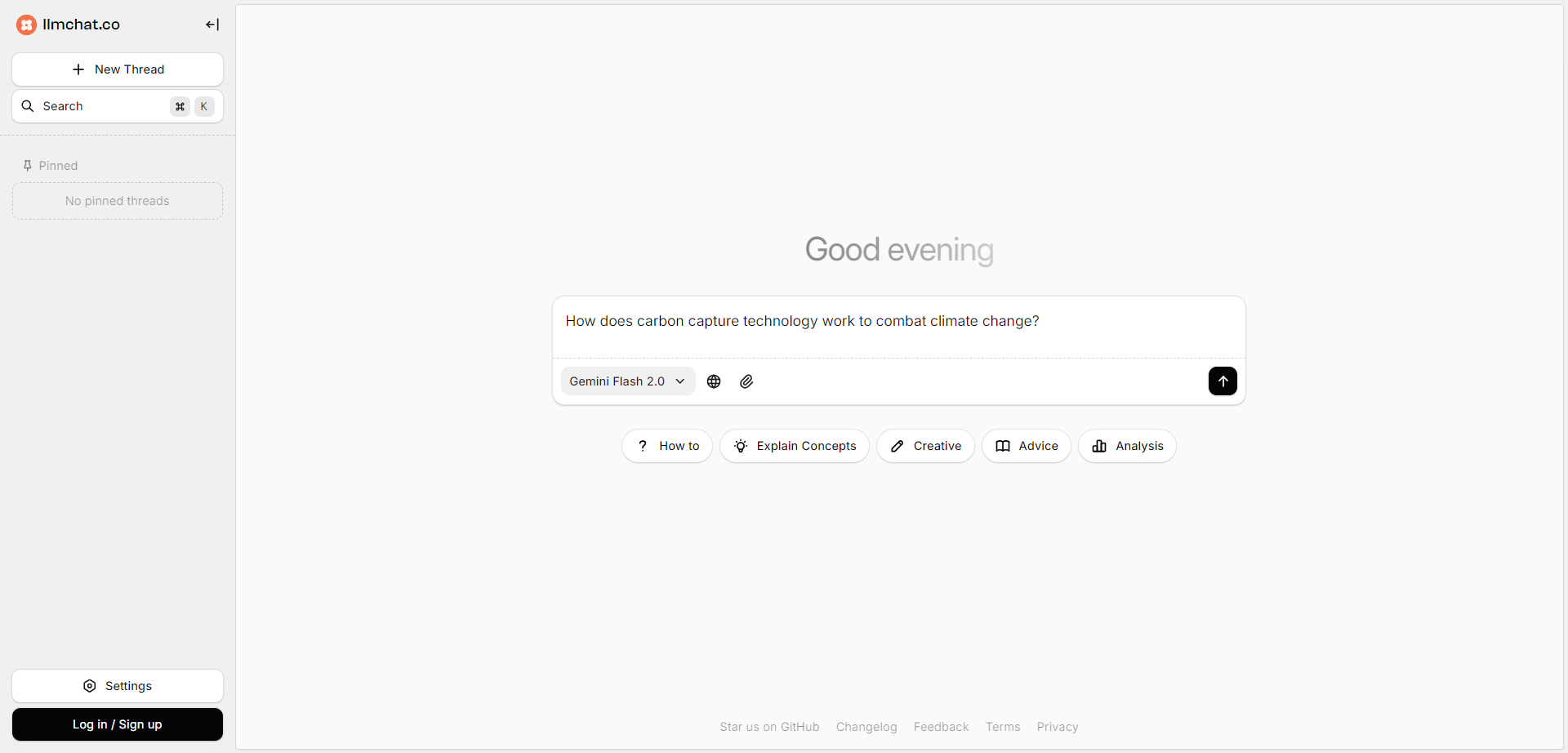

LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai