
- Terminal-Centric Developers: Ideal for those who prefer working within the command line and seek an AI assistant to streamline coding tasks.
- Startup Teams & Indie Hackers: Perfect for small teams needing rapid prototyping and code iteration without the overhead of larger models.
- Educators & Students: A valuable tool for learning and teaching programming concepts through interactive examples.
- API Integrators: Suitable for developers looking to integrate AI-powered coding assistance into their applications via API.
- Budget-Conscious Users: Offers a cost-effective solution for AI-driven code generation and editing tasks.
🛠️ How to Use codex-mini-latest?
Via Codex CLI:
- Install Codex CLI --> bash --> Copy --> npm install -g @openai/codex
- Set Your API Key: bash --> Copy --> export OPENAIAPIKEY="your-api-key-here"
- Run Codex: bash --> Copy --> codex
Interactively enter prompts, and codex-mini-latest will process them to generate or modify code accordingly.
Via API:
- Endpoint: Use the OpenAI API with the model name codex-mini-latest.
- Integration: Incorporate into your applications to enable AI-driven code assistance features
- Optimized for Terminal Use: Tailored for command-line interactions, providing seamless integration into terminal workflows.
- High Performance: Delivers fast response times, making it suitable for real-time coding assistance.
- Cost-Effective: Priced at $1.50 per million input tokens and $6.00 per million output tokens, with a 75% caching discount for repeated prompts.
- Large Context Window: Supports up to 200,000 tokens, allowing it to handle extensive codebases effectively.
- Multilingual Support: Capable of understanding and generating code in multiple programming languages.
- Fast and Responsive: Provides quick feedback, enhancing productivity during development.
- Affordable Pricing: Offers a budget-friendly option for AI-powered coding assistance.
- Intelligent Code Generation: Produces human-like, readable, and maintainable code.
- Easy Integration: Simple setup via CLI or API, facilitating quick adoption.
- Secure Execution: Operates within a sandboxed environment, ensuring safe code execution.
- No Image Input: Currently lacks support for processing visual inputs, limiting its use in frontend development tasks.
- No Mid-Task Interaction: Does not allow for real-time adjustments during task execution.
- Limited Internet Access: Operates offline, which may restrict access to external resources during code generation.
- Research Preview: As an experimental model, it may have limitations and is not recommended for production use without thorough testing.
- Learning Curve: Users unfamiliar with CLI tools may require time to adapt to the command-line interface.
API Only
$1.50/$6 for 1M tokens
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI o1-pro
o1-pro is a highly capable AI model developed by OpenAI, designed to deliver efficient, high-quality text generation across a wide range of use cases. As part of OpenAI’s GPT-4 architecture family, o1-pro is optimized for low-latency performance and high accuracy—making it suitable for both everyday tasks and enterprise-scale applications. It powers natural language interactions, content creation, summarization, and more, offering developers a solid balance between performance, cost, and output quality.
OpenAI o1-pro
o1-pro is a highly capable AI model developed by OpenAI, designed to deliver efficient, high-quality text generation across a wide range of use cases. As part of OpenAI’s GPT-4 architecture family, o1-pro is optimized for low-latency performance and high accuracy—making it suitable for both everyday tasks and enterprise-scale applications. It powers natural language interactions, content creation, summarization, and more, offering developers a solid balance between performance, cost, and output quality.
OpenAI o1-pro
o1-pro is a highly capable AI model developed by OpenAI, designed to deliver efficient, high-quality text generation across a wide range of use cases. As part of OpenAI’s GPT-4 architecture family, o1-pro is optimized for low-latency performance and high accuracy—making it suitable for both everyday tasks and enterprise-scale applications. It powers natural language interactions, content creation, summarization, and more, offering developers a solid balance between performance, cost, and output quality.

GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.

GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.

GPT-4o Mini Realtime Preview is a lightweight, high-speed variant of OpenAI’s flagship multimodal model, GPT-4o. Built for blazing-fast, cost-efficient inference across text, vision, and voice inputs, this preview version is optimized for real-time responsiveness—without compromising on core intelligence. Whether you’re building chatbots, interactive voice tools, or lightweight apps, GPT-4o Mini delivers smart performance with minimal latency and compute load. It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.
GPT-4o Mini Realtime Preview is a lightweight, high-speed variant of OpenAI’s flagship multimodal model, GPT-4o. Built for blazing-fast, cost-efficient inference across text, vision, and voice inputs, this preview version is optimized for real-time responsiveness—without compromising on core intelligence. Whether you’re building chatbots, interactive voice tools, or lightweight apps, GPT-4o Mini delivers smart performance with minimal latency and compute load. It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.
GPT-4o Mini Realtime Preview is a lightweight, high-speed variant of OpenAI’s flagship multimodal model, GPT-4o. Built for blazing-fast, cost-efficient inference across text, vision, and voice inputs, this preview version is optimized for real-time responsiveness—without compromising on core intelligence. Whether you’re building chatbots, interactive voice tools, or lightweight apps, GPT-4o Mini delivers smart performance with minimal latency and compute load. It’s the perfect choice when you need responsiveness, affordability, and multimodal capabilities all in one efficient package.

GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.

GPT-4o-mini Search Preview is OpenAI’s lightweight semantic search feature powered by the GPT-4o-mini model. Designed for real-time applications and low-latency environments, it brings retrieval-augmented intelligence to any product or tool that needs blazing-fast, accurate information lookup. While compact in size, it offers the power of contextual understanding, enabling smarter, more relevant search results with fewer resources. It’s ideal for startups, embedded systems, or anyone who needs search that just works—fast, efficient, and tuned for integration.
GPT-4o-mini Search Preview is OpenAI’s lightweight semantic search feature powered by the GPT-4o-mini model. Designed for real-time applications and low-latency environments, it brings retrieval-augmented intelligence to any product or tool that needs blazing-fast, accurate information lookup. While compact in size, it offers the power of contextual understanding, enabling smarter, more relevant search results with fewer resources. It’s ideal for startups, embedded systems, or anyone who needs search that just works—fast, efficient, and tuned for integration.
GPT-4o-mini Search Preview is OpenAI’s lightweight semantic search feature powered by the GPT-4o-mini model. Designed for real-time applications and low-latency environments, it brings retrieval-augmented intelligence to any product or tool that needs blazing-fast, accurate information lookup. While compact in size, it offers the power of contextual understanding, enabling smarter, more relevant search results with fewer resources. It’s ideal for startups, embedded systems, or anyone who needs search that just works—fast, efficient, and tuned for integration.

omni-moderation-latest is OpenAI’s most advanced content moderation model, designed to detect and flag harmful, unsafe, or policy-violating content across a wide range of modalities and languages. Built on the GPT-4o architecture, it leverages multimodal understanding and multilingual capabilities to provide robust moderation for text, images, and audio inputs. This model is particularly effective in identifying nuanced and culturally specific toxic content, including implicit insults, sarcasm, and aggression that general-purpose systems might overlook.
omni-moderation-latest is OpenAI’s most advanced content moderation model, designed to detect and flag harmful, unsafe, or policy-violating content across a wide range of modalities and languages. Built on the GPT-4o architecture, it leverages multimodal understanding and multilingual capabilities to provide robust moderation for text, images, and audio inputs. This model is particularly effective in identifying nuanced and culturally specific toxic content, including implicit insults, sarcasm, and aggression that general-purpose systems might overlook.
omni-moderation-latest is OpenAI’s most advanced content moderation model, designed to detect and flag harmful, unsafe, or policy-violating content across a wide range of modalities and languages. Built on the GPT-4o architecture, it leverages multimodal understanding and multilingual capabilities to provide robust moderation for text, images, and audio inputs. This model is particularly effective in identifying nuanced and culturally specific toxic content, including implicit insults, sarcasm, and aggression that general-purpose systems might overlook.
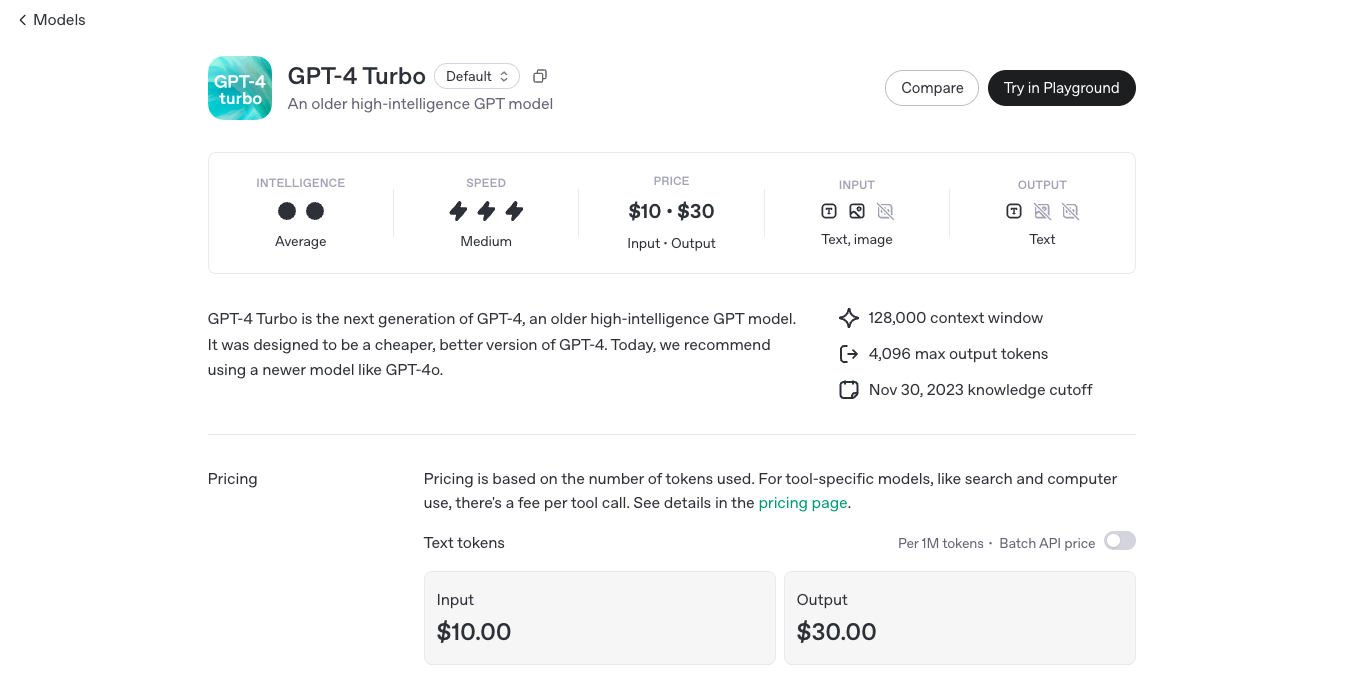
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
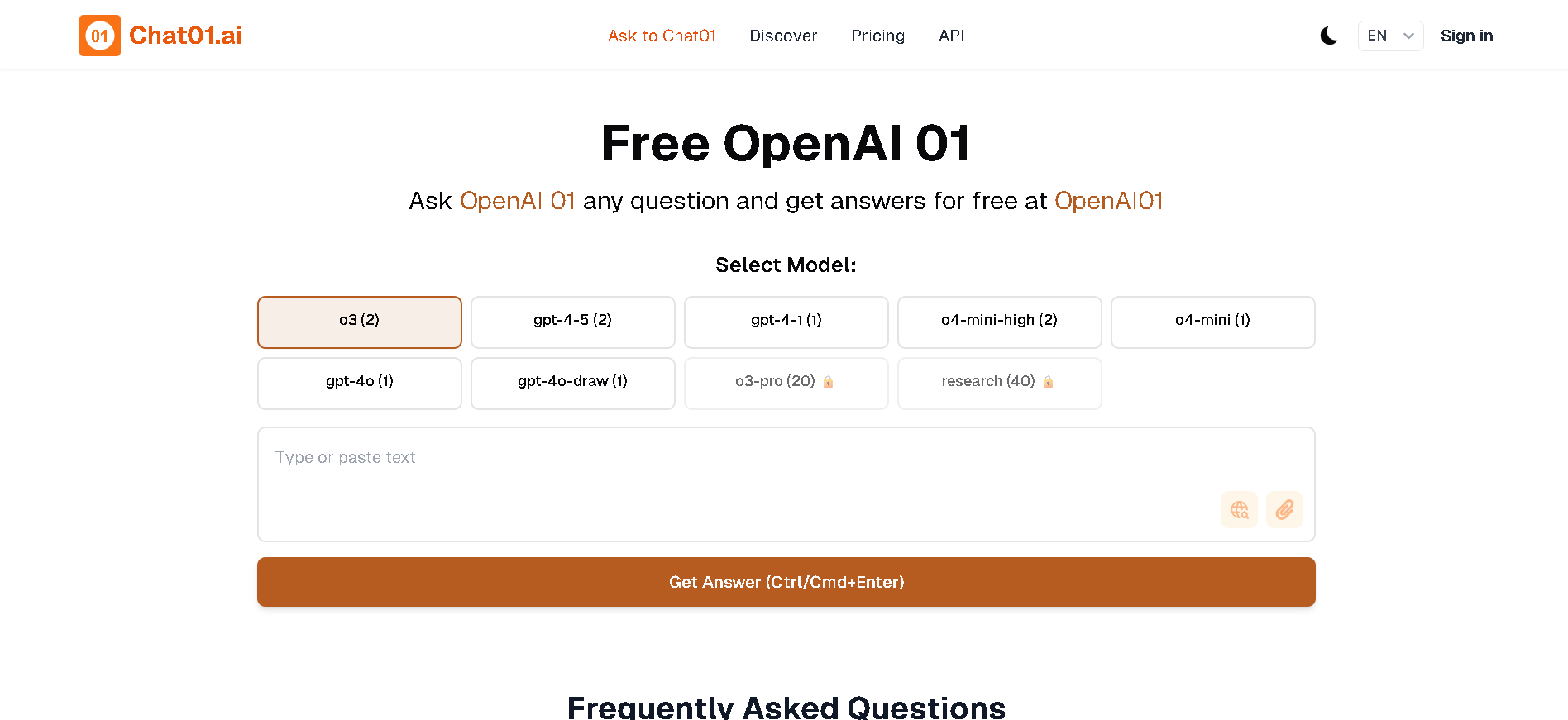
Chat 01 AI
Chat01.ai is a platform that offers free and unlimited chat with OpenAI 01, a new series of AI models. These models are specifically designed for complex reasoning and problem-solving in areas such as science, coding, and math, by employing a "think more before responding" approach, trying different strategies, and recognizing mistakes.
Chat 01 AI
Chat01.ai is a platform that offers free and unlimited chat with OpenAI 01, a new series of AI models. These models are specifically designed for complex reasoning and problem-solving in areas such as science, coding, and math, by employing a "think more before responding" approach, trying different strategies, and recognizing mistakes.
Chat 01 AI
Chat01.ai is a platform that offers free and unlimited chat with OpenAI 01, a new series of AI models. These models are specifically designed for complex reasoning and problem-solving in areas such as science, coding, and math, by employing a "think more before responding" approach, trying different strategies, and recognizing mistakes.
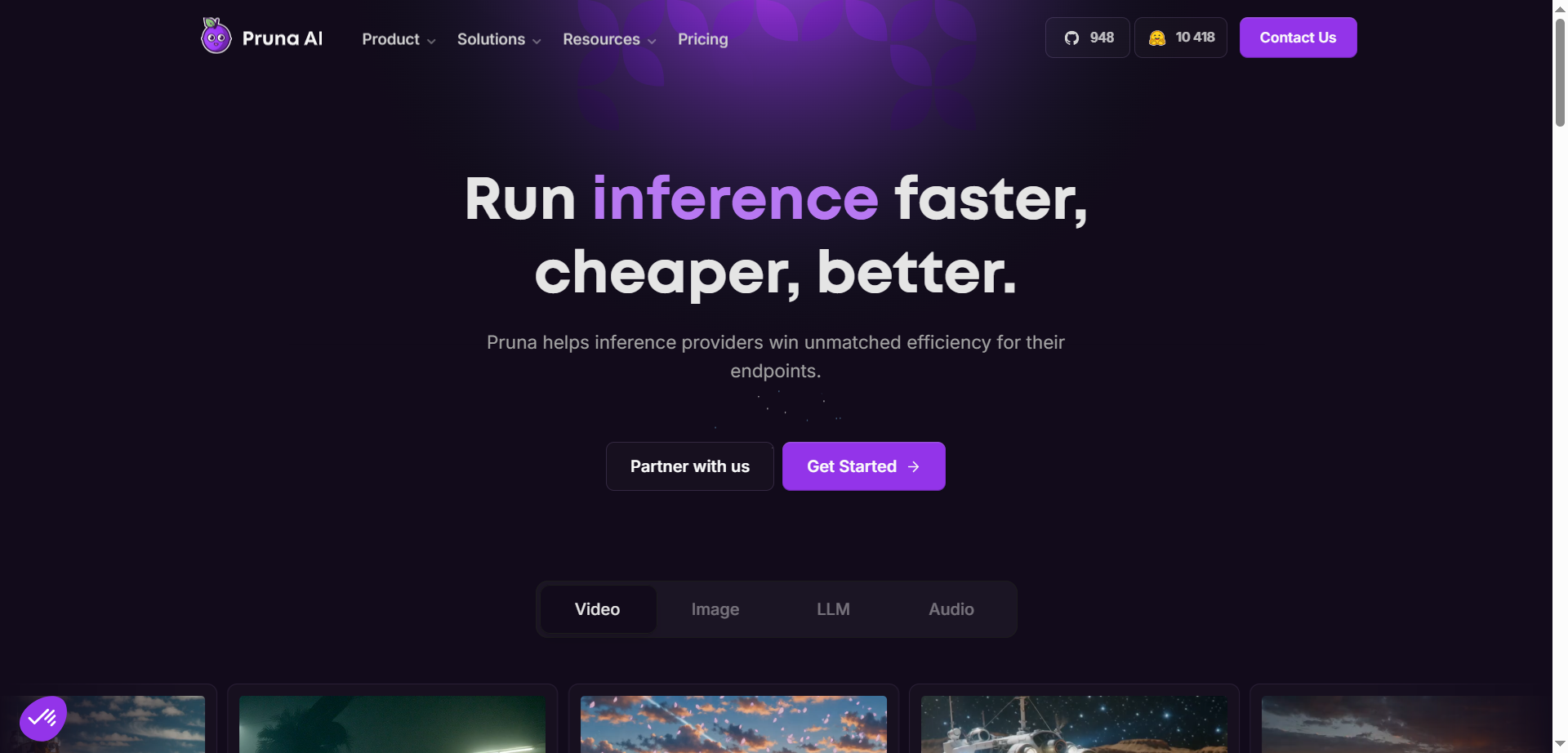

Pruna AI
Pruna.ai is an AI optimization engine designed to make machine learning models faster, smaller, cheaper, and greener with minimal overhead. It leverages advanced compression algorithms like pruning, quantization, distillation, caching, and compilation to reduce model size and accelerate inference times. The platform supports various AI models including large language models, vision transformers, and speech recognition models, making it ideal for real-time applications such as autonomous systems and recommendation engines. Pruna.ai aims to lower computational costs, decrease energy consumption, and improve deployment scalability across cloud and on-premise environments while ensuring minimal loss of model quality.
Pruna AI
Pruna.ai is an AI optimization engine designed to make machine learning models faster, smaller, cheaper, and greener with minimal overhead. It leverages advanced compression algorithms like pruning, quantization, distillation, caching, and compilation to reduce model size and accelerate inference times. The platform supports various AI models including large language models, vision transformers, and speech recognition models, making it ideal for real-time applications such as autonomous systems and recommendation engines. Pruna.ai aims to lower computational costs, decrease energy consumption, and improve deployment scalability across cloud and on-premise environments while ensuring minimal loss of model quality.
Pruna AI
Pruna.ai is an AI optimization engine designed to make machine learning models faster, smaller, cheaper, and greener with minimal overhead. It leverages advanced compression algorithms like pruning, quantization, distillation, caching, and compilation to reduce model size and accelerate inference times. The platform supports various AI models including large language models, vision transformers, and speech recognition models, making it ideal for real-time applications such as autonomous systems and recommendation engines. Pruna.ai aims to lower computational costs, decrease energy consumption, and improve deployment scalability across cloud and on-premise environments while ensuring minimal loss of model quality.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai