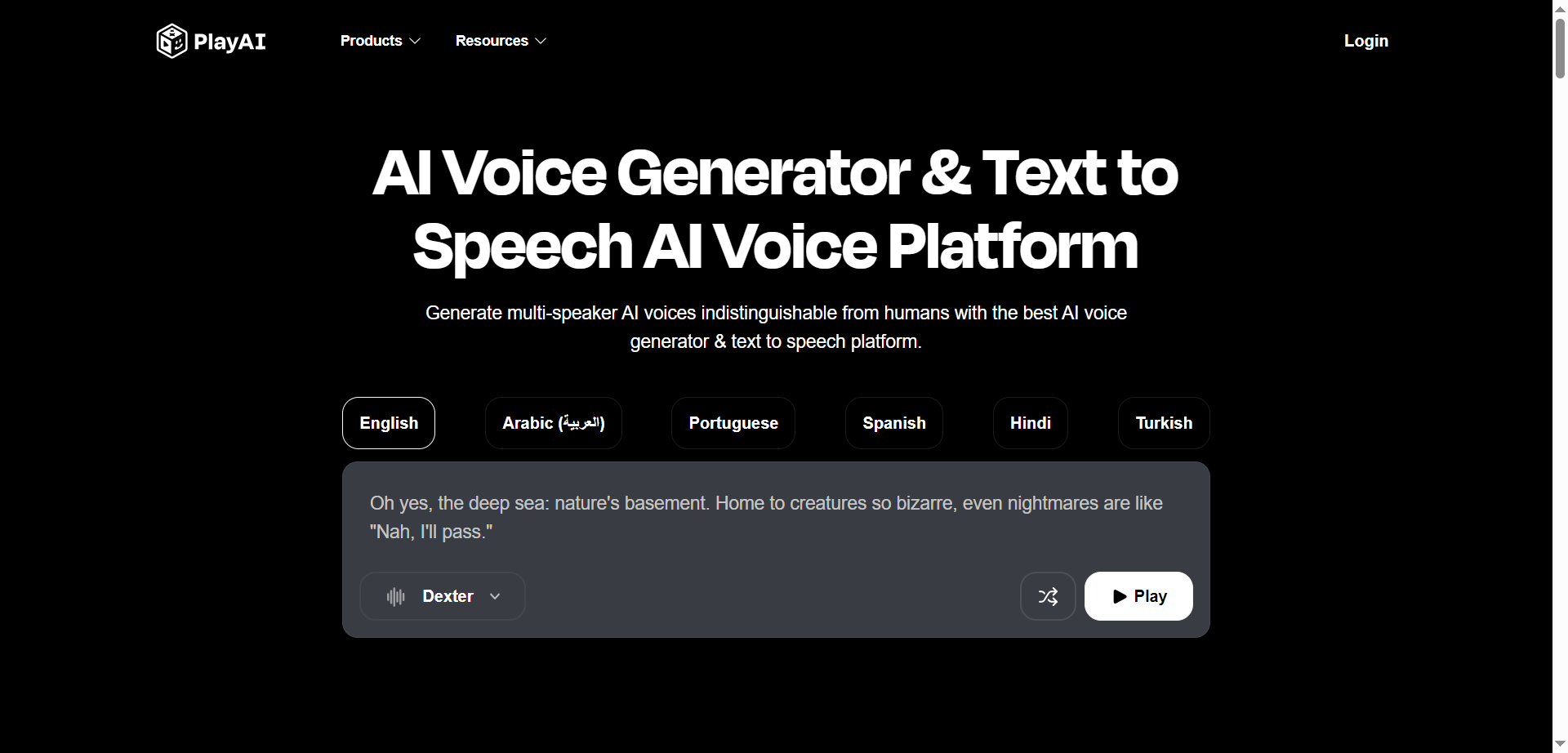
- Creators & Marketers: Produce consistent voiceovers for ads, product demos, and YouTube videos.
- Podcasters & Media: Generate multi-speaker, dialog-first episodes with expressive delivery.
- Educators & L&D: Narrate courses with accurate terminology and easy updates.
- Developers & Startups: Integrate real-time TTS, cloning, and multilingual dubbing via APIs.
- Game & UX Teams: Prototype characters and assistants with ultra-realistic voices.
How to Use Play.ht?
- Start a Project: Paste or import text, choose a voice, language, and style in the editor.
- Customize Speech: Adjust pitch, rate, emphasis, pauses, and set pronunciations for key terms.
- Create Dialog: Assign different voices to paragraphs for multi-speaker audio and preview.
- Export & Integrate: Download final audio, or use APIs for apps, assistants, and localization.
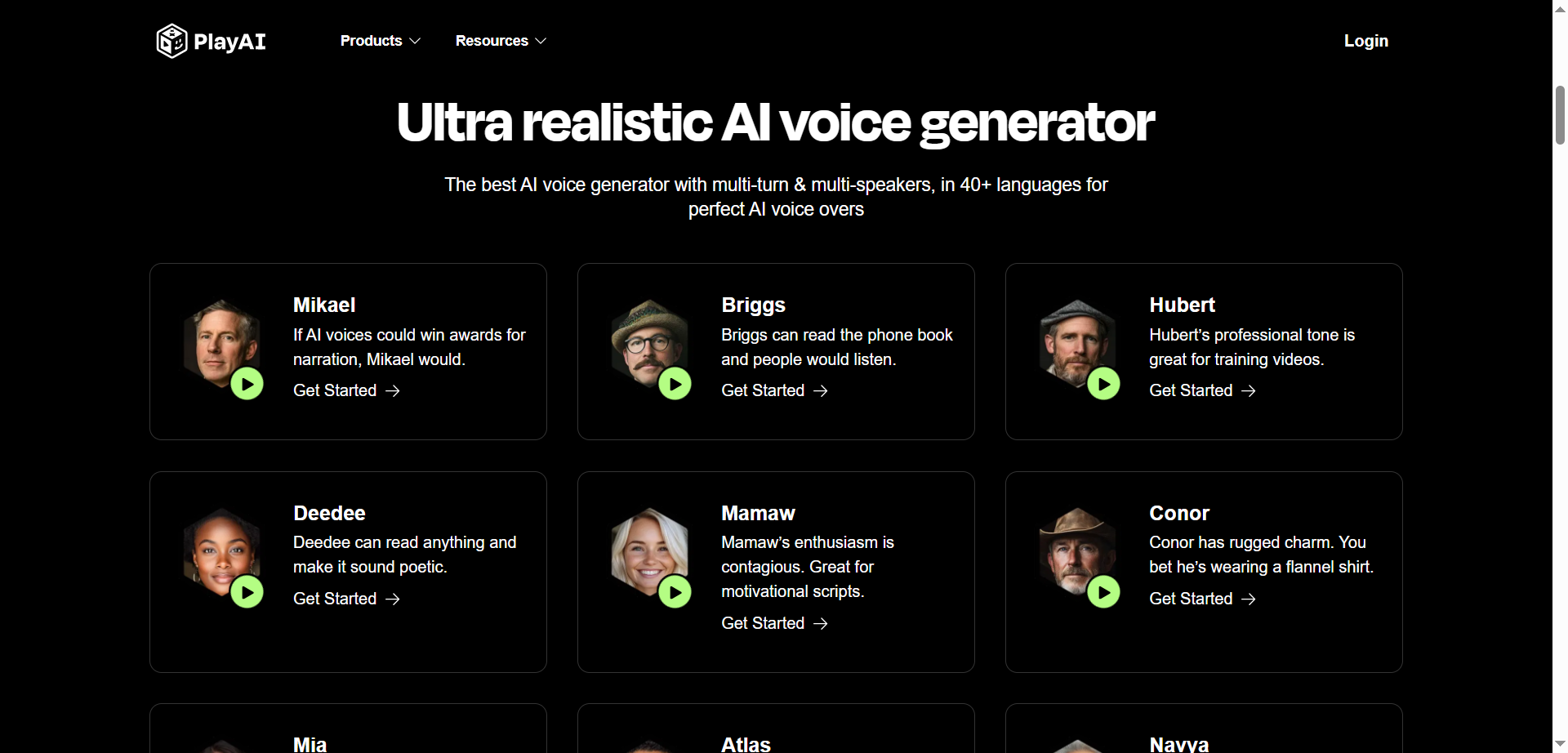
- Multi-Speaker Dialog: First dialog-enabled TTS for natural conversational podcasts.
- Large Voice Library: 200+ to 800+ voices cited by sources, with 30–40+ languages and accents.
- Pronunciation Control: Reusable dictionaries to standardize brand and technical terms.
- Voice Cloning: Create custom voices and preserve accent with cross-language dubbing.
- Low-Latency Streaming: Near-instant generation for live narration and assistants.
- Expressive voices with emotional styles and fine-grained SSML control.
- Dialog workflows that make multi-voice content fast to produce.
- Reusable pronunciations that keep terminology consistent.
- APIs for real-time TTS, cloning, and multilingual dubbing.
- Quality depends on careful styling and SSML tuning.
- Cloned voices require strong source ethics and consent.
- Some advanced features sit behind higher-tier plans.
- Editing is voice-first, not a full DAW for complex mixes.


Custom
Pricing information is not directly provided.
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI TTS1-HD
TTS-1-HD is OpenAI’s high-definition, low-latency streaming voice model designed to bring human-like speech to real-time applications. Building on the capabilities of the original TTS-1 model, TTS-1-HD enables developers to generate speech as the words are being produced—perfect for voice assistants, interactive bots, or live narration tools. It delivers smoother, faster, and more conversational speech experiences, making it an ideal choice for developers building next-gen voice-driven products.
OpenAI TTS1-HD
TTS-1-HD is OpenAI’s high-definition, low-latency streaming voice model designed to bring human-like speech to real-time applications. Building on the capabilities of the original TTS-1 model, TTS-1-HD enables developers to generate speech as the words are being produced—perfect for voice assistants, interactive bots, or live narration tools. It delivers smoother, faster, and more conversational speech experiences, making it an ideal choice for developers building next-gen voice-driven products.
OpenAI TTS1-HD
TTS-1-HD is OpenAI’s high-definition, low-latency streaming voice model designed to bring human-like speech to real-time applications. Building on the capabilities of the original TTS-1 model, TTS-1-HD enables developers to generate speech as the words are being produced—perfect for voice assistants, interactive bots, or live narration tools. It delivers smoother, faster, and more conversational speech experiences, making it an ideal choice for developers building next-gen voice-driven products.

Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
Vapi AI
Vapi.ai is an advanced developer-focused platform that enables the creation of AI-driven voice and conversational applications. It provides APIs and tools to build intelligent voice agents, handle real-time conversations, and integrate speech recognition, text-to-speech, and natural language processing into apps and services effortlessly.
Vapi AI
Vapi.ai is an advanced developer-focused platform that enables the creation of AI-driven voice and conversational applications. It provides APIs and tools to build intelligent voice agents, handle real-time conversations, and integrate speech recognition, text-to-speech, and natural language processing into apps and services effortlessly.
Vapi AI
Vapi.ai is an advanced developer-focused platform that enables the creation of AI-driven voice and conversational applications. It provides APIs and tools to build intelligent voice agents, handle real-time conversations, and integrate speech recognition, text-to-speech, and natural language processing into apps and services effortlessly.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Lovo
LOVO AI is a voiceover and video creation platform that combines an advanced text-to-speech engine with an online editor to produce natural, production-ready audio and visuals. With 500+ voices across 100+ languages, it enables rapid creation of voiceovers for marketing, e-learning, podcasts, social content, and more. Its Genny workspace adds scriptwriting, voice cloning, auto-subtitles, and AI image generation to streamline end-to-end production. Directable Pro V2 voices allow nuanced control of tone and delivery using natural language directions. Teams can collaborate in the cloud, export quickly, and even integrate via API to bring LOVO’s voices into apps and workflows. A free tier and trial options help projects start fast without setup friction.
Lovo
LOVO AI is a voiceover and video creation platform that combines an advanced text-to-speech engine with an online editor to produce natural, production-ready audio and visuals. With 500+ voices across 100+ languages, it enables rapid creation of voiceovers for marketing, e-learning, podcasts, social content, and more. Its Genny workspace adds scriptwriting, voice cloning, auto-subtitles, and AI image generation to streamline end-to-end production. Directable Pro V2 voices allow nuanced control of tone and delivery using natural language directions. Teams can collaborate in the cloud, export quickly, and even integrate via API to bring LOVO’s voices into apps and workflows. A free tier and trial options help projects start fast without setup friction.
Lovo
LOVO AI is a voiceover and video creation platform that combines an advanced text-to-speech engine with an online editor to produce natural, production-ready audio and visuals. With 500+ voices across 100+ languages, it enables rapid creation of voiceovers for marketing, e-learning, podcasts, social content, and more. Its Genny workspace adds scriptwriting, voice cloning, auto-subtitles, and AI image generation to streamline end-to-end production. Directable Pro V2 voices allow nuanced control of tone and delivery using natural language directions. Teams can collaborate in the cloud, export quickly, and even integrate via API to bring LOVO’s voices into apps and workflows. A free tier and trial options help projects start fast without setup friction.

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.

Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.


Narakeet
Narakeet is a text-to-speech and video automation platform that turns scripts, slides, and subtitle files into narrated videos and voiceovers at scale. It offers 100 languages and 800 realistic voices, letting teams update narration by simply editing text instead of re-recording audio. Users can convert PowerPoint, Google Slides, or Keynote into full HD videos with captions, or turn SRT/WebVTT subtitles into synchronized dubbing tracks. Markdown scripting and templates streamline creating social clips, tutorials, and product demos. With API and CLI support, Narakeet automates multi-language, multi-resolution outputs, accelerating production for training, marketing, and documentation content.
Narakeet
Narakeet is a text-to-speech and video automation platform that turns scripts, slides, and subtitle files into narrated videos and voiceovers at scale. It offers 100 languages and 800 realistic voices, letting teams update narration by simply editing text instead of re-recording audio. Users can convert PowerPoint, Google Slides, or Keynote into full HD videos with captions, or turn SRT/WebVTT subtitles into synchronized dubbing tracks. Markdown scripting and templates streamline creating social clips, tutorials, and product demos. With API and CLI support, Narakeet automates multi-language, multi-resolution outputs, accelerating production for training, marketing, and documentation content.
Narakeet
Narakeet is a text-to-speech and video automation platform that turns scripts, slides, and subtitle files into narrated videos and voiceovers at scale. It offers 100 languages and 800 realistic voices, letting teams update narration by simply editing text instead of re-recording audio. Users can convert PowerPoint, Google Slides, or Keynote into full HD videos with captions, or turn SRT/WebVTT subtitles into synchronized dubbing tracks. Markdown scripting and templates streamline creating social clips, tutorials, and product demos. With API and CLI support, Narakeet automates multi-language, multi-resolution outputs, accelerating production for training, marketing, and documentation content.
JuicyAI
Juicy AI is an innovative platform that provides a suite of AI assistants, known as "Juicers," designed to help users with a variety of tasks including writing, speaking, coding, image creation, and more. Each AI assistant is specialized for a specific function, allowing users to mix and match to create their ideal AI team. Juicy AI enables individuals and businesses to enhance productivity, streamline workflows, and tackle creative or technical challenges efficiently.
JuicyAI
Juicy AI is an innovative platform that provides a suite of AI assistants, known as "Juicers," designed to help users with a variety of tasks including writing, speaking, coding, image creation, and more. Each AI assistant is specialized for a specific function, allowing users to mix and match to create their ideal AI team. Juicy AI enables individuals and businesses to enhance productivity, streamline workflows, and tackle creative or technical challenges efficiently.
JuicyAI
Juicy AI is an innovative platform that provides a suite of AI assistants, known as "Juicers," designed to help users with a variety of tasks including writing, speaking, coding, image creation, and more. Each AI assistant is specialized for a specific function, allowing users to mix and match to create their ideal AI team. Juicy AI enables individuals and businesses to enhance productivity, streamline workflows, and tackle creative or technical challenges efficiently.

Hume
Hume AI is a company focused on creating emotionally intelligent voice-AI and speech systems. It advances voice-interfaces by not only converting text to speech, but enabling voices that convey emotion, adapt to the user’s tone, interruptions and context, and integrate conversationally with underlying language models. The technology is built on affective-computing research and aims to give voice agents more human-like responsiveness and emotional awareness. Clients include customer-service, healthcare and consumer-applications requiring nuanced voice interaction beyond a typical voice-bot. Hume AI emphasises real-time voice, emotional intelligence, and human-centric voice experiences.
Hume
Hume AI is a company focused on creating emotionally intelligent voice-AI and speech systems. It advances voice-interfaces by not only converting text to speech, but enabling voices that convey emotion, adapt to the user’s tone, interruptions and context, and integrate conversationally with underlying language models. The technology is built on affective-computing research and aims to give voice agents more human-like responsiveness and emotional awareness. Clients include customer-service, healthcare and consumer-applications requiring nuanced voice interaction beyond a typical voice-bot. Hume AI emphasises real-time voice, emotional intelligence, and human-centric voice experiences.
Hume
Hume AI is a company focused on creating emotionally intelligent voice-AI and speech systems. It advances voice-interfaces by not only converting text to speech, but enabling voices that convey emotion, adapt to the user’s tone, interruptions and context, and integrate conversationally with underlying language models. The technology is built on affective-computing research and aims to give voice agents more human-like responsiveness and emotional awareness. Clients include customer-service, healthcare and consumer-applications requiring nuanced voice interaction beyond a typical voice-bot. Hume AI emphasises real-time voice, emotional intelligence, and human-centric voice experiences.
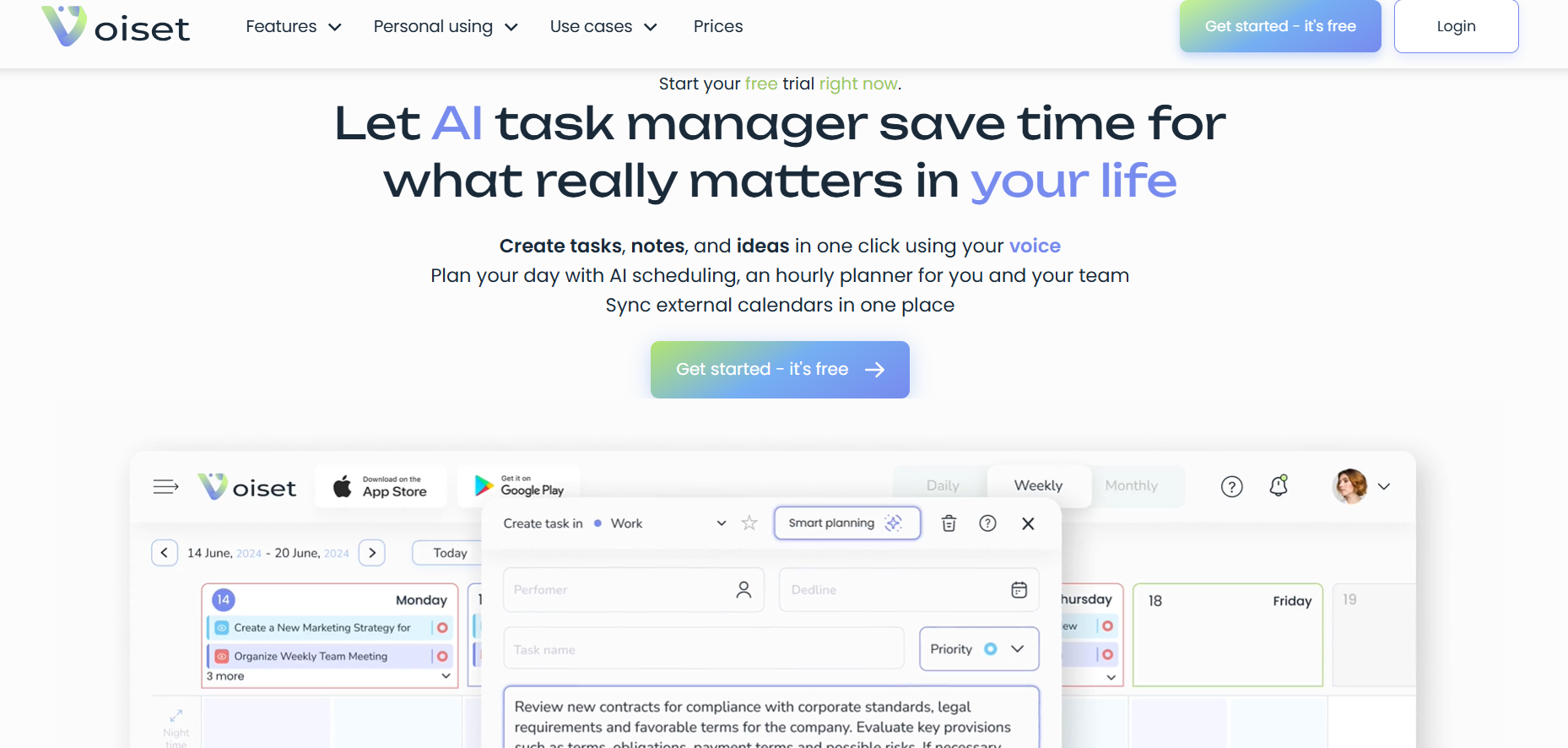
Voiset
Voiset is an AI-driven voice automation and conversational intelligence platform designed to enhance business communication, sales, and customer service. It allows teams to build intelligent voice agents that handle inbound and outbound calls, transcribe conversations, and provide real-time analytics. With advanced natural language processing, Voiset enables companies to automate communication tasks, reduce call handling time, and maintain personalized customer interactions. It integrates seamlessly with CRM tools and supports multiple languages, making it ideal for global teams and enterprises looking to scale voice operations.
Voiset
Voiset is an AI-driven voice automation and conversational intelligence platform designed to enhance business communication, sales, and customer service. It allows teams to build intelligent voice agents that handle inbound and outbound calls, transcribe conversations, and provide real-time analytics. With advanced natural language processing, Voiset enables companies to automate communication tasks, reduce call handling time, and maintain personalized customer interactions. It integrates seamlessly with CRM tools and supports multiple languages, making it ideal for global teams and enterprises looking to scale voice operations.
Voiset
Voiset is an AI-driven voice automation and conversational intelligence platform designed to enhance business communication, sales, and customer service. It allows teams to build intelligent voice agents that handle inbound and outbound calls, transcribe conversations, and provide real-time analytics. With advanced natural language processing, Voiset enables companies to automate communication tasks, reduce call handling time, and maintain personalized customer interactions. It integrates seamlessly with CRM tools and supports multiple languages, making it ideal for global teams and enterprises looking to scale voice operations.
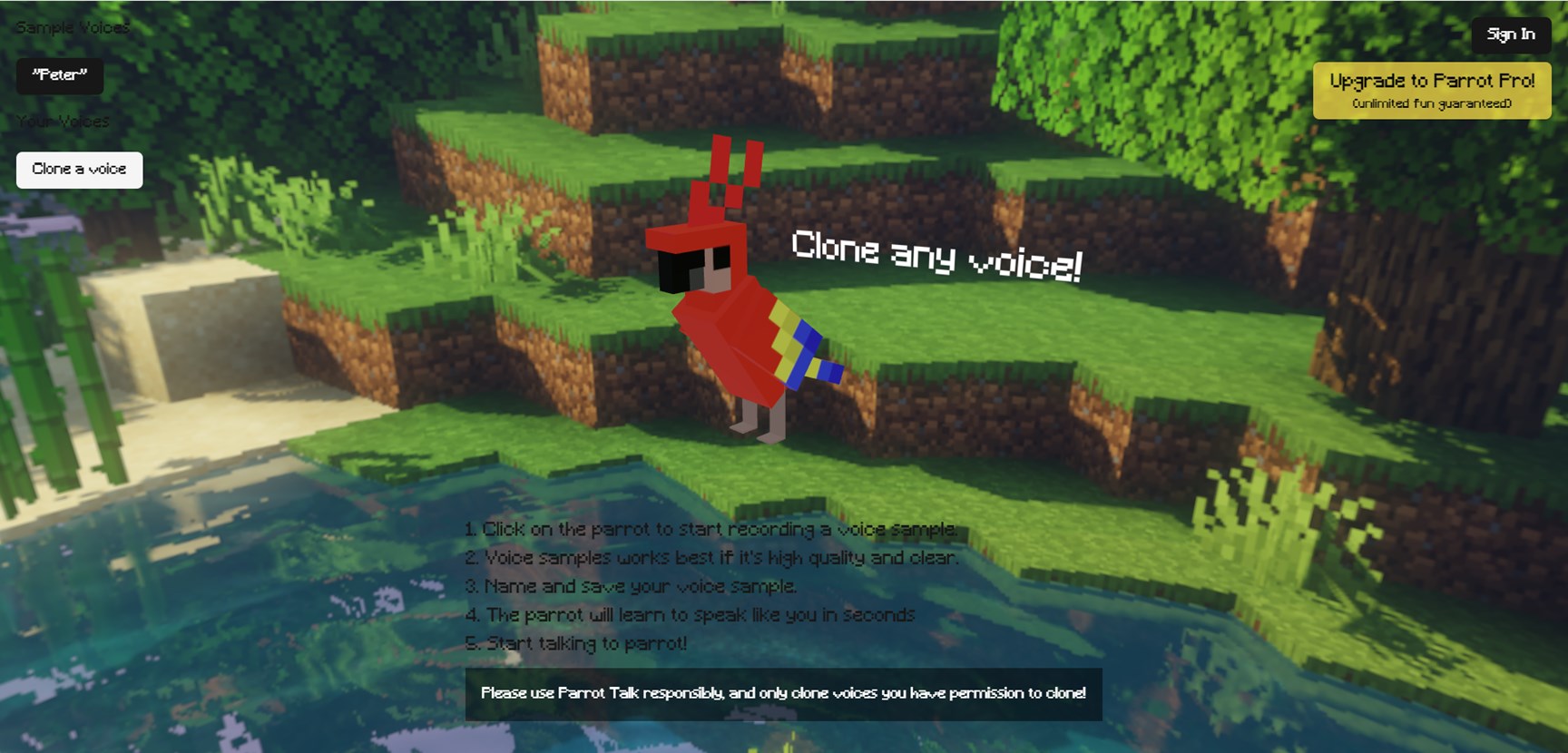

Parrot Talk
Parrottalk.ai is a cutting-edge voice cloning platform that lets users replicate any voice using just a single short audio recording. Upload a 10-second sample, and the AI generates realistic speech clones for podcasts, videos, audiobooks, or creative projects. It delivers high-fidelity results with natural intonation, accents, and timbre, making it ideal for content creators needing custom voices without expensive studios. The tool emphasizes ease-of-use with a simple web interface, quick processing times, and options for fine-tuning clones. Privacy-focused and accessible to beginners or pros, Parrottalk.ai transforms voiceovers, enabling personalized audio content at scale.
Parrot Talk
Parrottalk.ai is a cutting-edge voice cloning platform that lets users replicate any voice using just a single short audio recording. Upload a 10-second sample, and the AI generates realistic speech clones for podcasts, videos, audiobooks, or creative projects. It delivers high-fidelity results with natural intonation, accents, and timbre, making it ideal for content creators needing custom voices without expensive studios. The tool emphasizes ease-of-use with a simple web interface, quick processing times, and options for fine-tuning clones. Privacy-focused and accessible to beginners or pros, Parrottalk.ai transforms voiceovers, enabling personalized audio content at scale.
Parrot Talk
Parrottalk.ai is a cutting-edge voice cloning platform that lets users replicate any voice using just a single short audio recording. Upload a 10-second sample, and the AI generates realistic speech clones for podcasts, videos, audiobooks, or creative projects. It delivers high-fidelity results with natural intonation, accents, and timbre, making it ideal for content creators needing custom voices without expensive studios. The tool emphasizes ease-of-use with a simple web interface, quick processing times, and options for fine-tuning clones. Privacy-focused and accessible to beginners or pros, Parrottalk.ai transforms voiceovers, enabling personalized audio content at scale.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai