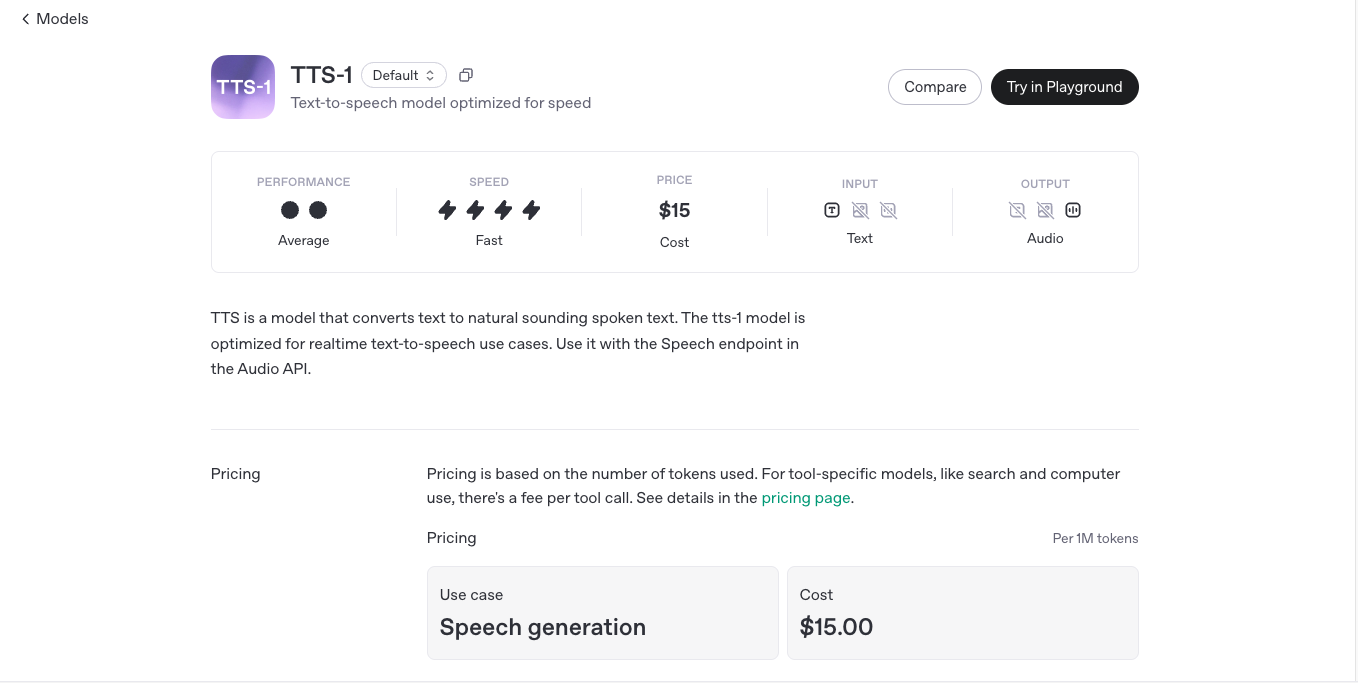
Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
- App Developers & Startups: Add lifelike voice to apps, from productivity tools to storytelling platforms.
- Conversational AI Creators: Build AI agents that speak fluently and naturally in real time.
- Voiceover & Media Teams: Generate narration, training content, or voiceovers without hiring voice actors.
- Accessibility Tool Builders: Support visually impaired users by reading content aloud with natural prosody.
- Game & Virtual World Designers: Give characters dynamic, believable voice lines at runtime.
- Educators & eLearning Platforms: Deliver engaging, spoken content for tutorials, lessons, and explainers.
🤖 How Does It Work?
- Step 1: Choose the API Endpoint: Use the /v1/audio/speech endpoint on OpenAI’s API platform.
- Step 2: Input Text & Select a Voice: Provide your input text and select from a set of high-quality voices like nova, shimmer, and more.
- Step 3: Get the Audio Output: The API returns high-quality audio in real time or as a downloadable file.
- Step 4: Integrate into Your App: Plug the audio into chat apps, e-learning platforms, storytelling tools, or wherever your users need voice.
Bonus: Streaming Option (TTS-1-HD): For ultra-low latency scenarios, the TTS-1-HD model supports streaming voice responses token-by-token.
- Human-Like Quality: TTS-1’s intonation, stress, and rhythm feel surprisingly real—perfect for dialogue and narration.
- Multiple High-Fidelity Voices: Choose from multiple distinct voice options that sound like different real people.
- Fast & Efficient: Latency is low, especially with TTS-1-HD for streaming. You can get usable speech almost instantly.
- Great for Conversational AI: It’s tightly integrated with GPT-4o, meaning your voice agent can think and talk smoothly.
- Emotionally Expressive: Subtle emotional shifts are captured for more compelling delivery.
- API-Based Delivery: No hardware or special software needed—just plug and play via API.
- Incredibly Realistic Voices: No robotic monotone—just smooth, human-sounding speech.
- Low Latency & Fast Output: Especially with streaming, responses are nearly instantaneous.
- Easy API Integration: Just a few lines of code to bring your app to life with voice.
- Voice Variety: Multiple high-quality options help match tone to use case.
- Plays Well with GPT-4o: Combine text and speech for seamless voice assistants.
- Limited Voice Customization: You can't yet fine-tune pitch, speed, or emotional tone beyond defaults.
- No Custom Voice Cloning: Currently, you're limited to OpenAI’s pre-set voice library.
- Language Support is Early-Stage: Multilingual capabilities are developing but not yet as strong as English.
- Pricing May Add Up at Scale: Frequent or long-form speech generation could be costly without optimization.
1 million tokens
$ 15.00
Output: Audio only
Endpoints: Speech generation (v1/audio/speech), plus support in Chat Completions, Responses, Realtime, Assistants, and Batch.
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

Speechify
Speechify.com is a leading AI-powered text-to-speech (TTS) reader designed to transform any written text into natural-sounding audio. With millions of users and high ratings, it aims to help individuals consume content faster and more efficiently across various devices and platforms. Beyond basic text-to-speech, Speechify also offers advanced AI features for content creators, including AI voice generation, voice cloning, and dubbing.
Speechify
Speechify.com is a leading AI-powered text-to-speech (TTS) reader designed to transform any written text into natural-sounding audio. With millions of users and high ratings, it aims to help individuals consume content faster and more efficiently across various devices and platforms. Beyond basic text-to-speech, Speechify also offers advanced AI features for content creators, including AI voice generation, voice cloning, and dubbing.
Speechify
Speechify.com is a leading AI-powered text-to-speech (TTS) reader designed to transform any written text into natural-sounding audio. With millions of users and high ratings, it aims to help individuals consume content faster and more efficiently across various devices and platforms. Beyond basic text-to-speech, Speechify also offers advanced AI features for content creators, including AI voice generation, voice cloning, and dubbing.
I ♡ Transcriptions is an AI-powered service that converts audio and video files into accurate text transcripts. Using OpenAI's Whisper transcription model, combined with their own optimizations, the platform provides a simple, accessible, and affordable solution for anyone needing to transcribe spoken content.
I ♡ Transcriptions is an AI-powered service that converts audio and video files into accurate text transcripts. Using OpenAI's Whisper transcription model, combined with their own optimizations, the platform provides a simple, accessible, and affordable solution for anyone needing to transcribe spoken content.
I ♡ Transcriptions is an AI-powered service that converts audio and video files into accurate text transcripts. Using OpenAI's Whisper transcription model, combined with their own optimizations, the platform provides a simple, accessible, and affordable solution for anyone needing to transcribe spoken content.

Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.


VoiSpark
VoiSpark is an advanced AI-driven voice generation platform designed to transform text into natural, expressive speech and to create unique vocal identities using industry-leading AI models like ElevenLabs, Cartesia, and OpenAI. The platform offers tools for text-to-speech conversion, voice generation with emotion and pitch control, voice changing to mimic celebrities or cartoons, and voice cloning with just one minute of audio. VoiSpark supports over 500 human-like voices across 30+ languages, making it ideal for content creators, marketers, and businesses seeking studio-quality voice solutions.
VoiSpark
VoiSpark is an advanced AI-driven voice generation platform designed to transform text into natural, expressive speech and to create unique vocal identities using industry-leading AI models like ElevenLabs, Cartesia, and OpenAI. The platform offers tools for text-to-speech conversion, voice generation with emotion and pitch control, voice changing to mimic celebrities or cartoons, and voice cloning with just one minute of audio. VoiSpark supports over 500 human-like voices across 30+ languages, making it ideal for content creators, marketers, and businesses seeking studio-quality voice solutions.
VoiSpark
VoiSpark is an advanced AI-driven voice generation platform designed to transform text into natural, expressive speech and to create unique vocal identities using industry-leading AI models like ElevenLabs, Cartesia, and OpenAI. The platform offers tools for text-to-speech conversion, voice generation with emotion and pitch control, voice changing to mimic celebrities or cartoons, and voice cloning with just one minute of audio. VoiSpark supports over 500 human-like voices across 30+ languages, making it ideal for content creators, marketers, and businesses seeking studio-quality voice solutions.
Whisprai.ai is an AI-powered transcription and summarization tool designed to help businesses and individuals quickly and accurately transcribe audio and video files, and generate concise summaries of their content. It offers features for improving workflow efficiency and enhancing productivity through AI-driven automation.
Whisprai.ai is an AI-powered transcription and summarization tool designed to help businesses and individuals quickly and accurately transcribe audio and video files, and generate concise summaries of their content. It offers features for improving workflow efficiency and enhancing productivity through AI-driven automation.
Whisprai.ai is an AI-powered transcription and summarization tool designed to help businesses and individuals quickly and accurately transcribe audio and video files, and generate concise summaries of their content. It offers features for improving workflow efficiency and enhancing productivity through AI-driven automation.
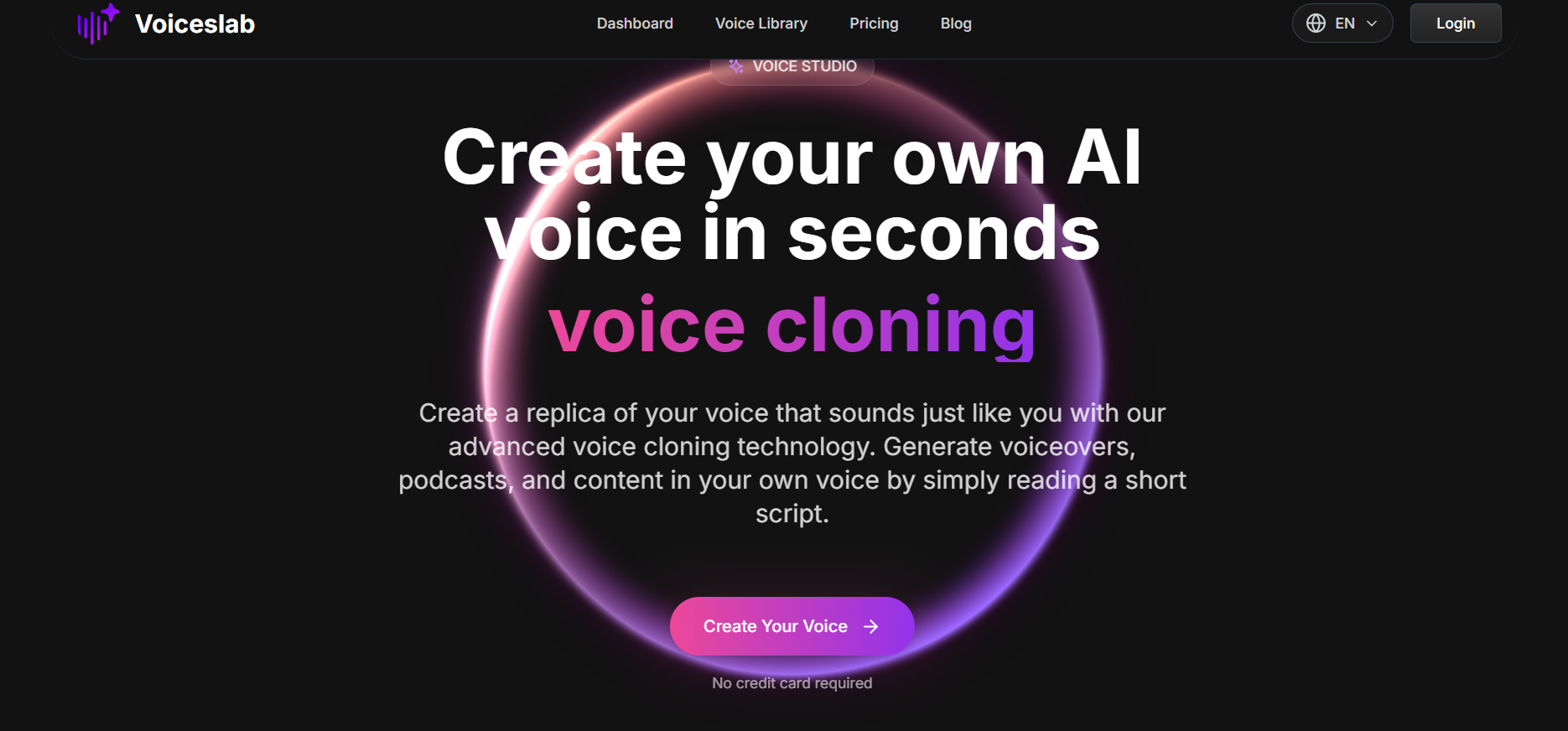
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
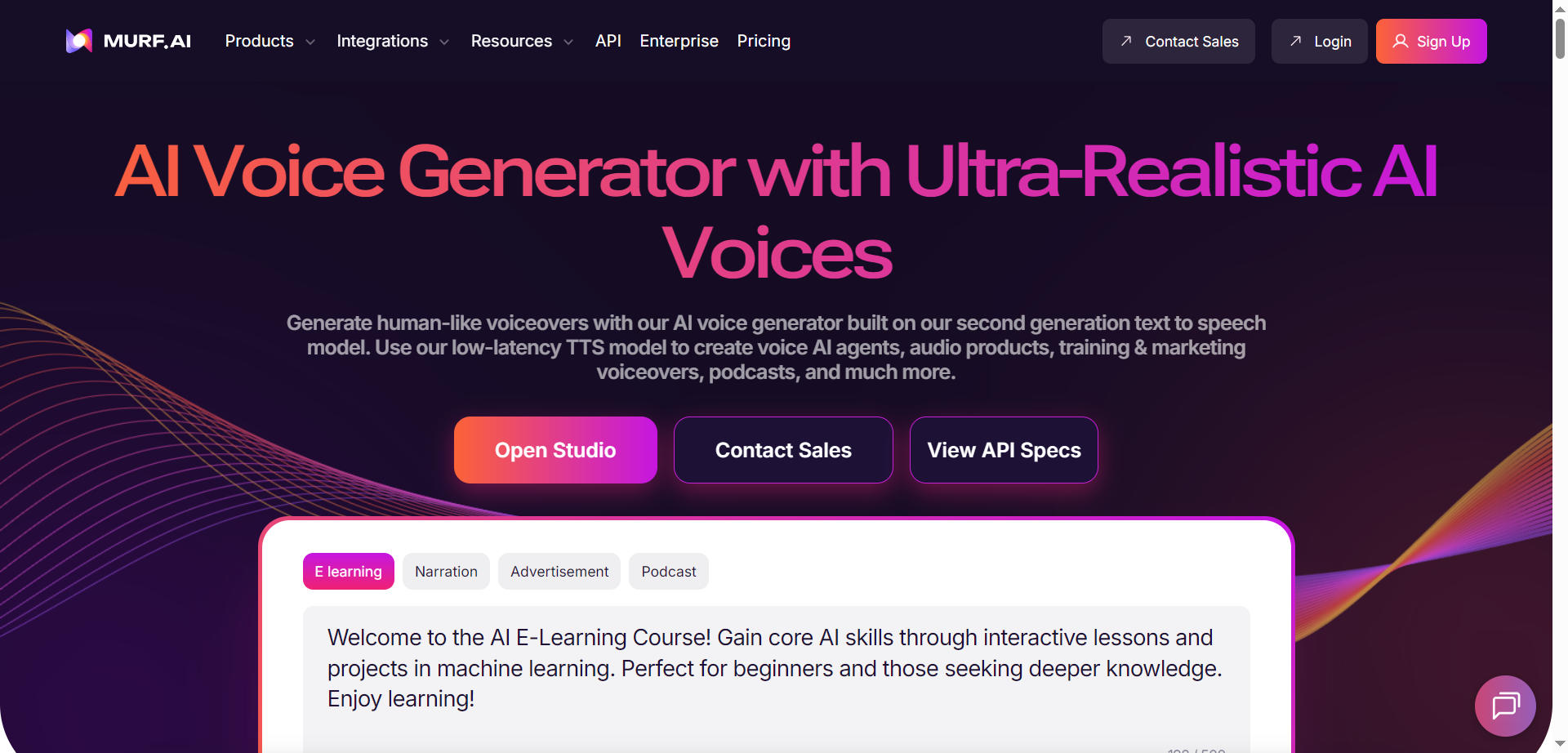

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
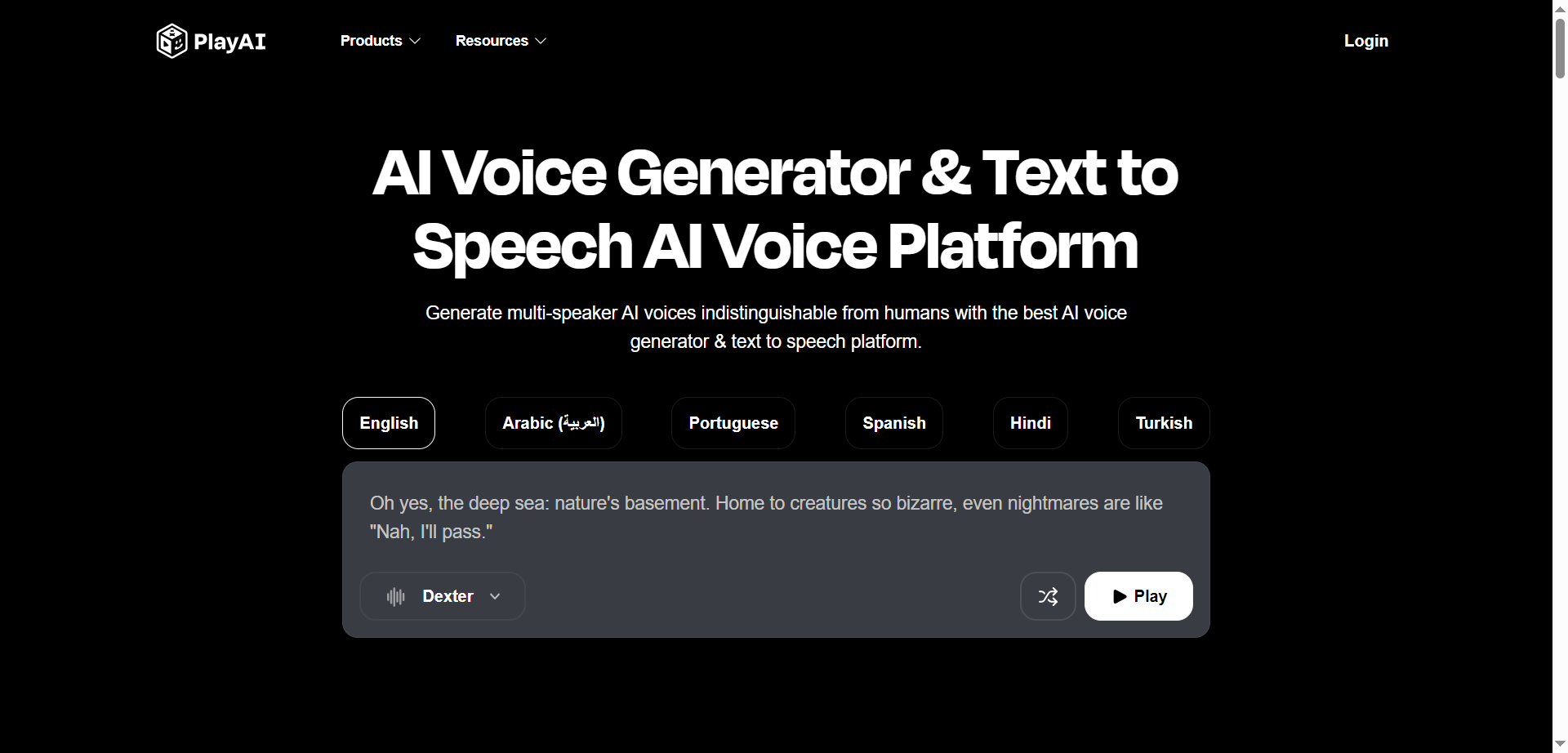
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.

Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
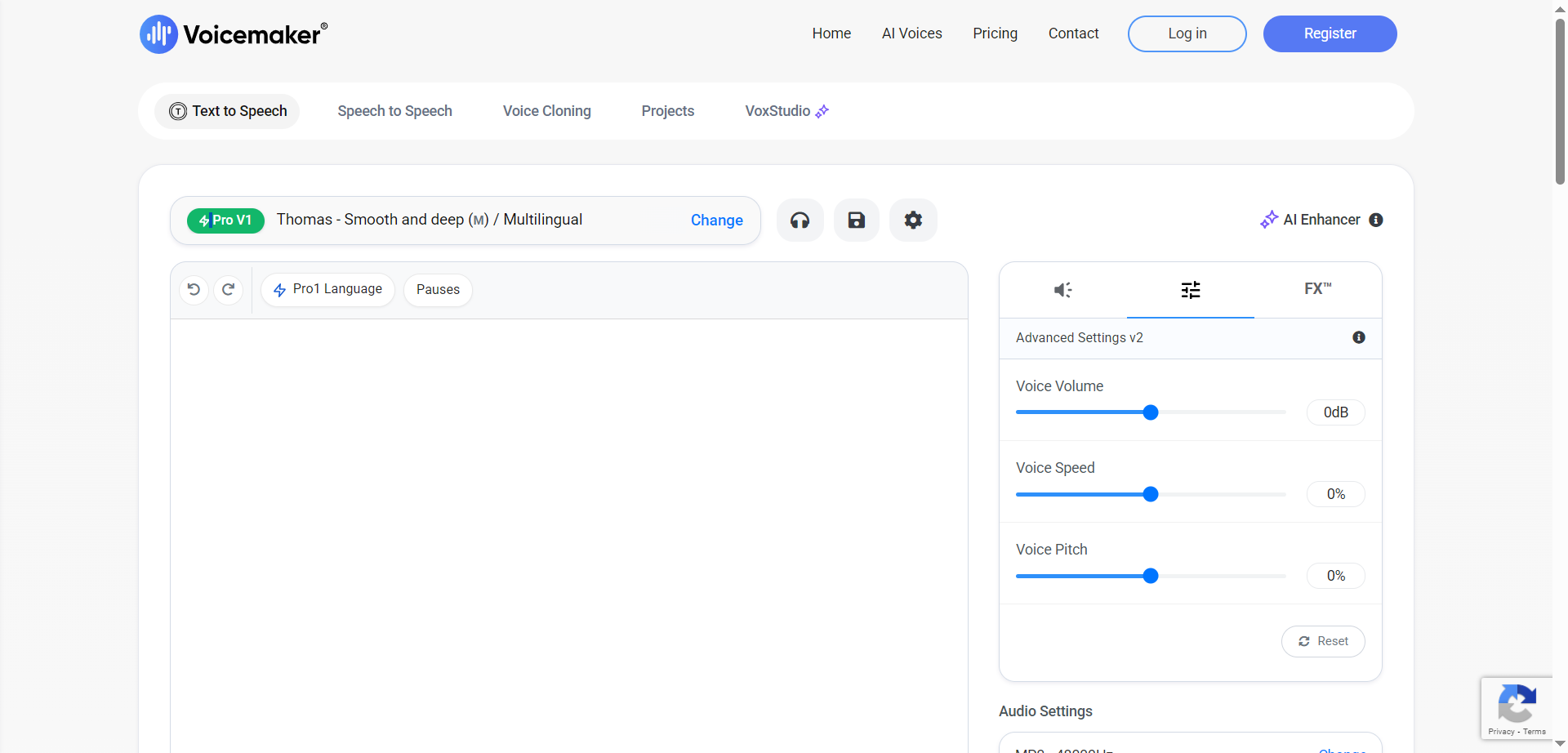
Voicemaker
Voicemaker is an AI-based online text-to-speech platform that turns written text into natural-sounding voiceovers across a wide range of languages and use cases. It offers ultra-fast, low-latency speech suitable for real-time applications, studio-like voices for production-quality narration, and a prompt-based dynamic model for highly expressive storytelling. Creators can fine-tune voice parameters such as volume, speed, pitch, stability, and similarity to match brand or project needs. Generated audio files can be redistributed globally, even after a subscription ends, enabling flexible usage across platforms. With simple controls and scalable voice options, Voicemaker streamlines voiceover creation for content, podcasts, videos, and more.
Voicemaker
Voicemaker is an AI-based online text-to-speech platform that turns written text into natural-sounding voiceovers across a wide range of languages and use cases. It offers ultra-fast, low-latency speech suitable for real-time applications, studio-like voices for production-quality narration, and a prompt-based dynamic model for highly expressive storytelling. Creators can fine-tune voice parameters such as volume, speed, pitch, stability, and similarity to match brand or project needs. Generated audio files can be redistributed globally, even after a subscription ends, enabling flexible usage across platforms. With simple controls and scalable voice options, Voicemaker streamlines voiceover creation for content, podcasts, videos, and more.
Voicemaker
Voicemaker is an AI-based online text-to-speech platform that turns written text into natural-sounding voiceovers across a wide range of languages and use cases. It offers ultra-fast, low-latency speech suitable for real-time applications, studio-like voices for production-quality narration, and a prompt-based dynamic model for highly expressive storytelling. Creators can fine-tune voice parameters such as volume, speed, pitch, stability, and similarity to match brand or project needs. Generated audio files can be redistributed globally, even after a subscription ends, enabling flexible usage across platforms. With simple controls and scalable voice options, Voicemaker streamlines voiceover creation for content, podcasts, videos, and more.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.

Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai