
It delivers smoother, faster, and more conversational speech experiences, making it an ideal choice for developers building next-gen voice-driven products.
- Real-Time App Developers: Ideal for apps that need on-the-fly responses, like customer support bots or AI companions.
- Conversational AI Creators: Build natural-sounding dialogue systems with virtually zero lag.
- Accessibility Platform Builders: Enable real-time screen reading or narration for visually impaired users.
- EdTech & eLearning Providers: Power engaging, responsive learning experiences with voice-driven content.
- Voice-Enabled Products: Create voice interfaces for IoT devices, kiosks, or embedded systems.
- Game Developers: Give characters real-time voice responses and enhance immersion.
🤖 How Does It Work?
- Step 1: Use Streaming Endpoint: Access the /v1/audio/speech endpoint with the voice and model set to tts-1-hd.
- Step 2: Enable Streaming Mode: Activate the streaming feature to receive partial audio chunks in real time.
- Step 3: Pass Input Text: Input user-generated or dynamically created text that you want converted to speech.
- Step 4: Process Audio on the Fly: Play back audio as it arrives, without waiting for the full response to complete.
- Step 5: Integrate Seamlessly: Combine with tools like Whisper, GPT-4o, or your own application logic to create interactive, spoken experiences.
- Ultra-Low Latency Streaming: Speech is generated as you go, not after the entire text is processed.
- Hyper-Realistic Output: Uses the latest speech synthesis tech to produce near-human, expressive voices.
- Built for Real-Time Interactions: Tailored for fast-paced scenarios like conversations, virtual agents, and real-time narration.
- Multiple Voices Available: Choose from OpenAI’s best-in-class voice library (e.g., nova, shimmer).
- Smooth API Experience: Easily accessible through OpenAI’s standard developer API.
- Seamless GPT Integration: Pairs perfectly with GPT-4o for true multimodal voice-based AI.
- Incredible Real-Time Voice Generation: Streams high-quality speech instantly as the text flows.
- Optimized for Conversations: Feels like you're talking to a person, not a machine.
- Easily Integrates into Apps: Works with standard HTTP streaming and audio playback tools.
- Ideal for Accessibility Use Cases: Great for live content narration and screen reading.
- Built to Pair with GPT-4o: Enables full-duplex AI agents that listen, think, and speak instantly.
- Limited Customization: You can’t yet fine-tune emotional tone, pitch, or speed.
- Multilingual Support Still Growing: Works best in English; support for other languages is limited.
- No Voice Cloning or Custom Voices: Only prebuilt voices available—no custom training or cloning.
- Requires Handling Streaming Logic: Integration may need more engineering effort vs. standard TTS.
- Costs Can Stack Up: Real-time streaming is compute-heavy and may impact budget at scale.
1 million tokens
$ 30.00
Output: Audio only
Endpoints: v1/audio/speech (Speech generation), plus Chat Completions, Responses, Realtime, Assistants, and Batch.
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

GPT-4o-mini-transcribe is a lightweight, high-speed speech-to-text model from OpenAI, built on the GPT-4o-mini architecture. It converts spoken language into text with exceptional speed and surprising accuracy for its size—making it ideal for real-time transcription in resource-constrained environments. Whether you're building voice-enabled apps, smart assistants, meeting transcription tools, or captioning systems, GPT-4o-mini-transcribe offers responsive, multilingual transcription that balances cost, performance, and ease of integration.
GPT-4o-mini-transcribe is a lightweight, high-speed speech-to-text model from OpenAI, built on the GPT-4o-mini architecture. It converts spoken language into text with exceptional speed and surprising accuracy for its size—making it ideal for real-time transcription in resource-constrained environments. Whether you're building voice-enabled apps, smart assistants, meeting transcription tools, or captioning systems, GPT-4o-mini-transcribe offers responsive, multilingual transcription that balances cost, performance, and ease of integration.
GPT-4o-mini-transcribe is a lightweight, high-speed speech-to-text model from OpenAI, built on the GPT-4o-mini architecture. It converts spoken language into text with exceptional speed and surprising accuracy for its size—making it ideal for real-time transcription in resource-constrained environments. Whether you're building voice-enabled apps, smart assistants, meeting transcription tools, or captioning systems, GPT-4o-mini-transcribe offers responsive, multilingual transcription that balances cost, performance, and ease of integration.
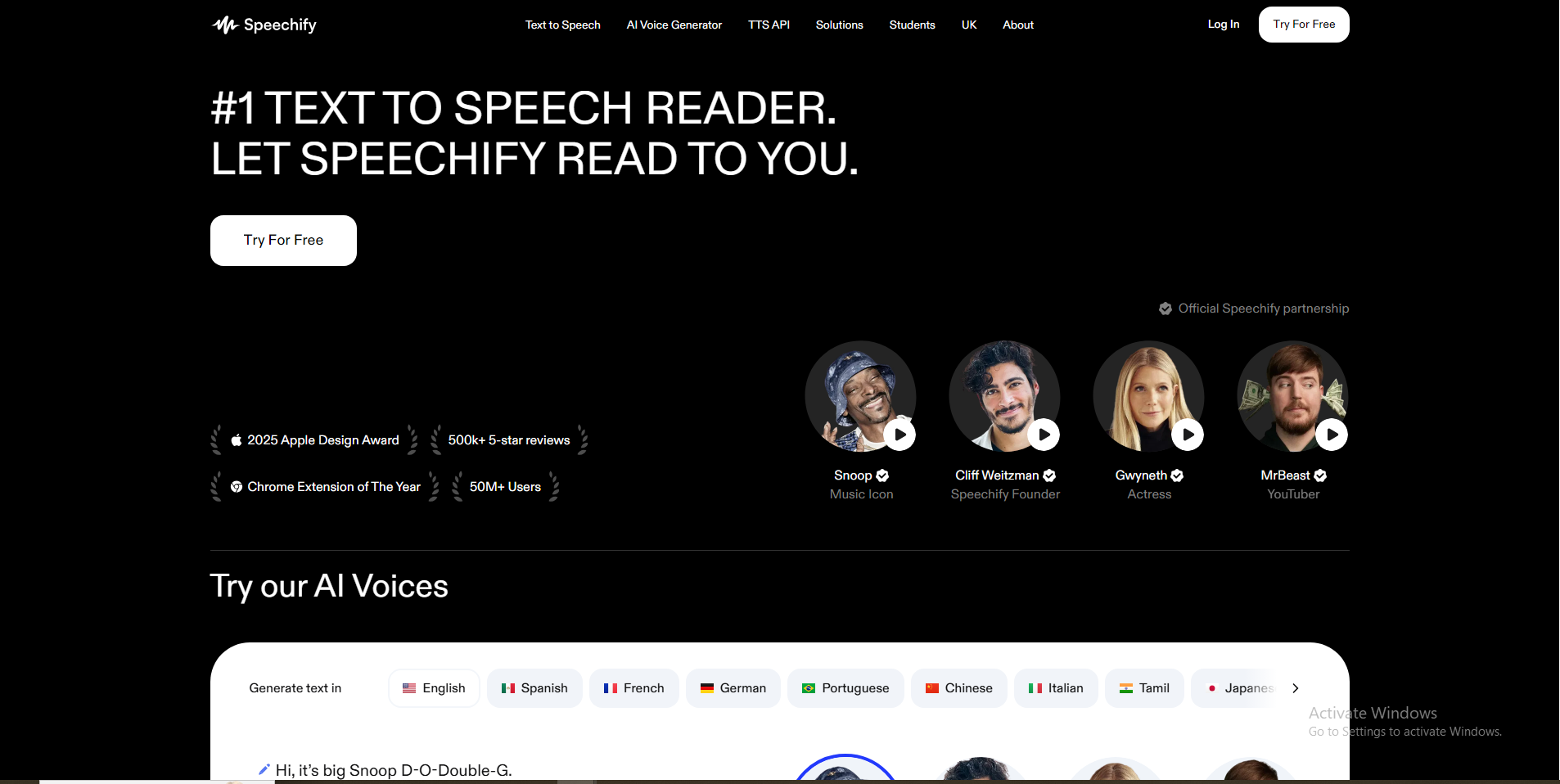

Speechify
Speechify.com is a leading AI-powered text-to-speech (TTS) reader designed to transform any written text into natural-sounding audio. With millions of users and high ratings, it aims to help individuals consume content faster and more efficiently across various devices and platforms. Beyond basic text-to-speech, Speechify also offers advanced AI features for content creators, including AI voice generation, voice cloning, and dubbing.
Speechify
Speechify.com is a leading AI-powered text-to-speech (TTS) reader designed to transform any written text into natural-sounding audio. With millions of users and high ratings, it aims to help individuals consume content faster and more efficiently across various devices and platforms. Beyond basic text-to-speech, Speechify also offers advanced AI features for content creators, including AI voice generation, voice cloning, and dubbing.
Speechify
Speechify.com is a leading AI-powered text-to-speech (TTS) reader designed to transform any written text into natural-sounding audio. With millions of users and high ratings, it aims to help individuals consume content faster and more efficiently across various devices and platforms. Beyond basic text-to-speech, Speechify also offers advanced AI features for content creators, including AI voice generation, voice cloning, and dubbing.
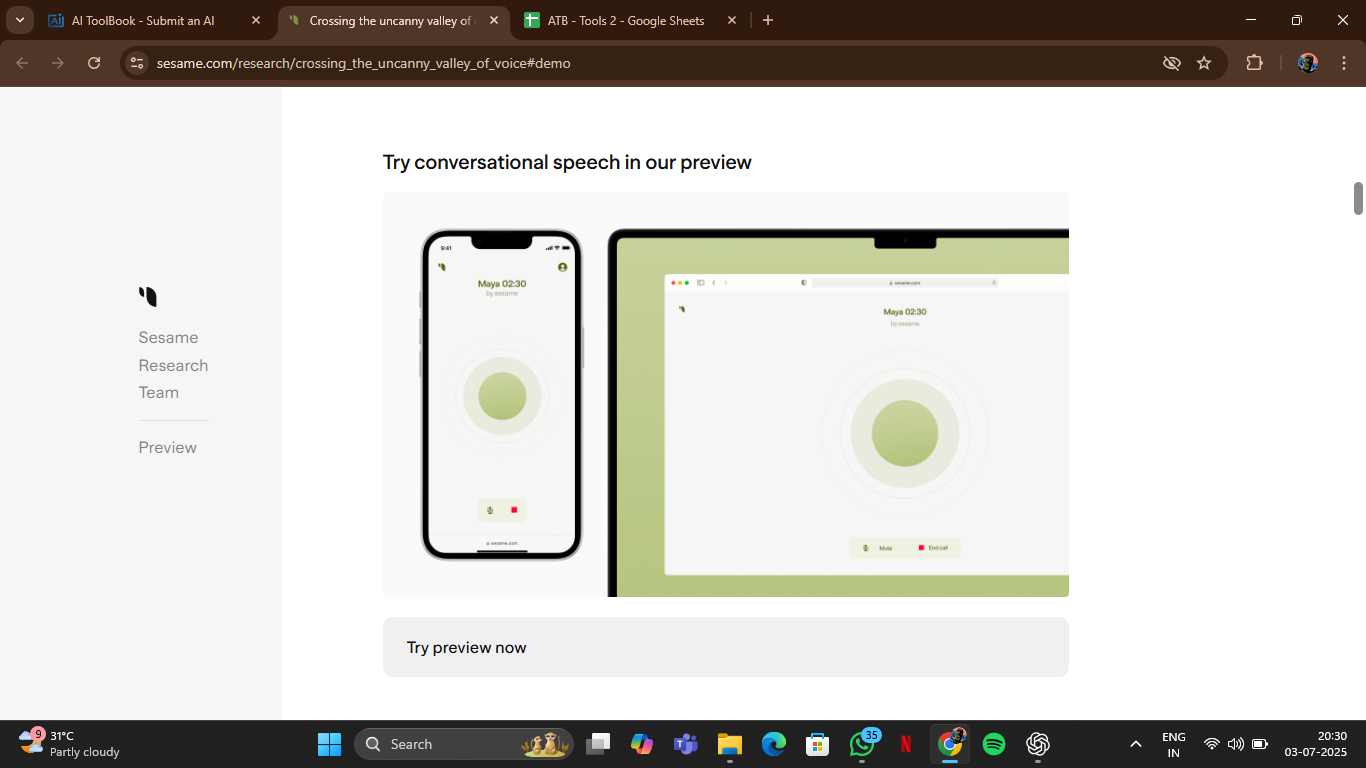
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.

Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.


VoiSpark
VoiSpark is an advanced AI-driven voice generation platform designed to transform text into natural, expressive speech and to create unique vocal identities using industry-leading AI models like ElevenLabs, Cartesia, and OpenAI. The platform offers tools for text-to-speech conversion, voice generation with emotion and pitch control, voice changing to mimic celebrities or cartoons, and voice cloning with just one minute of audio. VoiSpark supports over 500 human-like voices across 30+ languages, making it ideal for content creators, marketers, and businesses seeking studio-quality voice solutions.
VoiSpark
VoiSpark is an advanced AI-driven voice generation platform designed to transform text into natural, expressive speech and to create unique vocal identities using industry-leading AI models like ElevenLabs, Cartesia, and OpenAI. The platform offers tools for text-to-speech conversion, voice generation with emotion and pitch control, voice changing to mimic celebrities or cartoons, and voice cloning with just one minute of audio. VoiSpark supports over 500 human-like voices across 30+ languages, making it ideal for content creators, marketers, and businesses seeking studio-quality voice solutions.
VoiSpark
VoiSpark is an advanced AI-driven voice generation platform designed to transform text into natural, expressive speech and to create unique vocal identities using industry-leading AI models like ElevenLabs, Cartesia, and OpenAI. The platform offers tools for text-to-speech conversion, voice generation with emotion and pitch control, voice changing to mimic celebrities or cartoons, and voice cloning with just one minute of audio. VoiSpark supports over 500 human-like voices across 30+ languages, making it ideal for content creators, marketers, and businesses seeking studio-quality voice solutions.
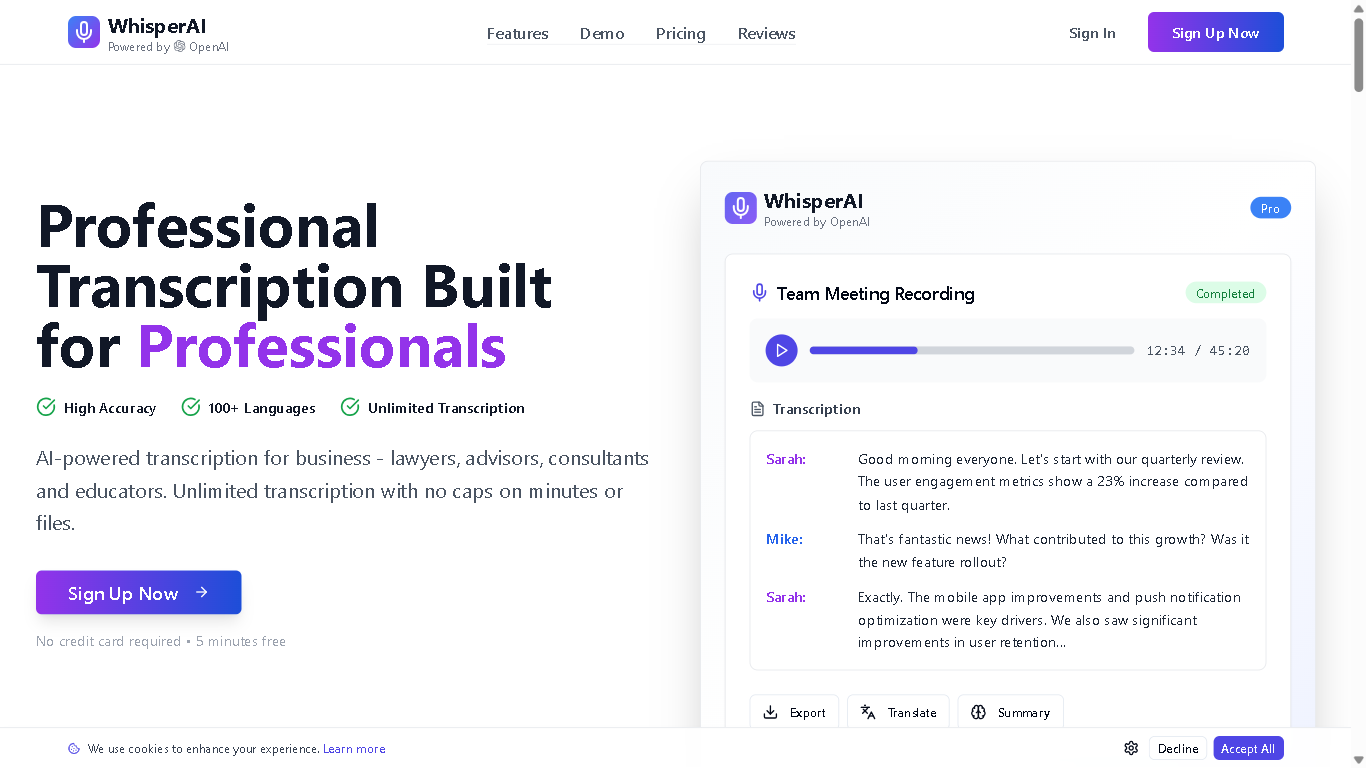
Whisprai.ai is an AI-powered transcription and summarization tool designed to help businesses and individuals quickly and accurately transcribe audio and video files, and generate concise summaries of their content. It offers features for improving workflow efficiency and enhancing productivity through AI-driven automation.
Whisprai.ai is an AI-powered transcription and summarization tool designed to help businesses and individuals quickly and accurately transcribe audio and video files, and generate concise summaries of their content. It offers features for improving workflow efficiency and enhancing productivity through AI-driven automation.
Whisprai.ai is an AI-powered transcription and summarization tool designed to help businesses and individuals quickly and accurately transcribe audio and video files, and generate concise summaries of their content. It offers features for improving workflow efficiency and enhancing productivity through AI-driven automation.
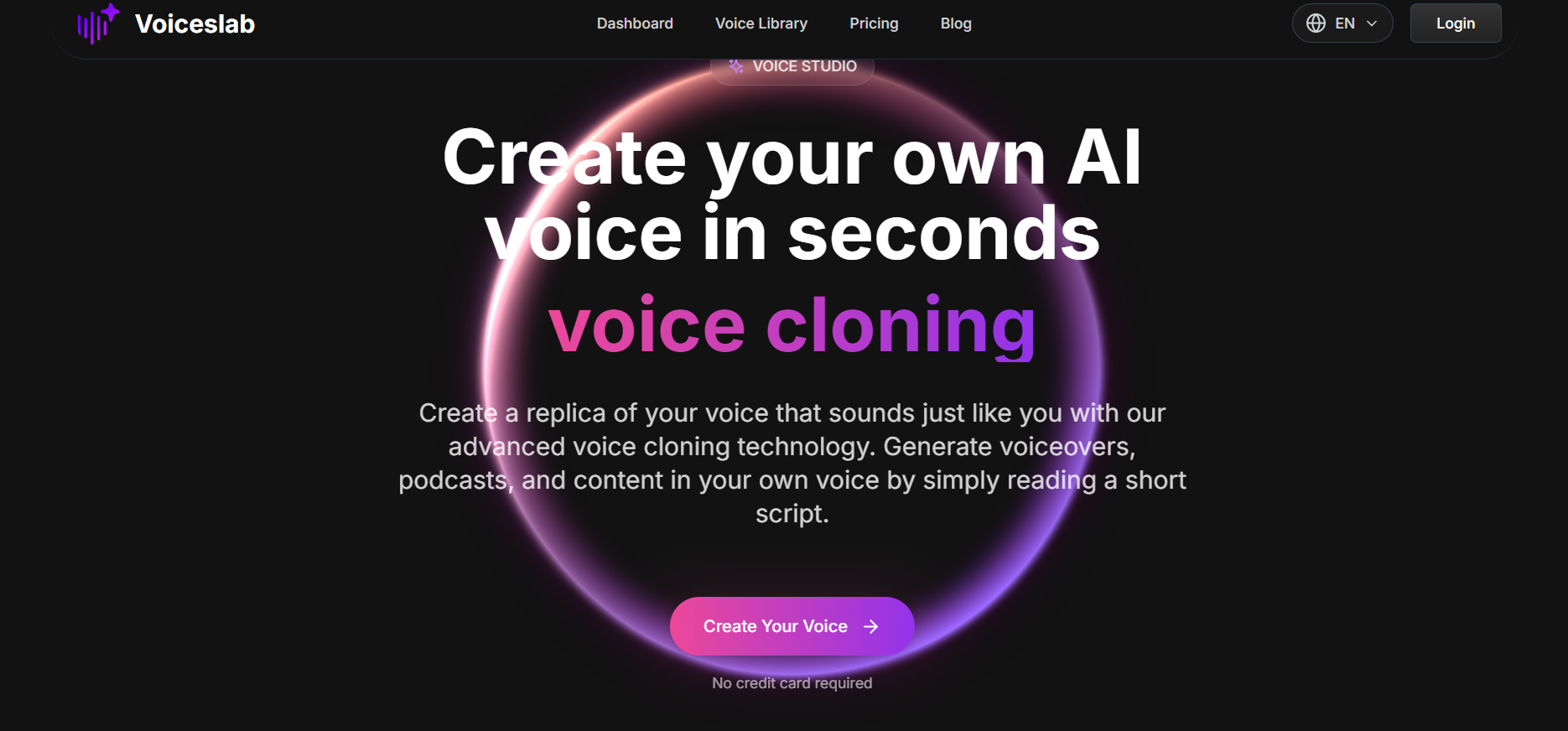
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Lovo
LOVO AI is a voiceover and video creation platform that combines an advanced text-to-speech engine with an online editor to produce natural, production-ready audio and visuals. With 500+ voices across 100+ languages, it enables rapid creation of voiceovers for marketing, e-learning, podcasts, social content, and more. Its Genny workspace adds scriptwriting, voice cloning, auto-subtitles, and AI image generation to streamline end-to-end production. Directable Pro V2 voices allow nuanced control of tone and delivery using natural language directions. Teams can collaborate in the cloud, export quickly, and even integrate via API to bring LOVO’s voices into apps and workflows. A free tier and trial options help projects start fast without setup friction.
Lovo
LOVO AI is a voiceover and video creation platform that combines an advanced text-to-speech engine with an online editor to produce natural, production-ready audio and visuals. With 500+ voices across 100+ languages, it enables rapid creation of voiceovers for marketing, e-learning, podcasts, social content, and more. Its Genny workspace adds scriptwriting, voice cloning, auto-subtitles, and AI image generation to streamline end-to-end production. Directable Pro V2 voices allow nuanced control of tone and delivery using natural language directions. Teams can collaborate in the cloud, export quickly, and even integrate via API to bring LOVO’s voices into apps and workflows. A free tier and trial options help projects start fast without setup friction.
Lovo
LOVO AI is a voiceover and video creation platform that combines an advanced text-to-speech engine with an online editor to produce natural, production-ready audio and visuals. With 500+ voices across 100+ languages, it enables rapid creation of voiceovers for marketing, e-learning, podcasts, social content, and more. Its Genny workspace adds scriptwriting, voice cloning, auto-subtitles, and AI image generation to streamline end-to-end production. Directable Pro V2 voices allow nuanced control of tone and delivery using natural language directions. Teams can collaborate in the cloud, export quickly, and even integrate via API to bring LOVO’s voices into apps and workflows. A free tier and trial options help projects start fast without setup friction.

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.

Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Voicemaker
Voicemaker is an AI-based online text-to-speech platform that turns written text into natural-sounding voiceovers across a wide range of languages and use cases. It offers ultra-fast, low-latency speech suitable for real-time applications, studio-like voices for production-quality narration, and a prompt-based dynamic model for highly expressive storytelling. Creators can fine-tune voice parameters such as volume, speed, pitch, stability, and similarity to match brand or project needs. Generated audio files can be redistributed globally, even after a subscription ends, enabling flexible usage across platforms. With simple controls and scalable voice options, Voicemaker streamlines voiceover creation for content, podcasts, videos, and more.
Voicemaker
Voicemaker is an AI-based online text-to-speech platform that turns written text into natural-sounding voiceovers across a wide range of languages and use cases. It offers ultra-fast, low-latency speech suitable for real-time applications, studio-like voices for production-quality narration, and a prompt-based dynamic model for highly expressive storytelling. Creators can fine-tune voice parameters such as volume, speed, pitch, stability, and similarity to match brand or project needs. Generated audio files can be redistributed globally, even after a subscription ends, enabling flexible usage across platforms. With simple controls and scalable voice options, Voicemaker streamlines voiceover creation for content, podcasts, videos, and more.
Voicemaker
Voicemaker is an AI-based online text-to-speech platform that turns written text into natural-sounding voiceovers across a wide range of languages and use cases. It offers ultra-fast, low-latency speech suitable for real-time applications, studio-like voices for production-quality narration, and a prompt-based dynamic model for highly expressive storytelling. Creators can fine-tune voice parameters such as volume, speed, pitch, stability, and similarity to match brand or project needs. Generated audio files can be redistributed globally, even after a subscription ends, enabling flexible usage across platforms. With simple controls and scalable voice options, Voicemaker streamlines voiceover creation for content, podcasts, videos, and more.

Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai