
- Developers & Engineers: Integrate high-accuracy ASR and speech intelligence capabilities into their applications and platforms using flexible REST APIs and SDKs.
- Media & Entertainment Companies: Auto-generate precise captions, comprehensive transcripts, and concise summaries for vast amounts of audio and video content, improving accessibility and searchability.
- Enterprise & SaaS Providers: Build advanced voice-enabled workflows and applications with high transcription accuracy, ensuring compliance with industry standards and internal policies.
- Research & Analytics Teams: Leverage sophisticated speech metadata, including topic extraction, sentiment analysis, and speaker diarization, to gain deep insights from conversational data.
- Accessibility & Compliance Teams: Generate accurate captions and summaries in multiple languages to meet accessibility standards and ensure content inclusivity for a diverse audience.
How to Use Rev.ai?
Rev.ai offers a developer-friendly approach to integrating speech-to-text and intelligence. Here's a general guide on how to use it:
- Sign Up for an API Key: Begin by creating a free Rev.ai account, which typically provides free credits to test and explore the API's capabilities. Obtain your unique API access token, which is essential for authenticating requests.
- Upload or Stream Audio/Video: Send your audio files (e.g., MP3, WAV, FLAC) or real-time audio streams to Rev.ai via its REST API. You can provide a direct URL to the media file or upload the binary data.
- Receive Results: Once the processing is complete (for asynchronous jobs) or in real-time (for streaming), you will receive a JSON output. This output typically includes the transcribed text, precise timestamps for each word, speaker labels (diarization), punctuation, and any requested speech intelligence insights.
- Process & Store Data: Integrate the received JSON data into your application. Use the transcripts to generate captions for videos,
- Industry-Leading ASR Accuracy: Rev.ai is widely recognized for its exceptionally high ASR accuracy and lowest word-error rates, largely due to its models being trained on a massive and diverse dataset of millions of hours of human-transcribed audio. This means cleaner, more reliable transcripts.
- Comprehensive Speech Intelligence Suite: Beyond basic transcription, it offers a rich suite of advanced speech insights tools, including automated topic extraction, sentiment analysis, intelligent summarization, language translation, forced alignment (aligning transcripts to audio), and robust language identification across multiple languages.
- Real-Time Streaming Support: Provides a low-latency Streaming API that enables instant transcription of live audio, crucial for applications like live captioning, voice bots, and real-time call center analytics, available in multiple languages.
- Secure & Compliant Data Handling: Adheres to stringent security and compliance standards.
- ASR Accuracy & Readability: Delivers transcripts with top-tier WER and excellent readability.
- Rich Speech Intelligence: Adds semantic insights—topics, sentiment, translation—to raw transcripts.
- Streaming Capabilities: Supports real-time workflows and live captioning.
- Strong Compliance & Security: Ideal for healthcare, finance, legal use cases.
- Scalable Pricing Options: From low-cost pay‑as‑you‑go to enterprise plans with volume deals.
- Advanced Features Require Usage: Topic extraction, summarization, and others incur additional per‑use charges.
- Limited Human Transcription Option: The platform focuses solely on machine-generated content.
- Tech Integration Needed: Requires engineering resources to integrate APIs and build pipelines.
Pay as you go
custom
$0.20 / hour
Languages: English
Rounded up to the nearest second, 15 second minimum
Reverb Turbo Transcription
$0.10 / hour
Languages: English
Rounded up to the nearest second, 15 second minimum
Reverb Foreign Language Transcription
$0.30 / hour
Languages: Spanish, French, Chinese, Portuguese, and 53 more.
Rounded up to the nearest second, 15 second minimum
Whisper Fusion Transcription
$0.005 / minute
Languages: English
Rounded up to the nearest second, 15 second minimum
Enterprise
custom
Dedicated account manager
Priority technical support
Additional free credits for evaluation
Highest level of data control and security.
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI Whisper
OpenAI Whisper is a powerful automatic speech recognition (ASR) system designed to transcribe and translate spoken language with high accuracy. It supports multiple languages and can handle a variety of audio formats, making it an essential tool for transcription services, accessibility solutions, and real-time voice applications. Whisper is trained on a vast dataset of multilingual audio, ensuring robustness even in noisy environments.
OpenAI Whisper
OpenAI Whisper is a powerful automatic speech recognition (ASR) system designed to transcribe and translate spoken language with high accuracy. It supports multiple languages and can handle a variety of audio formats, making it an essential tool for transcription services, accessibility solutions, and real-time voice applications. Whisper is trained on a vast dataset of multilingual audio, ensuring robustness even in noisy environments.
OpenAI Whisper
OpenAI Whisper is a powerful automatic speech recognition (ASR) system designed to transcribe and translate spoken language with high accuracy. It supports multiple languages and can handle a variety of audio formats, making it an essential tool for transcription services, accessibility solutions, and real-time voice applications. Whisper is trained on a vast dataset of multilingual audio, ensuring robustness even in noisy environments.
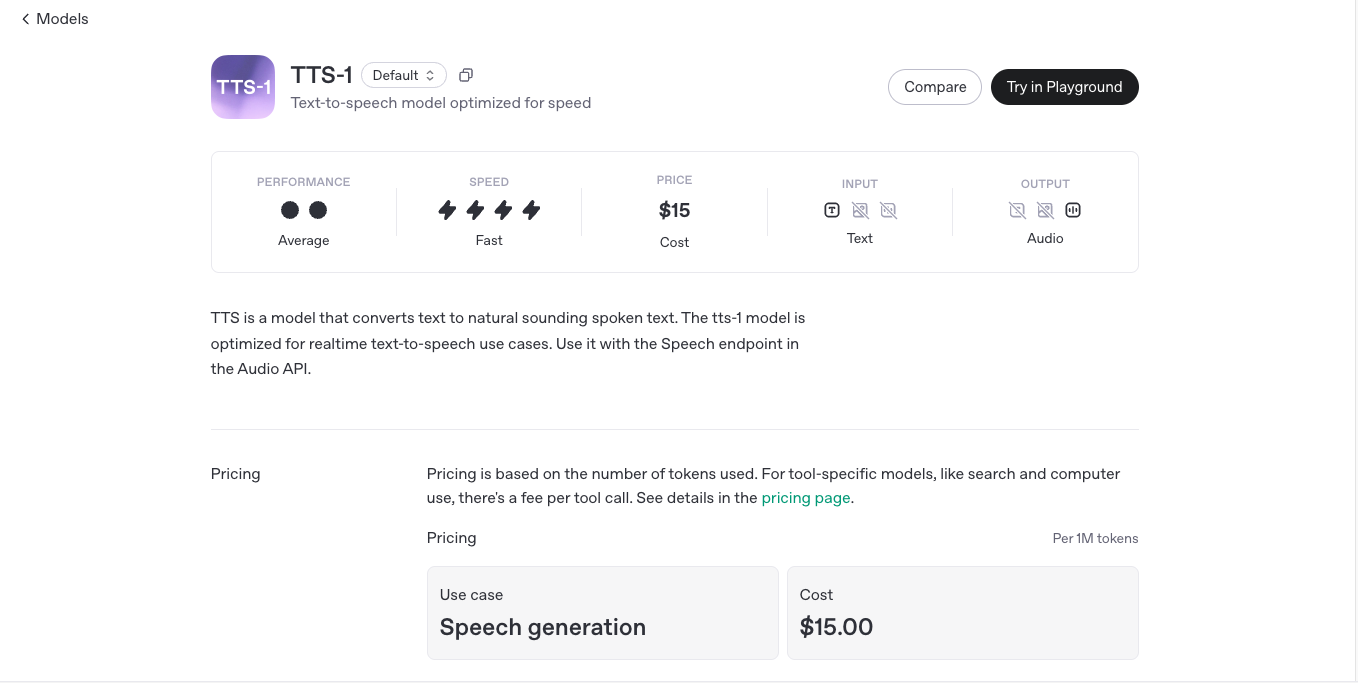
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
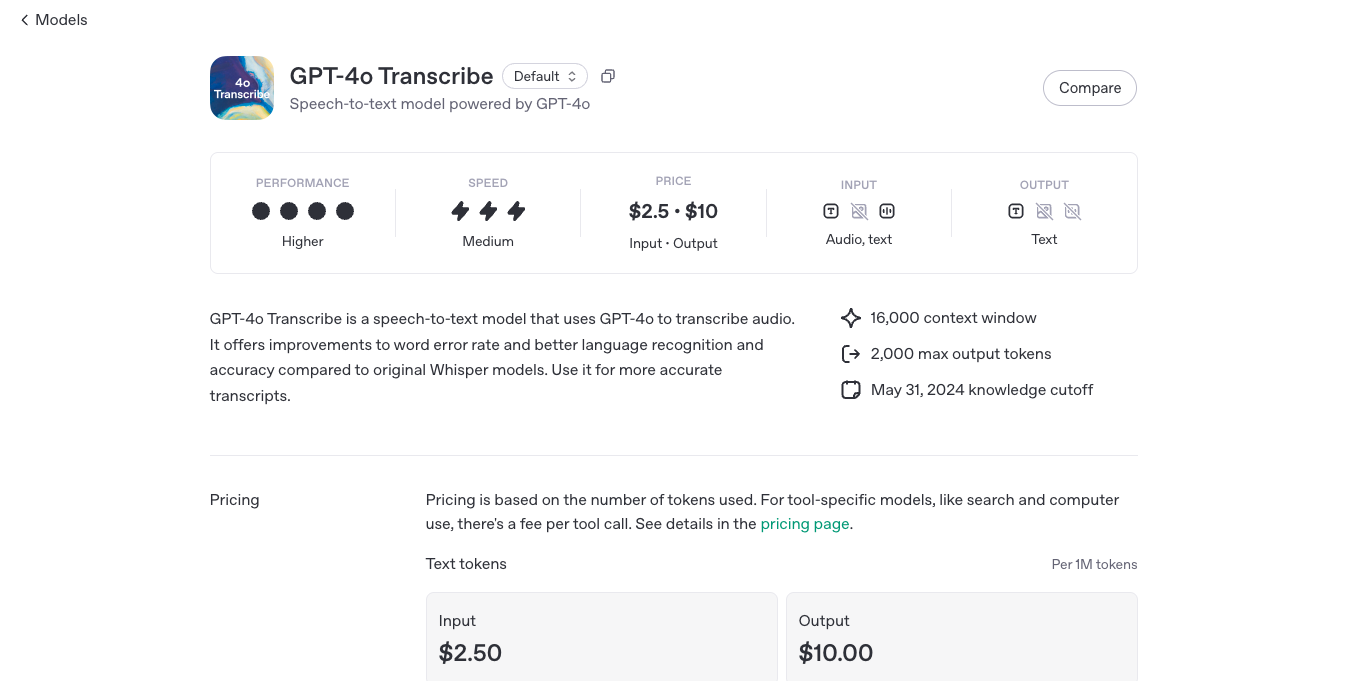
GPT-4o Transcribe is OpenAI’s high-performance speech-to-text model built into the GPT-4o family. It converts spoken audio into accurate, readable, and structured text—quickly and with surprising clarity. Whether you're transcribing interviews, meetings, podcasts, or real-time conversations, GPT-4o Transcribe delivers fast, multilingual transcription powered by the same model that understands and generates across text, vision, and audio. It’s ideal for developers and teams building voice-enabled apps, transcription services, or any tool where spoken language needs to become text—instantly and intelligently.
GPT-4o Transcribe is OpenAI’s high-performance speech-to-text model built into the GPT-4o family. It converts spoken audio into accurate, readable, and structured text—quickly and with surprising clarity. Whether you're transcribing interviews, meetings, podcasts, or real-time conversations, GPT-4o Transcribe delivers fast, multilingual transcription powered by the same model that understands and generates across text, vision, and audio. It’s ideal for developers and teams building voice-enabled apps, transcription services, or any tool where spoken language needs to become text—instantly and intelligently.
GPT-4o Transcribe is OpenAI’s high-performance speech-to-text model built into the GPT-4o family. It converts spoken audio into accurate, readable, and structured text—quickly and with surprising clarity. Whether you're transcribing interviews, meetings, podcasts, or real-time conversations, GPT-4o Transcribe delivers fast, multilingual transcription powered by the same model that understands and generates across text, vision, and audio. It’s ideal for developers and teams building voice-enabled apps, transcription services, or any tool where spoken language needs to become text—instantly and intelligently.

XSAudio
XSAudio is a powerful AI audio platform offering text-to-speech, voice cloning, and sound effect generation. With realistic voice libraries, custom cloning, and multilingual support, it’s perfect for creators, developers, and businesses needing high-quality audio fast. Use it for videos, podcasts, games, and more—with daily free credits and API access.
XSAudio
XSAudio is a powerful AI audio platform offering text-to-speech, voice cloning, and sound effect generation. With realistic voice libraries, custom cloning, and multilingual support, it’s perfect for creators, developers, and businesses needing high-quality audio fast. Use it for videos, podcasts, games, and more—with daily free credits and API access.
XSAudio
XSAudio is a powerful AI audio platform offering text-to-speech, voice cloning, and sound effect generation. With realistic voice libraries, custom cloning, and multilingual support, it’s perfect for creators, developers, and businesses needing high-quality audio fast. Use it for videos, podcasts, games, and more—with daily free credits and API access.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
Transcript LOL
Transcript.LOL is an AI-powered transcription platform that converts audio and video content into accurate, timestamped text. It supports a variety of file types and integrates with platforms like Zoom, Google Meet, and YouTube. The tool offers features such as speaker identification, summaries, topic extraction, and interactive Q&A, making it suitable for content creators, educators, journalists, and professionals seeking efficient transcription solutions.
Transcript LOL
Transcript.LOL is an AI-powered transcription platform that converts audio and video content into accurate, timestamped text. It supports a variety of file types and integrates with platforms like Zoom, Google Meet, and YouTube. The tool offers features such as speaker identification, summaries, topic extraction, and interactive Q&A, making it suitable for content creators, educators, journalists, and professionals seeking efficient transcription solutions.
Transcript LOL
Transcript.LOL is an AI-powered transcription platform that converts audio and video content into accurate, timestamped text. It supports a variety of file types and integrates with platforms like Zoom, Google Meet, and YouTube. The tool offers features such as speaker identification, summaries, topic extraction, and interactive Q&A, making it suitable for content creators, educators, journalists, and professionals seeking efficient transcription solutions.

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.

Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Voicemaker
Voicemaker is an AI-based online text-to-speech platform that turns written text into natural-sounding voiceovers across a wide range of languages and use cases. It offers ultra-fast, low-latency speech suitable for real-time applications, studio-like voices for production-quality narration, and a prompt-based dynamic model for highly expressive storytelling. Creators can fine-tune voice parameters such as volume, speed, pitch, stability, and similarity to match brand or project needs. Generated audio files can be redistributed globally, even after a subscription ends, enabling flexible usage across platforms. With simple controls and scalable voice options, Voicemaker streamlines voiceover creation for content, podcasts, videos, and more.
Voicemaker
Voicemaker is an AI-based online text-to-speech platform that turns written text into natural-sounding voiceovers across a wide range of languages and use cases. It offers ultra-fast, low-latency speech suitable for real-time applications, studio-like voices for production-quality narration, and a prompt-based dynamic model for highly expressive storytelling. Creators can fine-tune voice parameters such as volume, speed, pitch, stability, and similarity to match brand or project needs. Generated audio files can be redistributed globally, even after a subscription ends, enabling flexible usage across platforms. With simple controls and scalable voice options, Voicemaker streamlines voiceover creation for content, podcasts, videos, and more.
Voicemaker
Voicemaker is an AI-based online text-to-speech platform that turns written text into natural-sounding voiceovers across a wide range of languages and use cases. It offers ultra-fast, low-latency speech suitable for real-time applications, studio-like voices for production-quality narration, and a prompt-based dynamic model for highly expressive storytelling. Creators can fine-tune voice parameters such as volume, speed, pitch, stability, and similarity to match brand or project needs. Generated audio files can be redistributed globally, even after a subscription ends, enabling flexible usage across platforms. With simple controls and scalable voice options, Voicemaker streamlines voiceover creation for content, podcasts, videos, and more.

Awaz AI
Awaz AI is a voice-enabled conversational AI engine that enables businesses to build human-like voice agents for both outbound and inbound calls, achieving tasks such as booking meetings, qualifying leads, conducting interviews, sending follow-ups via SMS/WhatsApp and automating voice campaigns. It supports multilingual voice agents (30+ languages) and offers no-code tools for business users to configure agents, campaigns, and workflows. The platform aims to significantly boost productivity and scale by automating voice communications at volume, and includes integrations for CRM, calendar invites and workflow automation.
Awaz AI
Awaz AI is a voice-enabled conversational AI engine that enables businesses to build human-like voice agents for both outbound and inbound calls, achieving tasks such as booking meetings, qualifying leads, conducting interviews, sending follow-ups via SMS/WhatsApp and automating voice campaigns. It supports multilingual voice agents (30+ languages) and offers no-code tools for business users to configure agents, campaigns, and workflows. The platform aims to significantly boost productivity and scale by automating voice communications at volume, and includes integrations for CRM, calendar invites and workflow automation.
Awaz AI
Awaz AI is a voice-enabled conversational AI engine that enables businesses to build human-like voice agents for both outbound and inbound calls, achieving tasks such as booking meetings, qualifying leads, conducting interviews, sending follow-ups via SMS/WhatsApp and automating voice campaigns. It supports multilingual voice agents (30+ languages) and offers no-code tools for business users to configure agents, campaigns, and workflows. The platform aims to significantly boost productivity and scale by automating voice communications at volume, and includes integrations for CRM, calendar invites and workflow automation.

Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.

DeVoice
Devoice is an AI-powered audio tool that lets users convert audio and video files into accurate, editable text transcripts instantly using advanced speech recognition technology. It also includes useful audio enhancement features like background noise removal and AI-generated voice tools to help creators and professionals work with sound more efficiently.
DeVoice
Devoice is an AI-powered audio tool that lets users convert audio and video files into accurate, editable text transcripts instantly using advanced speech recognition technology. It also includes useful audio enhancement features like background noise removal and AI-generated voice tools to help creators and professionals work with sound more efficiently.
DeVoice
Devoice is an AI-powered audio tool that lets users convert audio and video files into accurate, editable text transcripts instantly using advanced speech recognition technology. It also includes useful audio enhancement features like background noise removal and AI-generated voice tools to help creators and professionals work with sound more efficiently.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai