It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
- Game Developers: Craft lifelike NPC dialogue or immersive storytelling with emotion-aware AI voices.
- Filmmakers & Animators: Generate voiceovers and character voices with natural tone shifts and delivery.
- Product Designers: Build more humanlike and emotionally resonant voice assistants or chatbots.
- Audio Creators & Podcasters: Use expressive voices to script narrative content, intros, and dialogues.
- Marketing Teams: Enhance brand presence with custom voices that can evoke specific emotional tones.
How to Use Sesame Voice AI?
- Visit the Platform: Head to the Sesame Voice AI demo page.
- Upload or Input Text: Provide written content or use demo prompts provided on the site.
- Choose Voice & Emotion: Select from various emotional tones (like excited, skeptical, tired, etc.) and personality profiles.
- Generate & Listen: Hear the AI-generated voice read your content aloud with natural emotion.
- Integrate via API: For more advanced users, integration options are available for real-time or batch processing in apps or services.
- Emotionally Rich Voice Synthesis: Goes beyond flat text-to-speech with realistic delivery and tone changes.
- Personality-Powered Audio: Add distinct personality traits like humor, doubt, confidence, or sarcasm to the voice output.
- Cross-Platform Usability: Suitable for web demos, audio apps, games, and voice interfaces.
- Humanlike Variability: Adjusts pitch, pacing, hesitation, and inflection to reflect real human conversation patterns.
- Research-Driven: Backed by extensive R&D, Sesame’s model aims to redefine what's possible in speech AI.
- Voice output is strikingly humanlike and expressive.
- Offers personality and emotion customization not seen in many other tools.
- Great demo experience with pre-loaded emotional voice variations.
- Research-backed innovation and transparent methodology.
- No clear self-service platform or pricing plans for commercial users.
- Currently limited to demo—API or SDK access is not public.
- Use cases may be more suited to developers and enterprises than individual creators.
Custom
Custom
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
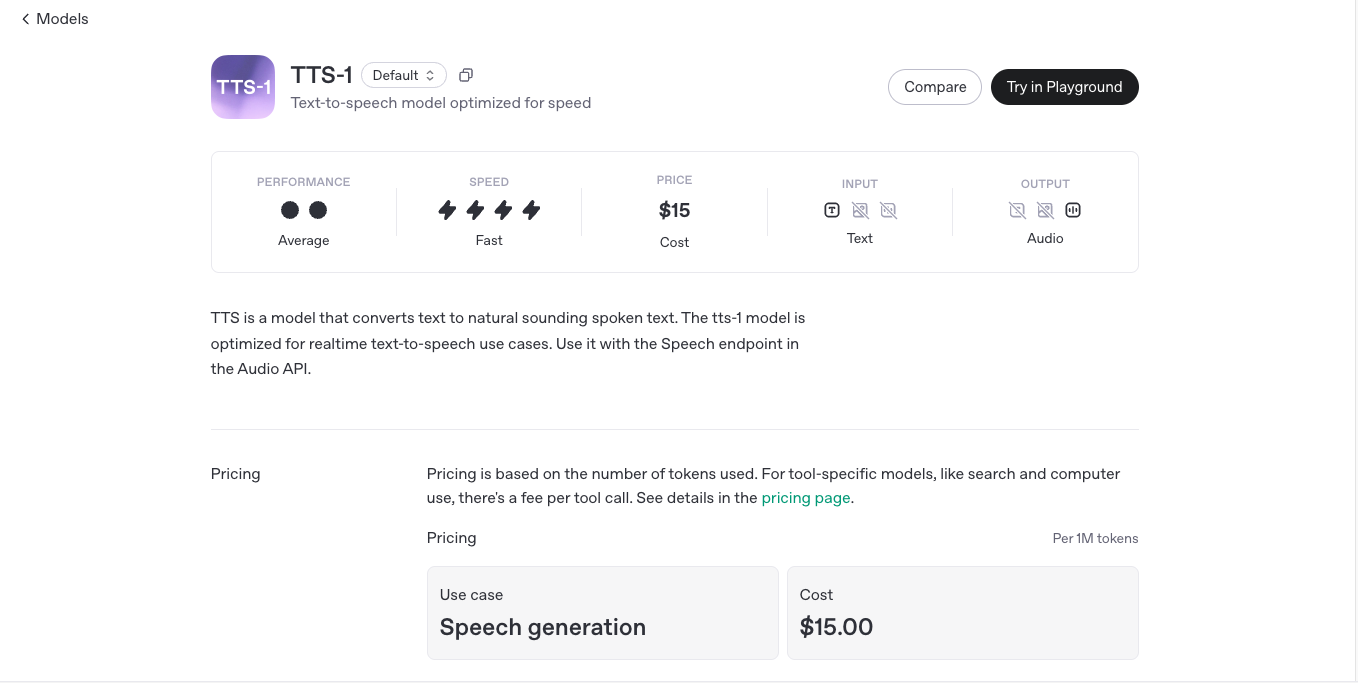
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.

OpenAI TTS1-HD
TTS-1-HD is OpenAI’s high-definition, low-latency streaming voice model designed to bring human-like speech to real-time applications. Building on the capabilities of the original TTS-1 model, TTS-1-HD enables developers to generate speech as the words are being produced—perfect for voice assistants, interactive bots, or live narration tools. It delivers smoother, faster, and more conversational speech experiences, making it an ideal choice for developers building next-gen voice-driven products.
OpenAI TTS1-HD
TTS-1-HD is OpenAI’s high-definition, low-latency streaming voice model designed to bring human-like speech to real-time applications. Building on the capabilities of the original TTS-1 model, TTS-1-HD enables developers to generate speech as the words are being produced—perfect for voice assistants, interactive bots, or live narration tools. It delivers smoother, faster, and more conversational speech experiences, making it an ideal choice for developers building next-gen voice-driven products.
OpenAI TTS1-HD
TTS-1-HD is OpenAI’s high-definition, low-latency streaming voice model designed to bring human-like speech to real-time applications. Building on the capabilities of the original TTS-1 model, TTS-1-HD enables developers to generate speech as the words are being produced—perfect for voice assistants, interactive bots, or live narration tools. It delivers smoother, faster, and more conversational speech experiences, making it an ideal choice for developers building next-gen voice-driven products.

Speechify
Speechify.com is a leading AI-powered text-to-speech (TTS) reader designed to transform any written text into natural-sounding audio. With millions of users and high ratings, it aims to help individuals consume content faster and more efficiently across various devices and platforms. Beyond basic text-to-speech, Speechify also offers advanced AI features for content creators, including AI voice generation, voice cloning, and dubbing.
Speechify
Speechify.com is a leading AI-powered text-to-speech (TTS) reader designed to transform any written text into natural-sounding audio. With millions of users and high ratings, it aims to help individuals consume content faster and more efficiently across various devices and platforms. Beyond basic text-to-speech, Speechify also offers advanced AI features for content creators, including AI voice generation, voice cloning, and dubbing.
Speechify
Speechify.com is a leading AI-powered text-to-speech (TTS) reader designed to transform any written text into natural-sounding audio. With millions of users and high ratings, it aims to help individuals consume content faster and more efficiently across various devices and platforms. Beyond basic text-to-speech, Speechify also offers advanced AI features for content creators, including AI voice generation, voice cloning, and dubbing.

Rev AI
Rev.ai is an AI-powered speech-to-text API platform that provides developers and enterprises with highly accurate transcription and advanced speech intelligence tools. Leveraging cutting-edge ASR models, Rev.ai enables seamless audio and video transcription, real-time streaming, language detection, sentiment analysis, topic extraction, summarization, translation, and more.
Rev AI
Rev.ai is an AI-powered speech-to-text API platform that provides developers and enterprises with highly accurate transcription and advanced speech intelligence tools. Leveraging cutting-edge ASR models, Rev.ai enables seamless audio and video transcription, real-time streaming, language detection, sentiment analysis, topic extraction, summarization, translation, and more.
Rev AI
Rev.ai is an AI-powered speech-to-text API platform that provides developers and enterprises with highly accurate transcription and advanced speech intelligence tools. Leveraging cutting-edge ASR models, Rev.ai enables seamless audio and video transcription, real-time streaming, language detection, sentiment analysis, topic extraction, summarization, translation, and more.


VoiSpark
VoiSpark is an advanced AI-driven voice generation platform designed to transform text into natural, expressive speech and to create unique vocal identities using industry-leading AI models like ElevenLabs, Cartesia, and OpenAI. The platform offers tools for text-to-speech conversion, voice generation with emotion and pitch control, voice changing to mimic celebrities or cartoons, and voice cloning with just one minute of audio. VoiSpark supports over 500 human-like voices across 30+ languages, making it ideal for content creators, marketers, and businesses seeking studio-quality voice solutions.
VoiSpark
VoiSpark is an advanced AI-driven voice generation platform designed to transform text into natural, expressive speech and to create unique vocal identities using industry-leading AI models like ElevenLabs, Cartesia, and OpenAI. The platform offers tools for text-to-speech conversion, voice generation with emotion and pitch control, voice changing to mimic celebrities or cartoons, and voice cloning with just one minute of audio. VoiSpark supports over 500 human-like voices across 30+ languages, making it ideal for content creators, marketers, and businesses seeking studio-quality voice solutions.
VoiSpark
VoiSpark is an advanced AI-driven voice generation platform designed to transform text into natural, expressive speech and to create unique vocal identities using industry-leading AI models like ElevenLabs, Cartesia, and OpenAI. The platform offers tools for text-to-speech conversion, voice generation with emotion and pitch control, voice changing to mimic celebrities or cartoons, and voice cloning with just one minute of audio. VoiSpark supports over 500 human-like voices across 30+ languages, making it ideal for content creators, marketers, and businesses seeking studio-quality voice solutions.
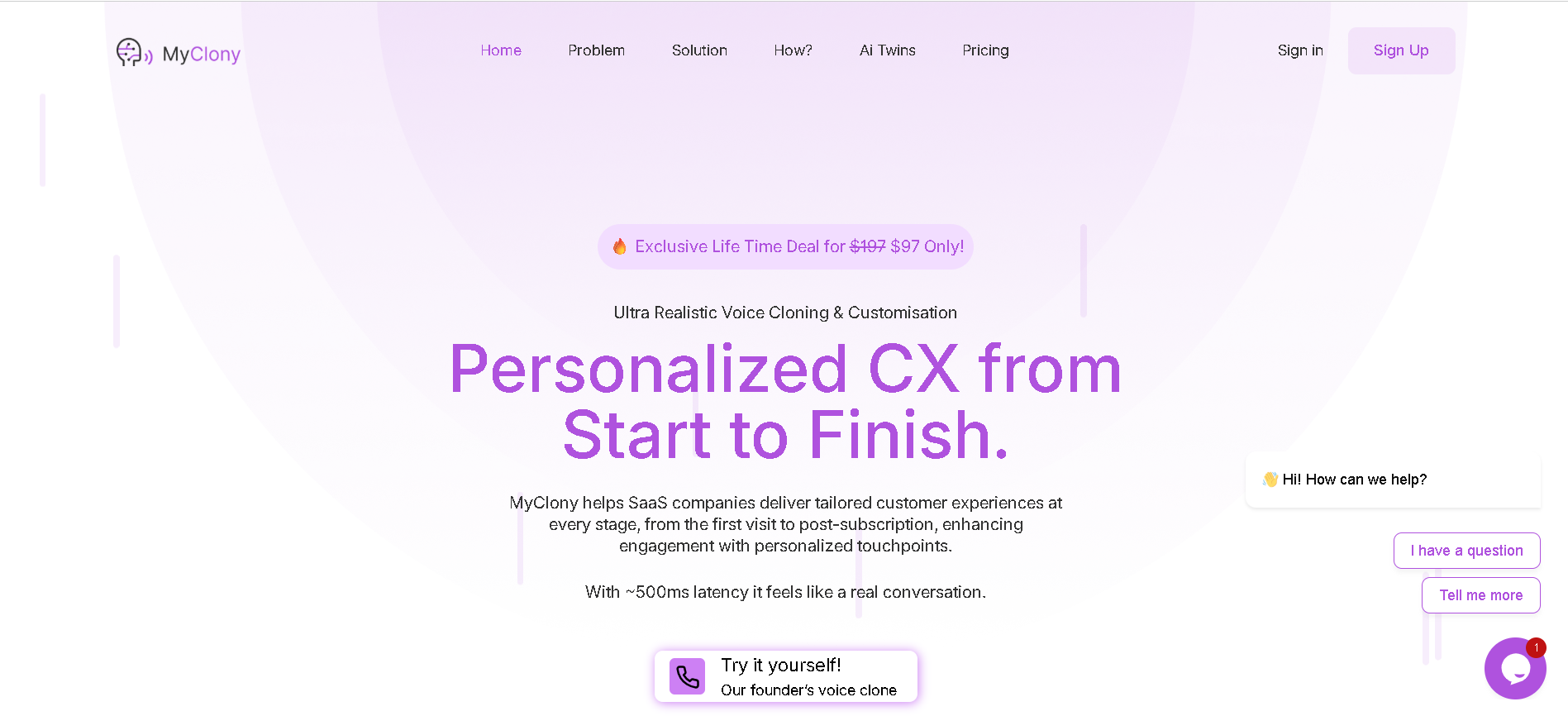
MyClony
Myclony is an AI-powered interactive voice cloning platform designed to enhance customer experience for SaaS companies. It creates personalized "Voice Twins" that provide real-time, human-like assistance, helping businesses to automate customer support and sales processes while fostering deeper emotional connections and trust.
MyClony
Myclony is an AI-powered interactive voice cloning platform designed to enhance customer experience for SaaS companies. It creates personalized "Voice Twins" that provide real-time, human-like assistance, helping businesses to automate customer support and sales processes while fostering deeper emotional connections and trust.
MyClony
Myclony is an AI-powered interactive voice cloning platform designed to enhance customer experience for SaaS companies. It creates personalized "Voice Twins" that provide real-time, human-like assistance, helping businesses to automate customer support and sales processes while fostering deeper emotional connections and trust.
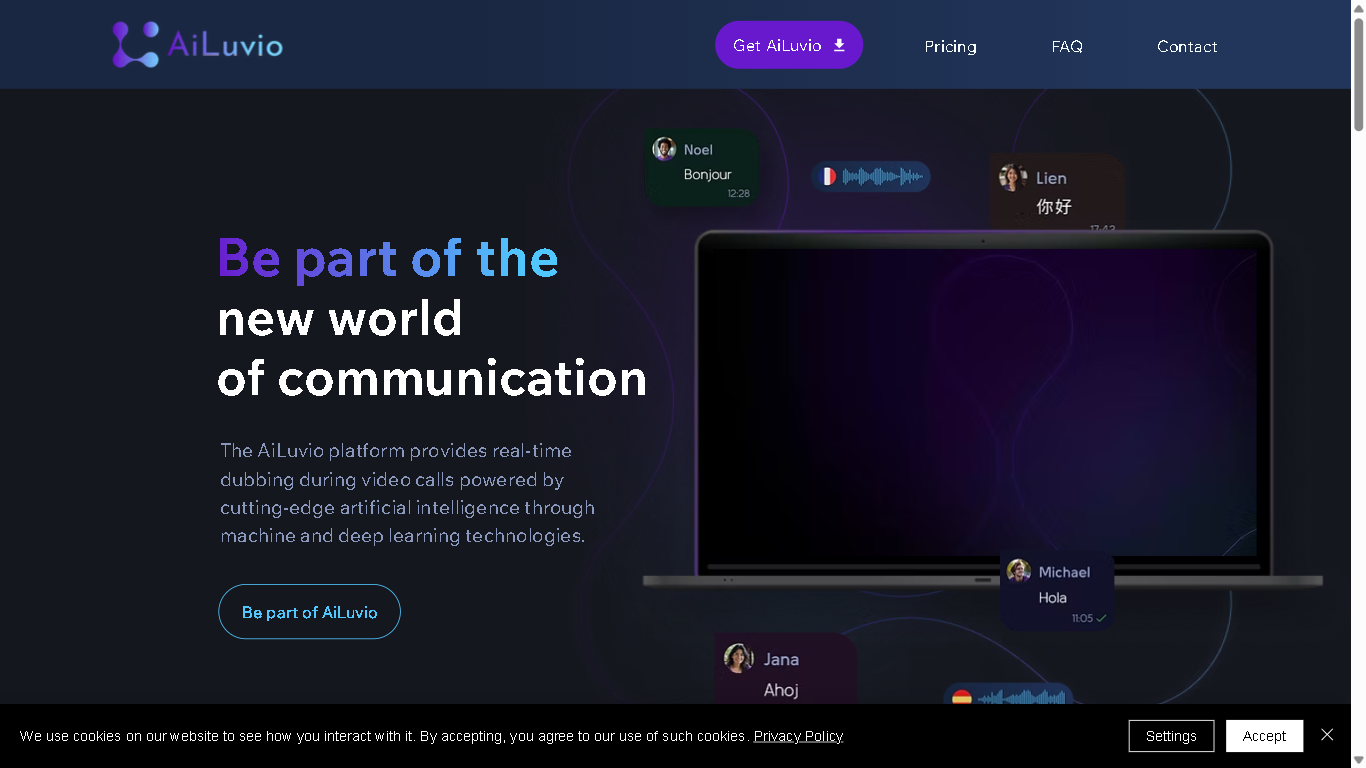

AiLuvio
AiLuvio is an AI-powered video communication platform that enables real-time dubbing during video calls in over 30 languages. It breaks down language barriers by translating speech in live conversations and offering features like automatic chat translation, voice cloning, and secure communication.
AiLuvio
AiLuvio is an AI-powered video communication platform that enables real-time dubbing during video calls in over 30 languages. It breaks down language barriers by translating speech in live conversations and offering features like automatic chat translation, voice cloning, and secure communication.
AiLuvio
AiLuvio is an AI-powered video communication platform that enables real-time dubbing during video calls in over 30 languages. It breaks down language barriers by translating speech in live conversations and offering features like automatic chat translation, voice cloning, and secure communication.
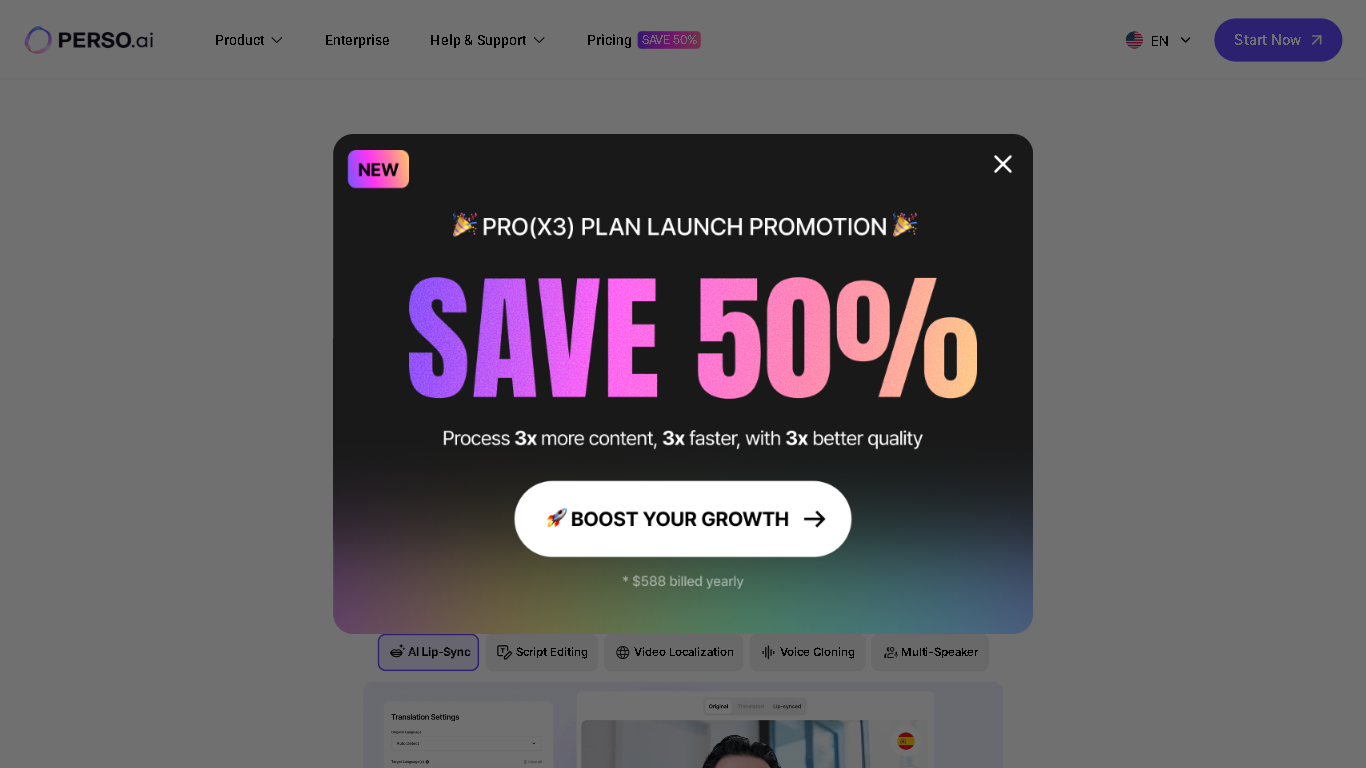
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
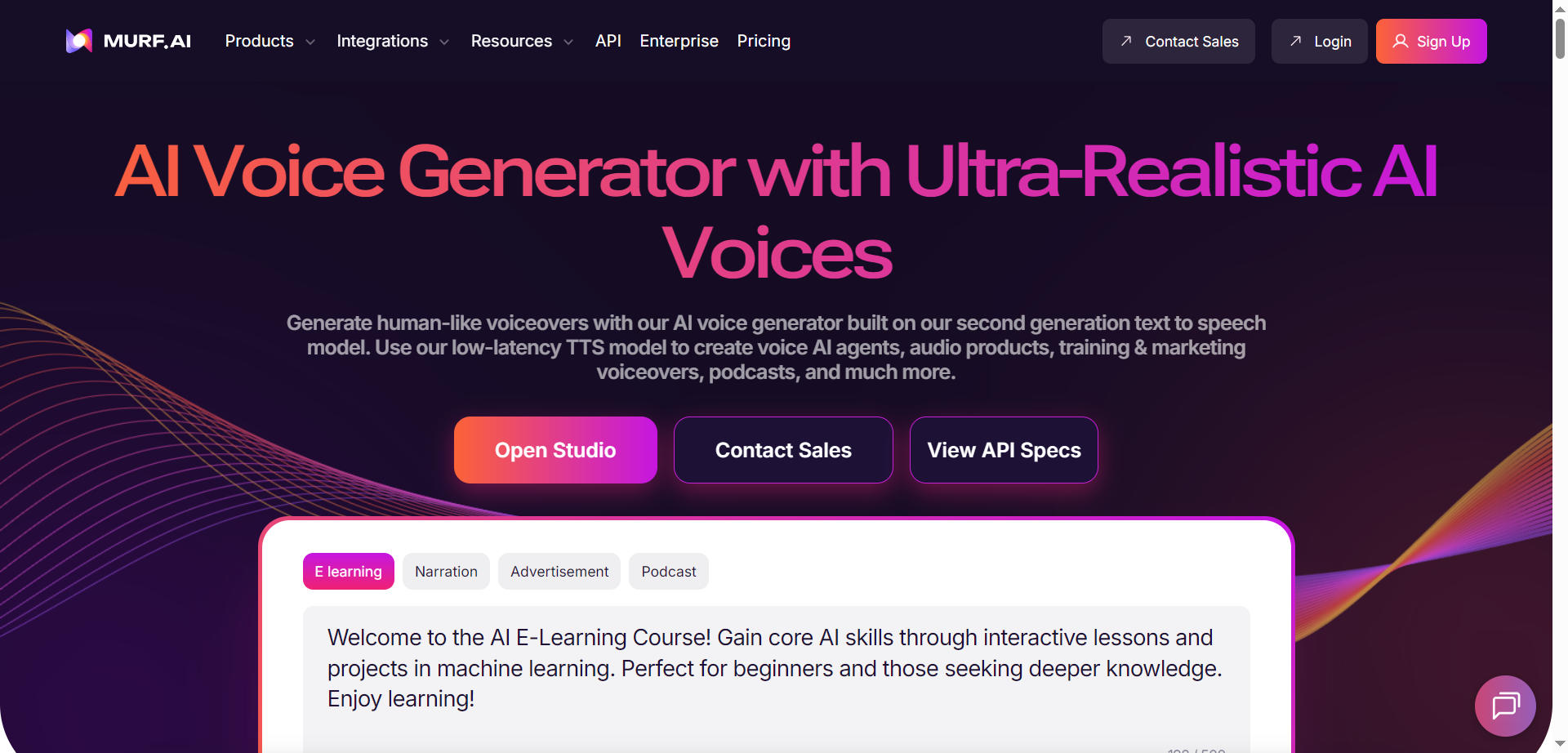

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.


Narakeet
Narakeet is a text-to-speech and video automation platform that turns scripts, slides, and subtitle files into narrated videos and voiceovers at scale. It offers 100 languages and 800 realistic voices, letting teams update narration by simply editing text instead of re-recording audio. Users can convert PowerPoint, Google Slides, or Keynote into full HD videos with captions, or turn SRT/WebVTT subtitles into synchronized dubbing tracks. Markdown scripting and templates streamline creating social clips, tutorials, and product demos. With API and CLI support, Narakeet automates multi-language, multi-resolution outputs, accelerating production for training, marketing, and documentation content.
Narakeet
Narakeet is a text-to-speech and video automation platform that turns scripts, slides, and subtitle files into narrated videos and voiceovers at scale. It offers 100 languages and 800 realistic voices, letting teams update narration by simply editing text instead of re-recording audio. Users can convert PowerPoint, Google Slides, or Keynote into full HD videos with captions, or turn SRT/WebVTT subtitles into synchronized dubbing tracks. Markdown scripting and templates streamline creating social clips, tutorials, and product demos. With API and CLI support, Narakeet automates multi-language, multi-resolution outputs, accelerating production for training, marketing, and documentation content.
Narakeet
Narakeet is a text-to-speech and video automation platform that turns scripts, slides, and subtitle files into narrated videos and voiceovers at scale. It offers 100 languages and 800 realistic voices, letting teams update narration by simply editing text instead of re-recording audio. Users can convert PowerPoint, Google Slides, or Keynote into full HD videos with captions, or turn SRT/WebVTT subtitles into synchronized dubbing tracks. Markdown scripting and templates streamline creating social clips, tutorials, and product demos. With API and CLI support, Narakeet automates multi-language, multi-resolution outputs, accelerating production for training, marketing, and documentation content.
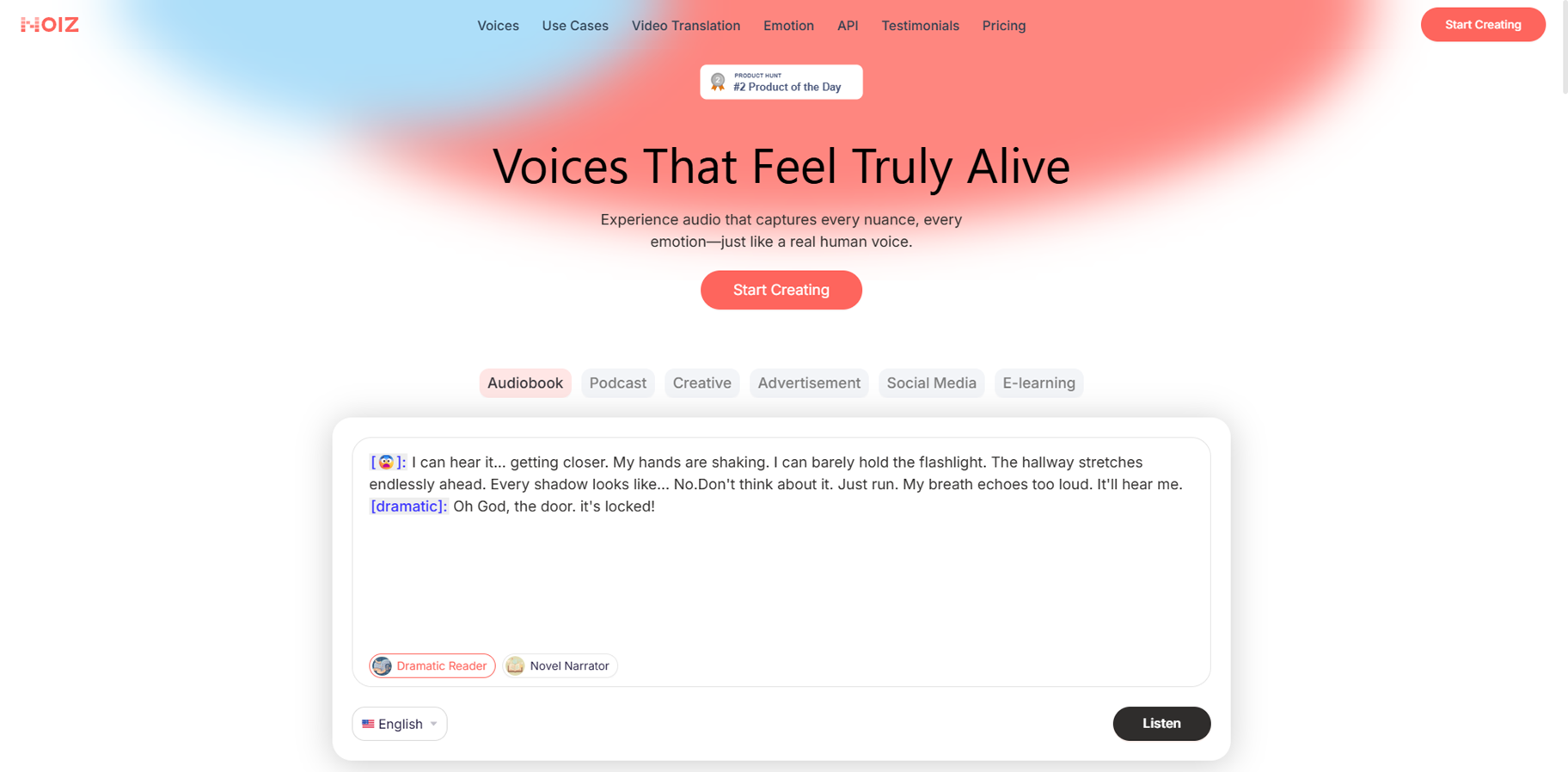

Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
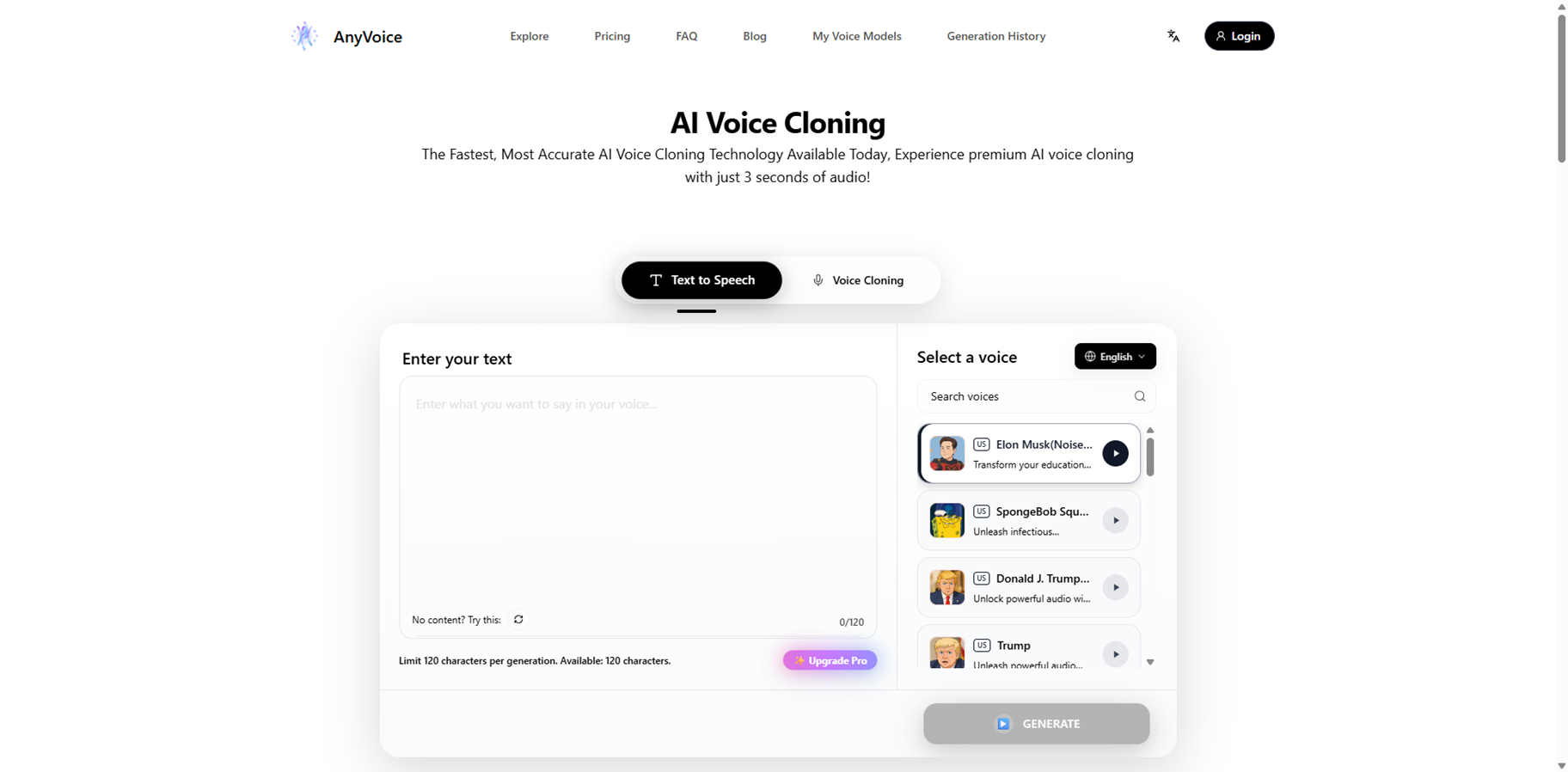

AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai