
✅ Content Creators & Podcasters – Easily transcribe audio and video content.
✅ Journalists & Researchers – Convert interviews and recorded conversations into text.
✅ Business Professionals – Automate meeting notes and voice-to-text documentation.
✅ Developers & AI Enthusiasts – Integrate speech-to-text capabilities into applications.
✅ Accessibility Advocates – Improve accessibility with AI-driven subtitles and captions.
How to Use OpenAI Whisper?
1️⃣ Access the Whisper Model – OpenAI provides Whisper as an open-source model, which can be accessed via GitHub or OpenAI’s API.
2️⃣ Choose Your Setup – You can either run Whisper locally on your computer or use OpenAI’s API for cloud-based transcription.
3️⃣ Install Dependencies – If running it locally, install Whisper using:
- bash
- Copy
- Edit
- pip install whisper
- bash
- Copy
- Edit
- whisper audio.mp3 --model large
- bash
- Copy
- Edit
- whisper audio.mp3 --model large --task translate
7️⃣ Integrate into Applications – Developers can embed Whisper into their apps using OpenAI’s API for real-time transcription, subtitles, and more.
🌍 Multilingual Support – Transcribes and translates across multiple languages.
⚡ Fast & Efficient Processing – Works on various hardware configurations for quick results.
🔊 Handles Noisy Audio Well – Maintains clarity even in challenging acoustic conditions.
🔄 Open-Source Availability – Developers can use and customize Whisper freely.
- Highly Accurate Transcription – Even with accents and low-quality audio.
- Supports Many Languages – Useful for global users and multilingual projects.
- Free & Open-Source – Available for developers to integrate into applications.
- Great for Accessibility – Enhances subtitles and real-time captions.
- Computationally Intensive – Requires strong hardware for real-time processing.
- No Live Streaming Support – Primarily designed for pre-recorded audio, not live conversations.
- Large Model Size – Can be resource-heavy for smaller devices.
Open Source
$ 0.00
Requirements: You need a computer with enough processing power (preferably with a GPU for best performance), and you must install Whisper and its dependencies.
OpenAI API
$ 0.006 per minute of audio transcribed
API
$ 0.006/min audio
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
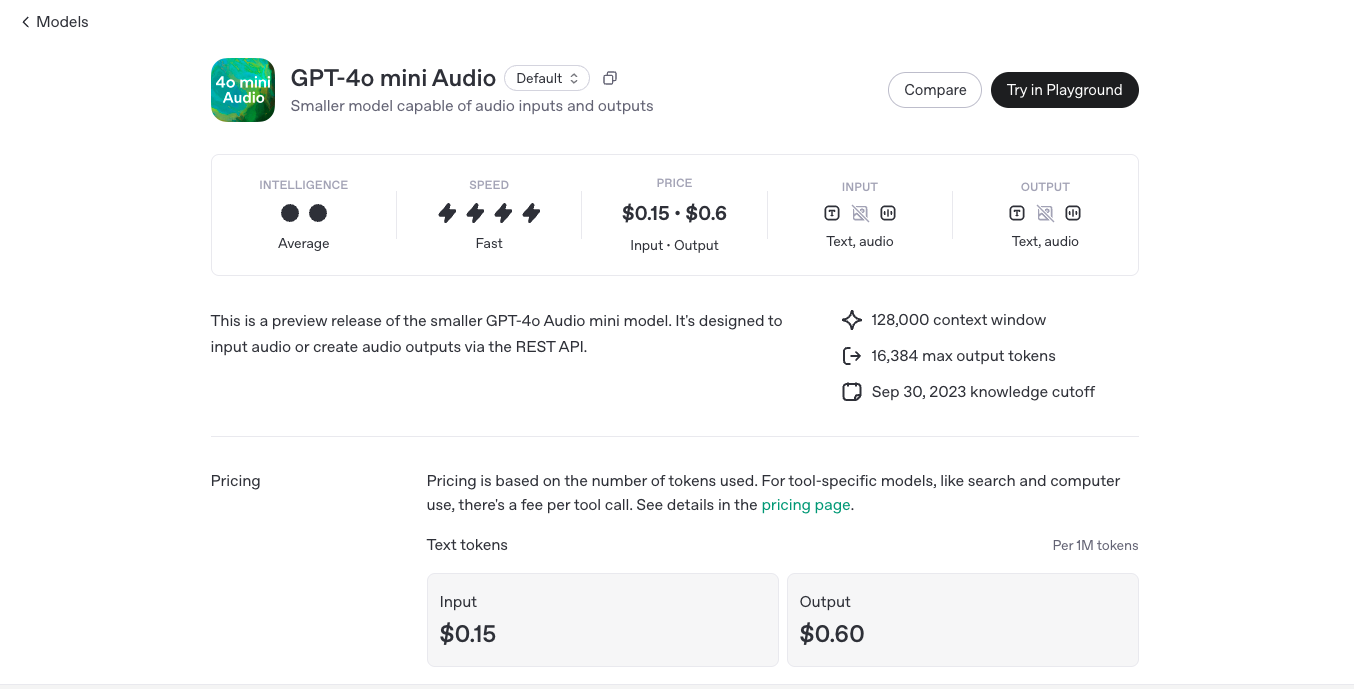
OpenAI GPT-4o Mini Audio is a lighter, faster, and cost-effective version of OpenAI's real-time voice AI, designed for natural and expressive AI conversations. It provides instant voice interactions with low latency, making it ideal for applications like AI assistants, customer service, and real-time translation without the high computational costs of full-scale GPT-4o Audio.
OpenAI GPT-4o Mini Audio is a lighter, faster, and cost-effective version of OpenAI's real-time voice AI, designed for natural and expressive AI conversations. It provides instant voice interactions with low latency, making it ideal for applications like AI assistants, customer service, and real-time translation without the high computational costs of full-scale GPT-4o Audio.
OpenAI GPT-4o Mini Audio is a lighter, faster, and cost-effective version of OpenAI's real-time voice AI, designed for natural and expressive AI conversations. It provides instant voice interactions with low latency, making it ideal for applications like AI assistants, customer service, and real-time translation without the high computational costs of full-scale GPT-4o Audio.

GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.

GPT-4o-mini-transcribe is a lightweight, high-speed speech-to-text model from OpenAI, built on the GPT-4o-mini architecture. It converts spoken language into text with exceptional speed and surprising accuracy for its size—making it ideal for real-time transcription in resource-constrained environments. Whether you're building voice-enabled apps, smart assistants, meeting transcription tools, or captioning systems, GPT-4o-mini-transcribe offers responsive, multilingual transcription that balances cost, performance, and ease of integration.
GPT-4o-mini-transcribe is a lightweight, high-speed speech-to-text model from OpenAI, built on the GPT-4o-mini architecture. It converts spoken language into text with exceptional speed and surprising accuracy for its size—making it ideal for real-time transcription in resource-constrained environments. Whether you're building voice-enabled apps, smart assistants, meeting transcription tools, or captioning systems, GPT-4o-mini-transcribe offers responsive, multilingual transcription that balances cost, performance, and ease of integration.
GPT-4o-mini-transcribe is a lightweight, high-speed speech-to-text model from OpenAI, built on the GPT-4o-mini architecture. It converts spoken language into text with exceptional speed and surprising accuracy for its size—making it ideal for real-time transcription in resource-constrained environments. Whether you're building voice-enabled apps, smart assistants, meeting transcription tools, or captioning systems, GPT-4o-mini-transcribe offers responsive, multilingual transcription that balances cost, performance, and ease of integration.

Rev AI
Rev.ai is an AI-powered speech-to-text API platform that provides developers and enterprises with highly accurate transcription and advanced speech intelligence tools. Leveraging cutting-edge ASR models, Rev.ai enables seamless audio and video transcription, real-time streaming, language detection, sentiment analysis, topic extraction, summarization, translation, and more.
Rev AI
Rev.ai is an AI-powered speech-to-text API platform that provides developers and enterprises with highly accurate transcription and advanced speech intelligence tools. Leveraging cutting-edge ASR models, Rev.ai enables seamless audio and video transcription, real-time streaming, language detection, sentiment analysis, topic extraction, summarization, translation, and more.
Rev AI
Rev.ai is an AI-powered speech-to-text API platform that provides developers and enterprises with highly accurate transcription and advanced speech intelligence tools. Leveraging cutting-edge ASR models, Rev.ai enables seamless audio and video transcription, real-time streaming, language detection, sentiment analysis, topic extraction, summarization, translation, and more.

Transmonkey
TransMonkey AI is a comprehensive, web-based AI translation suite that handles documents, images, audio/video, and plain text. Powered by large language models like ChatGPT, Gemini, Claude, and OpenAI’s Whisper, it offers format-preserving translations, speech-to-text transcription, subtitle generation, and realistic dubbing in over 130 languages. Ideal for multilingual content workflows—be it translating PDFs, dubbing videos, transcribing podcasts, or converting images with embedded text—TransMonkey consolidates powerful features into a single, user-friendly interface
Transmonkey
TransMonkey AI is a comprehensive, web-based AI translation suite that handles documents, images, audio/video, and plain text. Powered by large language models like ChatGPT, Gemini, Claude, and OpenAI’s Whisper, it offers format-preserving translations, speech-to-text transcription, subtitle generation, and realistic dubbing in over 130 languages. Ideal for multilingual content workflows—be it translating PDFs, dubbing videos, transcribing podcasts, or converting images with embedded text—TransMonkey consolidates powerful features into a single, user-friendly interface
Transmonkey
TransMonkey AI is a comprehensive, web-based AI translation suite that handles documents, images, audio/video, and plain text. Powered by large language models like ChatGPT, Gemini, Claude, and OpenAI’s Whisper, it offers format-preserving translations, speech-to-text transcription, subtitle generation, and realistic dubbing in over 130 languages. Ideal for multilingual content workflows—be it translating PDFs, dubbing videos, transcribing podcasts, or converting images with embedded text—TransMonkey consolidates powerful features into a single, user-friendly interface


VoicePen App
Voice Pen: Speech to Text AI is a powerful mobile application that transforms spoken words into text with remarkable accuracy. Leveraging advanced AI technology, it offers a seamless and efficient way to create documents, notes, emails, and more, simply by speaking. Designed for ease of use, Voice Pen caters to individuals seeking a faster and more convenient method of text creation.
VoicePen App
Voice Pen: Speech to Text AI is a powerful mobile application that transforms spoken words into text with remarkable accuracy. Leveraging advanced AI technology, it offers a seamless and efficient way to create documents, notes, emails, and more, simply by speaking. Designed for ease of use, Voice Pen caters to individuals seeking a faster and more convenient method of text creation.
VoicePen App
Voice Pen: Speech to Text AI is a powerful mobile application that transforms spoken words into text with remarkable accuracy. Leveraging advanced AI technology, it offers a seamless and efficient way to create documents, notes, emails, and more, simply by speaking. Designed for ease of use, Voice Pen caters to individuals seeking a faster and more convenient method of text creation.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.

VideoToWords AI
VideoToWords.ai is an AI-powered transcription service that quickly and accurately converts video and audio files into text. It offers various features including timestamping, speaker identification, and multiple language support, making it a versatile tool for content creators, researchers, and businesses.
VideoToWords AI
VideoToWords.ai is an AI-powered transcription service that quickly and accurately converts video and audio files into text. It offers various features including timestamping, speaker identification, and multiple language support, making it a versatile tool for content creators, researchers, and businesses.
VideoToWords AI
VideoToWords.ai is an AI-powered transcription service that quickly and accurately converts video and audio files into text. It offers various features including timestamping, speaker identification, and multiple language support, making it a versatile tool for content creators, researchers, and businesses.
Transcript LOL
Transcript.LOL is an AI-powered transcription platform that converts audio and video content into accurate, timestamped text. It supports a variety of file types and integrates with platforms like Zoom, Google Meet, and YouTube. The tool offers features such as speaker identification, summaries, topic extraction, and interactive Q&A, making it suitable for content creators, educators, journalists, and professionals seeking efficient transcription solutions.
Transcript LOL
Transcript.LOL is an AI-powered transcription platform that converts audio and video content into accurate, timestamped text. It supports a variety of file types and integrates with platforms like Zoom, Google Meet, and YouTube. The tool offers features such as speaker identification, summaries, topic extraction, and interactive Q&A, making it suitable for content creators, educators, journalists, and professionals seeking efficient transcription solutions.
Transcript LOL
Transcript.LOL is an AI-powered transcription platform that converts audio and video content into accurate, timestamped text. It supports a variety of file types and integrates with platforms like Zoom, Google Meet, and YouTube. The tool offers features such as speaker identification, summaries, topic extraction, and interactive Q&A, making it suitable for content creators, educators, journalists, and professionals seeking efficient transcription solutions.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
Voicemaker
Voicemaker is an AI-based online text-to-speech platform that turns written text into natural-sounding voiceovers across a wide range of languages and use cases. It offers ultra-fast, low-latency speech suitable for real-time applications, studio-like voices for production-quality narration, and a prompt-based dynamic model for highly expressive storytelling. Creators can fine-tune voice parameters such as volume, speed, pitch, stability, and similarity to match brand or project needs. Generated audio files can be redistributed globally, even after a subscription ends, enabling flexible usage across platforms. With simple controls and scalable voice options, Voicemaker streamlines voiceover creation for content, podcasts, videos, and more.
Voicemaker
Voicemaker is an AI-based online text-to-speech platform that turns written text into natural-sounding voiceovers across a wide range of languages and use cases. It offers ultra-fast, low-latency speech suitable for real-time applications, studio-like voices for production-quality narration, and a prompt-based dynamic model for highly expressive storytelling. Creators can fine-tune voice parameters such as volume, speed, pitch, stability, and similarity to match brand or project needs. Generated audio files can be redistributed globally, even after a subscription ends, enabling flexible usage across platforms. With simple controls and scalable voice options, Voicemaker streamlines voiceover creation for content, podcasts, videos, and more.
Voicemaker
Voicemaker is an AI-based online text-to-speech platform that turns written text into natural-sounding voiceovers across a wide range of languages and use cases. It offers ultra-fast, low-latency speech suitable for real-time applications, studio-like voices for production-quality narration, and a prompt-based dynamic model for highly expressive storytelling. Creators can fine-tune voice parameters such as volume, speed, pitch, stability, and similarity to match brand or project needs. Generated audio files can be redistributed globally, even after a subscription ends, enabling flexible usage across platforms. With simple controls and scalable voice options, Voicemaker streamlines voiceover creation for content, podcasts, videos, and more.
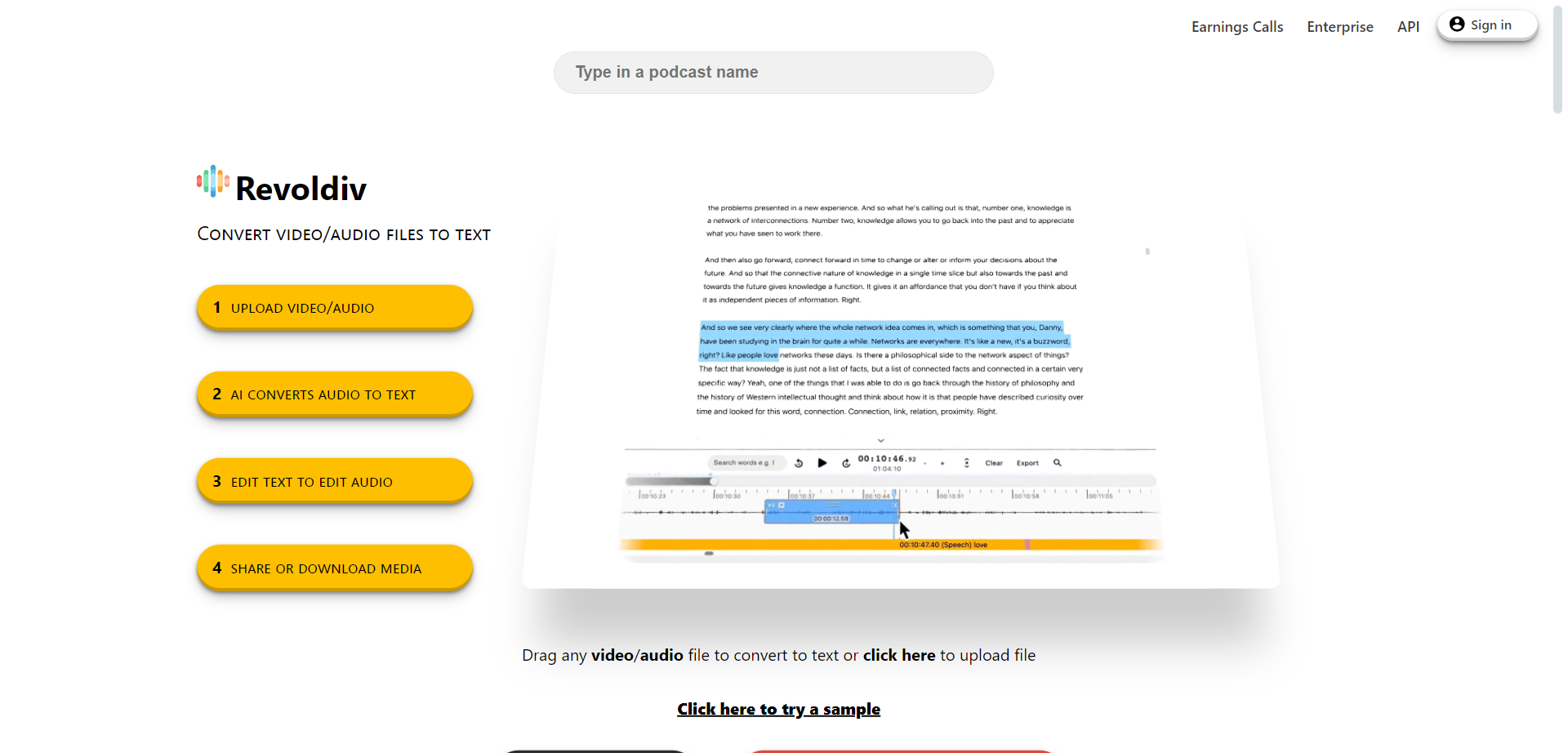

Revoldiv
Revoldiv is an AI-powered transcription platform that converts audio and video files into accurate, editable text transcripts directly through your web browser. Built as a Chrome and Firefox extension, it leverages OpenAI's Whisper technology to deliver impressive accuracy in speech recognition, including differentiating between speakers and understanding various accents. Beyond simple transcription, Revoldiv functions as a creative workspace where users can edit text and corresponding audio simultaneously, remove filler words with one click, create chapters for easier navigation, and generate audiograms for social media. It supports media files up to two hours long and offers real-time synchronization between audio playback and text, making it ideal for podcasters, content creators, and professionals.
Revoldiv
Revoldiv is an AI-powered transcription platform that converts audio and video files into accurate, editable text transcripts directly through your web browser. Built as a Chrome and Firefox extension, it leverages OpenAI's Whisper technology to deliver impressive accuracy in speech recognition, including differentiating between speakers and understanding various accents. Beyond simple transcription, Revoldiv functions as a creative workspace where users can edit text and corresponding audio simultaneously, remove filler words with one click, create chapters for easier navigation, and generate audiograms for social media. It supports media files up to two hours long and offers real-time synchronization between audio playback and text, making it ideal for podcasters, content creators, and professionals.
Revoldiv
Revoldiv is an AI-powered transcription platform that converts audio and video files into accurate, editable text transcripts directly through your web browser. Built as a Chrome and Firefox extension, it leverages OpenAI's Whisper technology to deliver impressive accuracy in speech recognition, including differentiating between speakers and understanding various accents. Beyond simple transcription, Revoldiv functions as a creative workspace where users can edit text and corresponding audio simultaneously, remove filler words with one click, create chapters for easier navigation, and generate audiograms for social media. It supports media files up to two hours long and offers real-time synchronization between audio playback and text, making it ideal for podcasters, content creators, and professionals.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai