✅ AI Assistant Users – People who want an efficient, natural-sounding AI voice assistant for daily tasks.
✅ Developers & Businesses – Companies looking to integrate AI voice features into their apps at a lower cost.
✅ Customer Support Services – Businesses that need fast, real-time AI-powered customer interactions.
✅ Language Learners & Travelers – AI-powered real-time speech translation.
✅ Visually Impaired Users – Those who rely on AI voice for accessibility tools.
How to Use OpenAI GPT-4o Mini Audio?
1️⃣ Access via ChatGPT Voice: Users can enable voice mode in the ChatGPT app to experience GPT-4o Mini Audio. Provides a quick and responsive AI voice interaction.
2️⃣ API Integration (Upcoming): OpenAI is expected to release an API for developers to integrate GPT-4o Mini Audio into applications. Ideal for AI-powered customer support, interactive voice bots, and more.
3️⃣ Real-Time Speech Translation: Like GPT-4o Audio, Mini Audio may support language translation features. Great for travel, cross-language communication, and learning new languages.
4️⃣ AI-Powered Voice Interactions: Can be used for AI companions, interactive storytelling, and productivity tools. Works well for low-latency applications that require fast responses.
💰 Cost-Effective AI Voice – A more affordable alternative to full GPT-4o Audio for businesses and developers.
🎭 Expressive & Realistic AI Speech – Maintains natural-sounding speech with emotion.
🔗 Future API Integration – Developers will be able to embed Mini Audio into applications.
- Quick & Real-Time Responses – Great for fast AI interactions.
- More Affordable Than GPT-4o Audio – Suitable for budget-conscious businesses.
- Natural-Sounding Voice – Expressive and human-like AI speech.
- Potential for Language Translation – Ideal for global communication.
- Limited Availability – Currently only accessible in ChatGPT voice mode; API release is pending.
- Less Advanced Than GPT-4o Audio – While efficient, it may not match GPT-4o’s expressiveness and nuance.
- Potential Feature Limitations – May lack some of the advanced customization options available in full GPT-4o Audio.
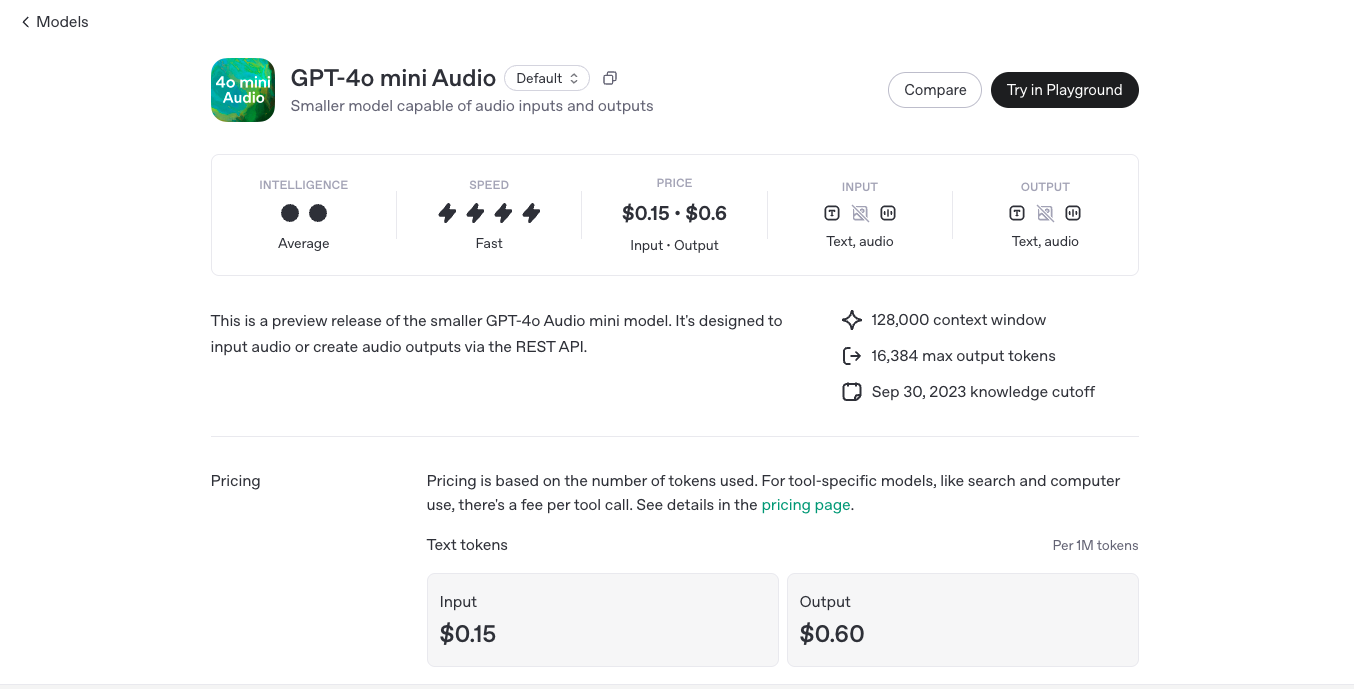
Text Tokens
$0.15/$0.60
Output: $0.60 per 1 million tokens
Audio Tokens
$10.00/$20.00
Output: $20.00 per 1 million tokens
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
OpenAI ChatGPT
ChatGPT is an advanced AI chatbot developed by OpenAI that can generate human-like text, answer questions, assist with creative writing, and engage in natural conversations. Powered by OpenAI’s GPT models, it is widely used for customer support, content creation, tutoring, and even casual chat. ChatGPT is available as a web app, API, and mobile app, making it accessible for personal and business use.
OpenAI ChatGPT
ChatGPT is an advanced AI chatbot developed by OpenAI that can generate human-like text, answer questions, assist with creative writing, and engage in natural conversations. Powered by OpenAI’s GPT models, it is widely used for customer support, content creation, tutoring, and even casual chat. ChatGPT is available as a web app, API, and mobile app, making it accessible for personal and business use.
OpenAI ChatGPT
ChatGPT is an advanced AI chatbot developed by OpenAI that can generate human-like text, answer questions, assist with creative writing, and engage in natural conversations. Powered by OpenAI’s GPT models, it is widely used for customer support, content creation, tutoring, and even casual chat. ChatGPT is available as a web app, API, and mobile app, making it accessible for personal and business use.

OpenAI Whisper
OpenAI Whisper is a powerful automatic speech recognition (ASR) system designed to transcribe and translate spoken language with high accuracy. It supports multiple languages and can handle a variety of audio formats, making it an essential tool for transcription services, accessibility solutions, and real-time voice applications. Whisper is trained on a vast dataset of multilingual audio, ensuring robustness even in noisy environments.
OpenAI Whisper
OpenAI Whisper is a powerful automatic speech recognition (ASR) system designed to transcribe and translate spoken language with high accuracy. It supports multiple languages and can handle a variety of audio formats, making it an essential tool for transcription services, accessibility solutions, and real-time voice applications. Whisper is trained on a vast dataset of multilingual audio, ensuring robustness even in noisy environments.
OpenAI Whisper
OpenAI Whisper is a powerful automatic speech recognition (ASR) system designed to transcribe and translate spoken language with high accuracy. It supports multiple languages and can handle a variety of audio formats, making it an essential tool for transcription services, accessibility solutions, and real-time voice applications. Whisper is trained on a vast dataset of multilingual audio, ensuring robustness even in noisy environments.

OpenAI TTS1-HD
TTS-1-HD is OpenAI’s high-definition, low-latency streaming voice model designed to bring human-like speech to real-time applications. Building on the capabilities of the original TTS-1 model, TTS-1-HD enables developers to generate speech as the words are being produced—perfect for voice assistants, interactive bots, or live narration tools. It delivers smoother, faster, and more conversational speech experiences, making it an ideal choice for developers building next-gen voice-driven products.
OpenAI TTS1-HD
TTS-1-HD is OpenAI’s high-definition, low-latency streaming voice model designed to bring human-like speech to real-time applications. Building on the capabilities of the original TTS-1 model, TTS-1-HD enables developers to generate speech as the words are being produced—perfect for voice assistants, interactive bots, or live narration tools. It delivers smoother, faster, and more conversational speech experiences, making it an ideal choice for developers building next-gen voice-driven products.
OpenAI TTS1-HD
TTS-1-HD is OpenAI’s high-definition, low-latency streaming voice model designed to bring human-like speech to real-time applications. Building on the capabilities of the original TTS-1 model, TTS-1-HD enables developers to generate speech as the words are being produced—perfect for voice assistants, interactive bots, or live narration tools. It delivers smoother, faster, and more conversational speech experiences, making it an ideal choice for developers building next-gen voice-driven products.

OpenAI GPT Image 1
GPT-Image-1 is OpenAI's state-of-the-art vision model designed to understand and interpret images with human-like perception. It enables developers and businesses to analyze, summarize, and extract detailed insights from images using natural language. Whether you're building AI agents, accessibility tools, or image-driven workflows, GPT-Image-1 brings powerful multimodal capabilities into your applications with impressive accuracy. Optimized for use via API, it can handle diverse image types—charts, screenshots, photographs, documents, and more—making it one of the most versatile models in OpenAI’s portfolio.
OpenAI GPT Image 1
GPT-Image-1 is OpenAI's state-of-the-art vision model designed to understand and interpret images with human-like perception. It enables developers and businesses to analyze, summarize, and extract detailed insights from images using natural language. Whether you're building AI agents, accessibility tools, or image-driven workflows, GPT-Image-1 brings powerful multimodal capabilities into your applications with impressive accuracy. Optimized for use via API, it can handle diverse image types—charts, screenshots, photographs, documents, and more—making it one of the most versatile models in OpenAI’s portfolio.
OpenAI GPT Image 1
GPT-Image-1 is OpenAI's state-of-the-art vision model designed to understand and interpret images with human-like perception. It enables developers and businesses to analyze, summarize, and extract detailed insights from images using natural language. Whether you're building AI agents, accessibility tools, or image-driven workflows, GPT-Image-1 brings powerful multimodal capabilities into your applications with impressive accuracy. Optimized for use via API, it can handle diverse image types—charts, screenshots, photographs, documents, and more—making it one of the most versatile models in OpenAI’s portfolio.

GPT-4o Search Preview is a powerful experimental feature of OpenAI’s GPT-4o model, designed to act as a high-performance retrieval system. Rather than just generating answers from training data, it allows the model to search through large datasets, documents, or knowledge bases to surface relevant results with context-aware accuracy. Think of it as your AI assistant with built-in research superpowers—faster, smarter, and surprisingly precise. This preview gives developers a taste of what’s coming next: an intelligent search engine built directly into the GPT-4o ecosystem.
GPT-4o Search Preview is a powerful experimental feature of OpenAI’s GPT-4o model, designed to act as a high-performance retrieval system. Rather than just generating answers from training data, it allows the model to search through large datasets, documents, or knowledge bases to surface relevant results with context-aware accuracy. Think of it as your AI assistant with built-in research superpowers—faster, smarter, and surprisingly precise. This preview gives developers a taste of what’s coming next: an intelligent search engine built directly into the GPT-4o ecosystem.
GPT-4o Search Preview is a powerful experimental feature of OpenAI’s GPT-4o model, designed to act as a high-performance retrieval system. Rather than just generating answers from training data, it allows the model to search through large datasets, documents, or knowledge bases to surface relevant results with context-aware accuracy. Think of it as your AI assistant with built-in research superpowers—faster, smarter, and surprisingly precise. This preview gives developers a taste of what’s coming next: an intelligent search engine built directly into the GPT-4o ecosystem.
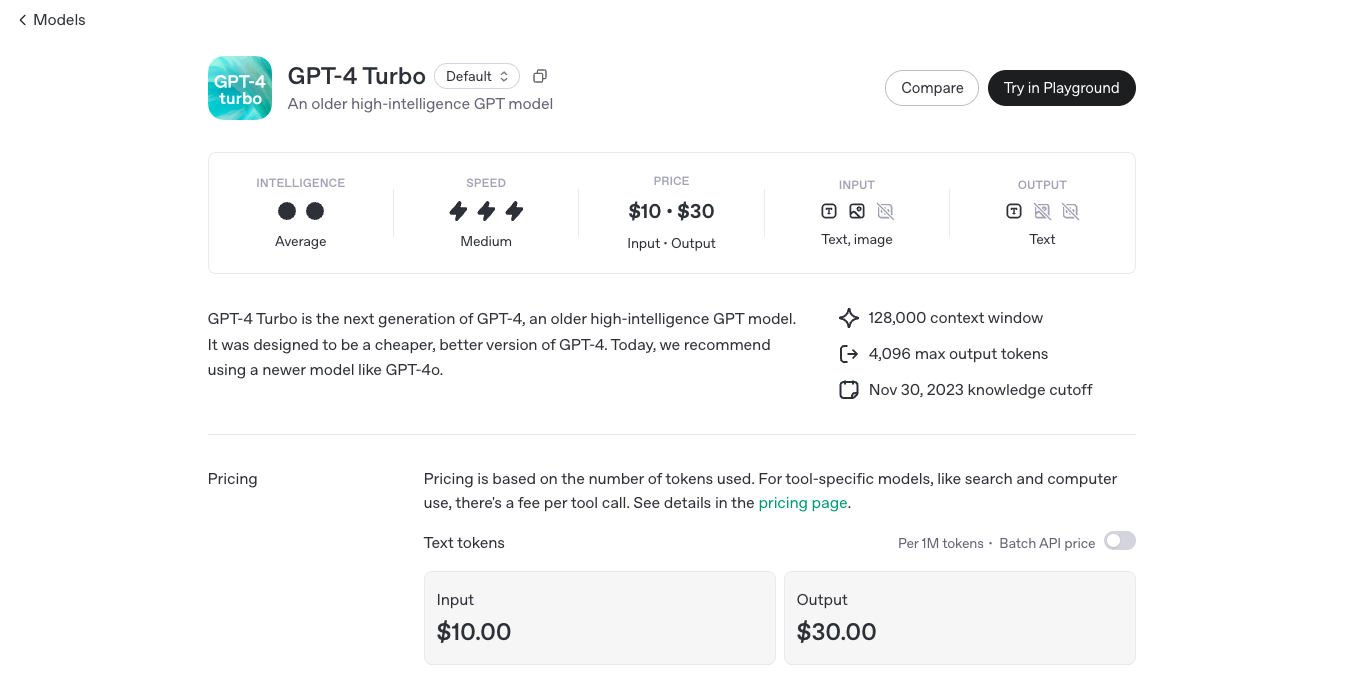
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.

XSAudio
XSAudio is a powerful AI audio platform offering text-to-speech, voice cloning, and sound effect generation. With realistic voice libraries, custom cloning, and multilingual support, it’s perfect for creators, developers, and businesses needing high-quality audio fast. Use it for videos, podcasts, games, and more—with daily free credits and API access.
XSAudio
XSAudio is a powerful AI audio platform offering text-to-speech, voice cloning, and sound effect generation. With realistic voice libraries, custom cloning, and multilingual support, it’s perfect for creators, developers, and businesses needing high-quality audio fast. Use it for videos, podcasts, games, and more—with daily free credits and API access.
XSAudio
XSAudio is a powerful AI audio platform offering text-to-speech, voice cloning, and sound effect generation. With realistic voice libraries, custom cloning, and multilingual support, it’s perfect for creators, developers, and businesses needing high-quality audio fast. Use it for videos, podcasts, games, and more—with daily free credits and API access.
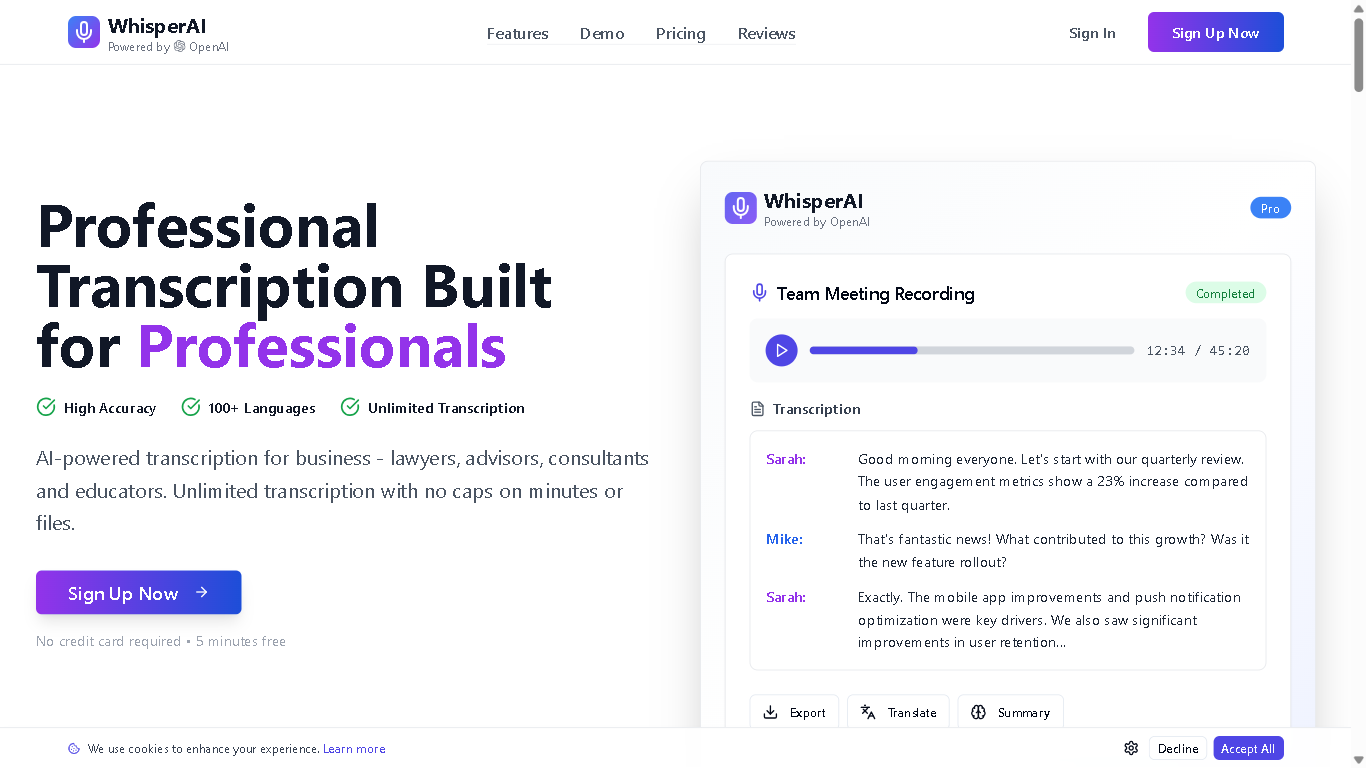
Whisprai.ai is an AI-powered transcription and summarization tool designed to help businesses and individuals quickly and accurately transcribe audio and video files, and generate concise summaries of their content. It offers features for improving workflow efficiency and enhancing productivity through AI-driven automation.
Whisprai.ai is an AI-powered transcription and summarization tool designed to help businesses and individuals quickly and accurately transcribe audio and video files, and generate concise summaries of their content. It offers features for improving workflow efficiency and enhancing productivity through AI-driven automation.
Whisprai.ai is an AI-powered transcription and summarization tool designed to help businesses and individuals quickly and accurately transcribe audio and video files, and generate concise summaries of their content. It offers features for improving workflow efficiency and enhancing productivity through AI-driven automation.
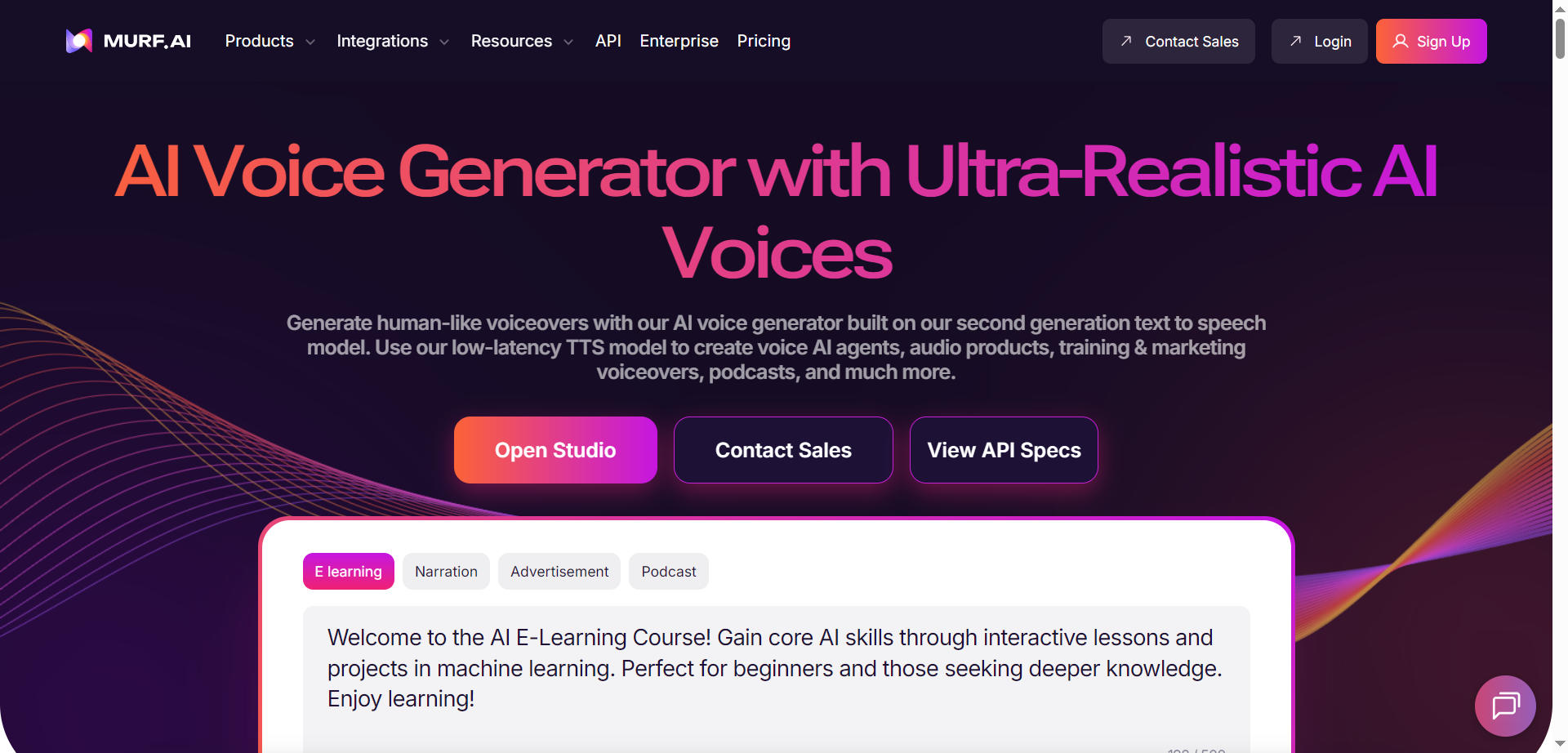

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
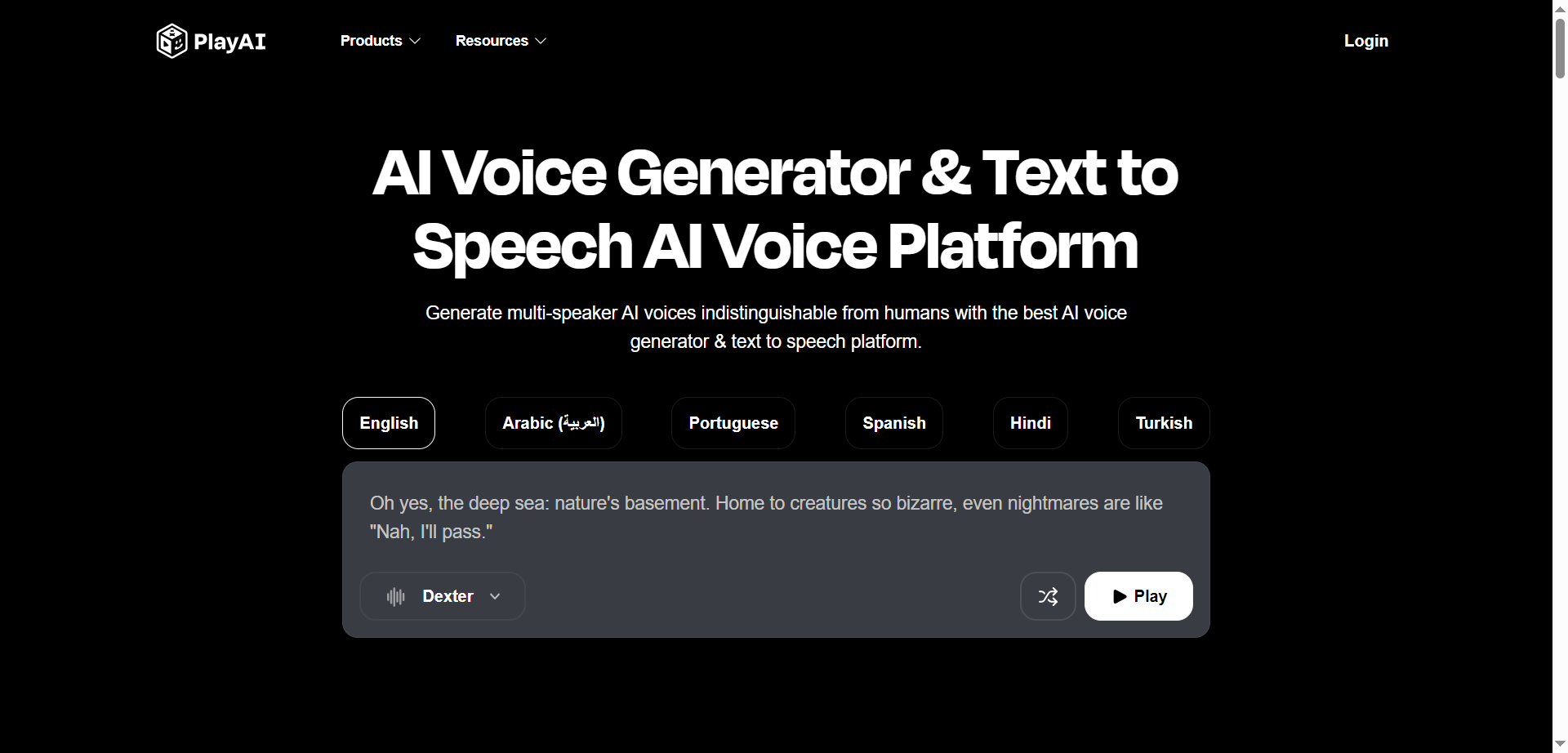
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
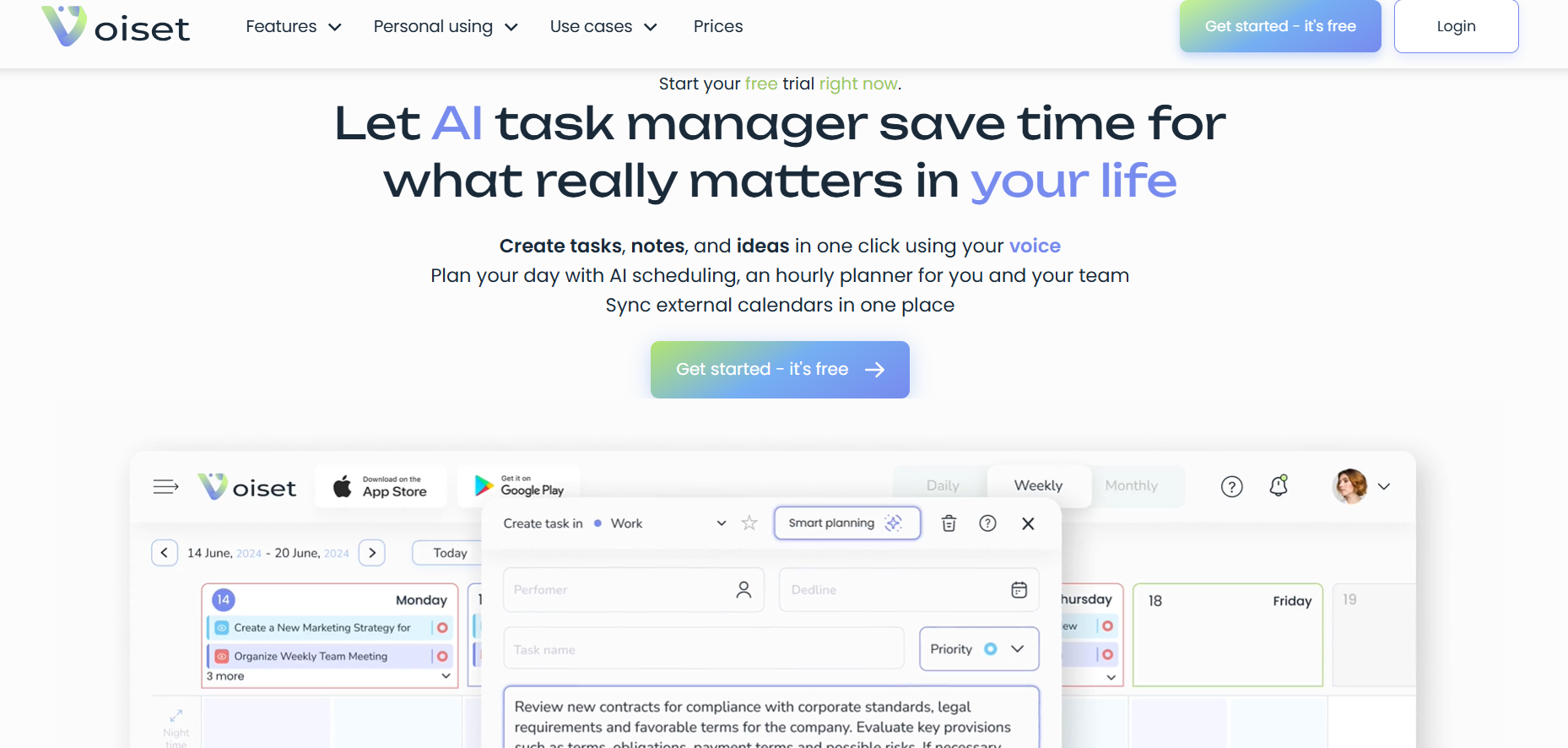
Voiset
Voiset is an AI-driven voice automation and conversational intelligence platform designed to enhance business communication, sales, and customer service. It allows teams to build intelligent voice agents that handle inbound and outbound calls, transcribe conversations, and provide real-time analytics. With advanced natural language processing, Voiset enables companies to automate communication tasks, reduce call handling time, and maintain personalized customer interactions. It integrates seamlessly with CRM tools and supports multiple languages, making it ideal for global teams and enterprises looking to scale voice operations.
Voiset
Voiset is an AI-driven voice automation and conversational intelligence platform designed to enhance business communication, sales, and customer service. It allows teams to build intelligent voice agents that handle inbound and outbound calls, transcribe conversations, and provide real-time analytics. With advanced natural language processing, Voiset enables companies to automate communication tasks, reduce call handling time, and maintain personalized customer interactions. It integrates seamlessly with CRM tools and supports multiple languages, making it ideal for global teams and enterprises looking to scale voice operations.
Voiset
Voiset is an AI-driven voice automation and conversational intelligence platform designed to enhance business communication, sales, and customer service. It allows teams to build intelligent voice agents that handle inbound and outbound calls, transcribe conversations, and provide real-time analytics. With advanced natural language processing, Voiset enables companies to automate communication tasks, reduce call handling time, and maintain personalized customer interactions. It integrates seamlessly with CRM tools and supports multiple languages, making it ideal for global teams and enterprises looking to scale voice operations.
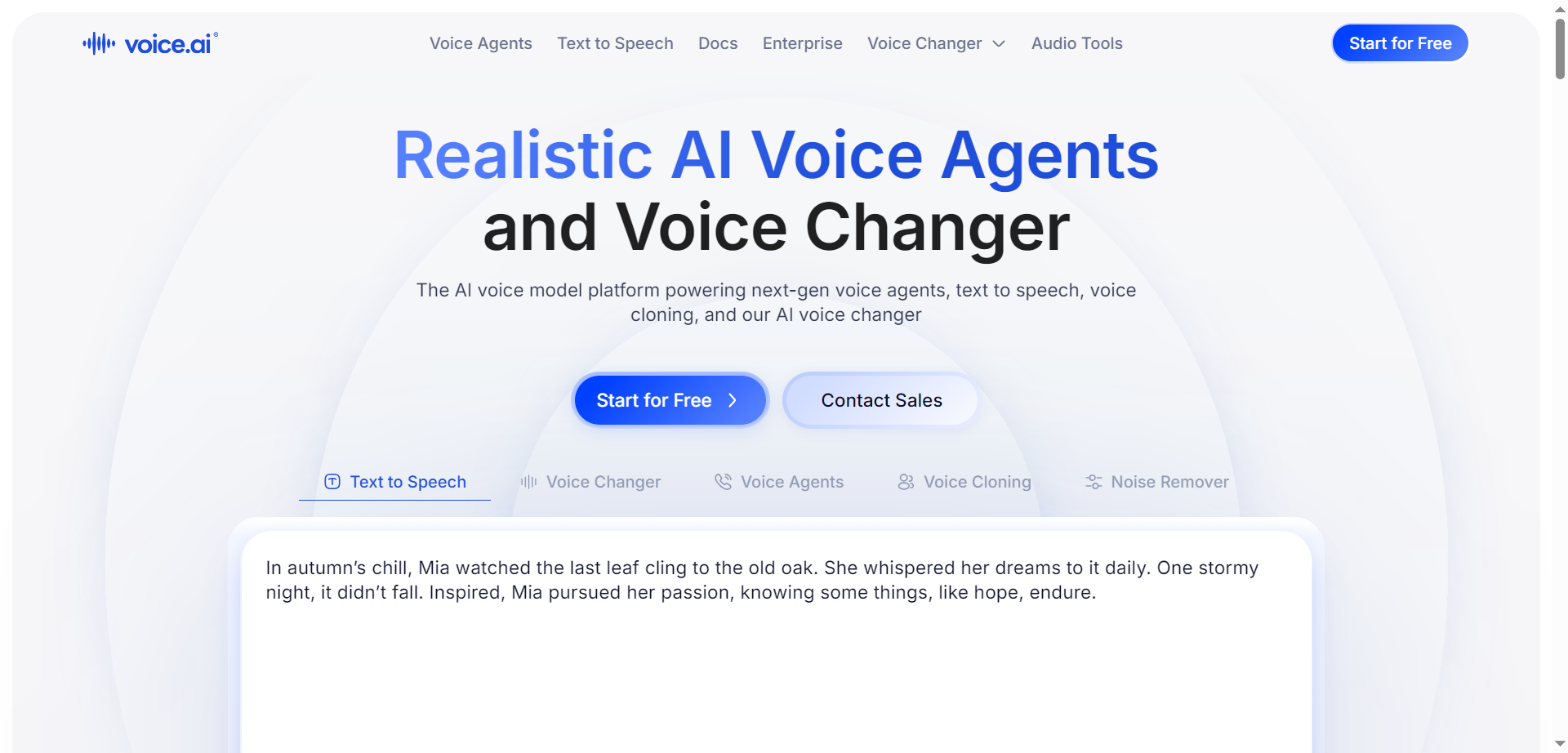

Voice.ai
Voice.ai is an AI voice platform that delivers realistic voice agents, studio-quality text-to-speech, rapid voice cloning, and a free real-time voice changer all in one system. Businesses can deploy human-like AI phone agents for 24/7 inbound and outbound calls, lead qualification, appointment booking, and customer conversations that integrate seamlessly with CRM tools like Salesforce and HubSpot. It generates lifelike TTS audio in 15+ languages with accent localization, clones voices from just 10 seconds of sample audio, and offers a free voice changer for gamers and streamers to switch voices live. With enterprise compliance including GDPR, SOC 2, and HIPAA plus cloud or on-premise deployment options.
Voice.ai
Voice.ai is an AI voice platform that delivers realistic voice agents, studio-quality text-to-speech, rapid voice cloning, and a free real-time voice changer all in one system. Businesses can deploy human-like AI phone agents for 24/7 inbound and outbound calls, lead qualification, appointment booking, and customer conversations that integrate seamlessly with CRM tools like Salesforce and HubSpot. It generates lifelike TTS audio in 15+ languages with accent localization, clones voices from just 10 seconds of sample audio, and offers a free voice changer for gamers and streamers to switch voices live. With enterprise compliance including GDPR, SOC 2, and HIPAA plus cloud or on-premise deployment options.
Voice.ai
Voice.ai is an AI voice platform that delivers realistic voice agents, studio-quality text-to-speech, rapid voice cloning, and a free real-time voice changer all in one system. Businesses can deploy human-like AI phone agents for 24/7 inbound and outbound calls, lead qualification, appointment booking, and customer conversations that integrate seamlessly with CRM tools like Salesforce and HubSpot. It generates lifelike TTS audio in 15+ languages with accent localization, clones voices from just 10 seconds of sample audio, and offers a free voice changer for gamers and streamers to switch voices live. With enterprise compliance including GDPR, SOC 2, and HIPAA plus cloud or on-premise deployment options.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai